1.1. 線性模型#
以下是一組用於迴歸的方法,其中目標值預期為特徵的線性組合。在數學符號中,如果 \(\hat{y}\) 是預測值。
在整個模組中,我們將向量 \(w = (w_1, ..., w_p)\) 指定為 coef_,\(w_0\) 指定為 intercept_。
要使用廣義線性模型執行分類,請參閱 邏輯迴歸。
1.1.1. 普通最小平方法#
LinearRegression 擬合一個具有係數 \(w = (w_1, ..., w_p)\) 的線性模型,以最小化資料集中觀察到的目標值與線性近似預測的目標值之間的殘差平方和。在數學上,它解決以下形式的問題
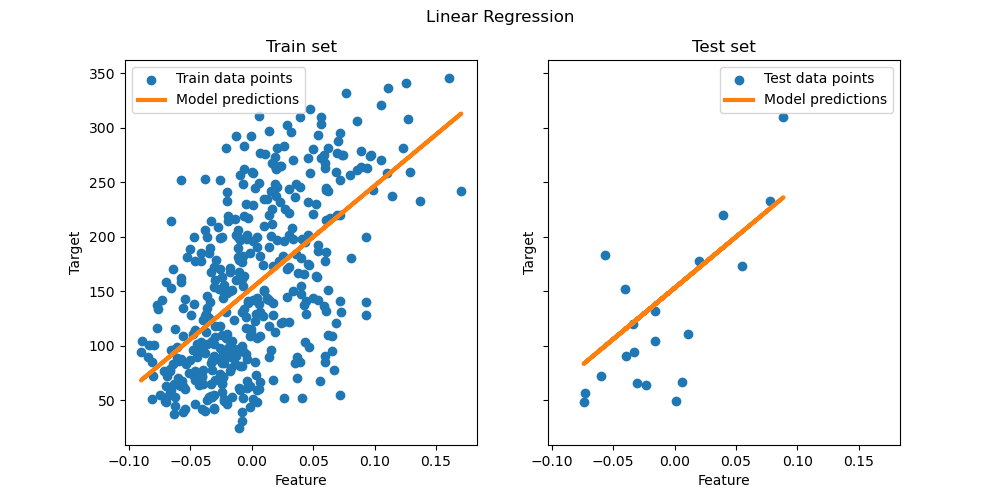
LinearRegression 將在其 fit 方法中接收陣列 X、y,並將線性模型的係數 \(w\) 儲存在其 coef_ 成員中
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression()
>>> reg.coef_
array([0.5, 0.5])
普通最小平方法的係數估計依賴於特徵的獨立性。當特徵相關且設計矩陣 \(X\) 的列具有近似線性依賴性時,設計矩陣會接近奇異,因此,最小平方估計對觀察到的目標中的隨機誤差高度敏感,從而產生較大的變異數。這種多重共線性的情況可能會發生,例如,當在沒有實驗設計的情況下收集資料時。
範例
1.1.1.1. 非負最小平方法#
可以約束所有係數為非負數,當它們表示某些物理或自然非負數量(例如,頻率計數或商品的價格)時,這可能很有用。LinearRegression 接受一個布林值 positive 參數:當設定為 True 時,會應用 非負最小平方法。
範例
1.1.1.2. 普通最小平方法的複雜度#
最小平方解是使用 X 的奇異值分解計算的。如果 X 是一個形狀為 (n_samples, n_features) 的矩陣,則此方法的成本為 \(O(n_{\text{samples}} n_{\text{features}}^2)\),假設 \(n_{\text{samples}} \geq n_{\text{features}}\)。
1.1.2. 嶺迴歸和分類#
1.1.2.1. 迴歸#
Ridge 迴歸透過對係數的大小施加懲罰來解決 普通最小平方法 的某些問題。嶺係數最小化懲罰的殘差平方和
複雜度參數 \(\alpha \geq 0\) 控制收縮量:\(\alpha\) 的值越大,收縮量越大,因此係數對共線性的抵抗力越強。
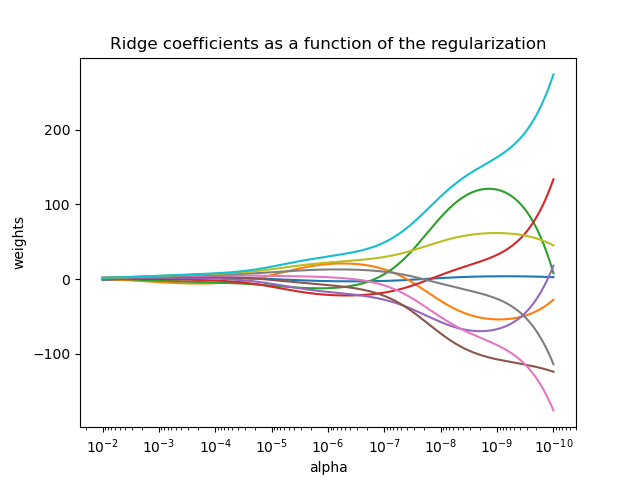
與其他線性模型一樣,Ridge 將在其 fit 方法中接收陣列 X、y,並將線性模型的係數 \(w\) 儲存在其 coef_ 成員中
>>> from sklearn import linear_model
>>> reg = linear_model.Ridge(alpha=.5)
>>> reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
Ridge(alpha=0.5)
>>> reg.coef_
array([0.34545455, 0.34545455])
>>> reg.intercept_
0.13636...
