1.12. 多類別與多輸出演算法#
本使用者指南章節涵蓋與多重學習問題相關的功能,包括多類別、多標籤,以及多輸出分類和迴歸。
本章節中的模組實作了元估計器,這些估計器需要在其建構函式中提供一個基本估計器。元估計器擴展了基本估計器的功能以支援多重學習問題,這是透過將多重學習問題轉換為一組更簡單的問題,然後為每個問題擬合一個估計器來實現的。
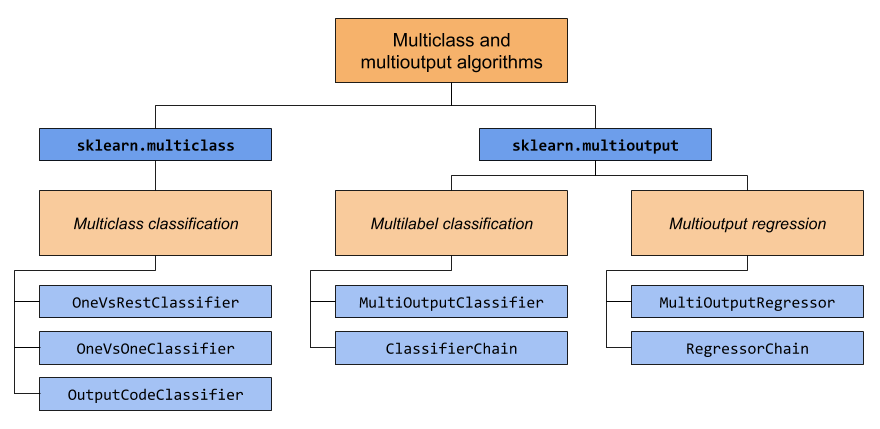
本節涵蓋兩個模組:sklearn.multiclass 和 sklearn.multioutput。下圖展示了每個模組負責的問題類型,以及每個模組提供的對應元估計器。
下表提供了問題類型之間差異的快速參考。更詳細的說明可以在本指南的後續章節中找到。
目標數量 |
目標基數 |
有效的 |
|
|---|---|---|---|
多類別分類 |
1 |
>2 |
‘multiclass’ |
多標籤分類 |
>1 |
2(0 或 1) |
‘multilabel-indicator’ |
多類別-多輸出分類 |
>1 |
>2 |
‘multiclass-multioutput’ |
多輸出迴歸 |
>1 |
連續 |
‘continuous-multioutput’ |
以下是 scikit-learn 具有內建多重學習支援的估計器摘要,按策略分組。如果您正在使用這些估計器之一,則不需要本節提供的元估計器。但是,元估計器可以提供超出內建功能的其他策略
固有地多類別
svm.LinearSVC(設定 multi_class=”crammer_singer”)linear_model.LogisticRegression(使用大多數求解器)linear_model.LogisticRegressionCV(使用大多數求解器)
多類別作為一對一
gaussian_process.GaussianProcessClassifier(設定 multi_class = “one_vs_one”)
多類別作為一對其餘
gaussian_process.GaussianProcessClassifier(設定 multi_class = “one_vs_rest”)svm.LinearSVC(設定 multi_class=”ovr”)linear_model.LogisticRegression(大多數求解器)
支援多標籤
支援多類別-多輸出
1.12.1. 多類別分類#
警告
scikit-learn 中的所有分類器都可直接進行多類別分類。除非您想嘗試不同的多類別策略,否則不需要使用 sklearn.multiclass 模組。
多類別分類是具有兩個以上類別的分類任務。每個樣本只能被標記為一個類別。
例如,使用從一組水果圖像中提取的特徵進行分類,其中每個圖像可能是橘子、蘋果或梨子。每個圖像都是一個樣本,並被標記為 3 個可能類別之一。多類別分類假設每個樣本只被分配到一個標籤 - 例如,一個樣本不能同時是梨子和蘋果。
雖然所有 scikit-learn 分類器都具備多類別分類的能力,但 sklearn.multiclass 提供的元估計器允許改變它們處理兩個以上類別的方式,因為這可能會影響分類器的效能(無論是在泛化誤差或所需的計算資源方面)。
1.12.1.1. 目標格式#
用於 type_of_target (y) 的有效多類別表示形式為
包含兩個以上離散值的一維或列向量。4 個樣本的向量
y的範例>>> import numpy as np >>> y = np.array(['apple', 'pear', 'apple', 'orange']) >>> print(y) ['apple' 'pear' 'apple' 'orange']
形狀為
(n_samples, n_classes)的稠密或稀疏 二元矩陣,其中每列代表一個類別,每行代表一個樣本。4 個樣本的稠密和稀疏 二元矩陣y的範例,其中各列依序為蘋果、橘子和梨子>>> import numpy as np >>> from sklearn.preprocessing import LabelBinarizer >>> y = np.array(['apple', 'pear', 'apple', 'orange']) >>> y_dense = LabelBinarizer().fit_transform(y) >>> print(y_dense) [[1 0 0] [0 0 1] [1 0 0] [0 1 0]] >>> from scipy import sparse >>> y_sparse = sparse.csr_matrix(y_dense) >>> print(y_sparse) <Compressed Sparse Row sparse matrix of dtype 'int64' with 4 stored elements and shape (4, 3)> Coords Values (0, 0) 1 (1, 2) 1 (2, 0) 1 (3, 1) 1
有關 LabelBinarizer 的更多資訊,請參閱轉換預測目標 (y)。
