3.2. 調整估算器的超參數#
超參數是估算器中未直接學習的參數。在 scikit-learn 中,它們作為引數傳遞給估算器類別的建構函式。典型的例子包括支援向量分類器的 C、kernel 和 gamma,Lasso 的 alpha 等。
建議且可能搜尋超參數空間以獲得最佳的交叉驗證分數。
在建構估算器時提供的任何參數都可以透過這種方式進行最佳化。具體來說,要尋找給定估算器的所有參數的名稱和目前值,請使用
estimator.get_params()
搜尋包括
一個估算器(迴歸器或分類器,例如
sklearn.svm.SVC());一個參數空間;
一種搜尋或取樣候選物件的方法;
一個交叉驗證方案;以及
一個評分函數。
scikit-learn 中提供了兩種通用的參數搜尋方法:對於給定的值,GridSearchCV 會詳盡地考慮所有參數組合,而RandomizedSearchCV可以從具有指定分佈的參數空間中取樣給定數量的候選物件。這兩種工具都有連續減半的對應工具HalvingGridSearchCV和HalvingRandomSearchCV,它們在尋找良好的參數組合時速度會快得多。
在描述這些工具之後,我們將詳細說明適用於這些方法的最佳實踐。某些模型允許專用的高效參數搜尋策略,詳述於暴力參數搜尋的替代方法中。
請注意,通常這些參數的一小部分可能會對模型的預測或計算效能產生很大影響,而其他參數可以保留為其預設值。建議閱讀估算器類別的 docstring 以更深入了解其預期行為,或者閱讀所附的文獻參考。
3.2.1. 詳盡網格搜尋#
GridSearchCV提供的網格搜尋會從使用 param_grid 參數指定的參數值網格中詳盡地產生候選物件。例如,以下 param_grid
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
指定應探索兩個網格:一個具有線性核心和 C 值在 [1, 10, 100, 1000] 中,另一個具有 RBF 核心,以及 C 值在 [1, 10, 100, 1000] 和 gamma 值在 [0.001, 0.0001] 中範圍內的交叉乘積。
GridSearchCV 執行個體實作了常用的估算器 API:當在資料集上「擬合」時,會評估參數值的所有可能組合,並保留最佳組合。
範例
有關在 iris 資料集上的交叉驗證迴圈內進行網格搜尋的範例,請參閱巢狀與非巢狀交叉驗證。這是使用網格搜尋評估模型效能的最佳實踐。
有關將文字文件特徵提取器(n-gram 計數向量器和 TF-IDF 轉換器)中的參數與分類器(此處為使用 SGD 訓練且帶有彈性網路或 L2 懲罰的線性 SVM)耦合的網格搜尋範例,請參閱文字特徵提取和評估的範例管線,使用
Pipeline執行個體。
進階範例#
有關在 iris 資料集上的交叉驗證迴圈內進行網格搜尋的範例,請參閱巢狀與非巢狀交叉驗證。這是使用網格搜尋評估模型效能的最佳實踐。
有關使用
GridSearchCV同時評估多個指標的範例,請參閱跨驗證和 GridSearchCV 上多指標評估的示範。有關在
GridSearchCV中使用refit=callable介面的範例,請參閱平衡模型複雜度和交叉驗證分數。該範例顯示此介面如何在識別「最佳」估算器時增加一定的彈性。此介面也可以用於多指標評估。有關如何在
GridSearchCV的輸出上進行統計比較的範例,請參閱使用網格搜尋對模型進行統計比較。
3.2.2. 隨機參數最佳化#
雖然使用參數設定網格是目前最廣泛使用的參數最佳化方法,但其他搜尋方法具有更佳的特性。RandomizedSearchCV 實作了對參數的隨機搜尋,其中每個設定都是從可能的參數值的分佈中取樣的。與詳盡搜尋相比,這有兩個主要好處
可以選擇獨立於參數數量和可能值的預算。
新增不影響效能的參數不會降低效率。
指定如何取樣參數是使用字典完成的,這與指定 GridSearchCV 的參數非常相似。此外,還可以使用 n_iter 參數指定計算預算,即取樣候選者的數量或取樣迭代次數。對於每個參數,可以指定可能值的分布或離散選擇的列表(將均勻取樣)。
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}
此範例使用 scipy.stats 模組,其中包含許多用於取樣參數的有用分布,例如 expon、gamma、uniform、loguniform 或 randint。
原則上,可以傳入任何提供 rvs(隨機變數取樣)方法來取樣值。呼叫 rvs 函數應在連續呼叫時提供來自可能參數值的獨立隨機樣本。
警告
在 scipy 0.16 版本之前的 scipy.stats 中的分布不允許指定隨機狀態。相反,它們使用全域 numpy 隨機狀態,該狀態可以透過 np.random.seed 設定種子,或者使用 np.random.set_state 設定。但是,從 scikit-learn 0.18 開始,如果 scipy >= 0.16 也可用,則 sklearn.model_selection 模組會設定使用者提供的隨機狀態。
