貢獻#
此專案是社群的共同努力成果,歡迎所有人貢獻。它託管於scikit-learn/scikit-learn。scikit-learn 的決策過程和治理結構在Scikit-learn 治理和決策中有說明。
Scikit-learn 在添加新演算法方面有些挑剔,而貢獻和幫助專案的最佳方法是開始處理已知的問題。請參閱給新貢獻者的問題以開始。
如果您在使用此套件時遇到問題,請不要猶豫,將問題提交到GitHub 問題追蹤器。也歡迎您發布功能請求或拉取請求。
貢獻方式#
有很多種方式可以為 scikit-learn 做出貢獻,最常見的方式是為專案貢獻程式碼或文件。改進文件與改進函式庫本身同等重要。如果您在文件中發現錯字,或做了改進,請不要猶豫,建立一個 GitHub 問題,或最好提交一個 GitHub 拉取請求。完整的檔案可以在 doc/ 目錄下找到。
但是還有許多其他方式可以提供幫助。特別是幫助改進、分類和調查問題以及審閱其他開發人員的拉取請求,都是非常有價值的貢獻,可以減輕專案維護者的負擔。
另一種貢獻方式是報告您遇到的問題,並在其他人報告且與您相關的問題上給予「讚」。如果您宣傳該專案,也會對我們有所幫助:從您的部落格和文章引用該專案,從您的網站連結到該專案,或只是按星號說「我使用它」
如果貢獻/問題涉及 API 原則的變更或依賴項或支援版本的變更,則必須有增強提案 (SLEP)的支持,其中 SLEP 必須以拉取請求的形式提交到增強提案,使用SLEP 範本,並遵循Scikit-learn 治理和決策中概述的決策過程。
自動化貢獻政策#
請勿提交由完全自動化工具產生的問題或拉取請求。維護人員保留自行決定關閉此類提交並封鎖任何對此負責的帳戶的權利。
理想情況下,貢獻應該來自以問題形式進行的人與人之間的討論。
提交錯誤報告或功能請求#
我們使用 GitHub 問題來追蹤所有錯誤和功能請求;如果您發現錯誤或希望看到實施某項功能,請隨時提出問題。
如果您在使用此套件時遇到問題,請不要猶豫,將問題提交到錯誤追蹤器。也歡迎您發布功能請求或拉取請求。
建議在提交之前檢查您的問題是否符合以下規則
如果您提交演算法或功能請求,請驗證該演算法是否符合我們的新演算法要求。
如果您提交錯誤報告,我們強烈建議您遵循如何撰寫良好的錯誤報告中的指南。
如何撰寫良好的錯誤報告#
當您向GitHub提交問題時,請盡力遵循這些指南!這將使我們更容易為您提供良好的回饋
理想的錯誤報告包含一個簡短可重現的程式碼片段,這樣任何人都可以輕鬆嘗試重現該錯誤。如果您的程式碼片段超過 50 行左右,請連結到Gist 或 GitHub 儲存庫。
如果無法包含可重現的程式碼片段,請具體說明所涉及的評估器和/或函式以及資料的形狀。
如果引發異常,請提供完整的追溯。
請包括您的作業系統類型和版本號碼,以及您的 Python、scikit-learn、numpy 和 scipy 版本。此資訊可以透過執行
python -c "import sklearn; sklearn.show_versions()"請確保所有程式碼片段和錯誤訊息都以適當的程式碼區塊格式化。請參閱建立和醒目提示程式碼區塊以瞭解更多詳細資訊。
如果您想幫助管理問題,請閱讀有關錯誤分類和問題管理的資訊。
貢獻程式碼#
注意
為了避免重複工作,強烈建議您搜尋問題追蹤器和PR 清單。如果您對重複工作有疑問,或者您想處理非普通的功能,建議您首先在問題追蹤器中開啟問題,以獲得核心開發人員的一些回饋。
尋找要處理的問題的一種簡單方法是在您的搜尋中應用「需要幫助」標籤。這會列出所有目前尚未聲明的問題。為了為自己聲明一個問題,請在其中評論 /take,以使 CI 自動將該問題分配給您。
為了保持程式碼庫的品質並簡化審閱過程,任何貢獻都必須符合專案的程式碼撰寫指南,特別是
請勿修改不相關的行,以使 PR 專注於其描述或問題中聲明的範圍。
僅撰寫可增加價值的內嵌註解,並避免說明顯而易見的事:說明「為什麼」而不是「是什麼」。
最重要的是:請勿貢獻您不了解的程式碼。
影片資源#
這些影片是關於如何為 scikit-learn 做出貢獻的逐步介紹,並且是以下文字指南的好夥伴。請務必仍然檢查我們下面的指南,因為它們描述了我們最新的最新工作流程。
注意
在 2021 年 1 月,為了使用更具包容性的詞語,scikit-learn GitHub 儲存庫的預設分支名稱從 master 變更為 main。這些影片是在分支重新命名之前製作的。對於正在觀看這些影片以設定工作環境並提交 PR 的貢獻者來說,應該將 master 替換為 main。
如何貢獻#
貢獻 scikit-learn 的首選方式是 fork GitHub 上的主要儲存庫,然後提交「pull request」(PR)。
在最初的幾個步驟中,我們將說明如何在本地安裝 scikit-learn,以及如何設定您的 git 儲存庫。
如果您還沒有 GitHub 帳戶,請在 GitHub 上建立一個帳戶。
Fork 專案儲存庫:點擊頁面頂端的「Fork」按鈕。這會在您的 GitHub 使用者帳戶下建立一份程式碼副本。有關如何 fork 儲存庫的更多詳細資訊,請參閱此指南。
將您 fork 的 scikit-learn 儲存庫從您的 GitHub 帳戶複製到您的本機磁碟。
git clone git@github.com:YourLogin/scikit-learn.git # add --depth 1 if your connection is slow cd scikit-learn
請依照從原始碼建置中的步驟 2-6,以開發模式建置 scikit-learn 並返回此文件。
安裝開發相依性。
pip install pytest pytest-cov ruff mypy numpydoc black==24.3.0
新增
upstream遠端。這會儲存對主要 scikit-learn 儲存庫的參考,您可以使用它來使您的儲存庫與最新的變更保持同步。git remote add upstream git@github.com:scikit-learn/scikit-learn.git執行
git remote -v檢查upstream和origin遠端別名是否已正確設定,該命令應顯示:origin git@github.com:YourLogin/scikit-learn.git (fetch) origin git@github.com:YourLogin/scikit-learn.git (push) upstream git@github.com:scikit-learn/scikit-learn.git (fetch) upstream git@github.com:scikit-learn/scikit-learn.git (push)
您現在應該有一個可運作的 scikit-learn 安裝,並且您的 git 儲存庫已正確設定。執行一些測試來驗證您的安裝可能會很有用。請參閱有用的 pytest 別名和標誌以取得範例。
接下來的步驟將說明修改程式碼並提交 PR 的流程。
將您的
