1.10. 決策樹#
決策樹 (DTs) 是一種非參數的監督式學習方法,用於分類和迴歸。其目標是建立一個模型,透過學習從資料特徵推斷出的簡單決策規則,來預測目標變數的值。一棵樹可以被視為一個分段常數近似。
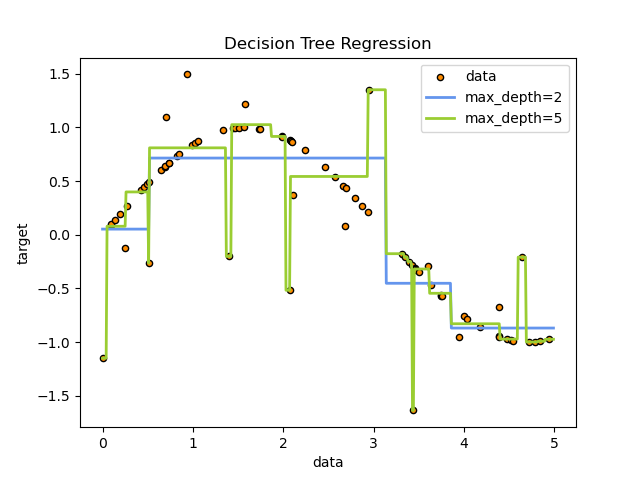
例如,在下面的範例中,決策樹從資料中學習,以一組 if-then-else 決策規則來近似正弦曲線。樹越深,決策規則越複雜,模型擬合度越高。
決策樹的一些優點是:
容易理解和解釋。樹可以被視覺化。
需要很少的資料準備。其他技術通常需要資料正規化,需要建立虛擬變數並移除空白值。某些樹和演算法組合支援遺失值。
使用樹的成本(即,預測資料)與用於訓練樹的資料點數量成對數關係。
能夠處理數值和類別資料。然而,scikit-learn 實作目前不支援類別變數。其他技術通常專門用於分析只有一種變數類型的資料集。請參閱演算法以獲取更多資訊。
能夠處理多輸出問題。
使用白箱模型。如果一個給定的情況在模型中是可觀察的,則該條件的解釋很容易用布林邏輯來解釋。相反,在黑箱模型(例如,在人工神經網路中),結果可能更難解釋。
可以使用統計測試驗證模型。這使得可以考慮模型的可靠性。
即使其假設在產生資料的真實模型中有些違背,也能表現良好。
決策樹的缺點包括:
決策樹學習器可能會建立過於複雜的樹,而無法很好地推廣資料。這稱為過擬合。諸如修剪、設定葉節點所需的最小樣本數或設定樹的最大深度等機制對於避免此問題是必要的。
決策樹可能不穩定,因為資料中的微小變化可能會導致產生完全不同的樹。使用集成中的決策樹可以減輕這個問題。
決策樹的預測既不平滑也不連續,而是如上圖所示的分段常數近似。因此,它們不擅長外推。
已知學習最佳決策樹的問題在最佳化的幾個方面,甚至是對於簡單的概念,都是 NP-完全的。因此,實際的決策樹學習演算法是基於啟發式演算法,例如貪婪演算法,其中在每個節點做出局部最佳決策。此類演算法無法保證返回全域最佳決策樹。這可以透過在集成學習器中訓練多棵樹來減輕,其中特徵和樣本是隨機採樣並替換的。
有些概念很難學習,因為決策樹不容易表達它們,例如 XOR、同位或多工器問題。
如果某些類別佔主導地位,決策樹學習器會建立有偏差的樹。因此,建議在用決策樹擬合之前平衡資料集。
1.10.1. 分類#
DecisionTreeClassifier是一個能夠在資料集上執行多類別分類的類別。
與其他分類器一樣,DecisionTreeClassifier將兩個陣列作為輸入:一個形狀為 (n_samples, n_features) 的稀疏或稠密陣列 X,包含訓練樣本,以及一個形狀為 (n_samples,) 的整數值陣列 Y,包含訓練樣本的類別標籤。
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
擬合後,該模型可用於預測樣本的類別。
>>> clf.predict([[2., 2.]])
array([1])
如果存在多個具有相同和最高機率的類別,則分類器將預測這些類別中索引最低的類別。
作為輸出特定類別的替代方法,可以預測每個類別的機率,這是葉節點中該類別的訓練樣本的比例。
>>> clf.predict_proba([[2., 2.]])
array([[0., 1.]])