對於連續參數,例如上面的 C,指定連續分布以充分利用隨機化非常重要。這樣,增加 n_iter 將始終導致更精細的搜尋。
連續對數均勻隨機變數是對數間隔參數的連續版本。例如,要指定與上面 C 等效的參數,可以使用 loguniform(1, 100) 而不是 [1, 10, 100]。
與網格搜尋中的上述範例類似,我們可以指定一個連續隨機變數,該變數在 1e0 和 1e3 之間呈對數均勻分布。
from sklearn.utils.fixes import loguniform
{'C': loguniform(1e0, 1e3),
'gamma': loguniform(1e-4, 1e-3),
'kernel': ['rbf'],
'class_weight':['balanced', None]}
範例
比較隨機搜尋和網格搜尋以進行超參數估計 比較了隨機搜尋和網格搜尋的使用方式和效率。
參考文獻
Bergstra, J. 和 Bengio, Y., Random search for hyper-parameter optimization, The Journal of Machine Learning Research (2012)
3.2.3. 使用連續減半搜尋最佳參數#
Scikit-learn 也提供了 HalvingGridSearchCV 和 HalvingRandomSearchCV 估算器,它們可用於使用連續減半來搜尋參數空間 [1] [2]。連續減半 (SH) 就像候選參數組合之間的競賽。SH 是一個迭代選擇過程,其中所有候選者(參數組合)在第一次迭代時都使用少量資源進行評估。只有其中一些候選者會被選中進行下一次迭代,下一次迭代將分配更多資源。對於參數調整,資源通常是訓練樣本的數量,但也可能是一個任意數值參數,例如隨機森林中的 n_estimators。
注意
選擇的資源增加幅度應該足夠大,以便在考慮統計顯著性時獲得分數的顯著改善。
如下圖所示,只有一小部分候選者「存活」到最後一次迭代。這些候選者在所有迭代中始終在得分最高的候選者中名列前茅。每次迭代都會為每個候選者分配越來越多的資源,這裡指的是樣本數。
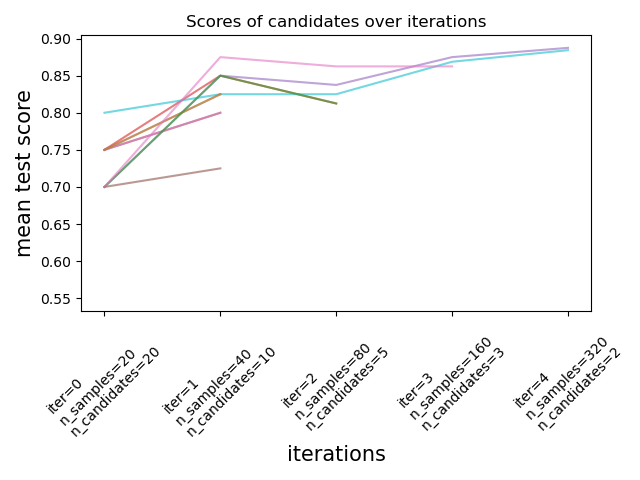
我們在這裡簡要描述主要參數,但每個參數及其交互作用在下面的下拉選單部分中會有更詳細的描述。factor (> 1) 參數控制資源增長的速度,以及候選者數量減少的速度。在每次迭代中,每個候選者的資源數量乘以 factor,候選者數量除以相同的因子。與 resource 和 min_resources 一起,factor 是控制我們實作中搜尋的最重要參數,儘管值為 3 通常效果很好。factor 有效控制 HalvingGridSearchCV 中的迭代次數,以及 HalvingRandomSearchCV 中的候選者數量(預設值)和迭代次數。如果可用資源數量很少,也可以使用 aggressive_elimination=True。透過調整 min_resources 參數可以獲得更多控制。
這些估算器仍然是實驗性的:它們的預測和 API 可能會在沒有任何棄用週期的情况下發生變化。要使用它們,您需要明確匯入 enable_halving_search_cv
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> from sklearn.model_selection import HalvingRandomSearchCV
範例
以下各節深入探討了連續減半的技術方面。
選擇 min_resources 和候選者數量#
除了 factor 之外,影響連續減半搜尋行為的兩個主要參數是 min_resources 參數,以及評估的候選者(或參數組合)數量。min_resources 是在第一次迭代時為每個候選者分配的資源量。候選者數量直接在 HalvingRandomSearchCV 中指定,並從 HalvingGridSearchCV 的 param_grid 參數中確定。
考慮一個資源是樣本數量的案例,其中我們有 1000 個樣本。理論上,如果 min_resources=10 和 factor=2,我們最多可以使用以下樣本數運行 7 次迭代:[10, 20, 40, 80, 160, 320, 640]。
但是,根據候選者的數量,我們可能運行的迭代次數少於 7 次:如果我們從少量的候選者開始,最後一次迭代可能會使用少於 640 個樣本,這意味著沒有使用所有可用的資源(樣本)。例如,如果我們從 5 個候選者開始,我們只需要 2 次迭代:第一次迭代有 5 個候選者,然後第二次迭代有 5 // 2 = 2 個候選者,之後我們知道哪個候選者表現最好(因此我們不需要第三個)。我們最多只會使用 20 個樣本,這是一種浪費,因為我們有 1000 個樣本可用。另一方面,如果我們從大量的候選者開始,我們可能最終會在最後一次迭代中出現許多候選者,這可能並不總是理想的:這意味著許多候選者將使用所有資源運行,基本上將該過程簡化為標準搜尋。