main分支與upstream/main分支同步,有關更多詳細資訊,請參閱 GitHub 文件。git checkout main git fetch upstream git merge upstream/main
建立一個功能分支以保留您的開發變更。
git checkout -b my_feature並開始進行變更。始終使用功能分支。永遠不要在
main分支上工作是很好的做法!(可選)安裝 pre-commit,以便在每次 commit 之前執行程式碼樣式檢查。
pip install pre-commit pre-commit install
可以使用
git commit -n停用特定 commit 的 pre-commit 檢查。在您的電腦上的功能分支上開發功能,使用 Git 進行版本控制。完成編輯後,使用
git add新增已變更的檔案,然後使用git commitgit add modified_files git commit
在 Git 中記錄您的變更,然後使用以下命令將變更推送至您的 GitHub 帳戶:
git push -u origin my_feature請按照這些指示從您的 fork 建立 pull request。這會向潛在的審閱者發送通知。如果您的 pull request 在幾天後沒有收到注意,您可能需要考慮向開發頻道中的 discord 發送訊息以提高可見度(但不保證會立即回覆)。
通常,使您的本機功能分支與主要 scikit-learn 儲存庫的最新變更保持同步會很有幫助。
git fetch upstream
git merge upstream/main
隨後,您可能需要解決衝突。您可以參考與使用命令列解決合併衝突相關的 Git 文件。
Pull request 核對清單#
在 PR 可以合併之前,需要兩位核心開發人員的批准。一個不完整的貢獻(您希望在收到完整審閱之前做更多工作)應該標記為草稿 pull request,並在成熟後更改為「準備好審閱」。草稿 PR 可能有助於:表明您正在處理某件事以避免重複工作、要求對功能或 API 進行廣泛審閱,或尋求合作者。草稿 PR 通常會受益於在 PR 描述中加入任務清單。
為了簡化審閱流程,我們建議您的貢獻在將 PR 標記為「準備好審閱」之前符合以下規則。粗體的規則尤其重要。
為您的 pull request 提供一個有用的標題,總結您的貢獻所做的事情。此標題在合併後通常會成為 commit 訊息,因此它應該總結您的貢獻,以供後人參考。在某些情況下,「Fix <ISSUE TITLE>」就足夠了。「Fix #<ISSUE NUMBER>」永遠不是一個好標題。
確保您的程式碼通過測試。可以使用
pytest執行整個測試套件,但通常不建議這樣做,因為這需要很長時間。通常僅執行與您的變更相關的測試就足夠了:例如,如果您在sklearn/linear_model/_logistic.py中變更了某些內容,則執行以下命令通常就足夠了:pytest sklearn/linear_model/_logistic.py以確保 doctest 範例正確。pytest sklearn/linear_model/tests/test_logistic.py以執行特定於該檔案的測試。pytest sklearn/linear_model以測試整個linear_model模組。pytest doc/modules/linear_model.rst以確保使用者指南範例正確。pytest sklearn/tests/test_common.py -k LogisticRegression以執行我們所有的估算器檢查(特別是針對LogisticRegression,如果您變更了該估算器)。
可能會有其他失敗的測試,但它們將被 CI 捕獲,因此您無需在本地執行整個測試套件。有關如何有效使用
pytest的指南,請參閱有用的 pytest 別名和標誌。確保您的程式碼已正確註解和記錄,並且確保文件能夠正確呈現。若要建置文件,請參閱我們的文件指南。CI 也會建置文件:請參閱GitHub Actions 上的產生文件。
測試對於接受增強功能是必要的。錯誤修復或新功能應提供非回歸測試。這些測試會驗證修復或功能的正確行為。這樣,程式碼庫的進一步修改將保證與所需的行為一致。在錯誤修復的情況下,在 PR 時,非回歸測試應該在
main分支的程式碼庫中失敗,並且在 PR 程式碼中通過。如果您的 PR 很可能會影響使用者,則需要新增一個變更日誌項目來描述您的 PR 變更,請參閱
以下 README <https://github.com/scikit-learn/scikit-learn/blob/main/doc/whats_new/upcoming_changes/README.md>以取得更多詳細資訊。請遵循程式碼撰寫指南。
如果適用,請使用
sklearn.utils模組中的驗證工具和腳本。開發人員可用的實用常式列表可以在開發人員實用工具頁面中找到。通常,pull request 會解決一個或多個其他問題(或 pull request)。如果合併您的 pull request 表示應該關閉其他一些問題/PR,則您應該使用關鍵字來建立與它們的連結(例如,
Fixes #1234;允許多個問題/PR,只要每個問題/PR 前面都有一個關鍵字)。合併後,這些問題/PR 將由 GitHub 自動關閉。如果您的 pull request 僅與其他一些問題/PR 相關,或者僅部分解決了目標問題,請建立與它們的連結,而無需使用關鍵字(例如,Towards #1234)。PR 應經常透過效能和效率的基準測試(請參閱效能監控)或使用範例來佐證變更。範例也能向使用者說明函式庫的特性和複雜之處。請參考 examples/ 目錄中的其他範例。範例應說明新功能在實務上的用途,如果可以,請將其與 scikit-learn 中提供的其他方法進行比較。
新功能會帶來一些維護負擔。我們期望 PR 作者至少在初期參與他們提交的程式碼維護。新功能需要在使用者指南中以敘述性文件說明,並附上簡短的程式碼片段。如果相關,也請在文獻中加入參考資料,並盡可能提供 PDF 連結。
使用者指南也應包含演算法的預期時間和空間複雜度以及可擴展性,例如「此演算法可以擴展到大量樣本 > 100000,但在維度上無法擴展:
n_features預期會低於 100」。
您也可以查看我們的 程式碼審查準則,以了解審查者會期望什麼。
您可以使用以下工具檢查常見的程式設計錯誤
程式碼應具有良好的單元測試覆蓋率(至少 80%,最好是 100%),使用以下指令檢查
pip install pytest pytest-cov pytest --cov sklearn path/to/tests
另請參閱 測試和改進測試覆蓋率。
使用
mypy執行靜態分析mypy sklearn這不應在您的 pull request 中產生新的錯誤。使用
# type: ignore註解可以作為 mypy 不支援的少數情況下的解決方法,特別是:當匯入 C 或 Cython 模組時,
在具有裝飾器的屬性上。
