2.3. 分群#
可以使用 分群模組 sklearn.cluster 來執行未標記資料的分群。
每個分群演算法都有兩種變體:一個類別,實作 fit 方法以在訓練資料上學習叢集,以及一個函數,該函數給定訓練資料,會傳回對應於不同叢集的整數標籤陣列。對於類別,訓練資料上的標籤可以在 labels_ 屬性中找到。
2.3.1. 分群方法概述#
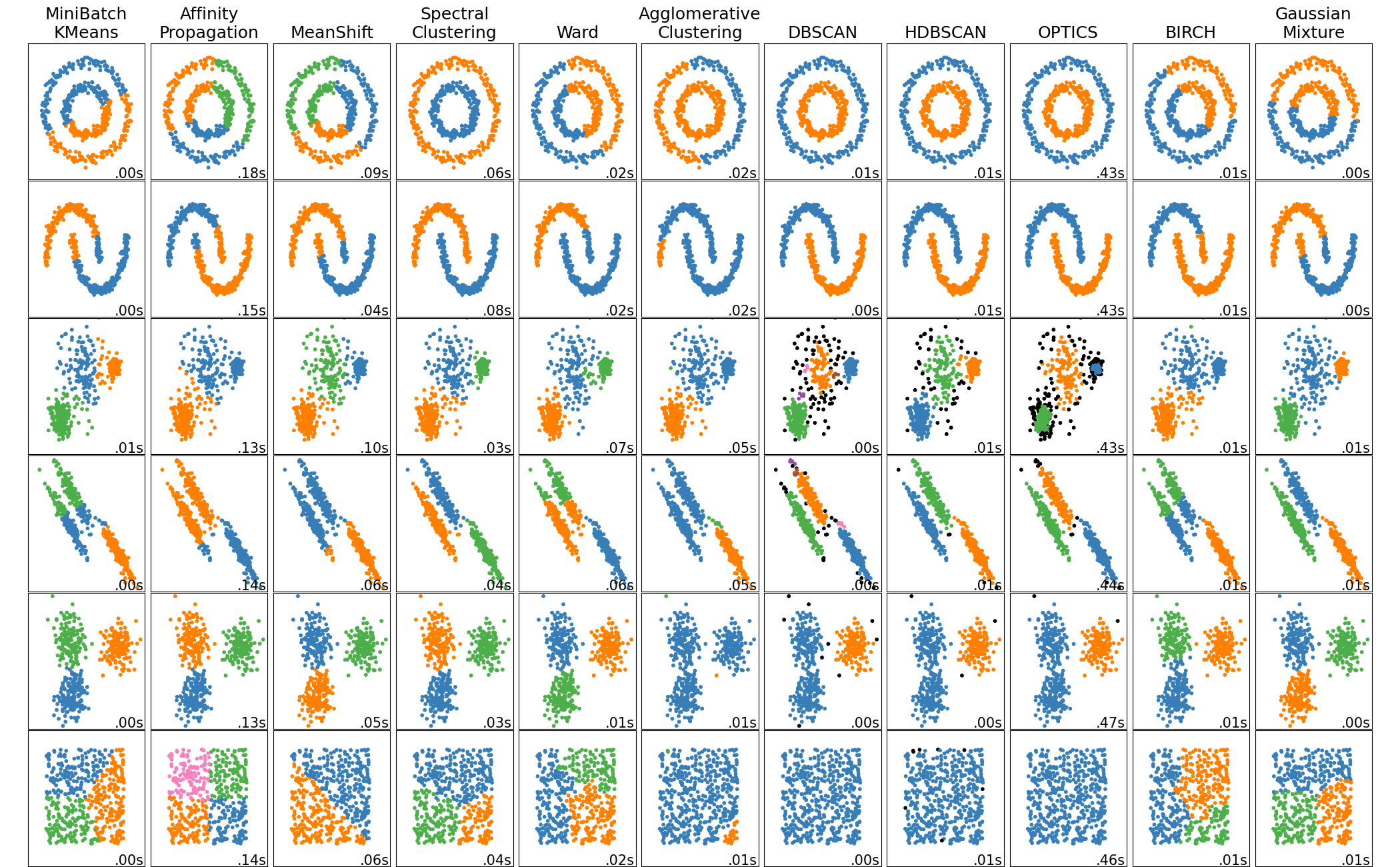
scikit-learn 中分群演算法的比較#
方法名稱 |
參數 |
可擴展性 |
用途 |
幾何形狀(使用的指標) |
|---|---|---|---|---|
叢集數量 |
非常大的 |
通用、均勻的叢集大小、平面幾何形狀、叢集數量不多、歸納式 |
點之間的距離 |
|
阻尼、樣本偏好 |
無法隨 n_samples 擴展 |
許多叢集、不均勻的叢集大小、非平面幾何形狀、歸納式 |
圖形距離(例如,最近鄰居圖) |
|
頻寬 |
無法隨 |
許多叢集、不均勻的叢集大小、非平面幾何形狀、歸納式 |
點之間的距離 |
|
叢集數量 |
中等的 |
少數叢集、均勻的叢集大小、非平面幾何形狀、演繹式 |
圖形距離(例如,最近鄰居圖) |
|
叢集數量或距離閾值 |
大的 |
許多叢集、可能存在連通性約束、演繹式 |
點之間的距離 |
|
叢集數量或距離閾值、連結類型、距離 |
大的 |
許多叢集、可能存在連通性約束、非歐幾里德距離、演繹式 |
任何成對距離 |
|
鄰域大小 |
非常大的 |
非平面幾何形狀、不均勻的叢集大小、離群值移除、演繹式 |
最近點之間的距離 |
|
最小叢集成員資格、最小點鄰居 |
大的 |
非平面幾何形狀、不均勻的叢集大小、離群值移除、演繹式、階層式、可變叢集密度 |
最近點之間的距離 |
|
最小叢集成員資格 |
非常大的 |
非平面幾何形狀、不均勻的叢集大小、可變叢集密度、離群值移除、演繹式 |
點之間的距離 |
|
許多 |
無法擴展 |
平面幾何形狀、適用於密度估計、歸納式 |
到中心的馬氏距離 |
|
分支因子、閾值、可選的全域叢集器。 |
大的 |
大型資料集、離群值移除、資料縮減、歸納式 |
點之間的歐幾里德距離 |
|
叢集數量 |
非常大的 |
通用、均勻的叢集大小、平面幾何形狀、無空叢集、歸納式、階層式 |
點之間的距離 |
當叢集具有特定形狀時(即非平面流形),非平面幾何形狀分群很有用,而標準歐幾里德距離並不是正確的指標。這種情況會出現在上圖的頂部兩行中。
適用於分群的高斯混合模型在文件中另一個專門討論混合模型的章節中描述。KMeans 可以視為每個成分具有相等共變異數的高斯混合模型的特例。
2.3.2. K-means#
KMeans 演算法會嘗試將樣本分為 n 個具有相等變異數的群組來分群資料,並最小化一個稱為慣性或叢集內平方和的準則(請參閱下文)。此演算法需要指定叢集數量。它能很好地擴展到大量樣本,並已在許多不同領域中的廣泛應用領域中使用。
K-means 演算法將一組 \(N\) 個樣本 \(X\) 分為 \(K\) 個不相交的叢集 \(C\),每個叢集都由叢集中樣本的平均值 \(\mu_j\) 描述。平均值通常稱為叢集「質心」;請注意,它們一般來說不是來自 \(X\) 的點,儘管它們位於相同的空間中。
K-means 演算法旨在選擇最小化慣性或叢集內平方和準則的質心
慣性可以認為是衡量叢集內部一致性的指標。它具有各種缺點
慣性假設叢集是凸形且各向同性的,但情況並非總是如此。它對細長的叢集或具有不規則形狀的流形反應不佳。
慣性不是正規化的指標:我們只知道較低的值比較好,而零是最佳值。但是在非常高維的空間中,歐幾里德距離往往會膨脹(這是所謂的「維度詛咒」的一個實例)。在 k-means 分群之前執行降維演算法(例如 主成分分析 (PCA))可以緩解此問題並加快計算速度。
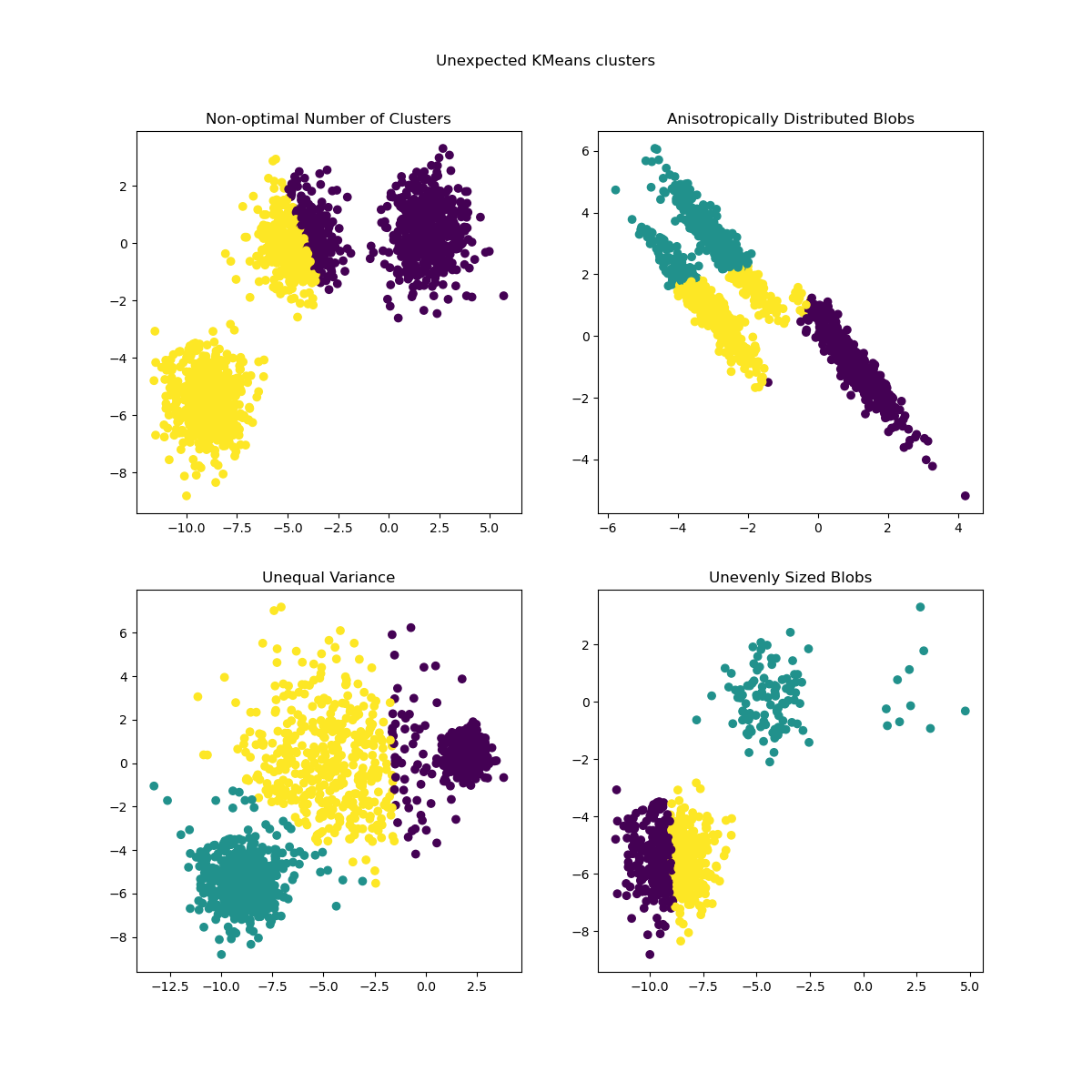
如需更詳細地說明上述問題以及如何解決這些問題,請參閱範例 K-means 假設的演示 和 使用 KMeans 分群上的輪廓分析選擇叢集數量。
K-means 通常被稱為 Lloyd 演算法。基本上,此演算法有三個步驟。第一步是選擇初始的質心,最基本的方法是從資料集 \(X\) 中選擇 \(k\) 個樣本。初始化之後,K-means 會在另外兩個步驟之間循環。第一個步驟是將每個樣本分配到最接近的質心。第二個步驟是透過取分配到每個先前質心的所有樣本的平均值來建立新的質心。計算新舊質心之間的差異,演算法會重複最後兩個步驟,直到該值小於閾值。換句話說,它會重複直到質心沒有顯著移動為止。
K-means 等同於具有小型、全等、對角共變異數矩陣的期望最大化演算法。
此演算法也可以透過 Voronoi 圖的概念來理解。首先,使用目前的質心計算點的 Voronoi 圖。Voronoi 圖中的每個區段都會變成一個獨立的群集。其次,質心會更新為每個區段的平均值。然後,演算法會重複執行此操作,直到滿足停止條件為止。通常,當迭代之間目標函數的相對減少量小於給定的容差值時,演算法會停止。但在此實作中並非如此:當質心的移動小於容差時,迭代會停止。
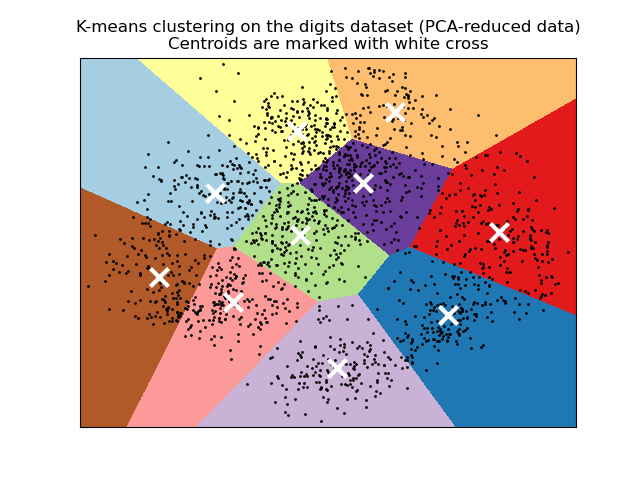
給予足夠的時間,K-means 總是會收斂,但可能會收斂到局部最小值。這高度取決於質心的初始化。因此,通常會多次進行計算,並使用不同的質心初始化。解決此問題的一種方法是 k-means++ 初始化方案,該方案已在 scikit-learn 中實作(使用 init='k-means++' 參數)。這會將質心初始化為(通常)彼此遠離,從而產生可能比隨機初始化更好的結果,如參考資料所示。如需比較不同初始化方案的詳細範例,請參閱 手寫數字資料上 K-Means 分群的範例。
也可以獨立呼叫 K-means++,以為其他分群演算法選擇種子,詳情和範例用法請參閱 sklearn.cluster.kmeans_plusplus。