請注意,類別 Ridge 允許使用者透過設定 solver="auto" 來指定自動選擇求解器。當指定此選項時,Ridge 將在 "lbfgs"、"cholesky" 和 "sparse_cg" 求解器之間進行選擇。Ridge 將從上到下開始檢查下表中顯示的條件。如果條件為真,則選擇對應的求解器。
求解器 |
條件 |
‘lbfgs’ |
指定 |
‘cholesky’ |
輸入陣列 X 不是稀疏的。 |
‘sparse_cg’ |
以上條件均不符合。 |
1.1.2.2. 分類#
Ridge 迴歸器有一個分類器變體:RidgeClassifier。此分類器首先將二元目標轉換為 {-1, 1},然後將問題視為迴歸任務,優化與上述相同的目標。預測的類別對應於迴歸器預測的符號。對於多類別分類,問題被視為多輸出迴歸,並且預測的類別對應於具有最高值的輸出。
使用(懲罰)最小平方法損失來擬合分類模型,而不是更傳統的邏輯或 hinge 損失,這似乎令人質疑。然而,在實踐中,所有這些模型在準確性或精確度/召回率方面都可以產生相似的交叉驗證分數,而 RidgeClassifier 使用的懲罰最小平方法損失允許選擇具有不同計算效能配置文件的數值求解器。
相較於例如 LogisticRegression,RidgeClassifier 在類別數量較多時可以顯著加快速度,因為它只需計算一次投影矩陣 \((X^T X)^{-1} X^T\)。
此分類器有時也被稱為具有線性核的最小平方支持向量機。
範例
1.1.2.3. 嶺迴歸複雜度#
此方法的複雜度與普通最小平方法相同。
1.1.2.4. 設定正規化參數:留一交叉驗證#
RidgeCV 和 RidgeClassifierCV 實現了嶺迴歸/分類,並內建了 alpha 參數的交叉驗證。它們的工作方式與 GridSearchCV 相同,只是預設為高效的留一交叉驗證。當使用預設的交叉驗證時,由於用於計算留一誤差的公式,alpha 不能為 0。詳情請參閱 [RL2007]。
使用範例
>>> import numpy as np
>>> from sklearn import linear_model
>>> reg = linear_model.RidgeCV(alphas=np.logspace(-6, 6, 13))
>>> reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
RidgeCV(alphas=array([1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01,
1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06]))
>>> reg.alpha_
0.01
指定 cv 屬性的值將會觸發使用 GridSearchCV 進行交叉驗證,例如 cv=10 表示 10 折交叉驗證,而不是留一交叉驗證。
1.1.3. Lasso#
Lasso 是一個估計稀疏係數的線性模型。在某些情況下,由於其傾向於選擇具有較少非零係數的解,有效地減少給定解所依賴的特徵數量,因此很有用。因此,Lasso 及其變體是壓縮感知領域的基礎。在特定條件下,它可以恢復確切的非零係數集(請參閱壓縮感知:使用 L1 先驗(Lasso)進行斷層掃描重建)。
在數學上,它由一個帶有附加正規化項的線性模型組成。要最小化的目標函數是
因此,Lasso 估計求解了最小平方懲罰與 \(\alpha ||w||_1\) 的最小化,其中 \(\alpha\) 是一個常數,而 \(||w||_1\) 是係數向量的 \(\ell_1\) 範數。