如果貢獻包含效能分析,其中包含基準測試腳本和效能分析輸出(請參閱 效能監控),將會是加分項。另請參閱 如何最佳化速度 指南,以了解有關效能分析和 Cython 最佳化的更多詳細資訊。
注意
目前 scikit-learn 程式碼庫的狀態並未完全符合所有這些準則,但我們期望對所有新的貢獻強制執行這些約束將使整體程式碼庫品質朝正確的方向發展。
另請參閱
如需兩個非常詳細且更詳盡的開發工作流程指南,請瀏覽 Scipy 開發工作流程 和 Astropy 開發人員工作流程 章節。
持續整合(CI)#
Azure pipelines 用於在 Linux、Mac 和 Windows 上,使用不同的依賴項和設定來測試 scikit-learn。
CircleCI 用於建置供檢視的文件。
Github Actions 用於各種任務,包括建置 wheel 和原始碼發行版本。
Cirrus CI 用於在 ARM 上建置。
提交訊息標記#
請注意,如果最新提交訊息中出現以下標記之一,則會採取以下動作。
提交訊息標記 |
CI 採取的動作 |
|---|---|
[ci skip] |
完全跳過 CI |
[cd build] |
執行 CD(建置 wheel 和原始碼發行版本) |
[cd build gh] |
僅針對 GitHub Actions 執行 CD |
[cd build cirrus] |
僅針對 Cirrus CI 執行 CD |
[lint skip] |
Azure pipeline 跳過 linting |
[scipy-dev] |
使用我們的依賴項(numpy、scipy 等)開發版本進行建置和測試 |
[free-threaded] |
使用 CPython 3.13 free-threaded 進行建置和測試 |
[pyodide] |
使用 Pyodide 進行建置和測試 |
[azure parallel] |
平行執行 Azure CI 工作 |
[cirrus arm] |
執行 Cirrus CI ARM 測試 |
[float32] |
透過設定 |
[doc skip] |
不建置文件 |
[doc quick] |
建置文件,但不包括範例圖庫圖表 |
[doc build] |
建置文件,包括範例圖庫圖表(非常耗時) |
請注意,預設情況下,會建置文件,但只會執行由 pull request 直接修改的範例。
建置鎖定檔案#
CI 使用鎖定檔案來建置具有特定依賴項版本的環境。當 PR 需要修改依賴項或其版本時,應相應地更新鎖定檔案。這可以透過直接在 GitHub Pull Request (PR) 討論中新增以下註解來完成
@scikit-learn-bot update lock-files
機器人會在幾分鐘內將包含更新鎖定檔案的 commit 推送到您的 PR 分支。請務必勾選 PR 右側邊欄底部的 *允許維護者編輯* 核取方塊。您也可以像在命令列中一樣,指定選項 --select-build、--skip-build 和 --select-tag。在指令碼 build_tools/update_environments_and_lock_files.py 上使用 --help 以取得更多資訊。例如,
@scikit-learn-bot update lock-files --select-tag main-ci --skip-build doc
機器人會自動將 提交訊息標記 新增至具有某些標籤的 commit。如果您想要手動新增更多標記,可以使用 --commit-marker 選項。例如,以下註解將觸發機器人更新與文件相關的鎖定檔案,並將 [doc build] 標記新增至 commit
@scikit-learn-bot update lock-files --select-build doc --commit-marker "[doc build]"
解決鎖定檔案中的衝突#
以下 bash 片段有助於解決環境和鎖定檔案中的衝突
# pull latest upstream/main
git pull upstream main --no-rebase
# resolve conflicts - keeping the upstream/main version for specific files
git checkout --theirs build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git add build_tools/*/*.lock build_tools/*/*environment.yml \
build_tools/*/*lock.txt build_tools/*/*requirements.txt
git merge --continue
這會將 upstream/main 合併到我們的分支中,針對衝突的環境和鎖定檔案自動優先處理 upstream/main(這已足夠,因為我們之後會重新產生鎖定檔案)。
請注意,這只會修正環境和鎖定檔案中的衝突,您可能還需要解決其他衝突。
最後,我們必須重新產生 CI 的環境和鎖定檔案,如 建置鎖定檔案 中所述,或透過執行
python build_tools/update_environments_and_lock_files.py
停滯的 pull request#
由於貢獻功能可能是一個漫長的過程,因此有些 pull request 看起來不活躍但尚未完成。在這種情況下,接管它們是對專案的一大幫助。接管的好禮儀是
判斷 PR 是否停滯
如果我們已經將 pull request 識別為其他貢獻者的候選者,則該 pull request 可能會具有「停滯」或「需要協助」標籤。
若要判斷不活躍的 PR 是否停滯,請詢問貢獻者是否計劃在近期內繼續處理該 PR。如果 2 週內未回應且沒有任何讓 PR 向前推進的活動,則表示該 PR 已停滯,並將使用「需要協助」標籤標記該 PR。
請注意,如果 PR 收到較早對貢獻的評論,且一個月內沒有回覆,則可以安全地假設該 PR 已停滯,並將等待時間縮短為一天。
衝刺結束後,衝刺期間開啟的未合併 PR 的後續追蹤將會通知衝刺參與者,並且這些 PR 將會標記為「衝刺」。標記為「衝刺」的 PR 可以由衝刺領導者重新指派或宣告停滯。
接管停滯的 PR:若要接管 PR,請務必在停滯的 PR 上評論您正在接管,並從新的 PR 連結到舊的 PR。新的 PR 應透過從舊的 PR 拉取來建立。
停滯和未聲明的 issue#
一般來說,可供選擇的 issue 會具有 「需要協助」標籤。但是,並非所有需要貢獻者的 issue 都會具有此標籤,因為「需要協助」標籤並非總是與 issue 的狀態保持同步。貢獻者可以使用以下準則來尋找仍可供選擇的 issue
首先,要判斷 issue 是否已被聲明
檢查連結的 pull request
檢查對話,看看是否有人說他們正在處理建立 pull request