此演算法支援樣本權重,可以使用參數 sample_weight 給定。這允許在計算群集中心和慣性值時,為某些樣本分配更多權重。例如,為樣本分配權重 2 等同於將該樣本的重複項新增至資料集 \(X\)。
範例
使用 k-means 分群文字文件:使用
KMeans和MiniBatchKMeans基於稀疏資料的文件分群K-Means++ 初始化範例:使用 K-means++ 為其他分群演算法選擇種子。
2.3.2.1. 低階平行處理#
KMeans 受惠於透過 Cython 實現的基於 OpenMP 的平行處理。小區塊的資料(256 個樣本)會平行處理,這也產生較小的記憶體佔用量。如需有關如何控制執行緒數量的詳細資訊,請參閱我們的平行處理註解。
範例
K-means 假設的示範:示範 k-means 何時執行直觀,以及何時不執行
手寫數字資料上 K-Means 分群的範例:分群手寫數字
參考文獻#
「k-means++:仔細播種的優點」 Arthur, David, 和 Sergei Vassilvitskii,第十八屆 ACM-SIAM 離散演算法年度研討會會議記錄,工業和應用數學學會 (2007)
2.3.2.2. 迷你批次 K-Means#
MiniBatchKMeans 是 KMeans 演算法的一種變體,它使用迷你批次來減少計算時間,同時仍嘗試最佳化相同的目標函數。迷你批次是輸入資料的子集,在每次訓練迭代中隨機取樣。這些迷你批次大幅減少了收斂到局部解所需的計算量。與其他減少 k-means 收斂時間的演算法相比,迷你批次 k-means 產生的結果通常只比標準演算法稍差。
此演算法會在兩個主要步驟之間迭代,與原始 k-means 類似。在第一個步驟中,從資料集中隨機抽取 \(b\) 個樣本以形成迷你批次。然後,將這些樣本分配到最接近的質心。在第二個步驟中,質心會更新。與 k-means 不同,這是以每個樣本為基礎完成的。對於迷你批次中的每個樣本,會透過取樣本和分配到該質心的所有先前樣本的串流平均值來更新分配的質心。這會隨著時間的推移降低質心的變化率。執行這些步驟,直到收斂或達到預先確定的迭代次數。
MiniBatchKMeans 比 KMeans 收斂得更快,但結果的品質會降低。實際上,品質上的差異可能非常小,如範例和引用的參考文獻所示。
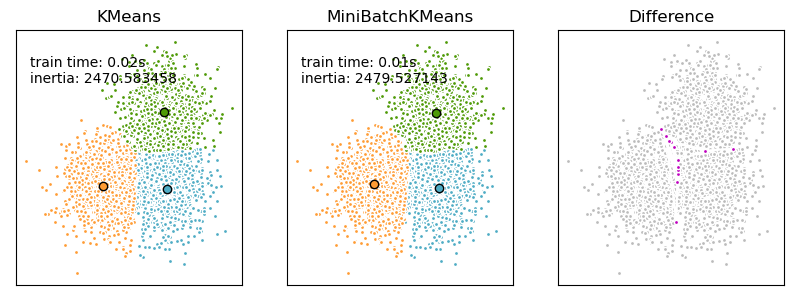
範例
K-Means 和 MiniBatchKMeans 分群演算法的比較:比較
KMeans和MiniBatchKMeans使用 k-means 分群文字文件:使用
KMeans和MiniBatchKMeans基於稀疏資料的文件分群
參考文獻#
「Web Scale K-Means 分群」 D. Sculley,第 19 屆國際全球資訊網會議記錄 (2010)
2.3.3. 親和力傳播#
AffinityPropagation 透過在樣本對之間傳送訊息直到收斂來建立群集。然後使用少量範例描述資料集,這些範例被識別為最能代表其他樣本的範例。在配對之間傳送的訊息表示一個樣本成為另一個樣本的範例的適合性,並根據其他配對的值進行更新。此更新會迭代進行,直到收斂為止,屆時會選擇最終的範例,並因此給定最終的分群。
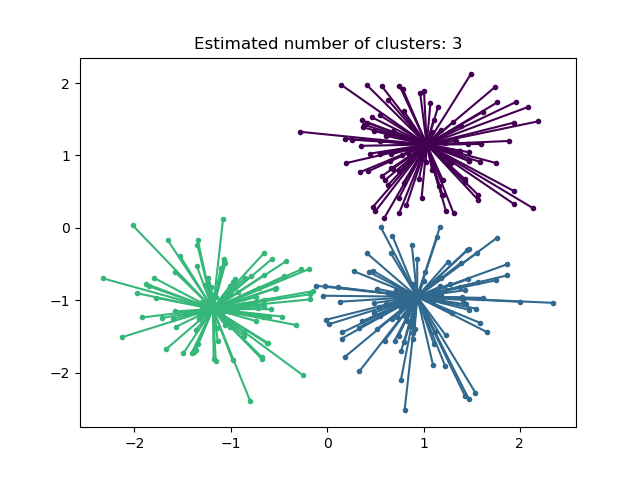
親和力傳播很有趣,因為它會根據提供的資料選擇群集的數量。為此,兩個重要的參數是偏好,它控制使用的範例數量,以及阻尼因子,它會抑制責任訊息和可用性訊息,以避免更新這些訊息時出現數值震盪。
親和力傳播的主要缺點是它的複雜性。此演算法的時間複雜度為 \(O(N^2 T)\) 階,其中 \(N\) 是樣本數,\(T\) 是直到收斂的迭代次數。此外,如果使用密集的相似性矩陣,記憶體複雜度為 \(O(N^2)\) 階,但如果使用稀疏的相似性矩陣,則可以減少。這使得親和力傳播最適合小型到中型的資料集。
演算法描述#
點之間傳送的訊息屬於兩種分類之一。第一種是責任 \(r(i, k)\),它是樣本 \(k\) 應該作為樣本 \(i\) 的代表樣本的累積證據。第二種是可用性 \(a(i, k)\),它是樣本 \(i\) 應該選擇樣本 \(k\) 作為其代表樣本的累積證據,並考慮所有其他樣本認為 \(k\) 應該成為代表樣本的值。透過這種方式,如果樣本 (1) 與許多樣本足夠相似,且 (2) 被許多樣本選擇作為其代表,則會選擇該樣本作為代表樣本。
更正式地說,樣本 \(k\) 作為樣本 \(i\) 的代表樣本的責任由下式給出:
其中 \(s(i, k)\) 是樣本 \(i\) 和 \(k\) 之間的相似度。樣本 \(k\) 作為樣本 \(i\) 的代表樣本的可用性由下式給出:
首先,所有 \(r\) 和 \(a\) 的值都設為零,並且每個值的計算都會迭代直到收斂。如上所述,為了避免更新訊息時出現數值震盪,引入阻尼因子 \(\lambda\) 到迭代過程中
其中 \(t\) 表示迭代次數。
範例
親和力傳播分群演算法的演示:在具有 3 個類別的合成 2D 資料集上進行親和力傳播。
股票市場結構視覺化:在金融時間序列上進行親和力傳播,以尋找公司群組。
2.3.4. 均值漂移#
MeanShift 分群旨在發現樣本平滑密度中的團塊。它是一種基於質心的演算法,其運作方式是將質心候選者更新為給定區域內點的平均值。然後在後處理階段篩選這些候選者,以消除近乎重複的候選者,形成最終的質心集合。
數學細節#
質心候選者的位置會使用一種稱為爬山法的技術進行迭代調整,該技術會尋找估計機率密度的局部最大值。給定迭代 \(t\) 的候選質心 \(x\),則會根據以下方程式更新候選質心:
其中 \(m\) 是為每個質心計算的均值漂移向量,該向量指向點密度最大增加的區域。為了計算 \(m\),我們將 \(N(x)\) 定義為 \(x\) 周圍給定距離內樣本的鄰域。然後,使用以下方程式計算 \(m\),有效地將質心更新為其鄰域內樣本的平均值:
一般來說,\(m\) 的方程式取決於用於密度估計的核函數。通用公式為:
在我們的實作中,如果 \(x\) 足夠小,則 \(K(x)\) 等於 1,否則等於 0。實際上,\(K(y - x)\) 表示 \(y\) 是否在 \(x\) 的鄰域中。
該演算法會自動設定叢集數量,而不是依賴於 bandwidth 參數,該參數指示要搜尋的區域大小。可以手動設定此參數,但可以使用提供的 estimate_bandwidth 函數進行估計,如果在未設定頻寬的情況下呼叫該函數。
該演算法不具有高度可擴展性,因為它在演算法執行期間需要多次最近鄰搜尋。但是,該演算法保證會收斂,當質心的變化很小時,演算法將停止迭代。
標記新樣本的方式是找到給定樣本的最近質心。
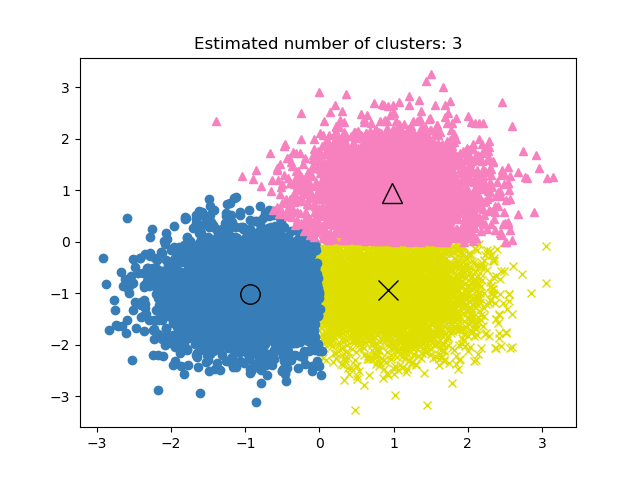
範例
均值漂移分群演算法的演示:在具有 3 個類別的合成 2D 資料集上進行均值漂移分群。
參考文獻#
「均值漂移:一種針對特徵空間分析的穩健方法」 D. Comaniciu 和 P. Meer,IEEE 模式分析與機器智慧學報 (2002)
2.3.5. 譜聚類#
SpectralClustering 對樣本之間的親和力矩陣執行低維嵌入,然後對低維空間中特徵向量的分量進行聚類,例如透過 KMeans。如果親和力矩陣是稀疏的,並且 amg 求解器用於特徵值問題,則它特別具有計算效率(請注意,amg 求解器要求安裝 pyamg 模組。)
目前版本的 SpectralClustering 要求預先指定叢集的數量。它適用於少量叢集,但不建議用於大量叢集。
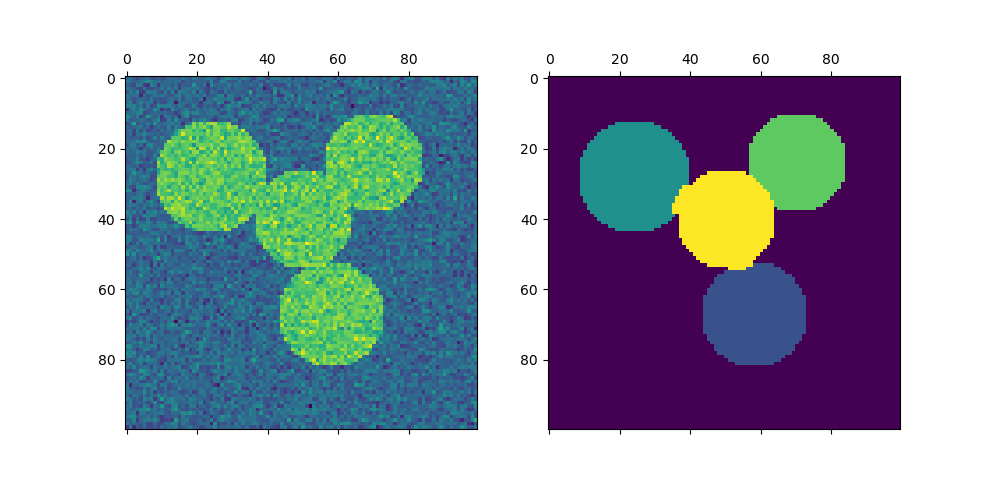
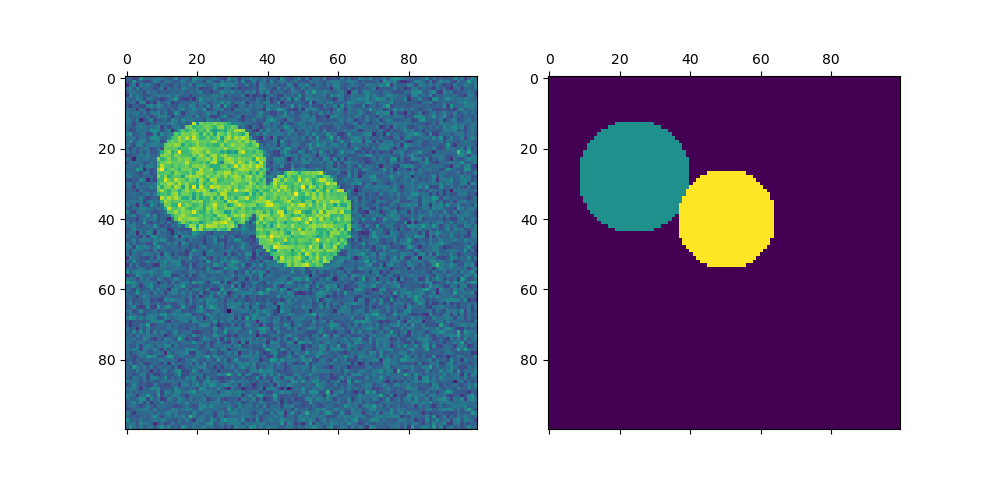
對於兩個叢集,SpectralClustering 會解決相似度圖上 正規化切割問題的凸鬆弛:將圖分成兩部分,以便切割的邊緣的權重相較於每個叢集內的邊緣權重較小。當處理圖像時,此準則特別有趣,在圖像中,圖的頂點是像素,並且相似度圖的邊緣權重是使用圖像梯度函數計算的。
警告
將距離轉換為行為良好的相似度
請注意,如果您的相似度矩陣的值分布不佳,例如具有負值或具有距離矩陣而非相似度,則光譜問題將是奇異的,且問題無法解決。在這種情況下,建議對矩陣的條目應用轉換。例如,在帶符號的距離矩陣的情況下,通常會應用熱核:
similarity = np.exp(-beta * distance / distance.std())
請參閱此類應用程式的範例。
範例
用於影像分割的光譜聚類:使用光譜聚類從雜訊背景中分割物件。
將希臘硬幣的圖片分割成區域:光譜聚類以將硬幣的影像分割成區域。
2.3.5.1. 不同的標籤指派策略#
可以使用不同的標籤指派策略,對應於 SpectralClustering 的 assign_labels 參數。 "kmeans" 策略可以匹配更精細的細節,但可能不穩定。特別是,除非您控制 random_state,否則它可能無法在每次執行時重現,因為它取決於隨機初始化。替代的 "discretize" 策略可 100% 重現,但往往會建立相當均勻和幾何形狀的包裹。最近新增的 "cluster_qr" 選項是一種確定性的替代方案,往往會在以下範例應用程式中建立視覺效果最佳的分區。
|
|
|
|---|---|---|
|
|
|



參考文獻#
「多類別光譜聚類」 Stella X. Yu, Jianbo Shi, 2003
「簡單、直接且有效率的多向譜聚類」Anil Damle, Victor Minden, Lexing Ying, 2019
2.3.5.2. 譜聚類圖#
譜聚類也可以透過其譜嵌入(spectral embeddings)來分割圖形。在這種情況下,相似性矩陣是圖形的鄰接矩陣,並且 SpectralClustering 會以 affinity='precomputed' 初始化。
>>> from sklearn.cluster import SpectralClustering
>>> sc = SpectralClustering(3, affinity='precomputed', n_init=100,
... assign_labels='discretize')
>>> sc.fit_predict(adjacency_matrix)
參考文獻#
「譜聚類教程」Ulrike von Luxburg, 2007
「正規化切割與影像分割」Jianbo Shi, Jitendra Malik, 2000
「譜分割的隨機漫步觀點」Marina Meila, Jianbo Shi, 2001
「關於譜聚類:分析與演算法」Andrew Y. Ng, Michael I. Jordan, Yair Weiss, 2001
「隨機區塊分割串流圖挑戰的預處理譜聚類」David Zhuzhunashvili, Andrew Knyazev
2.3.6. 階層式分群#
階層式分群是一般的分群演算法家族,透過連續合併或分割的方式來建立巢狀群集。這種群集階層以樹狀圖(或樹狀結構圖)表示。樹的根是聚集所有樣本的唯一群集,而葉子則是只有一個樣本的群集。有關更多詳細資訊,請參閱維基百科頁面。
AgglomerativeClustering物件使用由下而上的方法執行階層式分群:每個觀測值都從自己的群集開始,然後將群集依序合併在一起。連結準則決定了用於合併策略的度量。
Ward 會最小化所有群集內的平方差總和。它是一種變異數最小化的方法,從這個意義上來說,它與 k 平均數的目標函數相似,但採用了凝聚式階層方法。
最大值 或 完整連結 會最小化成對群集觀測值之間的最大距離。
平均連結 會最小化成對群集所有觀測值之間距離的平均值。