類別 Lasso 中的實作使用坐標下降法作為擬合係數的演算法。有關另一個實作,請參閱最小角迴歸
>>> from sklearn import linear_model
>>> reg = linear_model.Lasso(alpha=0.1)
>>> reg.fit([[0, 0], [1, 1]], [0, 1])
Lasso(alpha=0.1)
>>> reg.predict([[1, 1]])
array([0.8])
函數 lasso_path 對於較低階的任務很有用,因為它可以計算沿著所有可能值的完整路徑的係數。
範例
參考文獻#
以下兩個參考文獻解釋了 scikit-learn 坐標下降求解器中使用的迭代,以及用於收斂控制的對偶間隙計算。
“Regularization Path For Generalized linear Models by Coordinate Descent”,Friedman、Hastie 和 Tibshirani,J Stat Softw,2010 (論文)。
“An Interior-Point Method for Large-Scale L1-Regularized Least Squares,” S. J. Kim, K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, in IEEE Journal of Selected Topics in Signal Processing, 2007 (論文)
1.1.3.1. 設定正規化參數#
alpha 參數控制估計係數的稀疏程度。
1.1.3.1.1. 使用交叉驗證#
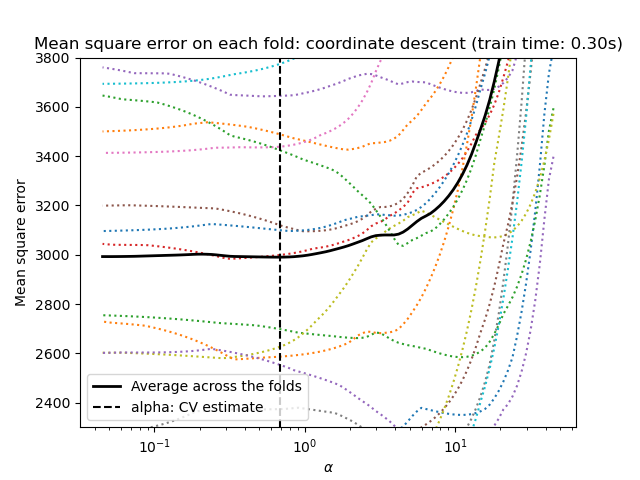
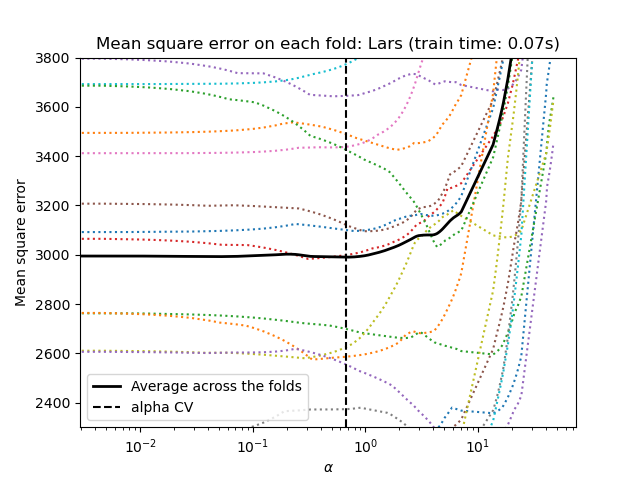
scikit-learn 暴露了透過交叉驗證設定 Lasso alpha 參數的物件:LassoCV 和 LassoLarsCV。LassoLarsCV 基於以下說明的最小角迴歸演算法。
對於具有許多共線性特徵的高維資料集,LassoCV 通常是較佳的選擇。但是,LassoLarsCV 的優點是探索了 alpha 參數更相關的值,並且如果樣本數量相較於特徵數量非常少,則它通常比 LassoCV 快。
1.1.3.1.2. 基於資訊準則的模型選擇#
或者,估計器 LassoLarsIC 建議使用赤池資訊量準則 (AIC) 和貝氏資訊量準則 (BIC)。這是一種計算成本較低的替代方法,可以找到 alpha 的最佳值,因為正規化路徑僅計算一次,而不是使用 k 折交叉驗證時的 k+1 次。
實際上,這些準則是在樣本內訓練集上計算的。簡而言之,它們會透過不同 Lasso 模型的靈活性來懲罰其過於樂觀的分數(參見下文的「數學細節」部分)。
但是,這些準則需要對解的自由度進行適當的估計,是為大樣本推導的(漸近結果),並假設正確的模型是正在研究的候選模型。當問題狀況不佳時(例如,特徵多於樣本),它們也容易崩潰。
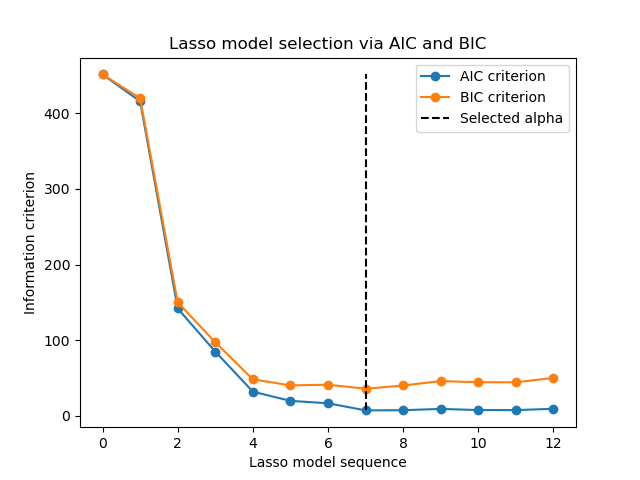
範例
1.1.3.1.3. AIC 和 BIC 準則#
AIC(以及 BIC)的定義在文獻中可能有所不同。在本節中,我們將提供有關在 scikit-learn 中計算的準則的更多資訊。
數學細節#
AIC 準則定義為
其中 \(\hat{L}\) 是模型的最大似然值,而 \(d\) 是參數的數量(在前一節中也稱為自由度)。
BIC 的定義將常數 \(2\) 替換為 \(\log(N)\)