在 HalvingRandomSearchCV 的情況下,候選者數量預設設定為使最後一次迭代盡可能多地使用可用資源。對於 HalvingGridSearchCV,候選者數量由 param_grid 參數決定。變更 min_resources 的值會影響可能的迭代次數,因此也會影響理想的候選者數量。
選擇 min_resources 時的另一個考慮因素是,是否容易使用少量資源區分好壞候選者。例如,如果您需要大量樣本才能區分好壞參數,建議使用較高的 min_resources。另一方面,如果即使使用少量樣本也能清楚地區分,那麼較小的 min_resources 可能更可取,因為它會加快計算速度。
請注意上面的範例,最後一次迭代並未使用所有可用的資源:雖然有 1000 個樣本可用,但最多只使用了 640 個。預設情況下,HalvingRandomSearchCV 和 HalvingGridSearchCV 都會嘗試在最後一次迭代中使用盡可能多的資源,但前提是資源量必須是 min_resources 和 factor 的倍數(此限制將在下一節中說明)。HalvingRandomSearchCV 會透過採樣正確數量的候選者來實現這一點,而 HalvingGridSearchCV 則透過正確設定 min_resources 來實現。
每次迭代的資源量和候選者數量#
在任何迭代 i 中,每個候選者都會被分配一定的資源量,我們將其表示為 n_resources_i。此數量由參數 factor 和 min_resources 控制,如下所示(factor 嚴格大於 1):
n_resources_i = factor**i * min_resources,
或等效地
n_resources_{i+1} = n_resources_i * factor
其中 min_resources == n_resources_0 是第一次迭代使用的資源量。factor 也定義了將被選入下一次迭代的候選者比例:
n_candidates_i = n_candidates // (factor ** i)
或等效地
n_candidates_0 = n_candidates
n_candidates_{i+1} = n_candidates_i // factor
因此,在第一次迭代中,我們使用 min_resources 資源 n_candidates 次。在第二次迭代中,我們使用 min_resources * factor 資源 n_candidates // factor 次。第三次再次增加每個候選者的資源,並減少候選者數量。當每個候選者達到最大資源量,或當我們識別出最佳候選者時,此過程停止。最佳候選者是在評估 factor 或更少候選者的迭代中識別出來的(請參閱下文的說明)。
以下是一個範例,其中 min_resources=3 且 factor=2,從 70 個候選者開始:
|
|
|---|---|
3 (=min_resources) |
70 (=n_candidates) |
3 * 2 = 6 |
70 // 2 = 35 |
6 * 2 = 12 |
35 // 2 = 17 |
12 * 2 = 24 |
17 // 2 = 8 |
24 * 2 = 48 |
8 // 2 = 4 |
48 * 2 = 96 |
4 // 2 = 2 |
我們可以注意到:
該過程在評估
factor=2個候選者的第一次迭代時停止:最佳候選者是這 2 個候選者中的最佳者。沒有必要執行額外的迭代,因為它只會評估一個候選者(即我們已經識別出的最佳候選者)。因此,一般而言,我們希望最後一次迭代最多運行factor個候選者。如果最後一次迭代評估的候選者多於factor個,那麼最後一次迭代會簡化為常規搜尋(如RandomizedSearchCV或GridSearchCV)。每個
n_resources_i都是factor和min_resources的倍數(其定義如上所述)。
每次迭代使用的資源量可以在 n_resources_ 屬性中找到。
選擇資源#
預設情況下,資源是根據樣本數定義的。也就是說,每次迭代都會使用越來越多的樣本進行訓練。但是,您可以使用 resource 參數手動指定一個參數作為資源。以下是一個範例,其中資源是根據隨機森林的估計器數量定義的:
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid = {'max_depth': [3, 5, 10],
... 'min_samples_split': [2, 5, 10]}
>>> base_estimator = RandomForestClassifier(random_state=0)
>>> X, y = make_classification(n_samples=1000, random_state=0)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, resource='n_estimators',