如果貢獻者在 issue 上評論說他們正在處理它,則預期在 2 週內(新貢獻者)或 4 週內(貢獻者或核心開發人員)會收到 pull request,除非明確給出較長的時間範圍。超過該時間後,其他貢獻者可以接手該 issue 並為其建立 pull request。我們鼓勵貢獻者直接在停滯或未聲明的 issue 上評論,讓社群成員知道他們將處理它。
如果 issue 連結到停滯的 pull request,我們建議貢獻者遵循 停滯的 pull request 章節中描述的程序,而不是直接處理 issue。
新貢獻者的 issue#
新貢獻者在尋找 issue 時應尋找以下標籤。我們強烈建議新貢獻者先解決「簡單」issue:這有助於貢獻者熟悉貢獻工作流程,並讓核心開發人員熟悉貢獻者;此外,我們經常低估 issue 的解決難度!
好的首個 issue 標籤
開始貢獻 scikit-learn 的一個好方法是從 issue 追蹤器中的 好的首個 issue 清單中選擇一個項目。解決這些 issue 可讓您在沒有太多先前知識的情況下開始貢獻專案。如果您已經為 scikit-learn 做出貢獻,則應改為查看簡單的 issue。
簡單標籤
如果您已經對 scikit-learn 做出貢獻,另一個為 scikit-learn 做出貢獻的好方法是從 issue tracker 中的簡易議題列表中挑選一個項目。您在這方面的協助將會受到更有經驗的開發人員的讚賞,因為這有助於他們騰出時間專注於其他議題。
需要協助標籤
我們經常使用「需要協助」標籤來標記議題,無論其難度如何。此外,我們使用「需要協助」標籤來標記已被原始貢獻者放棄,並可供其他人接手原始貢獻者未完成的 Pull Request。帶有「需要協助」標籤的議題列表可以在這裡找到。請注意,並非所有需要貢獻者的議題都會有此標籤。
文件#
我們樂於接受任何形式的文件
函式/方法/類別的 docstring:也稱為「API 文件」,這些描述了物件的作用,並詳細說明了任何參數、屬性和方法。Docstring 與程式碼一起存放在 sklearn/ 中,並根據 doc/api_reference.py 生成。若要新增、更新、移除或棄用在API 參考中列出的公共 API,這是您應該查看的地方。
使用者指南:這些提供了關於 scikit-learn 中實作的演算法的更詳細資訊,通常存放在根目錄 doc/ 目錄和 doc/modules/ 中。
範例:這些提供了完整的程式碼範例,可以示範 scikit-learn 模組的使用、比較不同的演算法或討論其解釋等等。範例存放在 examples/ 中。
其他 reStructuredText 文件:這些提供了各種其他有用的資訊(例如,貢獻 指南),並存放在 doc/ 中。
撰寫 docstring 的準則#
在記錄參數和屬性時,這裡列出一些格式良好的範例
n_clusters : int, default=3 The number of clusters detected by the algorithm. some_param : {"hello", "goodbye"}, bool or int, default=True The parameter description goes here, which can be either a string literal (either `hello` or `goodbye`), a bool, or an int. The default value is True. array_parameter : {array-like, sparse matrix} of shape (n_samples, n_features) \ or (n_samples,) This parameter accepts data in either of the mentioned forms, with one of the mentioned shapes. The default value is `np.ones(shape=(n_samples,))`. list_param : list of int typed_ndarray : ndarray of shape (n_samples,), dtype=np.int32 sample_weight : array-like of shape (n_samples,), default=None multioutput_array : ndarray of shape (n_samples, n_classes) or list of such arrays一般來說,請記住以下幾點
使用 Python 基本類型。(
bool而不是boolean)使用括號定義形狀:
array-like of shape (n_samples,)或array-like of shape (n_samples, n_features)對於具有多個選項的字串,請使用方括號:
input: {'log', 'squared', 'multinomial'}1D 或 2D 資料可以是
{array-like, ndarray, sparse matrix, dataframe}的子集。請注意,array-like也可以是list,而ndarray明確地僅為numpy.ndarray。當使用「框架式」特徵(例如,欄名稱)時,請指定
dataframe。在指定清單的資料類型時,請使用
of作為分隔符號:list of int。當參數支援提供有關形狀和/或資料類型的陣列以及此類陣列的列表時,您可以使用array-like of shape (n_samples,) or list of such arrays其中之一。在指定 ndarray 的 dtype 時,請在定義形狀後使用例如
dtype=np.int32:ndarray of shape (n_samples,), dtype=np.int32。您可以將多個 dtype 指定為一個集合:array-like of shape (n_samples,), dtype={np.float64, np.float32}。如果要提及任意精確度,請使用integral和floating而不是 Python dtypeint和float。當同時支援int和floating時,則無需指定 dtype。當預設值為
None時,僅需要在末尾指定default=None。請務必在 docstring 中包含當參數或屬性為None時的含義。
在 docstring 中新增「另請參閱」以參考相關的類別/函式。
docstring 中的「另請參閱」應為每個參考一行,帶有一個冒號和一個說明,例如
See Also -------- SelectKBest : Select features based on the k highest scores. SelectFpr : Select features based on a false positive rate test.