單一連結 會最小化成對群集最接近觀測值之間的距離。
AgglomerativeClustering在與連通性矩陣一起使用時,也可以擴展到大量樣本,但是當樣本之間沒有新增連通性限制時,計算量會非常大:它會在每個步驟中考慮所有可能的合併。
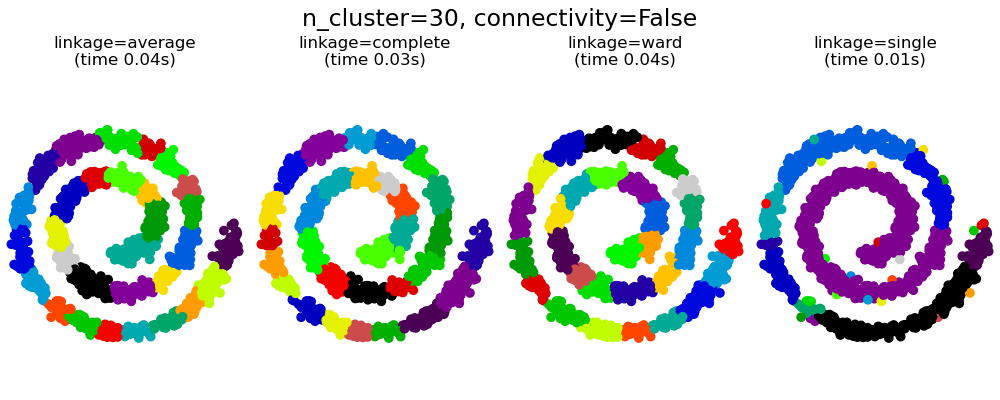
2.3.6.1. 不同的連結類型:Ward、完整、平均和單一連結#
AgglomerativeClustering支援 Ward、單一、平均和完整連結策略。
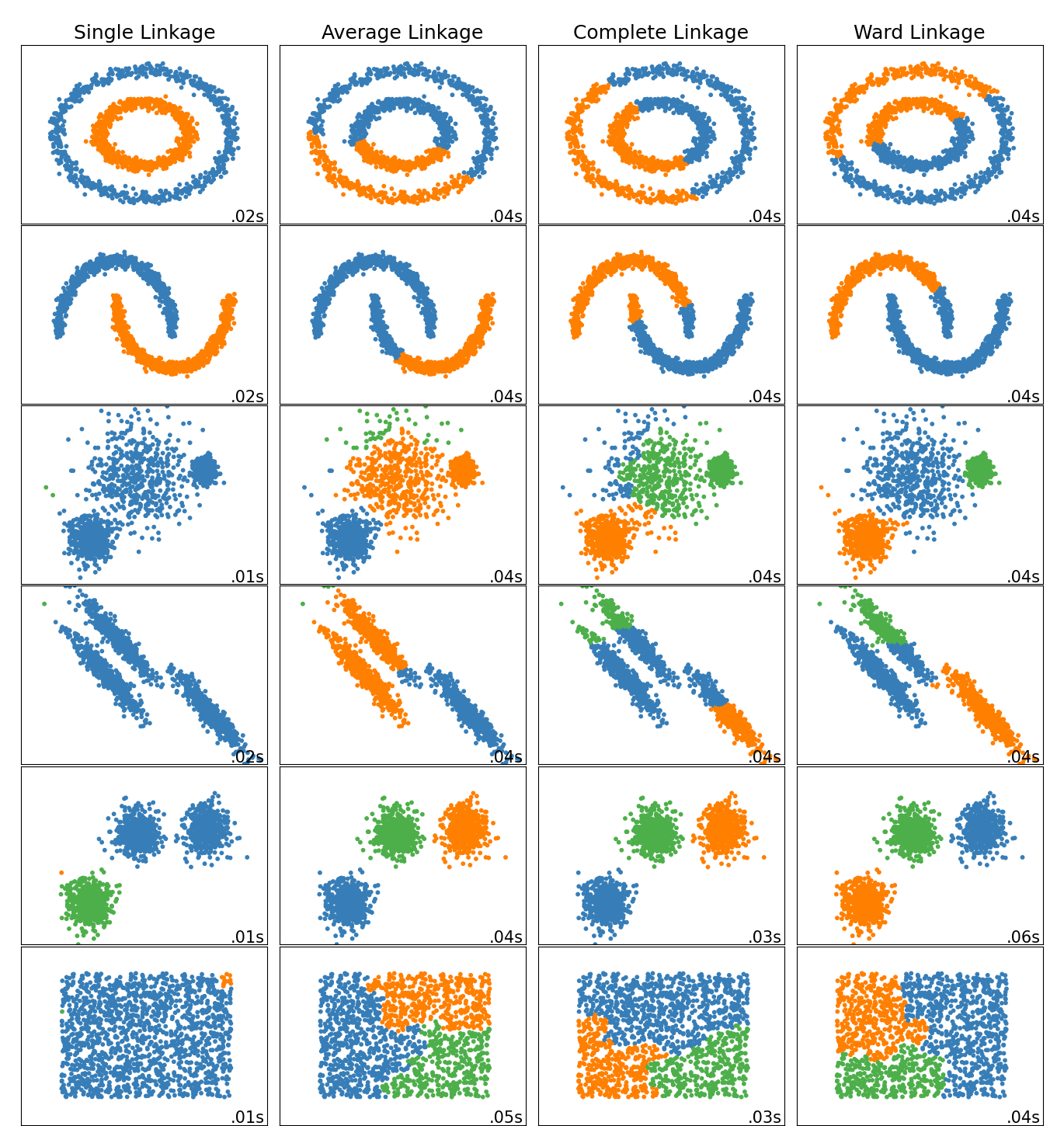
凝聚式分群具有「富者更富」的行為,這會導致群集大小不均。在這方面,單一連結是最糟糕的策略,而 Ward 給出最規則的大小。但是,親和性(或分群中使用的距離)無法與 Ward 一起改變,因此對於非歐幾里得度量,平均連結是一個很好的替代方案。單一連結雖然對雜訊資料不夠穩健,但可以非常有效率地計算,因此有助於提供較大資料集的階層式分群。單一連結在非球狀資料上也能表現良好。
範例
在數字的 2D 嵌入上進行各種凝聚式分群:探索真實資料集中不同的連結策略。
比較玩具資料集上不同的階層式連結方法:探索玩具資料集中不同的連結策略。
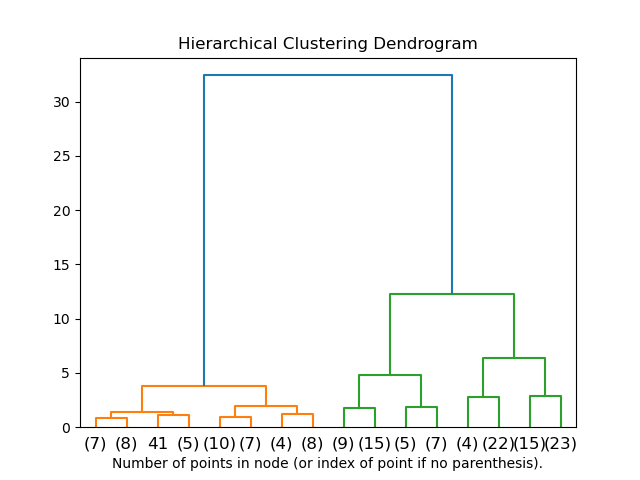
2.3.6.2. 群集階層的可視化#
可以將表示群集階層合併的樹狀結構視覺化為樹狀結構圖。視覺檢查通常有助於了解資料的結構,但在小樣本大小的情況下更是如此。
範例
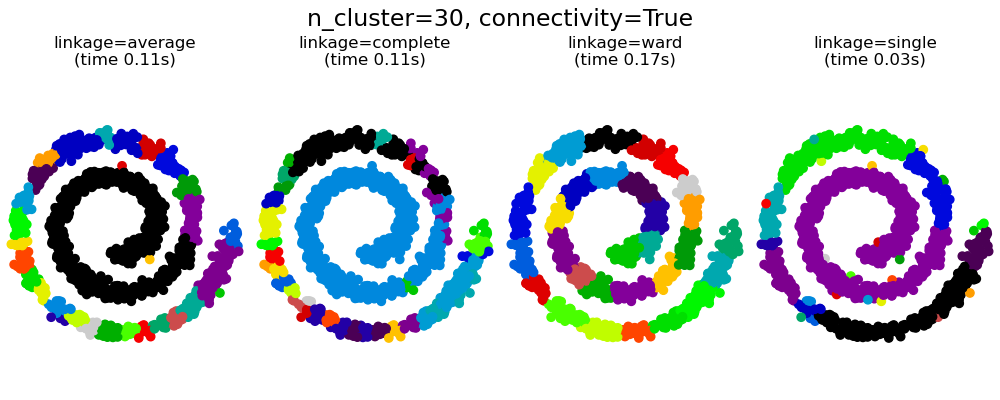
2.3.6.3. 新增連通性限制#
AgglomerativeClustering的一個有趣方面是,可以將連通性限制新增到此演算法(只能合併相鄰的群集),透過連通性矩陣來定義每個樣本的相鄰樣本,並遵循給定的資料結構。例如,在下面的 swiss-roll 範例中,連通性限制禁止合併在 swiss roll 上不相鄰的點,從而避免形成跨越 roll 重疊折疊的群集。
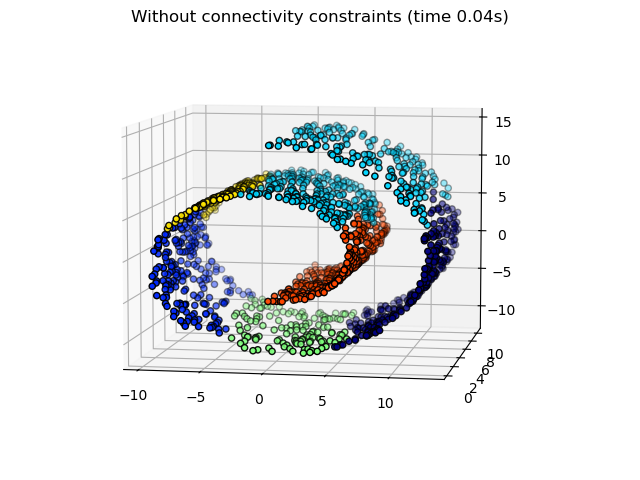
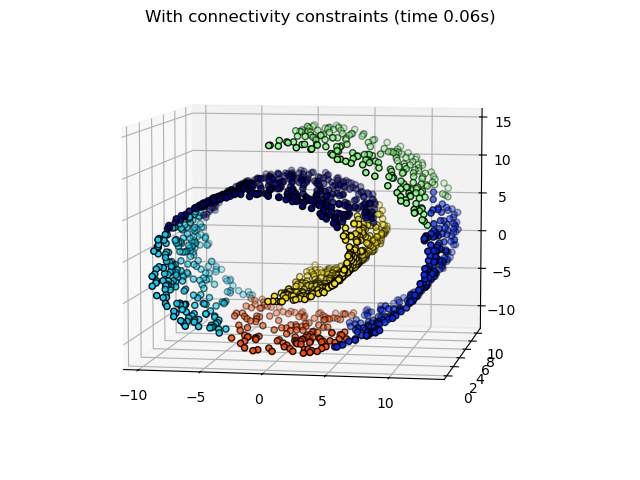
這些限制對於施加某些局部結構很有用,但它們也使演算法更快,尤其是在樣本數量較高時。
連通性限制透過連通性矩陣強制執行:一個 scipy 稀疏矩陣,其元素僅位於應連接的資料集的索引的行和列的交集處。此矩陣可以根據先驗資訊建構:例如,您可能希望僅合併具有從一個網頁指向另一個網頁的連結的網頁來將網頁分群。它也可以從資料中學習,例如使用sklearn.neighbors.kneighbors_graph來將合併限制為最鄰近的鄰居,如此範例中所示,或使用sklearn.feature_extraction.image.grid_to_graph來僅允許合併影像上相鄰的像素,如硬幣範例中所示。
警告
具有單一、平均和完整連結的連通性限制
連通性限制和單一、完整或平均連結可以增強凝聚式分群的「富者更富」方面,尤其是在它們是用sklearn.neighbors.kneighbors_graph建構時。在少數群集的限制下,它們傾向於給出幾個巨觀佔據的群集和幾乎空的群集。(請參閱具有和不具有結構的凝聚式分群中的討論)。單一連結是關於此問題最脆弱的連結選項。


範例
硬幣影像上結構化 Ward 階層式分群的示範:Ward 分群將硬幣影像分割為區域。
階層式分群:結構化與非結構化 Ward:swiss-roll 上 Ward 演算法的範例,比較結構化方法與非結構化方法。
特徵凝聚與單變量選擇:基於 Ward 階層式分群的特徵凝聚降維範例。
2.3.6.4. 變更度量#
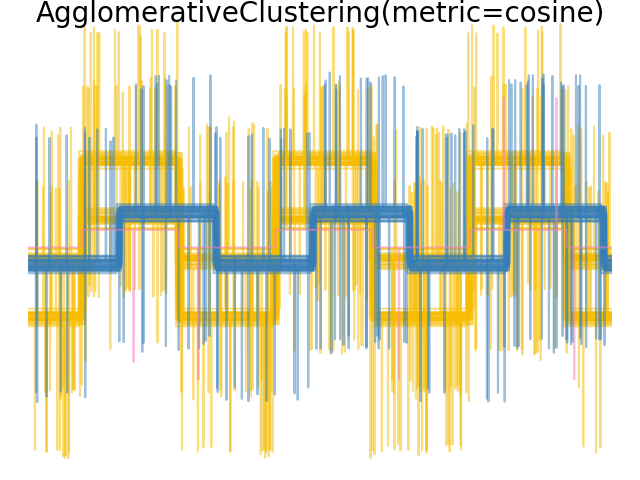
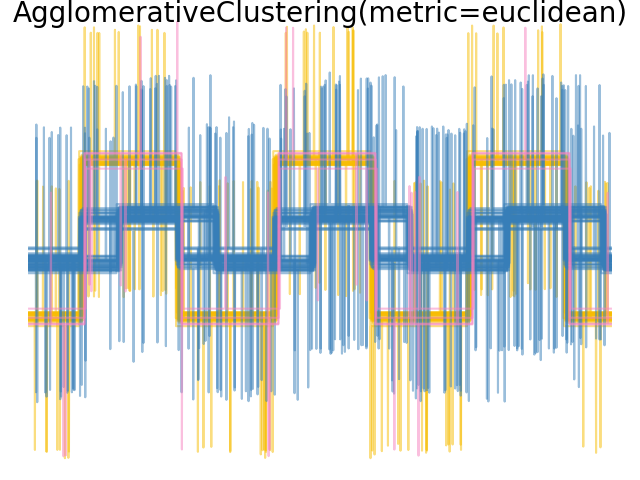
單一、平均和完整連結可以與各種距離(或親和性)一起使用,特別是歐幾里得距離(l2)、曼哈頓距離(或 Cityblock,或 l1)、餘弦距離或任何預先計算的親和性矩陣。
l1 距離通常適用於稀疏特徵或稀疏雜訊:也就是說,許多特徵為零,就像在使用罕見字詞的出現次數的文字探勘中一樣。
餘弦 距離很有趣,因為它對於訊號的全域縮放是不變的。
選擇度量的指南是使用一個最大化不同類別中樣本之間的距離,並最小化每個類別中的距離。
範例
2.3.6.5. 二分 K 平均數#
BisectingKMeans是KMeans的迭代變體,使用分裂階層式分群。不是一次建立所有質心,而是根據先前的分群逐步選取質心:將一個群集重複分割成兩個新群集,直到達到目標群集數量為止。
BisectingKMeans 在群集數量較多時,比 KMeans 更有效率,因為它在每次二分時僅處理資料的子集,而 KMeans 總是處理整個資料集。
雖然 BisectingKMeans 在設計上無法受益於 "k-means++" 初始化方法的優勢,但它在慣性(inertia)方面仍會產生與 KMeans(init="k-means++") 相近的結果,且計算成本更低,並且可能比使用隨機初始化的 KMeans 產生更好的結果。
如果群集數量相較於資料點數量較少,此變體在凝聚式群集(agglomerative clustering)中更有效率。
此變體也不會產生空的群集。
- 有兩種策略可供選擇要分割的群集:
bisecting_strategy="largest_cluster"選擇擁有最多點的群集。bisecting_strategy="biggest_inertia"選擇慣性最大的群集(群集內部平方誤差總和最大者)。
在大多數情況下,依據最大資料點數量選擇產生的結果與依據慣性選擇的結果一樣準確,且速度更快(尤其是在資料點數量較大的情況下,計算誤差可能會很耗費成本)。