DecisionTreeClassifier能夠進行二元(標籤為 [-1, 1])分類和多類別(標籤為 [0, …, K-1])分類。
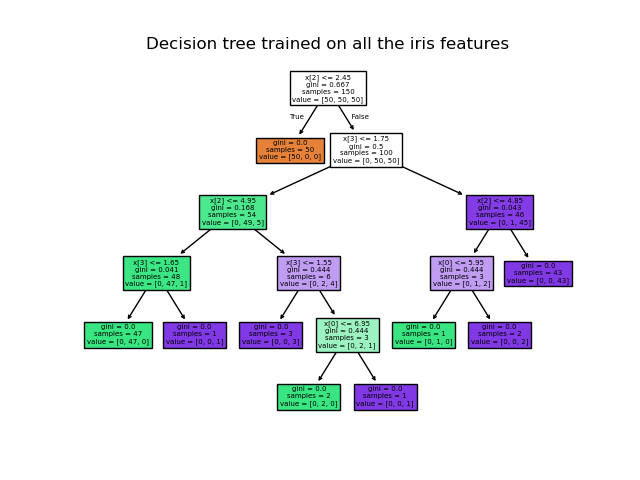
使用 Iris 資料集,我們可以按如下方式建構一棵樹。
>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, y)
訓練完成後,可以使用plot_tree函數繪製樹。
>>> tree.plot_tree(clf)
[...]
匯出樹的其他方式#
我們也可以使用export_graphviz匯出器以Graphviz格式匯出樹。如果您使用conda套件管理器,則可以使用 conda install python-graphviz 安裝 graphviz 二進位檔和 python 套件。
或者,可以從 graphviz 專案首頁下載 graphviz 的二進位檔,並使用 pip install graphviz 從 pypi 安裝 Python 包裝器。
以下是在整個虹膜資料集上訓練的上述樹的 graphviz 匯出範例;結果將儲存在輸出檔案 iris.pdf 中。
>>> import graphviz
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = graphviz.Source(dot_data)
>>> graph.render("iris")
export_graphviz匯出器還支援各種美學選項,包括按其類別(或迴歸的值)為節點著色,以及在需要時使用明確的變數和類別名稱。Jupyter 筆記本也會自動內嵌呈現這些圖。
>>> dot_data = tree.export_graphviz(clf, out_file=None,
... feature_names=iris.feature_names,
... class_names=iris.target_names,
... filled=True, rounded=True,
... special_characters=True)
>>> graph = graphviz.Source(dot_data)
>>> graph

或者,也可以使用函數export_text以文字格式匯出樹。此方法不需要安裝外部程式庫,並且更緊湊。
>>> from sklearn.datasets import load_iris
>>> from sklearn.tree import DecisionTreeClassifier
>>> from sklearn.tree import export_text
>>> iris = load_iris()
>>> decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2)
>>> decision_tree = decision_tree.fit(iris.data, iris.target)
>>> r = export_text(decision_tree, feature_names=iris['feature_names'])
>>> print(r)
|--- petal width (cm) <= 0.80
| |--- class: 0
|--- petal width (cm) > 0.80
| |--- petal width (cm) <= 1.75
| | |--- class: 1
| |--- petal width (cm) > 1.75
| | |--- class: 2
範例
1.10.2. 迴歸#
決策樹也可以使用DecisionTreeRegressor類別應用於迴歸問題。
如同在分類設定中,fit 方法會接收陣列 X 和 y 作為參數,只是在此情況下,y 預期會具有浮點數值而非整數值。
>>> from sklearn import tree
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> clf = tree.DecisionTreeRegressor()