其中 \(N\) 是樣本數。
對於線性高斯模型,最大對數似然值定義為
其中 \(\sigma^2\) 是雜訊變異數的估計值,\(y_i\) 和 \(\hat{y}_i\) 分別是真實目標值和預測目標值,而 \(n\) 是樣本數。
將最大對數似然值代入 AIC 公式可得
當提供 \(\sigma^2\) 時,由於上式的第一項是常數,因此有時會被捨棄。此外,有時會聲稱 AIC 等價於 \(C_p\) 統計量 [12]。然而,嚴格來說,它僅在某個常數和一個乘法因子的範圍內等價。
最後,我們在上面提到 \(\sigma^2\) 是雜訊變異數的估計值。在 LassoLarsIC 中,當未提供參數 noise_variance(預設值)時,雜訊變異數會透過無偏估計量 [13] 估計,定義為
其中 \(p\) 是特徵的數量,而 \(\hat{y}_i\) 是使用普通最小平方迴歸預測的目標值。請注意,此公式僅在 n_samples > n_features 時有效。
參考文獻
1.1.3.1.4. 與 SVM 的正規化參數的比較#
alpha 與 SVM 的正規化參數 C 之間的等價關係由 alpha = 1 / C 或 alpha = 1 / (n_samples * C) 給出,具體取決於估計器和模型所優化的確切目標函數。
1.1.4. 多任務 Lasso#
MultiTaskLasso 是一個線性模型,它聯合估計多個迴歸問題的稀疏係數:y 是一個形狀為 (n_samples, n_tasks) 的二維陣列。約束條件是針對所有迴歸問題(也稱為任務)選取的特徵都是相同的。
下圖比較了使用簡單 Lasso 或 MultiTaskLasso 獲得的係數矩陣 W 中非零項的位置。Lasso 估計產生分散的非零項,而 MultiTaskLasso 的非零項則是完整的列。
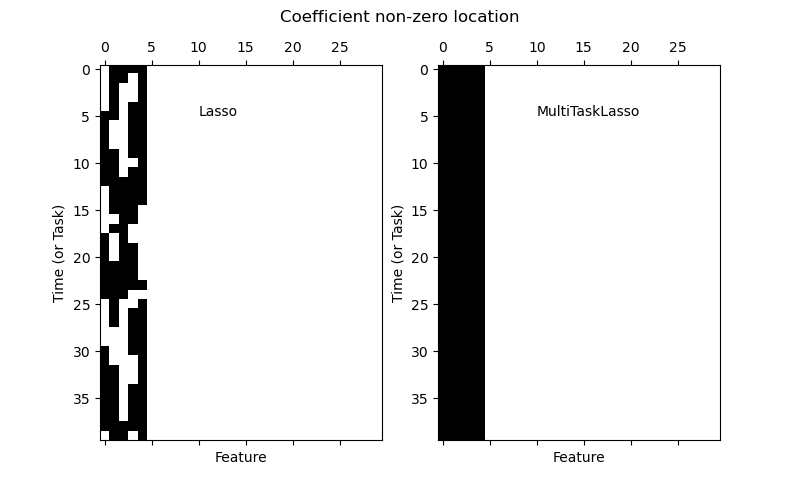
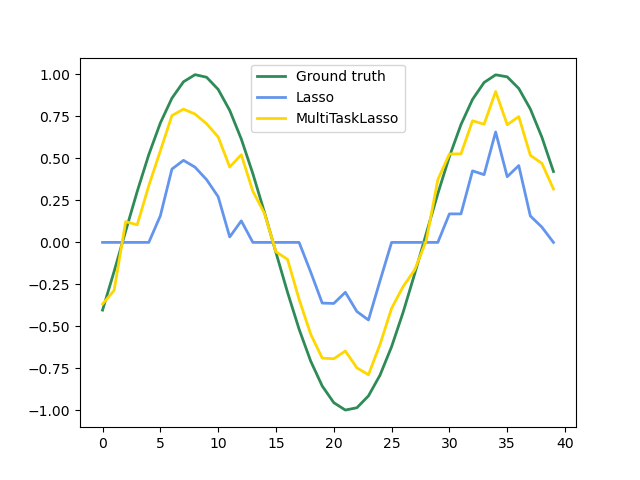
擬合時間序列模型,強制任何作用中的特徵在所有時間都處於活動狀態。
範例
數學細節#
在數學上,它由一個線性模型組成,該模型使用混合的 \(\ell_1\) \(\ell_2\) 範數進行正規化。要最小化的目標函數是
其中 \(\text{Fro}\) 表示 Frobenius 範數
而 \(\ell_1\) \(\ell_2\) 讀作
類別 MultiTaskLasso 中的實作使用座標下降作為擬合係數的演算法。
1.1.5. 彈性網#
ElasticNet 是一個線性迴歸模型,它使用係數的 \(\ell_1\) 和 \(\ell_2\) 範數正規化進行訓練。這種組合允許學習一個稀疏模型,其中只有少數權重是非零的,就像 Lasso 一樣,同時仍然保持 Ridge 的正規化特性。我們使用 l1_ratio 參數控制 \(\ell_1\) 和 \(\ell_2\) 的凸組合。
當存在多個彼此相關的特徵時,彈性網非常有用。Lasso 很有可能會隨機選擇其中一個,而彈性網則很有可能會選擇兩個。
在 Lasso 和 Ridge 之間進行權衡的一個實際優勢是,它允許彈性網繼承 Ridge 在旋轉下的一些穩定性。
在這種情況下要最小化的目標函數是
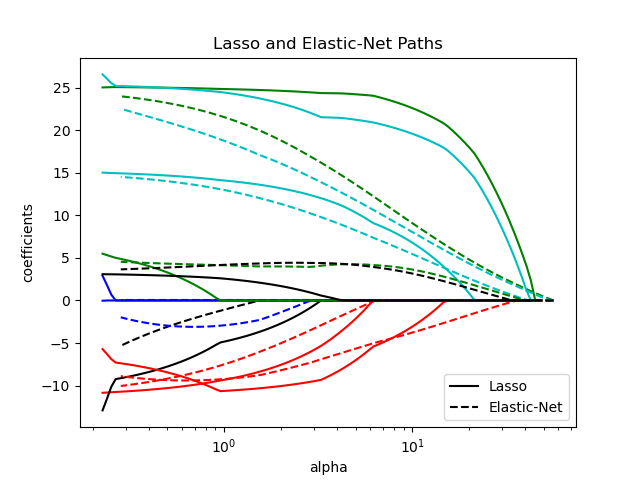
類別 ElasticNetCV 可用於通過交叉驗證設定參數 alpha (\(\alpha\)) 和 l1_ratio (\(\rho\))。
範例
參考文獻#
以下兩個參考文獻解釋了 scikit-learn 坐標下降求解器中使用的迭代,以及用於收斂控制的對偶間隙計算。