依據最大資料點數量選擇也可能產生大小相似的群集,而 KMeans 則已知會產生大小不同的群集。
二分 K-Means 和一般 K-Means 之間的差異可以在範例 二分 K-Means 與一般 K-Means 效能比較 中看到。雖然一般 K-Means 演算法傾向於建立不相關的群集,但二分 K-Means 的群集則排序良好,並建立了相當明顯的層次結構。
參考文獻#
「文件群集技術比較」 Michael Steinbach, George Karypis 和 Vipin Kumar,明尼蘇達大學電腦科學與工程系(2000 年 6 月)
「Weblog 資料中 K-Means 和二分 K-Means 演算法的效能分析」 K.Abirami 和 Dr.P.Mayilvahanan,《國際工程技術新興期刊》(IJETER) 第 4 卷,第 8 期,(2016 年 8 月)
「基於 K 值自我決定和群集中心最佳化的二分 K-means 演算法」 Jian Di,Xinyue Gou,華北電力大學控制與電腦工程學院,中國河北保定(2017 年 8 月)
2.3.7. DBSCAN#
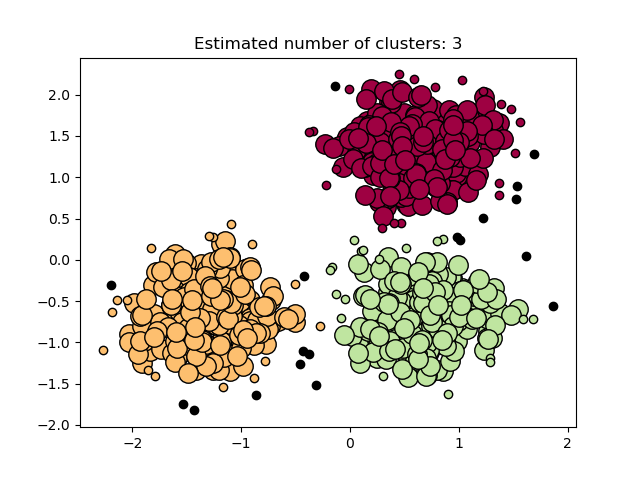
DBSCAN 演算法將群集視為高密度區域,並由低密度區域分隔。由於這種相當通用的觀點,DBSCAN 找到的群集可以是任何形狀,而不是 k-means 假設群集是凸形的。DBSCAN 的核心組件是 *核心樣本* 的概念,這些樣本位於高密度區域。因此,群集是一組彼此接近(以某種距離度量衡量)的核心樣本,以及一組接近核心樣本(但本身不是核心樣本)的非核心樣本。演算法有兩個參數,min_samples 和 eps,它們正式定義了我們所說的 *密集*。較高的 min_samples 或較低的 eps 表示形成群集所需的密度較高。
更正式地說,我們將核心樣本定義為資料集中存在 min_samples 個其他樣本,它們與該核心樣本的距離在 eps 範圍內,這些樣本被定義為核心樣本的 *鄰居*。這告訴我們核心樣本位於向量空間的密集區域中。群集是一組核心樣本,可以透過遞迴地取一個核心樣本、找到它所有身為核心樣本的鄰居、找到所有*它們*身為核心樣本的鄰居等等來建立。群集還有一組非核心樣本,這些樣本是群集中核心樣本的鄰居,但本身不是核心樣本。直觀地說,這些樣本位於群集的邊緣。
根據定義,任何核心樣本都是群集的一部分。任何不是核心樣本,且與任何核心樣本的距離至少為 eps 的樣本,都會被演算法視為離群值。
雖然參數 min_samples 主要控制演算法對雜訊的容忍度(在雜訊較多且資料集較大的情況下,增加此參數可能是可取的),但參數 eps *對於資料集和距離函數的適當選擇至關重要*,通常不能保留預設值。它控制點的局部鄰域。如果選擇太小,大多數資料將根本不會被群集(並被標記為 -1 表示「雜訊」)。如果選擇太大,則會導致接近的群集合併為一個群集,最終將整個資料集作為單一群集傳回。文獻中已討論過一些用於選擇此參數的啟發式方法,例如基於最近鄰距離圖中的拐點(如下列參考文獻中所討論)。
在下圖中,顏色表示群集成員資格,大圓圈表示演算法找到的核心樣本。較小的圓圈是仍屬於群集的非核心樣本。此外,離群值由下方的黑點表示。
範例
實作#
DBSCAN 演算法是確定性的,在給定相同順序的相同資料時,始終會產生相同的群集。但是,當以不同的順序提供資料時,結果可能會有所不同。首先,即使核心樣本始終會被分配到相同的群集,這些群集的標籤也會取決於在資料中遇到這些樣本的順序。其次,更重要的是,非核心樣本被分配到的群集可能會因資料順序而異。當非核心樣本與不同群集中的兩個核心樣本的距離低於 eps 時,就會發生這種情況。根據三角不等式,這兩個核心樣本之間的距離必須大於彼此的 eps,否則它們會在同一個群集中。非核心樣本會被分配給在資料傳遞中首先產生的群集,因此結果將取決於資料排序。
目前的實作使用球樹和 kd 樹來判斷點的鄰域,這避免了計算完整的距離矩陣(如 scikit-learn 0.14 之前的版本中所做的那樣)。保留了使用自訂指標的可能性;詳情請參閱 NearestNeighbors。
大型樣本大小的記憶體消耗#
預設情況下,此實作的記憶體效率不高,因為在無法使用 kd 樹或球樹的情況下(例如,使用稀疏矩陣),它會建構完整的成對相似性矩陣。此矩陣將消耗 \(n^2\) 個浮點數。有幾種方法可以解決這個問題:
將 OPTICS 群集與
extract_dbscan方法結合使用。OPTICS 群集也會計算完整的成對矩陣,但一次僅在記憶體中保留一行(記憶體複雜度為 n)。可以使用記憶體有效的方式預先計算稀疏半徑鄰域圖(其中遺失的條目被認為超出 eps 範圍),並且可以使用
metric='precomputed'在此圖上執行 dbscan。請參閱sklearn.neighbors.NearestNeighbors.radius_neighbors_graph。可以壓縮資料集,方法是移除資料中出現的完全重複項,或者使用 BIRCH。然後,您只需要一小部分代表來代表大量的點。然後,您可以在擬合 DBSCAN 時提供
sample_weight。
參考文獻#
用於在帶有雜訊的大型空間資料庫中發現叢集的基於密度的演算法 Ester, M., H. P. Kriegel, J. Sander, and X. Xu, 在 Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, pp. 226-231. 1996
重新探討 DBSCAN:為什麼以及如何(仍然)應該使用 DBSCAN。 Schubert, E., Sander, J., Ester, M., Kriegel, H. P., & Xu, X. (2017). 在 ACM Transactions on Database Systems (TODS), 42(3), 19.