>>> clf = clf.fit(X, y)
>>> clf.predict([[1, 1]])
array([0.5])
範例
1.10.3. 多輸出問題#
多輸出問題是一個監督式學習問題,其中有多個輸出需要預測,也就是當 Y 是一個形狀為 (n_samples, n_outputs) 的 2 維陣列時。
當輸出之間沒有相關性時,解決這類問題的一個非常簡單的方法是建立 n 個獨立的模型,也就是每個輸出一個模型,然後使用這些模型來獨立預測 n 個輸出中的每一個。然而,由於與相同輸入相關的輸出值本身很可能存在相關性,因此通常較好的方法是建立一個能夠同時預測所有 n 個輸出的單一模型。首先,它需要較少的訓練時間,因為只需要建立一個估計器。其次,所得估計器的泛化準確度通常可以提高。
對於決策樹而言,這種策略可以很容易地用於支援多輸出問題。這需要以下變更
在葉節點中儲存 n 個輸出值,而非 1 個;
使用計算所有 n 個輸出平均減少量的分割標準。
此模組透過在 DecisionTreeClassifier 和 DecisionTreeRegressor 中實作此策略來提供對多輸出問題的支援。如果決策樹是針對形狀為 (n_samples, n_outputs) 的輸出陣列 Y 進行擬合,則所得的估計器將
在
predict時輸出 n_output 個值;在
predict_proba時輸出 n_output 個類別機率陣列的列表。
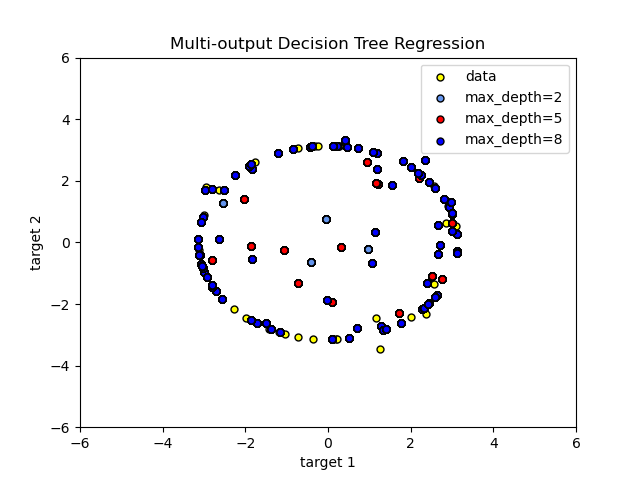
在 決策樹迴歸中展示了使用多輸出樹進行迴歸。在此範例中,輸入 X 是單一實數值,而輸出 Y 是 X 的正弦和餘弦值。
在 使用多輸出估計器的臉部補全中展示了使用多輸出樹進行分類。在此範例中,輸入 X 是臉部上半部的像素,而輸出 Y 是臉部下半部的像素。

範例
參考文獻
M. Dumont 等人,使用隨機子視窗和多輸出隨機樹的快速多類別影像註解,2009 年電腦視覺理論與應用國際會議
1.10.4. 複雜度#
一般而言,建構平衡二元樹的執行時間成本為 \(O(n_{samples}n_{features}\log(n_{samples}))\),而查詢時間為 \(O(\log(n_{samples}))\)。雖然樹狀結構建構演算法嘗試產生平衡的樹狀結構,但它們並非總是平衡的。假設子樹保持大致平衡,則每個節點的成本包括搜尋 \(O(n_{features})\) 以尋找可提供雜質標準(例如,對數損失(相當於資訊增益))最大減少的特徵。這在每個節點的成本為 \(O(n_{features}n_{samples}\log(n_{samples}))\),導致整個樹的總成本(透過將每個節點的成本加總)為 \(O(n_{features}n_{samples}^{2}\log(n_{samples}))\)。
1.10.5. 實際使用訣竅#
決策樹在具有大量特徵的資料上容易過度擬合。取得樣本數與特徵數的正確比例非常重要,因為在高維空間中具有少量樣本的樹很可能過度擬合。
了解決策樹結構將有助於深入了解決策樹如何進行預測,這對於了解資料中的重要特徵非常重要。
使用
export函式在訓練時視覺化您的樹。使用max_depth=3作為初始樹深度,以了解樹如何擬合您的資料,然後增加深度。請記住,樹的每個額外層級的樣本需求量都會增加一倍。使用
max_depth來控制樹的大小以防止過度擬合。使用
min_samples_split或min_samples_leaf來確保多個樣本在樹的每個決策中提供資訊,方法是控制將考慮哪些分割。非常小的數字通常意味著樹會過度擬合,而較大的數字會阻止樹學習資料。嘗試使用min_samples_leaf=5作為初始值。如果樣本大小差異很大,則可以在這兩個參數中使用浮點數作為百分比。雖然min_samples_split可以建立任意小的葉節點,但min_samples_leaf保證每個葉節點都具有最小大小,避免迴歸問題中出現低變異、過度擬合的葉節點。對於類別較少的分類,min_samples_leaf=1通常是最佳選擇。請注意,如果提供