在「範例」部分中新增一或兩個程式碼片段,以顯示如何使用它。
撰寫使用者指南和其他 reStructuredText 文件的準則#
重要的是要在數學和演算法細節之間保持良好的折衷,並向讀者提供關於演算法如何運作的直觀理解。
首先對演算法/程式碼如何處理資料進行簡潔的、帶有手勢的解釋。
強調該功能的實用性及其推薦的應用。考慮納入演算法的複雜度 (\(O\left(g\left(n\right)\right)\))(如果可用),因為「經驗法則」可能非常依賴於機器。只有在這些複雜度不可用的情況下,才能改為提供經驗法則。
併入相關的圖表(從範例產生)以提供直觀的理解。
包含一或兩個簡短的程式碼範例,以示範該功能的使用方式。
引入任何必要的數學方程式,然後是參考文獻。透過延遲數學方面,文檔對於主要有興趣了解該功能的實際含義而不是其底層機制的使用者來說更容易理解。
當編輯 reStructuredText (
.rst) 檔案時,請盡可能將行長度保持在 88 個字元以下(例外情況包括連結和表格)。在 scikit-learn reStructuredText 檔案中,用單引號和雙引號括住文字都將呈現為內嵌文字(通常用於程式碼,例如,
list)。這是由於我們設定的特定設定。現在應該使用單引號。過多的資訊會使使用者難以存取他們感興趣的內容。使用下拉式選單透過以下語法來分解它
.. dropdown:: Dropdown title Dropdown content.
上面的程式碼片段將產生以下下拉式選單
下拉式選單標題#
下拉式選單內容。
可以使用下拉式選單預設隱藏的資訊是
低階層的部分,例如
References、Properties等(例如,請參閱檢測錯誤權衡 (DET)中的小節);深入的數學細節;
特定於用例的敘述;
一般來說,可能只對想要超越給定工具的實用性的使用者感興趣的敘述。
請勿對低階層的部分
Examples使用下拉式選單,因為它應該對所有使用者保持可見。請確保Examples部分緊接在主要討論之後,並且中間盡可能減少摺疊的部分。請注意,下拉式選單會破壞交叉參考。如果這有意義,請將參考與提及它的文字一起隱藏。否則,請勿使用下拉式選單。
撰寫參考文獻的準則#
當書目參考文獻具有 arxiv 或 數位物件識別碼 識別碼時,請使用 sphinx 指令
:arxiv:或:doi:。例如,請參閱譜聚類圖中的參考文獻。對於 docstring 中的「參考文獻」部分,請參閱
sklearn.metrics.silhouette_score作為範例。要交叉參考 scikit-learn 文檔中的其他頁面,請使用 reStructuredText 交叉參考語法
部分:要連結到文檔中的任意部分,請使用參考標籤(請參閱Sphinx 文檔)。例如
.. _my-section: My section ---------- This is the text of the section. To refer to itself use :ref:`my-section`.