“Regularization Path For Generalized linear Models by Coordinate Descent”,Friedman、Hastie 和 Tibshirani,J Stat Softw,2010 (論文)。
“An Interior-Point Method for Large-Scale L1-Regularized Least Squares,” S. J. Kim, K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, in IEEE Journal of Selected Topics in Signal Processing, 2007 (論文)
1.1.6. 多任務彈性網#
MultiTaskElasticNet 是一個彈性網模型,它聯合估計多個迴歸問題的稀疏係數:Y 是一個形狀為 (n_samples, n_tasks) 的二維陣列。約束條件是針對所有迴歸問題(也稱為任務)選取的特徵都是相同的。
在數學上,它由一個線性模型組成,該模型使用混合的 \(\ell_1\) \(\ell_2\) 範數和 \(\ell_2\) 範數進行正規化。要最小化的目標函數是
類別 MultiTaskElasticNet 中的實作使用座標下降作為擬合係數的演算法。
類別 MultiTaskElasticNetCV 可用於通過交叉驗證設定參數 alpha (\(\alpha\)) 和 l1_ratio (\(\rho\))。
1.1.7. 最小角度迴歸#
最小角度迴歸 (LARS) 是一種用於高維數據的迴歸演算法,由 Bradley Efron、Trevor Hastie、Iain Johnstone 和 Robert Tibshirani 開發。LARS 與正向逐步迴歸類似。在每個步驟中,它都會找到與目標最相關的特徵。當有多個具有相等相關性的特徵時,它不會沿著相同的特徵繼續,而是沿著特徵之間等角度的方向進行。
LARS 的優點是
在特徵數量顯著大於樣本數量的情況下,它在數值上非常有效率。
它的計算速度與正向選擇一樣快,並且具有與普通最小平方相同的複雜度等級。
它會產生完整的線性分段解路徑,這在交叉驗證或類似的嘗試以調整模型時非常有用。
如果兩個特徵與目標的相關性幾乎相等,則它們的係數應該以大致相同的速率增加。因此,該演算法的行為符合直覺預期,並且也更穩定。
它很容易被修改以產生其他估計器(如 Lasso)的解。
LARS 方法的缺點包括
由於 LARS 基於殘差的迭代重新擬合,因此它似乎對雜訊的影響特別敏感。Weisberg 在 Efron 等人(2004 年)的《統計年鑑》文章的討論部分中詳細討論了這個問題。
LARS 模型可以透過估計器 Lars 或其底層實作 lars_path 或 lars_path_gram 來使用。
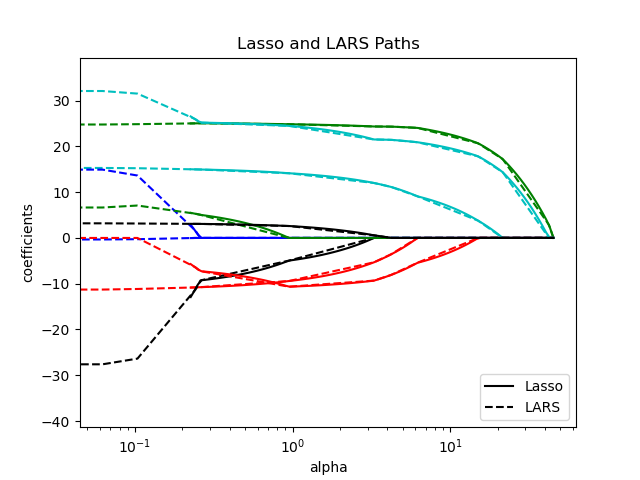
1.1.8. LARS Lasso#
LassoLars 是一個使用 LARS 演算法實作的 Lasso 模型,與基於座標下降的實作不同,它會產生精確的解,該解是其係數範數的線性分段函數。
>>> from sklearn import linear_model
>>> reg = linear_model.LassoLars(alpha=.1)
>>> reg.fit([[0, 0], [1, 1]], [0, 1])
LassoLars(alpha=0.1)
>>> reg.coef_
array([0.6..., 0. ])