sample_weight,則min_samples_split會直接且獨立於sample_weight來考慮樣本(例如,具有 m 個加權樣本的節點仍然被視為具有正好 m 個樣本)。如果需要在分割時考慮樣本權重,請考慮min_weight_fraction_leaf或min_impurity_decrease。在訓練之前平衡您的資料集,以防止樹偏向於佔優勢的類別。類別平衡可以透過從每個類別取樣相等數量的樣本來完成,或者最好透過將每個類別的樣本權重總和 (
sample_weight) 正規化為相同的值來完成。另請注意,基於權重的預修剪標準(例如min_weight_fraction_leaf)將比不了解樣本權重的標準(如min_samples_leaf)更不易偏向於佔優勢的類別。如果樣本是加權的,則使用基於權重的預修剪標準(例如
min_weight_fraction_leaf)來優化樹結構會更容易,這可確保葉節點至少包含樣本權重總和的一部分。所有決策樹在內部都使用
np.float32陣列。如果訓練資料不是這種格式,則會建立資料集的副本。如果輸入矩陣 X 非常稀疏,建議在呼叫 fit 之前轉換為稀疏
csc_matrix,並在呼叫 predict 之前轉換為稀疏csr_matrix。當特徵在大多數樣本中具有零值時,稀疏矩陣輸入的訓練時間可能比密集矩陣快數個數量級。
1.10.6. 樹狀結構演算法:ID3、C4.5、C5.0 和 CART#
所有各種決策樹演算法是什麼?它們彼此之間有何不同?scikit-learn 中實作的是哪一個?
各種決策樹演算法#
ID3 (Iterative Dichotomiser 3) 是 Ross Quinlan 在 1986 年開發的。此演算法會建立一個多向樹,針對每個節點(即以貪婪的方式)尋找將為類別目標產生最大資訊增益的類別特徵。樹會擴展到最大大小,然後通常會應用修剪步驟以提高樹狀結構泛化到未見資料的能力。
C4.5 是 ID3 的後繼者,透過動態定義一個離散屬性(基於數值變數)來分割連續屬性值為一組離散間隔,進而消除了特徵必須是類別的限制。C4.5 會將訓練好的樹(即 ID3 演算法的輸出)轉換為 if-then 規則集。然後評估每個規則的準確性,以決定它們應該被套用的順序。如果規則在沒有它的情況下提高了準確性,則透過移除規則的先決條件來進行修剪。
C5.0 是 Quinlan 在專有授權下發布的最新版本。它比 C4.5 使用更少的記憶體,並建立更小的規則集,同時更準確。
CART (Classification and Regression Trees) 與 C4.5 非常相似,但不同之處在於它支援數值目標變數(迴歸)並且不計算規則集。CART 使用在每個節點產生最大資訊增益的特徵和臨界值來建構二元樹。
scikit-learn 使用 CART 演算法的優化版本;但是,scikit-learn 實作目前不支援類別變數。
1.10.7. 數學公式#
給定訓練向量 \(x_i \in R^n\),i=1,…, l 和標籤向量 \(y \in R^l\),決策樹會遞迴地分割特徵空間,使得具有相同標籤或相似目標值的樣本會分組在一起。
令節點 \(m\) 的資料表示為 \(Q_m\),其中包含 \(n_m\) 個樣本。對於每個候選分割 \(\theta = (j, t_m)\),由特徵 \(j\) 和閾值 \(t_m\) 組成,將資料分割成 \(Q_m^{left}(\theta)\) 和 \(Q_m^{right}(\theta)\) 子集。
節點 \(m\) 的候選分割品質,使用雜質函數或損失函數 \(H()\) 來計算,函數的選擇取決於要解決的任務(分類或迴歸)。
選擇能最小化雜質的參數。
遞迴處理子集 \(Q_m^{left}(\theta^*)\) 和 \(Q_m^{right}(\theta^*)\),直到達到允許的最大深度、\(n_m < \min_{samples}\) 或 \(n_m = 1\)。
1.10.7.1. 分類準則#
如果目標是分類結果,取值為 0, 1, ..., K-1,對於節點 \(m\),令