您不應修改現有的 sphinx 參考標籤,因為這會破壞現有的交叉參考和指向 scikit-learn 文檔中特定部分的外部連結。
詞彙表:連結到常用詞彙和 API 元素詞彙表中的術語。
:term:`cross_validation`
函式:要連結到函式的說明文件,請使用函式的完整匯入路徑。
:func:`~sklearn.model_selection.cross_val_score`
但是,如果文件上方有
.. currentmodule::指令,您只需要使用指定目前模組後面的函式路徑。例如:.. currentmodule:: sklearn.model_selection :func:`cross_val_score`
類別:要連結到類別的說明文件,請使用類別的完整匯入路徑,除非文件上方有
.. currentmodule::指令(請參閱上方)。:class:`~sklearn.preprocessing.StandardScaler`
您可以使用任何文字編輯器編輯說明文件,然後按照建置說明文件的步驟產生 HTML 輸出。產生的 HTML 檔案將會放置在 _build/html/ 中,並可以在網頁瀏覽器中檢視,例如開啟本機 _build/html/index.html 檔案或執行本機伺服器。
python -m http.server -d _build/html
建置說明文件#
在提交 Pull Request 之前,請先在本機建置說明文件,檢查您的修改是否引入了新的 Sphinx 警告,並嘗試修正它們。
首先,請確認您已正確安裝了開發版本。除此之外,建置說明文件還需要安裝一些額外的套件。
pip install sphinx sphinx-gallery numpydoc matplotlib Pillow pandas \
polars scikit-image packaging seaborn sphinx-prompt \
sphinxext-opengraph sphinx-copybutton plotly pooch \
pydata-sphinx-theme sphinxcontrib-sass sphinx-design \
sphinx-remove-toctrees
若要建置說明文件,您需要位於 doc 資料夾中。
cd doc
在絕大多數情況下,您只需要產生不含範例展示的網站。
make
說明文件將會在 _build/html/stable 目錄中產生,並可以在網頁瀏覽器中檢視,例如開啟本機 _build/html/stable/index.html 檔案。若要同時產生範例展示,您可以使用:
make html
這會執行所有的範例,需要一些時間。您也可以根據檔案名稱僅執行少數範例。以下是執行所有檔案名稱包含 plot_calibration 的範例的方法:
EXAMPLES_PATTERN="plot_calibration" make html
您可以針對更進階的使用情境使用正規表示式。
如果您打算在離線環境中檢視說明文件,請設定環境變數 NO_MATHJAX=1。若要建置 PDF 手冊,請執行:
make latexpdf
Sphinx 版本
我們盡力讓說明文件在盡可能多的 Sphinx 版本下建置,但不同版本的行為往往略有不同。為了獲得最佳結果,您應該使用與我們在 CircleCI 上使用的相同版本。查看此GitHub 搜尋,以了解確切的版本。
在 GitHub Actions 上產生的說明文件#
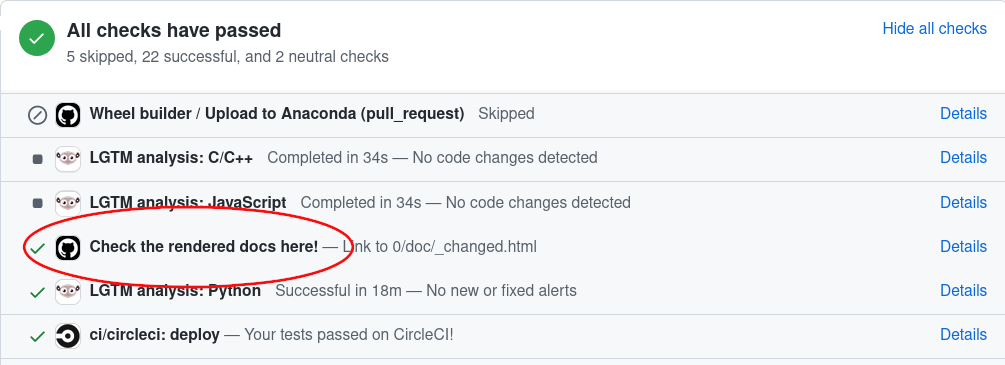
當您在 Pull Request 中變更說明文件時,GitHub Actions 會自動建置它。若要檢視 GitHub Actions 產生的說明文件,只需前往您的 PR 頁面底部,尋找「Check the rendered docs here!」項目,然後按一下旁邊的「details」。
測試和改善測試覆蓋率#
高品質的單元測試是 scikit-learn 開發流程的基石。為此,我們使用 pytest 套件。這些測試是適當命名的函式,位於 tests 子目錄中,可檢查演算法和程式碼不同選項的有效性。
在資料夾中執行 pytest 將會執行對應子套件的所有測試。如需更詳細的 pytest 工作流程,請參閱Pull Request 檢查清單。
我們期望新功能的程式碼覆蓋率至少達到 90% 左右。
監控效能#
此章節大量參考自pandas 說明文件。
在建議變更現有程式碼庫時,請務必確保它們不會造成效能降低。Scikit-learn 使用 asv 基準來監控選定常見評估器和函式的效能。您可以在 scikit-learn 基準頁面上檢視這些基準。對應的基準套件可以在 asv_benchmarks/ 目錄中找到。
若要使用 asv 的所有功能,您將需要 conda 或 virtualenv。如需更多詳細資訊,請查看 asv 安裝網頁。
首先,您需要安裝開發版本的 asv:
pip install git+https://github.com/airspeed-velocity/asv
並將您的目錄變更為 asv_benchmarks/
cd asv_benchmarks
基準套件已設定為針對您的 scikit-learn 本機複製執行。請確定它是最新的。
git fetch upstream
在基準套件中,基準是按照與 scikit-learn 相同的結構來組織。例如,您可以在 upstream/main 和您正在處理的分支之間比較特定評估器的效能:
asv continuous -b LogisticRegression upstream/main HEAD
此命令預設會使用 conda 來建立基準環境。如果您想要改用 virtualenv,請使用 -E 旗標:
asv continuous -E virtualenv -b LogisticRegression upstream/main HEAD
您也可以指定要基準化的整個模組:
asv continuous -b linear_model upstream/main HEAD
您可以將 HEAD 替換為任何本機分支。預設情況下,它只會報告變動至少 10% 的基準。您可以使用 -f 旗標來控制此比例。
若要執行完整的基準套件,只需移除 -b 旗標即可:
asv continuous upstream/main HEAD
但是,這可能需要長達兩個小時的時間。-b 旗標也接受正規表示式,以便執行更複雜的基準子集。
若要執行基準而不與另一個分支比較,請使用 run 命令:
asv run -b linear_model HEAD^!