2.3.8. HDBSCAN#
HDBSCAN 演算法可以被視為 DBSCAN 和 OPTICS 的擴展。具體來說,DBSCAN 假設叢集標準(即密度要求)是全局同質的。換句話說,DBSCAN 可能難以成功捕獲具有不同密度的叢集。HDBSCAN 減輕了這個假設,並通過建立叢集問題的替代表示來探索所有可能的密度尺度。
注意
此實作是基於 [LJ2017],改編自 HDBSCAN 的原始實作:scikit-learn-contrib/hdbscan。
範例
2.3.8.1. 相互可達性圖#
HDBSCAN 首先定義 \(d_c(x_p)\),樣本 \(x_p\) 的核心距離,作為到其 min_samples 個最近鄰的距離,包括自身。例如,如果 min_samples=5 且 \(x_*\) 是 \(x_p\) 的第 5 個最近鄰,則核心距離為
接下來,它定義 \(d_m(x_p, x_q)\),兩個點 \(x_p, x_q\) 的相互可達距離,如下所示
這兩個概念使我們能夠建構相互可達性圖 \(G_{ms}\),該圖針對 min_samples 的固定選擇而定義,方法是將每個樣本 \(x_p\) 與圖的頂點關聯,因此點 \(x_p, x_q\) 之間的邊是它們之間的相互可達距離 \(d_m(x_p, x_q)\)。我們可以通過移除任何值大於 \(\varepsilon\) 的邊來建立此圖的子集,表示為 \(G_{ms,\varepsilon}\):從原始圖中。任何核心距離小於 \(\varepsilon\) 的點:在這個階段被標記為雜訊。然後,通過找到這個修剪圖的連通分量來叢集剩餘的點。
注意
取修剪圖 \(G_{ms,\varepsilon}\) 的連通分量等同於使用 min_samples 和 \(\varepsilon\) 執行 DBSCAN*。DBSCAN* 是 [CM2013] 中提到的 DBSCAN 的略微修改版本。
2.3.8.2. 階層式叢集#
HDBSCAN 可以被看作是一種在所有 \(\varepsilon\) 值上執行 DBSCAN* 叢集的演算法。如前所述,這等同於找到所有 \(\varepsilon\) 值的相互可達性圖的連通分量。為了有效率地做到這一點,HDBSCAN 首先從完全連線的相互可達性圖中提取最小生成樹 (MST),然後貪婪地切割權重最高的邊。HDBSCAN 演算法的概述如下
提取 \(G_{ms}\) 的 MST。
通過為每個頂點添加一個「自邊」來擴展 MST,其權重等於基礎樣本的核心距離。
初始化 MST 的單個叢集和標籤。
從 MST 中移除權重最大的邊(同時移除連接)。
將叢集標籤指派給包含現在已移除邊的端點的連通分量。如果組件沒有至少一條邊,則會改為指派「空」標籤,將其標記為雜訊。
重複 4-5,直到沒有更多的連通分量為止。
因此,HDBSCAN 能夠以階層式方式獲得所有可能通過 DBSCAN* 實現的分區,以固定選擇的 min_samples 進行。事實上,這允許 HDBSCAN 跨多個密度執行叢集,因此它不再需要將 \(\varepsilon\) 作為超參數給定。相反,它僅依賴於 min_samples 的選擇,這往往是一個更穩健的超參數。
可以使用額外的超參數 min_cluster_size 來平滑 HDBSCAN,該參數指定在階層式叢集期間,樣本少於 minimum_cluster_size 的組件會被視為雜訊。在實務中,可以設定 minimum_cluster_size = min_samples 來耦合參數並簡化超參數空間。
參考文獻
Campello, R.J.G.B., Moulavi, D., Sander, J. (2013). 基於階層式密度估計的基於密度的叢集。在:Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G. (eds) 知識發現和資料探勘的進展。PAKDD 2013。計算機科學講義(),第 7819 卷。Springer, Berlin, Heidelberg. 基於階層式密度估計的基於密度的叢集
L. McInnes 和 J. Healy, (2017)。加速階層式基於密度的叢集。在:IEEE 國際資料探勘研討會 (ICDMW),2017,第 33-42 頁。加速階層式基於密度的叢集
2.3.9. OPTICS#
OPTICS 演算法與 DBSCAN 演算法有許多相似之處,並且可以被視為 DBSCAN 的廣義化,它將 eps 要求從單個值放寬到一個值範圍。DBSCAN 和 OPTICS 之間的主要區別在於 OPTICS 演算法會建立一個可達性圖,該圖會為每個樣本指派一個 reachability_ 距離,以及在叢集 ordering_ 屬性中的一個位置;這兩個屬性會在模型擬合時指派,並用於判斷叢集成員資格。如果 OPTICS 在 max_eps 設定為預設值 inf 的情況下執行,則可以使用 cluster_optics_dbscan 方法,針對任何給定的 eps 值,以線性時間重複執行 DBSCAN 風格的叢集提取。將 max_eps 設定為較低的值將導致較短的執行時間,並且可以將其視為從每個點尋找其他潛在可達點的最大鄰近半徑。
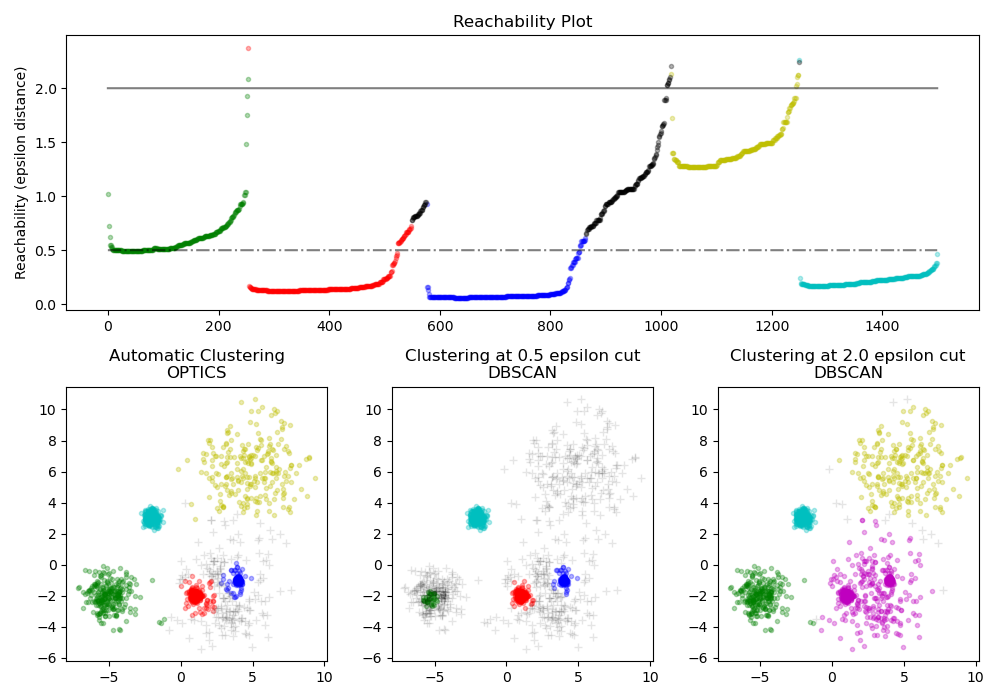
OPTICS 產生的可達性距離允許在單個數據集中變更叢集的密度提取。如上圖所示,結合可達性距離和數據集 ordering_ 會產生一個可達性圖,其中點密度表示在 Y 軸上,並且點的排序方式是附近的點相鄰。「切割」可達性圖中的單個值會產生類似 DBSCAN 的結果;所有高於「切割」的點都會被歸類為雜訊,並且每次從左到右讀取時出現斷裂時,都表示一個新的叢集。使用 OPTICS 的預設叢集提取會檢視圖中的陡峭斜率以尋找叢集,並且使用者可以使用參數 xi 定義什麼算是陡峭的斜率。對於圖本身還有其他分析的可能性,例如通過可達性圖狀圖生成數據的階層式表示,並且可以通過 cluster_hierarchy_ 參數訪問演算法偵測到的叢集層次結構。上面的圖表已進行顏色編碼,以便平面空間中的叢集顏色與可達性圖的線性區段叢集相符。請注意,藍色和紅色叢集在可達性圖中是相鄰的,並且可以階層式地表示為較大父叢集的子叢集。
範例
與 DBSCAN 的比較#
OPTICS 的 cluster_optics_dbscan 方法和 DBSCAN 的結果非常相似,但並非總是完全相同;特別是在周邊和雜訊點的標記上。這部分是因為 OPTICS 處理的每個密集區域的第一個樣本具有較大的可達性值,同時又靠近其區域中的其他點,因此有時會被標記為雜訊而不是周邊。當它們被視為標記為周邊或雜訊的候選點時,這會影響相鄰的點。
請注意,對於任何單個 eps 值,DBSCAN 的運行時間通常會比 OPTICS 短;但是,對於在不同 eps 值下重複運行,單次執行 OPTICS 可能比 DBSCAN 需要較少的累計運行時間。同樣重要的是要注意,只有當 eps 和 max_eps 相近時,OPTICS 的輸出才接近 DBSCAN 的輸出。
計算複雜度#
空間索引樹用於避免計算完整距離矩陣,並允許在大型樣本集上有效使用記憶體。可以通過 metric 關鍵字提供不同的距離度量。
對於大型數據集,可以通過 HDBSCAN 獲得相似(但不完全相同)的結果。HDBSCAN 實作是多執行緒的,並且比 OPTICS 具有更好的演算法執行時間複雜度,但代價是記憶體擴展性較差。對於使用 HDBSCAN 會耗盡系統記憶體的極大型數據集,OPTICS 將保持 \(n\) (而不是 \(n^2\))的記憶體擴展;但是,可能需要調整 max_eps 參數,才能在合理的實際時間內給出解決方案。
參考文獻#
“OPTICS: ordering points to identify the clustering structure.” Ankerst, Mihael, Markus M. Breunig, Hans-Peter Kriegel, and Jörg Sander. In ACM Sigmod Record, vol. 28, no. 2, pp. 49-60. ACM, 1999.