... max_resources=30).fit(X, y)
>>> sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)
請注意,不能將參數網格中的參數作為預算。
耗盡可用資源#
如上所述,每次迭代使用的資源數量取決於 min_resources 參數。如果您有大量可用資源,但從少量資源開始,則可能會浪費一些資源(即未使用)。
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid= {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources=20).fit(X, y)
>>> sh.n_resources_
[20, 40, 80]
搜尋過程最多只會使用 80 個資源,而我們的最大可用資源量是 n_samples=1000。在這裡,我們有 min_resources = r_0 = 20。
對於 HalvingGridSearchCV,預設情況下,min_resources 參數設定為「exhaust」。這表示 min_resources 會自動設定,以便最後一次迭代可以在 max_resources 限制內使用盡可能多的資源。
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources='exhaust').fit(X, y)
>>> sh.n_resources_
[250, 500, 1000]
此處的 min_resources 會自動設定為 250,這使得最後一次迭代可以使用所有資源。使用的確切值取決於候選參數的數量、max_resources 和 factor。
對於 HalvingRandomSearchCV,可以透過 2 種方式耗盡資源:
就像
HalvingGridSearchCV一樣,設定min_resources='exhaust';設定
n_candidates='exhaust'。
這兩種選項是互斥的:使用 min_resources='exhaust' 需要知道候選者的數量,相對地,n_candidates='exhaust' 需要知道 min_resources。
一般而言,耗盡總資源數量會產生更好的最終候選參數,並且稍微耗時。
3.2.3.1. 積極淘汰候選者#
使用 aggressive_elimination 參數,您可以強制搜尋過程在最後一次迭代中以少於 factor 個候選者結束。
積極淘汰的程式碼範例#
理想情況下,我們希望最後一次迭代評估 factor 個候選者。然後我們只需要選擇最佳的一個。當可用資源數量相對於候選者數量較少時,最後一次迭代可能必須評估多於 factor 個候選者。
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid = {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, max_resources=40,
... aggressive_elimination=False).fit(X, y)
>>> sh.n_resources_
[20, 40]
>>> sh.n_candidates_
[6, 3]
由於我們不能使用超過 max_resources=40 個資源,因此該過程必須在評估多於 factor=2 個候選者的第二次迭代時停止。
當使用 aggressive_elimination 時,該過程將使用 min_resources 個資源消除盡可能多的候選者。
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2,
... max_resources=40,
... aggressive_elimination=True,
... ).fit(X, y)
>>> sh.n_resources_
[20, 20, 40]
>>> sh.n_candidates_
[6, 3, 2]
請注意,由於我們在第一輪迭代中已使用 n_resources = min_resources = 20 淘汰了足夠的候選者,因此在最後一次迭代中,我們以 2 個候選者結束。
3.2.3.2. 使用 cv_results_ 屬性分析結果#
cv_results_ 屬性包含分析搜尋結果的實用資訊。它可以使用 df = pd.DataFrame(est.cv_results_) 轉換為 pandas 資料框。HalvingGridSearchCV 和 HalvingRandomSearchCV 的 cv_results_ 屬性與 GridSearchCV 和 RandomizedSearchCV 類似,並帶有與連續對分過程相關的額外資訊。
(截斷的)輸出資料框範例:#