您也可以使用目前 Python 環境中已安裝的 scikit-learn 版本來執行基準套件:
asv run --python=same
當您以可編輯模式安裝 scikit-learn 時,這在您每次執行基準時避免建立新環境特別有用。預設情況下,當使用現有安裝時,不會儲存結果。若要儲存結果,您必須指定 commit 雜湊:
asv run --python=same --set-commit-hash=<commit hash>
基準會依機器、環境和 commit 儲存和組織。若要查看所有已儲存的基準清單:
asv show
以及查看特定執行的報告:
asv show <commit hash>
當您執行正在處理的 Pull Request 的基準時,請在 GitHub 上報告結果。
基準套件支援額外的可設定選項,這些選項可以在 benchmarks/config.json 設定檔中設定。例如,基準可以針對 n_jobs 參數的提供值清單執行。
如需有關如何撰寫基準和如何使用 asv 的更多資訊,請參閱 asv 說明文件。
維持向後相容性#
棄用#
如果任何公開存取的類別、函式、方法、屬性或參數被重新命名,我們仍然會在兩個版本中支援舊的名稱,並在呼叫、傳遞或存取時發出棄用警告。
棄用類別或函式
假設函式 zero_one 被重新命名為 zero_one_loss,我們會在 zero_one 上加上裝飾器 utils.deprecated,並從該函式呼叫 zero_one_loss。
from ..utils import deprecated
def zero_one_loss(y_true, y_pred, normalize=True):
# actual implementation
pass
@deprecated(
"Function `zero_one` was renamed to `zero_one_loss` in 0.13 and will be "
"removed in 0.15. Default behavior is changed from `normalize=False` to "
"`normalize=True`"
)
def zero_one(y_true, y_pred, normalize=False):
return zero_one_loss(y_true, y_pred, normalize)
還需要將 zero_one 從 API_REFERENCE 移至 DEPRECATED_API_REFERENCE,並在 doc/api_reference.py 檔案中的 API_REFERENCE 中加入 zero_one_loss,以反映 API 參考 中的變更。
棄用屬性或方法
如果要棄用屬性或方法,請在屬性上使用裝飾器 deprecated。請注意,如果存在 property 裝飾器,則 deprecated 裝飾器應放在 property 裝飾器之前,以便正確呈現 docstring。例如,將屬性 labels_ 重新命名為 classes_ 可以這樣做:
@deprecated(
"Attribute `labels_` was deprecated in 0.13 and will be removed in 0.15. Use "
"`classes_` instead"
)
@property
def labels_(self):
return self.classes_
棄用參數
如果必須棄用參數,則必須手動引發 FutureWarning 警告。在以下範例中,k 已被棄用並重新命名為 n_clusters。
import warnings
def example_function(n_clusters=8, k="deprecated"):
if k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15",
FutureWarning,
)
n_clusters = k
當變更發生在類別中時,我們會在 fit 中驗證並引發警告。
import warnings
class ExampleEstimator(BaseEstimator):
def __init__(self, n_clusters=8, k='deprecated'):
self.n_clusters = n_clusters
self.k = k
def fit(self, X, y):
if self.k != "deprecated":
warnings.warn(
"`k` was renamed to `n_clusters` in 0.13 and will be removed in 0.15.",
FutureWarning,
)
self._n_clusters = self.k
else:
self._n_clusters = self.n_clusters
如這些範例所示,警告訊息應始終提供發生棄用的版本以及舊行為將被移除的版本。如果棄用發生在版本 0.x-dev 中,則訊息應說明棄用發生在版本 0.x 中,並將在 0.(x+2) 中移除,以便使用者有足夠的時間使其程式碼適應新的行為。例如,如果棄用發生在版本 0.18-dev 中,則訊息應說明它發生在版本 0.18 中,並且舊行為將在版本 0.20 中移除。
警告訊息還應簡要說明變更,並引導使用者尋找替代方案。
此外,應在 docstring 中加入棄用註解,回顧與上述棄用警告相同的資訊。使用 .. deprecated:: 指令。
.. deprecated:: 0.13
``k`` was renamed to ``n_clusters`` in version 0.13 and will be removed
in 0.15.
此外,棄用需要測試,以確保在相關情況下引發警告,而在其他情況下則不會引發警告。應在所有其他測試中捕獲警告(例如,使用 @pytest.mark.filterwarnings),並且在範例中不應有警告。
變更參數的預設值#
如果需要變更參數的預設值,請將預設值取代為特定值(例如,"warn"),並在使用者使用預設值時引發 FutureWarning。以下範例假設目前版本為 0.20,並且我們將 n_clusters 的預設值從 5(0.20 的舊預設值)變更為 10(0.22 的新預設值)。
import warnings
def example_function(n_clusters="warn"):
if n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
n_clusters = 5
當變更發生在類別中時,我們會在 fit 中驗證並引發警告。
import warnings
class ExampleEstimator:
def __init__(self, n_clusters="warn"):
self.n_clusters = n_clusters
def fit(self, X, y):
if self.n_clusters == "warn":
warnings.warn(
"The default value of `n_clusters` will change from 5 to 10 in 0.22.",
FutureWarning,
)
self._n_clusters = 5
與棄用類似,警告訊息應始終提供發生變更的版本以及舊行為將被移除的版本。
docstring 中的參數描述需要進行相應的更新,方法是加入 versionchanged 指令,其中包含舊預設值和新預設值,並指向變更將生效的版本。
.. versionchanged:: 0.22
The default value for `n_clusters` will change from 5 to 10 in version 0.22.