2.3.10. BIRCH#
Birch 為給定的資料建立一個名為叢集特徵樹(Clustering Feature Tree,CFT)的樹。資料基本上會被有損壓縮到一組叢集特徵節點(CF 節點)。CF 節點具有許多稱為叢集特徵子叢集(CF 子叢集)的子叢集,而位於非終端 CF 節點中的這些 CF 子叢集可以將 CF 節點作為子節點。
CF 子叢集保存叢集所需的資訊,從而避免將整個輸入資料保存在記憶體中。此資訊包括
子叢集中的樣本數。
線性總和 - 一個 n 維向量,保存所有樣本的總和
平方和 - 所有樣本的平方 L2 範數的總和。
質心 - 為避免重新計算線性總和 / n_samples。
質心的平方範數。
BIRCH 演算法有兩個參數:閾值和分支因子。分支因子限制節點中的子叢集數,而閾值限制輸入樣本與現有子叢集之間的距離。
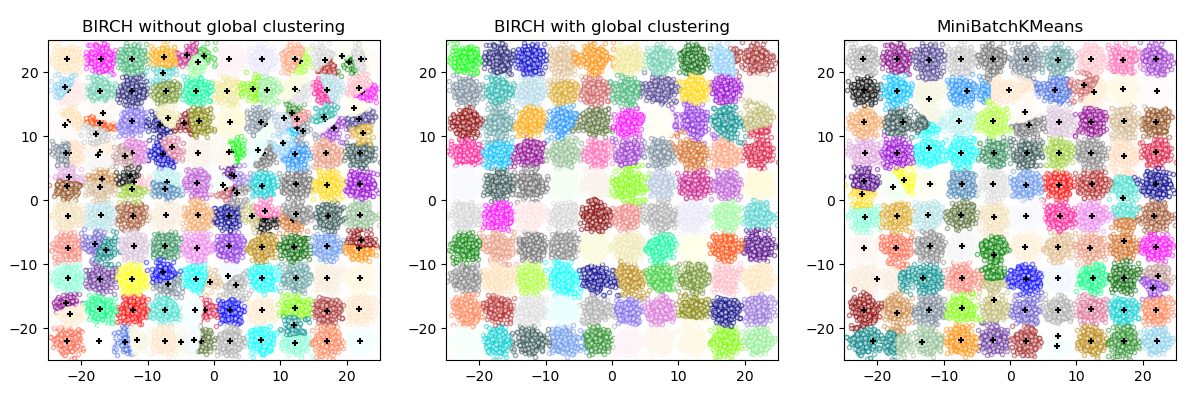
此演算法可以視為一個實例或資料縮減方法,因為它將輸入資料縮減為一組直接從 CFT 的葉子獲得的子叢集。此縮減的資料可以透過將其輸入到全域叢集器中來進一步處理。可以使用 n_clusters 設定此全域叢集器。如果將 n_clusters 設定為 None,則會直接讀取葉子中的子叢集,否則全域叢集步驟會將這些子叢集標記為全域叢集(標籤),並且樣本會映射到最近的子叢集的全域標籤。
演算法描述#
新樣本會插入到 CF 樹的根部,它是一個 CF 節點。然後,它會與根的子叢集合併,合併後半徑最小的子叢集,並受限於閾值和分支因子條件。如果子叢集有任何子節點,則會重複執行此操作,直到它到達葉子。在葉子中找到最近的子叢集後,會遞迴更新此子叢集和父子叢集的屬性。
如果合併新樣本和最近子叢集所獲得的子叢集半徑大於閾值的平方,並且如果子叢集數大於分支因子,則會暫時為此新樣本分配空間。會取出兩個最遠的子叢集,並根據這些子叢集之間的距離將子叢集分為兩組。
如果此分割節點具有父子叢集,並且有空間可容納新的子叢集,則會將父節點分割為兩個。如果沒有空間,則會將此節點再次分割為兩個,並遞迴地繼續此過程,直到它到達根。
BIRCH 或 MiniBatchKMeans?#
BIRCH 無法很好地擴展到高維資料。根據經驗,如果
n_features大於 20,則通常最好使用 MiniBatchKMeans。如果需要減少資料的實例數,或者如果希望有大量的子叢集(無論是作為預處理步驟還是其他方式),BIRCH 比 MiniBatchKMeans 更實用。
如何使用 partial_fit?#
為了避免計算全域叢集,建議使用者在每次呼叫 partial_fit 時執行以下操作
最初設定
n_clusters=None。透過多次呼叫 partial_fit 來訓練所有資料。
使用
brc.set_params(n_clusters=n_clusters)將n_clusters設定為所需的值。最後呼叫不帶任何引數的
partial_fit,即brc.partial_fit(),它會執行全域叢集。
參考文獻#
Tian Zhang, Raghu Ramakrishnan, Maron Livny BIRCH: An efficient data clustering method for large databases. https://www.cs.sfu.ca/CourseCentral/459/han/papers/zhang96.pdf
Roberto Perdisci JBirch - Java implementation of BIRCH clustering algorithm https://code.google.com/archive/p/jbirch
2.3.11. 叢集效能評估#
評估叢集演算法的效能並不像計算監督分類演算法的錯誤數或精確度和召回率那麼簡單。特別是,任何評估指標都不應考慮叢集標籤的絕對值,而是考慮此叢集是否定義了與某些基本事實類別集相似的資料分離,或者是否滿足某些假設,例如根據某些相似性度量,屬於同一類別的成員比屬於不同類別的成員更相似。
2.3.11.1. 蘭德指數#
在已知基本事實類別分配 labels_true 和我們對相同樣本的叢集演算法分配 labels_pred 的情況下,(調整或未調整)蘭德指數是一個函數,用於測量兩個分配的相似性,忽略排列
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.rand_score(labels_true, labels_pred)
0.66...
蘭德指數不能保證為隨機標記獲得接近 0.0 的值。調整後的蘭德指數會校正機率,並給出這樣的基準。
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24...
與所有叢集指標一樣,可以在預測的標籤中排列 0 和 1,將 2 重新命名為 3,並獲得相同的分數
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.rand_score(labels_true, labels_pred)
0.66...
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
0.24...
此外,rand_score adjusted_rand_score 都是對稱的:交換引數不會改變分數。因此,它們可以用作共識度量
>>> metrics.rand_score(labels_pred, labels_true)
0.66...
>>> metrics.adjusted_rand_score(labels_pred, labels_true)
0.24...
完美標記的分數為 1.0
>>> labels_pred = labels_true[:]
>>> metrics.rand_score(labels_true, labels_pred)
1.0
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
1.0
不一致的標籤(例如,獨立標記)的分數較低,並且對於調整後的蘭德指數,分數將為負或接近於零。但是,對於未調整的蘭德指數,分數雖然較低,但不一定接近於零。
>>> labels_true = [0, 0, 0, 0, 0, 0, 1, 1]
>>> labels_pred = [0, 1, 2, 3, 4, 5, 5, 6]
>>> metrics.rand_score(labels_true, labels_pred)
0.39...
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
-0.07...
範例
集群效能評估中針對機率的調整:分析資料集大小對隨機分配的集群度量值之影響。
數學公式#
如果 C 是真實類別分配,而 K 是集群,則讓我們定義 \(a\) 和 \(b\) 為
\(a\),C 中在同一集合中,且在 K 中在同一集合中的元素對數量
\(b\),C 中在不同集合中,且在 K 中在不同集合中的元素對數量
則未調整的蘭德指數由下式給出
其中 \(C_2^{n_{samples}}\) 是資料集中可能的配對總數。只要計算方式一致,則計算是在有序對還是無序對上執行並不重要。
然而,蘭德指數不能保證隨機標籤分配會得到接近零的值(尤其是當集群數量與樣本數量在同一個數量級時)。
為了抵消這種效應,我們可以藉由定義調整蘭德指數如下,來折算隨機標籤分配的預期 RI \(E[\text{RI}]\)
參考文獻#
比較分割 L. Hubert 和 P. Arabie, Journal of Classification 1985
Hubert-Arabie 調整蘭德指數的屬性 D. Steinley, Psychological Methods 2004
2.3.11.2. 基於互信息的評分#
在知道真實類別分配 labels_true 和我們相同的樣本 labels_pred 的集群演算法分配後,互信息是一個函數,用來測量兩個分配的一致性,忽略排列。此度量標準有兩個不同的標準化版本可用,標準化互信息 (NMI) 和調整互信息 (AMI)。NMI 經常在文獻中使用,而 AMI 是最近提出的,且是針對機率進行標準化
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504...
可以在預測標籤中排列 0 和 1,將 2 重新命名為 3,並得到相同的分數
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504...
所有 mutual_info_score、adjusted_mutual_info_score 和 normalized_mutual_info_score 都是對稱的:交換引數不會改變分數。因此,它們可以用作共識度量
>>> metrics.adjusted_mutual_info_score(labels_pred, labels_true)
0.22504...
完美標記的分數為 1.0
>>> labels_pred = labels_true[:]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
1.0
>>> metrics.normalized_mutual_info_score(labels_true, labels_pred)
1.0
mutual_info_score 並非如此,因此較難判斷
>>> metrics.mutual_info_score(labels_true, labels_pred)
0.69...
不佳的(例如,獨立的標籤分配)具有非正值的分數
>>> labels_true = [0, 1, 2, 0, 3, 4, 5, 1]
>>> labels_pred = [1, 1, 0, 0, 2, 2, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
-0.10526...
範例
集群效能評估中針對機率的調整:分析資料集大小對隨機分配的集群度量值之影響。此範例也包含調整蘭德指數。
數學公式#
假設兩個標籤分配(相同的 N 個物件),\(U\) 和 \(V\)。它們的熵是分割集合的不確定性量,定義為
其中 \(P(i) = |U_i| / N\) 是從 \(U\) 中隨機挑選的物件落入類別 \(U_i\) 的機率。對於 \(V\) 也是如此
其中 \(P'(j) = |V_j| / N\)。 \(U\) 和 \(V\) 之間的互信息 (MI) 計算如下
其中 \(P(i, j) = |U_i \cap V_j| / N\) 是從隨機選取的物件落入類別 \(U_i\) 和 \(V_j\) 的機率。
它也可以用集合基數公式表示
標準化互信息定義為
互信息的這個值以及標準化變體都沒有針對機率進行調整,並且隨著不同標籤(集群)數量的增加而趨於增加,而與標籤分配之間實際的「互信息」量無關。
可以使用以下方程式計算互信息的預期值 [VEB2009]。在此方程式中,\(a_i = |U_i|\) (\(U_i\) 中的元素數量),而 \(b_j = |V_j|\) (\(V_j\) 中的元素數量)。
使用期望值,調整後的互資訊可以使用類似調整後的蘭德指數的形式計算。
對於正規化的互資訊和調整後的互資訊,正規化值通常是每個叢集熵的某種廣義平均值。存在各種廣義平均值,並且沒有明確的規則來偏好其中一種。該決定很大程度上是基於領域的;例如,在社群檢測中,算術平均值是最常見的。每種正規化方法都提供「質性上相似的行為」[YAT2016]。在我們的實作中,這由 average_method 參數控制。
Vinh 等人 (2010) 以其平均方法命名了 NMI 和 AMI 的變體 [VEB2010]。他們的「sqrt」和「sum」平均值分別是幾何平均值和算術平均值;我們使用這些更廣泛通用的名稱。
參考文獻
Strehl, Alexander, 和 Joydeep Ghosh (2002)。「叢集集成 - 用於結合多個分割的知識重用框架」。機器學習研究期刊 3: 583-617。 doi:10.1162/153244303321897735。
Vinh、Epps 和 Bailey,(2009)。「用於叢集比較的資訊理論測量」。第 26 屆機器學習年度國際會議論文集 - ICML '09。 doi:10.1145/1553374.1553511。 ISBN 9781605585161。
Vinh、Epps 和 Bailey,(2010)。「用於叢集比較的資訊理論測量:變體、屬性、正規化和機會校正」。JMLR <https://jmlr.csail.mit.edu/papers/volume11/vinh10a/vinh10a.pdf>
Yang、Algesheimer 和 Tessone,(2016)。「人工網路社群檢測演算法的比較分析」。科學報告 6: 30750。 doi:10.1038/srep30750。
2.3.11.3. 同質性、完整性和 V 度量#
在知道樣本的真實類別分配的情況下,可以使用條件熵分析來定義一些直觀的度量。
特別是,Rosenberg 和 Hirschberg (2007) 為任何叢集分配定義了以下兩個理想的目標
同質性:每個叢集僅包含單個類別的成員。
完整性:給定類別的所有成員都被分配到同一個叢集。
我們可以將這些概念轉換為分數 homogeneity_score 和 completeness_score。兩者都以下限 0.0 和上限 1.0 為界(越高越好)。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.homogeneity_score(labels_true, labels_pred)
0.66...
>>> metrics.completeness_score(labels_true, labels_pred)
0.42...
它們的調和平均值稱為 V 度量,由 v_measure_score 計算。
>>> metrics.v_measure_score(labels_true, labels_pred)
0.51...
此函數的公式如下
beta 預設值為 1.0,但對於使用小於 1 的 beta 值
>>> metrics.v_measure_score(labels_true, labels_pred, beta=0.6)
0.54...