1.12.1.2. OneVsRestClassifier#
一對其餘策略,也稱為一對全部,在 OneVsRestClassifier 中實作。該策略包含為每個類別擬合一個分類器。對於每個分類器,該類別會與所有其他類別進行擬合。除了其計算效率(僅需要 n_classes 個分類器)外,這種方法的一個優點是其可解釋性。由於每個類別都由一個且僅一個分類器表示,因此可以透過檢查其對應的分類器來獲得關於該類別的知識。這是最常用的策略,並且是合理的預設選擇。
以下是使用 OvR 進行多類別學習的範例
>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsRestClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
OneVsRestClassifier 也支援多標籤分類。要使用此功能,請將指示矩陣饋入分類器,其中儲存格 [i, j] 指示樣本 i 中是否存在標籤 j。
範例
1.12.1.3. OneVsOneClassifier#
OneVsOneClassifier 為每對類別建立一個分類器。在預測時,會選擇獲得最多票數的類別。如果出現平局(兩個類別的票數相同),它會選擇透過對底層二元分類器計算的成對分類信賴度級別求和,來獲得最高總體分類信賴度的類別。
由於它需要擬合 n_classes * (n_classes - 1) / 2 個分類器,因此由於其 O(n_classes^2) 的複雜度,此方法通常比一對多的方法慢。然而,對於像核心演算法這種無法隨 n_samples 很好地擴展的演算法,此方法可能很有利。這是因為每個單獨的學習問題只涉及數據的一小部分子集,而使用一對多的方法,則會 n_classes 次使用完整數據集。決策函數是一對一分類的單調轉換結果。
以下是使用 OvO 進行多類別學習的範例
>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsOneClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsOneClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
參考文獻
“Pattern Recognition and Machine Learning. Springer”, Christopher M. Bishop, 第 183 頁, (第一版)
1.12.1.4. OutputCodeClassifier#
基於錯誤校正輸出碼的策略與一對多和一對一的方法截然不同。透過這些策略,每個類別都以歐幾里得空間表示,其中每個維度只能為 0 或 1。換句話說,每個類別都由二元碼(0 和 1 的陣列)表示。追蹤每個類別的位置/碼的矩陣稱為程式碼簿。程式碼大小是上述空間的維度。直觀上,每個類別都應由盡可能唯一的程式碼表示,並且應設計良好的程式碼簿來最佳化分類準確性。在此實作中,我們僅使用 [3] 中提倡的隨機產生程式碼簿,儘管未來可能會新增更精細的方法。
在擬合時,會擬合程式碼簿中每個位元一個二元分類器。在預測時,會使用分類器將新點投影到類別空間中,並選擇最接近這些點的類別。
在 OutputCodeClassifier 中,code_size 屬性允許使用者控制將使用的分類器數量。它是類別總數的百分比。
介於 0 和 1 之間的值將需要比一對多更少的分類器。理論上,log2(n_classes) / n_classes 足以明確表示每個類別。然而,實際上,它可能無法帶來良好的準確性,因為 log2(n_classes) 比 n_classes 小得多。
大於 1 的值將需要比一對多更多的分類器。在這種情況下,理論上某些分類器會校正其他分類器所犯的錯誤,因此得名「錯誤校正」。然而,實際上,這可能不會發生,因為分類器錯誤通常會相互關聯。錯誤校正輸出碼具有與裝袋類似的效果。
以下是使用輸出碼進行多類別學習的範例
>>> from sklearn import datasets
>>> from sklearn.multiclass import OutputCodeClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> clf = OutputCodeClassifier(LinearSVC(random_state=0), code_size=2, random_state=0)
>>> clf.fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 2, 2, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
參考文獻
“Solving multiclass learning problems via error-correcting output codes”, Dietterich T., Bakiri G., Journal of Artificial Intelligence Research 2, 1995.