iter |
n_resources |
mean_test_score |
params |
|
|---|---|---|---|---|
0 |
0 |
125 |
0.983667 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 5} |
1 |
0 |
125 |
0.983667 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 8, ‘min_samples_split’: 7} |
2 |
0 |
125 |
0.983667 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 10} |
3 |
0 |
125 |
0.983667 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 6, ‘min_samples_split’: 6} |
… |
… |
… |
… |
… |
15 |
2 |
500 |
0.951958 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 10} |
16 |
2 |
500 |
0.947958 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 10} |
17 |
2 |
500 |
0.951958 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 4} |
18 |
3 |
1000 |
0.961009 |
{‘criterion’: ‘log_loss’, ‘max_depth’: None, ‘max_features’: 9, ‘min_samples_split’: 10} |
19 |
3 |
1000 |
0.955989 |
{‘criterion’: ‘gini’, ‘max_depth’: None, ‘max_features’: 10, ‘min_samples_split’: 4} |
每一列都對應一個給定的參數組合(一個候選者)和一個給定的迭代次數。迭代次數由 iter 欄位給出。n_resources 欄位告訴您使用了多少資源。
在上面的範例中,最佳的參數組合是 {'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10},因為它以最高的分數:0.96 到達了最後一次迭代 (3)。
參考文獻
3.2.4. 參數搜尋的提示#
3.2.4.1. 指定目標度量#
依預設,參數搜尋會使用評估器的 score 函式來評估參數設定。這些是分類的 sklearn.metrics.accuracy_score 和迴歸的 sklearn.metrics.r2_score。對於某些應用,其他評分函式更為合適(例如,在不平衡的分類中,準確性分數通常沒有資訊)。可以使用大多數參數搜尋工具的 scoring 參數來指定替代的評分函式。有關詳細資訊,請參閱 評分參數:定義模型評估規則。
3.2.4.2. 指定多個評估指標#
GridSearchCV 和 RandomizedSearchCV 允許為 scoring 參數指定多個指標。
多指標評分可以指定為預定義分數名稱的字串清單,或是將評分者名稱對應到評分者函式和/或預定義評分者名稱的字典。有關詳細資訊,請參閱 使用多個指標評估。
在指定多個指標時,必須將 refit 參數設定為將找到 best_params_ 並用於在整個資料集上建構 best_estimator_ 的指標(字串)。如果搜尋不應重新擬合,請設定 refit=False。如果使用多個指標時,將 refit 保留為預設值 None 將導致錯誤。
有關範例用法,請參閱 交叉驗證和 GridSearchCV 上多指標評估的示範。
HalvingRandomSearchCV 和 HalvingGridSearchCV 不支援多指標評分。
3.2.4.3. 複合評估器和參數空間#
GridSearchCV 和 RandomizedSearchCV 允許使用專用的 <estimator>__<parameter> 語法,搜尋複合或巢狀評估器(例如 Pipeline、ColumnTransformer、VotingClassifier 或 CalibratedClassifierCV)的參數
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.calibration import CalibratedClassifierCV
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_moons
>>> X, y = make_moons()
>>> calibrated_forest = CalibratedClassifierCV(