範例
Lars 演算法幾乎免費地提供了沿著正規化參數的係數的完整路徑,因此常見的操作是使用函數 lars_path 或 lars_path_gram 來檢索路徑。
1.1.9. 正交匹配追蹤(OMP)#
OrthogonalMatchingPursuit 和 orthogonal_mp 實作了 OMP 演算法,用於近似具有對非零係數數量施加約束(即 \(\ell_0\) 偽範數)的線性模型的擬合。
作為類似於最小角度迴歸的前向特徵選擇方法,正交匹配追蹤可以使用固定數量的非零元素來近似最佳解向量
或者,正交匹配追蹤可以針對特定誤差,而不是特定數量的非零係數。這可以表示為
OMP 基於一種貪婪演算法,該演算法在每個步驟都包含與當前殘差相關性最高的原子。它類似於更簡單的匹配追蹤 (MP) 方法,但更好的是,在每次迭代時,都會使用先前選擇的字典元素空間上的正交投影來重新計算殘差。
範例
參考文獻#
https://www.cs.technion.ac.il/~ronrubin/Publications/KSVD-OMP-v2.pdf
具有時頻字典的匹配追蹤, S. G. Mallat, Z. Zhang,
1.1.10. 貝氏迴歸#
貝氏迴歸技術可用於在估計過程中包含正規化參數:正規化參數不是以硬性的方式設定,而是根據手頭的資料進行調整。
這可以透過在模型的超參數上引入無資訊先驗來完成。在嶺迴歸和分類中使用的\(\ell_{2}\) 正規化等同於在具有精度為 \(\lambda^{-1}\) 的係數 \(w\) 下找到最大後驗估計。可以將 lambda 視為要從資料中估計的隨機變數,而不是手動設定。
為了獲得完全機率模型,假定輸出 \(y\) 在 \(X w\) 周圍呈高斯分佈
其中 \(\alpha\) 再次被視為要從資料中估計的隨機變數。
貝氏迴歸的優點是
它可以根據手頭的資料進行調整。
它可以被用來在估計過程中包含正規化參數。
貝氏迴歸的缺點包括
模型的推斷可能很耗時。
參考文獻#
C. Bishop:《模式識別與機器學習》中對貝氏方法進行了很好的介紹。
原始演算法在 Radford M. Neal 的書
Bayesian learning for neural networks中有詳細說明。
1.1.10.1. 貝氏嶺迴歸#
BayesianRidge 估計如上所述的迴歸問題的機率模型。係數 \(w\) 的先驗由球形高斯分佈給出
\(\alpha\) 和 \(\lambda\) 的先驗被選擇為伽瑪分佈,這是高斯精度的共軛先驗。所得模型稱為貝氏嶺迴歸,它類似於經典的 Ridge。
參數 \(w\)、\(\alpha\) 和 \(\lambda\) 在模型擬合期間被聯合估計,正規化參數 \(\alpha\) 和 \(\lambda\) 通過最大化對數邊際似然來估計。scikit-learn 實作基於 (Tipping, 2001) 的附錄 A 中描述的演算法,其中參數 \(\alpha\) 和 \(\lambda\) 的更新是按照 (MacKay, 1992) 中建議的方式進行的。最大化過程的初始值可以使用超參數 alpha_init 和 lambda_init 來設定。
伽瑪先驗分佈在 \(\alpha\) 和 \(\lambda\) 上還有另外四個超參數:\(\alpha_1\)、\(\alpha_2\)、\(\lambda_1\) 和 \(\lambda_2\)。這些通常被選擇為無資訊。預設情況下,\(\alpha_1 = \alpha_2 = \lambda_1 = \lambda_2 = 10^{-6}\)。
貝氏嶺迴歸用於迴歸