為節點 \(m\) 中類別 k 的觀測值比例。如果 \(m\) 是終端節點,則此區域的 predict_proba 設定為 \(p_{mk}\)。常見的雜質度量如下。
吉尼係數(Gini)
對數損失或熵(Log Loss or Entropy)
香農熵#
熵準則計算可能類別的香農熵。它將到達給定葉節點 \(m\) 的訓練資料點的類別頻率作為其機率。將香農熵用作樹節點分割準則等同於最小化真實標籤 \(y_i\) 和樹模型 \(T\) 對於類別 \(k\) 的機率預測 \(T_k(x_i)\) 之間的對數損失(也稱為交叉熵和多項式偏差)。
為了說明這一點,首先回顧一下在資料集 \(D\) 上計算的樹模型 \(T\) 的對數損失定義如下:
其中 \(D\) 是包含 \(n\) 對 \((x_i, y_i)\) 的訓練資料集。
在分類樹中,葉節點內的預測類別機率是恆定的,也就是說:對於所有 \((x_i, y_i) \in Q_m\),對於每個類別 \(k\),都有:\(T_k(x_i) = p_{mk}\)。
此屬性使得可以將 \(\mathrm{LL}(D, T)\) 重寫為每個葉節點的香農熵總和,並根據到達每個葉節點的訓練資料點數量加權:
1.10.7.2. 迴歸準則#
如果目標是連續值,則對於節點 \(m\),常用的最小化準則來確定未來分割的位置是均方誤差(MSE 或 L2 誤差)、泊松偏差以及平均絕對誤差(MAE 或 L1 誤差)。MSE 和泊松偏差都將終端節點的預測值設定為節點的學習平均值 \(\bar{y}_m\),而 MAE 將終端節點的預測值設定為中位數 \(median(y)_m\)。
均方誤差(Mean Squared Error)
平均泊松偏差(Mean Poisson deviance)
如果你的目標是計數或頻率(每單位計數),則設定 criterion="poisson" 可能是一個不錯的選擇。在任何情況下,\(y >= 0\) 是使用此準則的必要條件。請注意,它的擬合速度比 MSE 準則慢得多。出於效能考量,實際實現會最小化一半的平均泊松偏差,即平均泊松偏差除以 2。
平均絕對誤差(Mean Absolute Error)
請注意,它的擬合速度比 MSE 準則慢得多。
1.10.8. 遺失值支援#
DecisionTreeClassifier 和 DecisionTreeRegressor 使用 splitter='best' 內建支援遺失值,其中分割是以貪婪方式決定。ExtraTreeClassifier 和 ExtraTreeRegressor 對於 splitter='random' 內建支援遺失值,其中分割是隨機決定。有關分割器在非遺失值上的差異的更多詳細資訊,請參閱森林章節。
當存在遺失值時,支援的準則是分類的 'gini'、'entropy’ 或 'log_loss',或迴歸的 'squared_error'、'friedman_mse' 或 'poisson'。
首先,我們將描述 DecisionTreeClassifier 和 DecisionTreeRegressor 如何處理資料中的遺失值。
對於非遺失資料上的每個潛在閾值,分割器將評估所有遺失值都前往左節點或右節點的分割。
決策制定如下:
預設情況下,在預測時,遺失值的樣本會以訓練期間找到的分割中使用的類別進行分類。
>>> from sklearn.tree import DecisionTreeClassifier >>> import numpy as np >>> X = np.array([0, 1, 6, np.nan]).reshape(-1, 1) >>> y = [0, 0, 1, 1] >>> tree = DecisionTreeClassifier(random_state=0).fit(X, y) >>> tree.predict(X) array([0, 0, 1, 1])
如果兩個節點的準則評估都相同,則在預測時,遺失值的平手將透過前往右節點來打破。分割器還會檢查所有遺失值前往一個子節點,而非遺失值前往另一個子節點的分割。