將更多權重歸因於同質性,並使用大於 1 的值
>>> metrics.v_measure_score(labels_true, labels_pred, beta=1.8)
0.48...
將更多權重歸因於完整性。
V 度量實際上等同於上面討論的互資訊 (NMI),其中聚合函數是算術平均值 [B2011]。
可以使用 homogeneity_completeness_v_measure 一次計算同質性、完整性和 V 度量,如下所示。
>>> metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)
(0.66..., 0.42..., 0.51...)
以下叢集分配稍微好一些,因為它是同質的但不完整。
>>> labels_pred = [0, 0, 0, 1, 2, 2]
>>> metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)
(1.0, 0.68..., 0.81...)
注意
v_measure_score 是對稱的:它可以用於評估同一個資料集上兩個獨立分配的一致性。
對於 completeness_score 和 homogeneity_score 則不是這樣:兩者都受限於以下關係
homogeneity_score(a, b) == completeness_score(b, a)
範例
集群效能評估中針對機率的調整:分析資料集大小對隨機分配的集群度量值之影響。
數學公式#
同質性和完整性分數正式表示為
其中 \(H(C|K)\) 是給定叢集分配的類別的條件熵,由以下公式給出
而 \(H(C)\) 是類別的熵,由以下公式給出
其中 \(n\) 是樣本總數,\(n_c\) 和 \(n_k\) 分別是屬於類別 \(c\) 和叢集 \(k\) 的樣本數,最後 \(n_{c,k}\) 是從類別 \(c\) 分配到叢集 \(k\) 的樣本數。
給定類別的叢集條件熵 \(H(K|C)\) 和叢集的熵 \(H(K)\) 以對稱方式定義。
Rosenberg 和 Hirschberg 進一步將 V 度量定義為同質性和完整性的調和平均值
參考文獻
V 度量:基於條件熵的外部叢集評估度量 Andrew Rosenberg 和 Julia Hirschberg,2007 年
社群媒體事件的識別和表徵,Hila Becker,博士論文。
2.3.11.4. Fowlkes-Mallows 分數#
原始的 Fowlkes-Mallows 指數 (FMI) 旨在衡量兩個叢集結果之間的相似性,這本質上是一種非監督式比較。當知道樣本的真實類別分配時,可以使用 Fowlkes-Mallows 指數的監督式改編(如在 sklearn.metrics.fowlkes_mallows_score 中實作)。FMI 定義為成對精確度和召回率的幾何平均值
在上面的公式中
TP(真正例):在真實標籤和預測標籤中都叢集在一起的點對數。FP(假正例):在預測標籤中叢集在一起但在真實標籤中沒有叢集在一起的點對數。FN(假負例):在真實標籤中叢集在一起但在預測標籤中沒有叢集在一起的點對數。
分數範圍從 0 到 1。高值表示兩個叢集之間的良好相似性。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
可以在預測標籤中排列 0 和 1,將 2 重新命名為 3,並得到相同的分數
>>> labels_pred = [1, 1, 0, 0, 3, 3]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.47140...
完美標記的分數為 1.0
>>> labels_pred = labels_true[:]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
1.0
較差的(例如獨立標記)分數為零。
>>> labels_true = [0, 1, 2, 0, 3, 4, 5, 1]
>>> labels_pred = [1, 1, 0, 0, 2, 2, 2, 2]
>>> metrics.fowlkes_mallows_score(labels_true, labels_pred)
0.0
參考文獻#
E. B. Fowkles 和 C. L. Mallows,1983。「一種比較兩個階層式群集的方法」。美國統計協會雜誌。https://www.tandfonline.com/doi/abs/10.1080/01621459.1983.10478008
2.3.11.5. 輪廓係數#
如果不知道真實標籤,則必須使用模型本身進行評估。輪廓係數(sklearn.metrics.silhouette_score)就是這種評估的一個例子,其中較高的輪廓係數分數表示模型具有更明確的群集。輪廓係數是針對每個樣本定義的,由兩個分數組成
a:樣本與同類中所有其他點之間的平均距離。
b:樣本與次近群集中所有其他點之間的平均距離。
然後,單個樣本的輪廓係數 s 給出如下
一組樣本的輪廓係數給出為每個樣本的輪廓係數的平均值。
>>> from sklearn import metrics
>>> from sklearn.metrics import pairwise_distances
>>> from sklearn import datasets
>>> X, y = datasets.load_iris(return_X_y=True)
在正常使用中,輪廓係數應用於群集分析的結果。
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.silhouette_score(X, labels, metric='euclidean')
0.55...
範例
使用 KMeans 群集上的輪廓分析選擇群集數量:在此範例中,輪廓分析用於選擇 n_clusters 的最佳值。
參考文獻#
Peter J. Rousseeuw (1987)。「輪廓:群集分析的解釋和驗證的圖形輔助工具」。計算和應用數學 20: 53-65。
2.3.11.6. 卡林斯基-哈拉巴茲指數#
如果不知道真實標籤,則可以使用卡林斯基-哈拉巴茲指數(sklearn.metrics.calinski_harabasz_score)(也稱為變異數比率準則)來評估模型,其中較高的卡林斯基-哈拉巴茲分數表示模型具有更明確的群集。
該指數是所有群集的群集間離散度和群集內離散度之和的比率(其中離散度定義為距離平方和)
>>> from sklearn import metrics
>>> from sklearn.metrics import pairwise_distances
>>> from sklearn import datasets
>>> X, y = datasets.load_iris(return_X_y=True)
在正常使用中,卡林斯基-哈拉巴茲指數應用於群集分析的結果
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.calinski_harabasz_score(X, labels)
561.59...
數學公式#
對於大小為 \(n_E\) 且已群集成 \(k\) 個群集的一組資料 \(E\),卡林斯基-哈拉巴茲分數 \(s\) 定義為群集間離散度均值與群集內離散度的比率
其中 \(\mathrm{tr}(B_k)\) 是群組間離散矩陣的跡,而 \(\mathrm{tr}(W_k)\) 是群集內離散矩陣的跡,定義為
其中 \(C_q\) 是群集 \(q\) 中的點集,\(c_q\) 是群集 \(q\) 的中心,\(c_E\) 是 \(E\) 的中心,而 \(n_q\) 是群集 \(q\) 中的點數。
參考文獻#
Caliński, T., & Harabasz, J. (1974)。「一種用於群集分析的樹突方法」。統計學理論與方法通訊 3: 1-27。
2.3.11.7. 戴維斯-博爾丁指數#
如果不知道真實標籤,則可以使用戴維斯-博爾丁指數(sklearn.metrics.davies_bouldin_score)來評估模型,其中較低的戴維斯-博爾丁指數表示群集之間具有更好的分離度的模型。
此指數表示群集之間的平均「相似度」,其中相似度是比較群集之間的距離與群集本身大小的度量。
零是最低可能的分數。接近零的值表示更好的分割。
在正常使用中,戴維斯-博爾丁指數按如下方式應用於群集分析的結果
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> X = iris.data
>>> from sklearn.cluster import KMeans
>>> from sklearn.metrics import davies_bouldin_score
>>> kmeans = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans.labels_
>>> davies_bouldin_score(X, labels)
0.666...
數學公式#
該指數定義為每個群集 \(C_i\)(對於 \(i=1, ..., k\))及其最相似群集 \(C_j\) 之間的平均相似度。在此指數的上下文中,相似度定義為一種度量 \(R_{ij}\),它會權衡
\(s_i\),群集 \(i\) 的每個點與該群集的質心之間的平均距離 – 也稱為群集直徑。
\(d_{ij}\),群集質心 \(i\) 和 \(j\) 之間的距離。
構建 \(R_{ij}\) 的一個簡單選擇是使它為非負且對稱,即
然後,戴維斯-博爾丁指數定義為
參考文獻#
Davies, David L.; Bouldin, Donald W. (1979)。「群集分離度量」。IEEE 模式分析和機器智慧彙刊。PAMI-1 (2): 224-227。
Halkidi, Maria; Batistakis, Yannis; Vazirgiannis, Michalis (2001)。「關於群集驗證技術」。智慧資訊系統雜誌,17(2-3), 107-145。
2.3.11.8. 列聯表#
列聯表(sklearn.metrics.cluster.contingency_matrix)會報告每個真實/預測集群配對的交集基數。對於樣本是獨立且同分布,且不需要考慮某些實例未被聚類的情況,列聯表為所有聚類指標提供了足夠的統計數據。
這是一個範例
>>> from sklearn.metrics.cluster import contingency_matrix
>>> x = ["a", "a", "a", "b", "b", "b"]
>>> y = [0, 0, 1, 1, 2, 2]
>>> contingency_matrix(x, y)
array([[2, 1, 0],
[0, 1, 2]])
輸出陣列的第一列表示有三個樣本的真實集群為「a」。其中,兩個在預測集群 0 中,一個在 1 中,沒有在 2 中。第二列表示有三個樣本的真實集群為「b」。其中,沒有在預測集群 0 中,一個在 1 中,兩個在 2 中。
分類的混淆矩陣是一個方形的列聯表,其中行和列的順序對應於類別列表。
參考文獻#
2.3.11.9. 成對混淆矩陣#
成對混淆矩陣(sklearn.metrics.cluster.pair_confusion_matrix)是一個 2x2 的相似度矩陣
藉由考慮所有樣本對,並計算在真實和預測的聚類下被分配到相同或不同集群中的樣本對,來計算兩個聚類之間的矩陣。
它具有以下條目
\(C_{00}\):兩個聚類都沒有將樣本聚在一起的樣本對數量
\(C_{10}\):真實標籤聚類將樣本聚在一起,但另一個聚類沒有將樣本聚在一起的樣本對數量
\(C_{01}\):真實標籤聚類沒有將樣本聚在一起,但另一個聚類將樣本聚在一起的樣本對數量
\(C_{11}\):兩個聚類都將樣本聚在一起的樣本對數量
如果將聚在一起的樣本對視為正對,那麼如同在二元分類中,真陰性的計數是 \(C_{00}\),假陰性是 \(C_{10}\),真陽性是 \(C_{11}\),假陽性是 \(C_{01}\)。
完全匹配的標籤會在對角線上具有所有非零的條目,無論實際標籤值為何
>>> from sklearn.metrics.cluster import pair_confusion_matrix
>>> pair_confusion_matrix([0, 0, 1, 1], [0, 0, 1, 1])
array([[8, 0],
[0, 4]])
>>> pair_confusion_matrix([0, 0, 1, 1], [1, 1, 0, 0])
array([[8, 0],
[0, 4]])
將所有類別成員分配到相同集群的標籤是完整的,但可能不總是純粹的,因此會受到懲罰,並且具有一些非對角的非零條目
>>> pair_confusion_matrix([0, 0, 1, 2], [0, 0, 1, 1])
array([[8, 2],
[0, 2]])
這個矩陣不是對稱的
>>> pair_confusion_matrix([0, 0, 1, 1], [0, 0, 1, 2])
array([[8, 0],
[2, 2]])
如果類別成員完全分散在不同的集群中,則分配是完全不完整的,因此矩陣在對角線上具有所有零條目
>>> pair_confusion_matrix([0, 0, 0, 0], [0, 1, 2, 3])
array([[ 0, 0],
[12, 0]])