>>> from sklearn import linear_model
>>> X = [[0., 0.], [1., 1.], [2., 2.], [3., 3.]]
>>> Y = [0., 1., 2., 3.]
>>> reg = linear_model.BayesianRidge()
>>> reg.fit(X, Y)
BayesianRidge()
擬合後,可以使用該模型來預測新值
>>> reg.predict([[1, 0.]])
array([0.50000013])
可以存取模型的係數 \(w\)
>>> reg.coef_
array([0.49999993, 0.49999993])
由於貝氏框架,找到的權重與普通最小平方找到的權重略有不同。但是,貝氏嶺迴歸對於不適定問題更具魯棒性。
範例
參考文獻#
Christopher M. Bishop:《模式識別與機器學習》2006 年的第 3.3 節
David J. C. MacKay, 貝氏插值, 1992.
Michael E. Tipping, 稀疏貝氏學習和相關向量機, 2001.
1.1.10.2. 自動關聯性判定 - ARD#
自動關聯性判定 (Automatic Relevance Determination, ARD),如在 ARDRegression 中實作的一樣,是一種與 貝氏嶺迴歸 非常相似的線性模型,但它會產生更稀疏的係數 \(w\) [1] [2]。
ARDRegression 對 \(w\) 設置了不同的先驗:它捨棄了球形高斯分佈,改用中心橢圓高斯分佈。這表示每個係數 \(w_{i}\) 本身可以從一個以零為中心,精確度為 \(\lambda_{i}\) 的高斯分佈中抽取。
其中 \(A\) 是一個正定的對角矩陣,且 \(\text{diag}(A) = \lambda = \{\lambda_{1},...,\lambda_{p}\}\)。
與貝氏嶺迴歸不同,\(w_{i}\) 的每個座標都有其自身的標準差 \(\frac{1}{\lambda_i}\)。所有 \(\lambda_i\) 的先驗被選擇為由超參數 \(\lambda_1\) 和 \(\lambda_2\) 給出的相同伽瑪分佈。
在文獻中,ARD 也被稱為稀疏貝氏學習和關聯向量機 [3] [4]。 有關 ARD 和 貝氏嶺迴歸 之間詳細的比較,請參閱下面的範例。
範例
參考文獻
1.1.11. 邏輯迴歸#
邏輯迴歸在 LogisticRegression 中實作。儘管它名稱如此,但在 scikit-learn/ML 的術語中,它是作為分類而不是迴歸的線性模型實作的。邏輯迴歸在文獻中也稱為 logit 迴歸、最大熵分類 (MaxEnt) 或對數線性分類器。在此模型中,使用 邏輯函數 對描述單次試驗可能結果的機率進行建模。
此實作可以擬合二元、一對多或多項邏輯迴歸,並可選擇使用 \(\ell_1\)、\(\ell_2\) 或彈性網路正規化。
注意
正規化
預設情況下會應用正規化,這在機器學習中很常見,但在統計學中則不然。正規化的另一個優點是它可以提高數值穩定性。不進行正規化相當於將 C 設定為非常高的值。
注意
邏輯迴歸作為廣義線性模型 (GLM) 的特例
邏輯迴歸是廣義線性模型的特例,其條件分佈為二項式/伯努利分佈,且連結函數為 Logit。邏輯迴歸的數值輸出(即預測機率)可以透過應用閾值(預設為 0.5)來用作分類器。這就是 scikit-learn 中的實作方式,因此它期望一個分類目標,使邏輯迴歸成為一個分類器。
範例
1.1.11.1. 二元情況#