“The Elements of Statistical Learning”, Hastie T., Tibshirani R., Friedman J., 第 606 頁 (第二版), 2008.
1.12.2. 多標籤分類#
多標籤分類(與多輸出分類密切相關)是一種分類任務,使用 n_classes 個可能的類別中的 m 個標籤標記每個樣本,其中 m 可以是 0 到 n_classes(含)。這可以被認為是預測樣本的不互斥屬性。形式上,會為每個樣本的每個類別指派一個二元輸出。正類別以 1 表示,負類別以 0 或 -1 表示。因此,它相當於執行 n_classes 個二元分類任務,例如使用 MultiOutputClassifier。這種方法會獨立處理每個標籤,而多標籤分類器可能會同時處理多個類別,考慮它們之間的相關行為。
例如,預測與文字文件或影片相關的主題。文件或影片可能是關於「宗教」、「政治」、「金融」或「教育」其中之一、多個主題類別或所有主題類別。
1.12.2.1. 目標格式#
有效的 多標籤 y 表示法是形狀為 (n_samples, n_classes) 的密集或稀疏 二元 矩陣。每列代表一個類別。每列中的 1 表示樣本已標記的正類別。適用於 3 個樣本的密集矩陣 y 的範例
>>> y = np.array([[1, 0, 0, 1], [0, 0, 1, 1], [0, 0, 0, 0]])
>>> print(y)
[[1 0 0 1]
[0 0 1 1]
[0 0 0 0]]
也可以使用 MultiLabelBinarizer 建立密集二元矩陣。如需更多資訊,請參閱 轉換預測目標 (y)。
以稀疏矩陣形式表示的相同 y 的範例
>>> y_sparse = sparse.csr_matrix(y)
>>> print(y_sparse)
<Compressed Sparse Row sparse matrix of dtype 'int64'
with 4 stored elements and shape (3, 4)>
Coords Values
(0, 0) 1
(0, 3) 1
(1, 2) 1
(1, 3) 1
1.12.2.2. MultiOutputClassifier#
可以使用 MultiOutputClassifier 將多標籤分類支援新增到任何分類器。此策略包括針對每個目標擬合一個分類器。這允許進行多個目標變數分類。此類別的目的是擴展估計器,使其能夠估計一系列目標函數 (f1,f2,f3…,fn),這些目標函數在單個 X 預測矩陣上進行訓練,以預測一系列回應 (y1,y2,y3…,yn)。
您可以在 多類別-多輸出分類 部分找到 MultiOutputClassifier 的使用範例,因為它是將多標籤分類廣泛化到多類別輸出(而不是二元輸出)。
1.12.2.3. ClassifierChain#
分類器鏈 (請參閱 ClassifierChain) 是一種將多個二元分類器組合到單個多標籤模型中的方法,該模型能夠利用目標之間的相關性。
對於具有 N 個類別的多標籤分類問題,會將 0 到 N-1 之間的整數指派給 N 個二元分類器。這些整數定義了鏈中模型的順序。然後在可用的訓練數據以及模型已指派較低編號的類別的真實標籤上擬合每個分類器。
在預測時,真實標籤將不可用。而是將每個模型的預測傳遞到鏈中的後續模型,以用作特徵。
顯然,鏈的順序很重要。鏈中的第一個模型沒有關於其他標籤的資訊,而鏈中的最後一個模型則具有指示所有其他標籤存在情況的特徵。一般來說,人們不知道鏈中模型的最佳順序,因此通常會擬合許多隨機排序的鏈,並將它們的預測平均在一起。
參考文獻
Jesse Read, Bernhard Pfahringer, Geoff Holmes, Eibe Frank, “Classifier Chains for Multi-label Classification”, 2009.