最後,我們需要測試,以確保在相關情況下引發警告,而在其他情況下則不會引發警告。應在所有其他測試中捕獲警告(例如,使用 @pytest.mark.filterwarnings),並且在範例中不應有警告。
程式碼審查指南#
審查以 PR 形式貢獻給專案的程式碼是 scikit-learn 開發的關鍵組成部分。我們鼓勵任何人開始審查其他開發人員的程式碼。程式碼審查過程通常對每個參與者都具有高度的教育意義。如果您希望使用某項功能,並且能夠對 PR 是否滿足您的需求做出批判性回應,則此做法尤其合適。雖然每個 pull request 都需要兩位核心開發人員簽核,但您可以透過提供您的意見反應來加快此過程。
注意
客觀改進與主觀挑剔之間的區別並不總是清楚的。審查人員應記得,程式碼審查的主要目的是降低專案中的風險。在審查程式碼時,應旨在避免可能需要錯誤修正、棄用或撤回的情況。關於文件:錯字、文法問題和消除歧義最好立即處理。
任何程式碼審查中需要涵蓋的重要面向#
以下是任何程式碼審查中需要涵蓋的一些重要面向,從高階問題到更詳細的檢查清單。
我們是否希望將此功能加入程式庫?它是否有可能被使用?作為 scikit-learn 使用者,您是否喜歡此變更並打算使用它?它是否在 scikit-learn 的範圍內?維護新功能的成本是否值得其好處?
程式碼是否與 scikit-learn 的 API 一致?公開的函式/類別/參數是否命名良好且設計直觀?
是否所有公開的函式/類別及其參數、回傳類型和儲存的屬性都根據 scikit-learn 的慣例命名並清楚地記錄下來?
使用者指南中是否描述了任何新功能,並以範例說明?
是否測試了每個公開的函式/類別?是否測試了合理的一組參數、它們的值、值類型和組合?測試是否驗證程式碼是正確的,即執行文件所說的功能?如果變更是錯誤修正,是否包含非回歸測試?請參閱此處以開始使用 Python 進行測試。
測試是否在持續整合建置中通過?如果適當,請協助貢獻者了解測試失敗的原因。
測試是否涵蓋每一行程式碼(請參閱建置日誌中的涵蓋率報告)?如果沒有,缺少涵蓋率的行是否為良好的例外狀況?
程式碼是否易於閱讀且冗餘度低?是否應改進變數名稱以提高清晰度或一致性?是否應加入註解?是否應移除不必要或多餘的註解?
是否可以輕鬆地重寫程式碼,以在相關設定下更有效率地執行?
程式碼是否與先前的版本向後相容?(或是必須進行棄用週期?)
新程式碼是否會對其他程式庫增加任何相依性?(這不太可能被接受)
文件是否正確呈現(請參閱文件章節以取得更多詳細資料),並且繪圖是否具有指導意義?
用於審查的標準回覆包含審查人員可能會提出的一些常見意見。
溝通指南#
審查開放的 pull request (PR) 有助於推動專案發展。這是熟悉程式碼庫的好方法,並應激勵貢獻者繼續參與專案。[1]
每個 PR,無論好壞,都是一種慷慨的行為。以正面的評論開始將有助於作者感到受到獎勵,並且您的後續評論可能會被更清楚地聽到。您也可能會感覺良好。
如果可能,請從較大的問題開始,以便作者知道他們已被理解。請抵制立即逐行閱讀或以小的普遍問題開始的誘惑。
不要讓完美成為好的敵人。如果您發現自己提出了許多不屬於程式碼審查指南的小建議,請考慮以下方法:
避免提交這些建議;
將它們加上「Nit」前綴,以便貢獻者知道不處理是可以接受的;
後續的 PR 中再進行處理,基於禮貌,您可能需要通知原始貢獻者。
不要急,花時間讓您的評論清晰,並為您的建議提出理由。
您是這個專案的門面。每個人都會有狀況不好的時候,在這種情況下,您應該休息一下:試著花時間並保持離線狀態。
閱讀現有程式碼庫#
閱讀並理解現有的程式碼庫始終是一項艱難的練習,需要時間和經驗才能掌握。儘管我們通常盡力編寫簡單的程式碼,但考慮到專案的龐大規模,理解程式碼起初可能讓人感到難以承受。以下是一些可能有助於使這項任務更輕鬆、更快速的提示(順序不分先後)。
熟悉 scikit-learn 物件的 API:了解 fit、predict、transform 等的用途。
在深入閱讀函數/類別的程式碼之前,請先瀏覽 docstrings,並試著了解每個參數/屬性的作用。停下來思考一下如果我必須自己做,我會怎麼做?也可能會有幫助。
最棘手的事情通常是識別程式碼的哪些部分是相關的,哪些不是。在 scikit-learn 中,會執行大量的輸入檢查,尤其是在 fit 方法的開頭。有時,只有一小部分程式碼在執行實際的工作。例如,查看
fit方法的LinearRegression,您要找的可能只是呼叫scipy.linalg.lstsq,但它被埋藏在多行輸入檢查和不同種類的參數處理中。由於使用了繼承,某些方法可能會在父類別中實作。所有估算器都至少繼承自
BaseEstimator和一個Mixin類別(例如ClassifierMixin),它根據估算器(分類器、回歸器、轉換器等)的性質啟用預設行為。有時,閱讀給定函數的測試將使您了解其預期用途。您可以使用
git grep(見下文)來查找為函數編寫的所有測試。特定函數/類別的大多數測試都放在模組的tests/資料夾下。您經常會看到如下的程式碼:
out = Parallel(...)(delayed(some_function)(param) for param in some_iterable)。這使用 Joblib 並行執行some_function。out接著是一個包含some_function每次呼叫傳回值的可迭代物件。我們使用 Cython 來編寫快速程式碼。Cython 程式碼位於
.pyx和.pxd檔案中。Cython 程式碼具有更類似 C 的風格:我們使用指標、執行手動記憶體分配等。在這裡,具備一些 C / C++ 的最低限度經驗幾乎是強制性的。有關更多資訊,請參閱Cython 最佳實務、慣例和知識。精通您的工具。
設定
git blame以忽略將程式碼風格遷移到black的 commit。git config blame.ignoreRevsFile .git-blame-ignore-revs在 black 的避免破壞 git blame 的文件中找到更多資訊。