... estimator=RandomForestClassifier(n_estimators=10))
>>> param_grid = {
... 'estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(calibrated_forest, param_grid, cv=5)
>>> search.fit(X, y)
GridSearchCV(cv=5,
estimator=CalibratedClassifierCV(estimator=RandomForestClassifier(n_estimators=10)),
param_grid={'estimator__max_depth': [2, 4, 6, 8]})
在此,<estimator> 是巢狀評估器的參數名稱,在此例中為 estimator。如果元評估器是建構為評估器的集合(如 pipeline.Pipeline 中),則 <estimator> 是指評估器的名稱,請參閱 存取巢狀參數。實際上,可能存在多個巢狀層級
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.feature_selection import SelectKBest
>>> pipe = Pipeline([
... ('select', SelectKBest()),
... ('model', calibrated_forest)])
>>> param_grid = {
... 'select__k': [1, 2],
... 'model__estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(pipe, param_grid, cv=5).fit(X, y)
有關在管道上執行參數搜尋的資訊,請參閱 Pipeline:鏈接評估器。
3.2.4.4. 模型選擇:開發和評估#
藉由評估各種參數設定進行模型選擇可以看作是一種使用已標記資料來「訓練」網格參數的方式。
在評估結果模型時,重要的是在網格搜尋過程中沒有看到的保留樣本上進行評估:建議將資料分成開發集(將其饋送到 GridSearchCV 執行個體)和評估集來計算效能指標。
這可以使用 train_test_split 工具函式來完成。
3.2.4.5. 平行處理#
參數搜尋工具會獨立評估每個資料折疊上的每個參數組合。可以使用關鍵字 n_jobs=-1 平行執行計算。請參閱函式簽名以取得更多詳細資訊,另請參閱 n_jobs 的詞彙條目。
3.2.4.6. 對失敗的穩健性#
某些參數設定可能會導致 fit 一個或多個資料折疊失敗。依預設,這些設定的分數將為 np.nan。可以透過設定 error_score="raise" 來控制,如果在擬合失敗時引發例外狀況,或者例如 error_score=0 為失敗的參數組合設定另一個分數值。
3.2.5. 暴力參數搜尋的替代方案#
3.2.5.1. 模型特定的交叉驗證#
某些模型在擬合某些參數範圍的數據時,幾乎可以像擬合單一參數值的估計器一樣有效率。這個特性可以被利用來執行更有效率的交叉驗證,用於此參數的模型選擇。
最適用於此策略的常見參數是編碼正規化強度的參數。在這種情況下,我們說我們計算估計器的正規化路徑。
以下是此類模型的列表
|
使用沿著正規化路徑迭代擬合的彈性網路模型。 |
|
交叉驗證的最小角度回歸模型。 |
|
使用沿著正規化路徑迭代擬合的 Lasso 線性模型。 |
|
使用 LARS 演算法的交叉驗證 Lasso。 |
|
邏輯迴歸交叉驗證(又稱 logit,MaxEnt)分類器。 |
|
具有內建交叉驗證的多任務 L1/L2 彈性網路。 |
|
使用 L1/L2 混合範數作為正規化器的多任務 Lasso 模型。 |
交叉驗證的正交匹配追蹤模型 (OMP)。 |
|
|
具有內建交叉驗證的嶺迴歸。 |
|
具有內建交叉驗證的嶺分類器。 |
3.2.5.2. 資訊準則#
某些模型可以透過計算單一正規化路徑(而不是使用交叉驗證時的多個路徑),提供正規化參數最佳估計的資訊理論閉合形式公式。
以下是受益於赤池資訊準則 (AIC) 或貝氏資訊準則 (BIC) 來自動進行模型選擇的模型列表
|
使用 Lars 擬合的 Lasso 模型,並使用 BIC 或 AIC 進行模型選擇。 |
3.2.5.3. 袋外估計#
當使用基於 bagging 的集成方法時,即使用帶放回的抽樣生成新的訓練集,部分訓練集將保持未使用。對於集成中的每個分類器,訓練集的不同部分會被排除在外。
這個排除的部分可以用來估計泛化誤差,而無需依賴單獨的驗證集。這種估計是「免費」的,因為不需要額外的資料,並且可以用於模型選擇。
目前在以下類別中實作:
隨機森林分類器。 |
|
隨機森林迴歸器。 |
|
極端隨機樹分類器。 |
|
|
極端隨機樹迴歸器。 |
|
用於分類的梯度提升。 |
|
用於迴歸的梯度提升。 |