>>> from sklearn.tree import DecisionTreeClassifier >>> import numpy as np >>> X = np.array([np.nan, -1, np.nan, 1]).reshape(-1, 1) >>> y = [0, 0, 1, 1] >>> tree = DecisionTreeClassifier(random_state=0).fit(X, y) >>> X_test = np.array([np.nan]).reshape(-1, 1) >>> tree.predict(X_test) array([1])
如果在訓練期間,給定特徵沒有看到遺失值,則在預測期間,遺失值會被映射到樣本最多的子節點。
>>> from sklearn.tree import DecisionTreeClassifier >>> import numpy as np >>> X = np.array([0, 1, 2, 3]).reshape(-1, 1) >>> y = [0, 1, 1, 1] >>> tree = DecisionTreeClassifier(random_state=0).fit(X, y) >>> X_test = np.array([np.nan]).reshape(-1, 1) >>> tree.predict(X_test) array([1])
ExtraTreeClassifier 和 ExtraTreeRegressor 以稍微不同的方式處理遺失值。分割節點時,將選擇隨機閾值來分割非遺失值。然後,非遺失值將根據隨機選擇的閾值發送到左子節點和右子節點,而遺失值也會隨機發送到左子節點或右子節點。針對每次分割考慮的每個特徵都會重複此操作。選擇其中最佳的分割。
在預測期間,遺失值的處理方式與決策樹相同。
預設情況下,在預測時,遺失值的樣本會以訓練期間找到的分割中使用的類別進行分類。
如果在訓練期間,給定特徵沒有看到遺失值,則在預測期間,遺失值會被映射到樣本最多的子節點。
1.10.9. 最小成本複雜度剪枝#
最小成本複雜度剪枝是一種用於修剪樹以避免過度擬合的演算法,在[BRE]的第 3 章中描述。此演算法由稱為複雜度參數的 \(\alpha\ge0\) 參數化。複雜度參數用於定義給定樹 \(T\) 的成本複雜度度量 \(R_\alpha(T)\):
其中 \(|\widetilde{T}|\) 是 \(T\) 中終端節點的數量,而 \(R(T)\) 傳統上定義為終端節點的總誤分類率。或者,scikit-learn 使用終端節點的總樣本加權不純度來計算 \(R(T)\)。如上所示,節點的不純度取決於準則。最小成本複雜度修剪法會找出 \(T\) 的子樹,使其能夠最小化 \(R_\alpha(T)\)。
單一節點的成本複雜度度量為 \(R_\alpha(t)=R(t)+\alpha\)。分支 \(T_t\) 定義為以節點 \(t\) 為根的樹。一般來說,節點的不純度大於其終端節點的不純度之和,即 \(R(T_t)<R(t)\)。然而,節點 \(t\) 及其分支 \(T_t\) 的成本複雜度度量可能會相等,具體取決於 \(\alpha\)。我們定義節點的有效 \(\alpha\) 為它們相等的數值,即 \(R_\alpha(T_t)=R_\alpha(t)\) 或 \(\alpha_{eff}(t)=\frac{R(t)-R(T_t)}{|T|-1}\)。具有最小 \(\alpha_{eff}\) 值的非終端節點是最弱的環節,將被修剪。當修剪後的樹的最小 \(\alpha_{eff}\) 大於 ccp_alpha 參數時,此過程停止。
範例
參考文獻
L. Breiman, J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Wadsworth, Belmont, CA, 1984.
J.R. Quinlan. C4. 5: programs for machine learning. Morgan Kaufmann, 1993.
T. Hastie, R. Tibshirani and J. Friedman. Elements of Statistical Learning, Springer, 2009.