1.12.3. 多類別-多輸出分類#
多類別-多輸出分類(也稱為多任務分類)是一種分類任務,它使用一組非二元屬性標記每個樣本。每個屬性的屬性數量和類別數量都大於 2。因此,單個估計器處理多個聯合分類任務。這既是多標籤分類任務的廣泛化,後者僅考慮二元屬性,也是多類別分類任務的廣泛化,其中僅考慮一個屬性。
例如,對一組水果圖像的「水果類型」和「顏色」屬性進行分類。「水果類型」屬性具有可能的類別:「蘋果」、「梨子」和「橘子」。「顏色」屬性具有可能的類別:「綠色」、「紅色」、「黃色」和「橘色」。每個樣本都是一個水果的圖像,會針對兩個屬性輸出一個標籤,並且每個標籤都是相應屬性的可能類別之一。
請注意,所有處理多類別-多輸出(也稱為多任務分類)任務的分類器都支援多標籤分類任務作為特例。多任務分類類似於具有不同模型公式的多輸出分類任務。如需更多資訊,請參閱相關的估計器文件。
以下是多類別-多輸出分類的範例
>>> from sklearn.datasets import make_classification
>>> from sklearn.multioutput import MultiOutputClassifier
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.utils import shuffle
>>> import numpy as np
>>> X, y1 = make_classification(n_samples=10, n_features=100,
... n_informative=30, n_classes=3,
... random_state=1)
>>> y2 = shuffle(y1, random_state=1)
>>> y3 = shuffle(y1, random_state=2)
>>> Y = np.vstack((y1, y2, y3)).T
>>> n_samples, n_features = X.shape # 10,100
>>> n_outputs = Y.shape[1] # 3
>>> n_classes = 3
>>> forest = RandomForestClassifier(random_state=1)
>>> multi_target_forest = MultiOutputClassifier(forest, n_jobs=2)
>>> multi_target_forest.fit(X, Y).predict(X)
array([[2, 2, 0],
[1, 2, 1],
[2, 1, 0],
[0, 0, 2],
[0, 2, 1],
[0, 0, 2],
[1, 1, 0],
[1, 1, 1],
[0, 0, 2],
[2, 0, 0]])
警告
目前,sklearn.metrics 中沒有指標支援多類別-多輸出分類任務。
1.12.3.1. 目標格式#
一個有效的 多輸出 (multioutput) y 表示法是一個形狀為 (n_samples, n_classes) 的類別標籤密集矩陣。它是 1 維 多類別 (multiclass) 變數的逐欄串聯。以下是一個具有 3 個樣本的 y 範例。
>>> y = np.array([['apple', 'green'], ['orange', 'orange'], ['pear', 'green']])
>>> print(y)
[['apple' 'green']
['orange' 'orange']
['pear' 'green']]
1.12.4. 多輸出迴歸#
多輸出迴歸 (Multioutput regression) 預測每個樣本的多個數值屬性。每個屬性都是一個數值變數,且每個樣本要預測的屬性數量大於或等於 2。有些支援多輸出迴歸的估計器比僅運行 n_output 個估計器更快。
例如,使用在特定地點取得的數據,預測風速和風向(以度為單位)。每個樣本是在一個地點取得的數據,而每個樣本都會輸出風速和風向。
以下迴歸器原生支援多輸出迴歸:
1.12.4.1. 目標格式#
一個有效的 多輸出 (multioutput) y 表示法是一個形狀為 (n_samples, n_output) 的浮點數密集矩陣。它是 連續 (continuous) 變數的逐欄串聯。以下是一個具有 3 個樣本的 y 範例。
>>> y = np.array([[31.4, 94], [40.5, 109], [25.0, 30]])
>>> print(y)
[[ 31.4 94. ]
[ 40.5 109. ]
[ 25. 30. ]]
1.12.4.2. MultiOutputRegressor#
可以使用 MultiOutputRegressor 將多輸出迴歸支援新增到任何迴歸器。此策略包括為每個目標擬合一個迴歸器。由於每個目標都由一個迴歸器精確地表示,因此可以透過檢查其對應的迴歸器來獲取關於目標的知識。由於 MultiOutputRegressor 為每個目標擬合一個迴歸器,因此它無法利用目標之間的相關性。
以下是一個多輸出迴歸的範例:
>>> from sklearn.datasets import make_regression
>>> from sklearn.multioutput import MultiOutputRegressor
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_regression(n_samples=10, n_targets=3, random_state=1)
>>> MultiOutputRegressor(GradientBoostingRegressor(random_state=0)).fit(X, y).predict(X)
array([[-154.75474165, -147.03498585, -50.03812219],
[ 7.12165031, 5.12914884, -81.46081961],
[-187.8948621 , -100.44373091, 13.88978285],
[-141.62745778, 95.02891072, -191.48204257],
[ 97.03260883, 165.34867495, 139.52003279],
[ 123.92529176, 21.25719016, -7.84253 ],
[-122.25193977, -85.16443186, -107.12274212],
[ -30.170388 , -94.80956739, 12.16979946],
[ 140.72667194, 176.50941682, -17.50447799],
[ 149.37967282, -81.15699552, -5.72850319]])
1.12.4.3. RegressorChain#
迴歸器鏈(參見 RegressorChain)類似於 ClassifierChain,是一種將多個迴歸組合到單一多目標模型中的方法,能夠利用目標之間的相關性。