為了符號方便起見,我們假設對於資料點 \(i\),目標 \(y_i\) 的值取自集合 \(\{0, 1\}\)。一旦擬合,predict_proba 方法的 LogisticRegression 會預測正類別的機率 \(P(y_i=1|X_i)\),如下所示
作為一個最佳化問題,具有正規化項 \(r(w)\) 的二元類別邏輯迴歸會最小化以下成本函數
其中 \({s_i}\) 對應於使用者分配給特定訓練樣本的權重(向量 \(s\) 是透過類別權重和樣本權重逐元素相乘形成的),並且總和 \(S = \sum_{i=1}^n s_i\)。
我們目前透過 penalty 引數為正規化項 \(r(w)\) 提供四種選擇
懲罰 |
\(r(w)\) |
|---|---|
|
\(0\) |
\(\ell_1\) |
\(\|w\|_1\) |
\(\ell_2\) |
\(\frac{1}{2}\|w\|_2^2 = \frac{1}{2}w^T w\) |
|
\(\frac{1 - \rho}{2}w^T w + \rho \|w\|_1\) |
對於彈性網路,\(\rho\)(對應於 l1_ratio 參數)控制 \(\ell_1\) 正規化與 \(\ell_2\) 正規化的強度。當 \(\rho = 1\) 時,彈性網路等效於 \(\ell_1\);當 \(\rho=0\) 時,則等效於 \(\ell_2\)。
請注意,類別權重和樣本權重的尺度會影響最佳化問題。例如,將樣本權重乘以常數 \(b>0\) 等同於將(反向)正規化強度 C 乘以 \(b\)。
1.1.11.2. 多項式情況#
二元情況可以擴展到 \(K\) 個類別,從而產生多項式邏輯迴歸,另請參閱對數線性模型。
注意
僅使用 \(K-1\) 個權重向量來參數化 \(K\) 類別分類模型是可行的,利用所有類別機率必須加總為 1 的事實,使一個類別機率完全由其他類別機率決定。為了易於實作並保留關於類別排序的對稱歸納偏差,我們刻意選擇使用 \(K\) 個權重向量來過度參數化模型,請參閱 [16]。當使用正規化時,此效果變得特別重要。如 [16] 所示,對於未施加懲罰的模型,過度參數化的選擇可能是有害的,因為這樣解決方案可能不是唯一的。
數學細節#
令 \(y_i \in {1, \ldots, K}\) 為觀察值 \(i\) 的標籤(順序)編碼目標變數。現在我們有一個係數矩陣 \(W\) 而不是單個係數向量,其中每個列向量 \(W_k\) 對應於類別 \(k\)。我們旨在透過 predict_proba 預測類別機率 \(P(y_i=k|X_i)\),如下所示
最佳化的目標變為
其中 \([P]\) 表示 Iverson 括號,如果 \(P\) 為假,則求值為 \(0\);否則求值為 \(1\)。
再次,\(s_{ik}\) 是使用者分配的權重(樣本權重和類別權重的乘積),其總和為 \(S = \sum_{i=1}^n \sum_{k=0}^{K-1} s_{ik}\)。
我們目前透過 penalty 引數為正規化項 \(r(W)\) 提供四種選擇,其中 \(m\) 是特徵的數量
懲罰 |
\(r(W)\) |
|---|---|
|
\(0\) |
\(\ell_1\) |
\(\|W\|_{1,1} = \sum_{i=1}^m\sum_{j=1}^{K}|W_{i,j}|\) |
\(\ell_2\) |
\(\frac{1}{2}\|W\|_F^2 = \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^{K} W_{i,j}^2\) |
|
\(\frac{1 - \rho}{2}\|W\|_F^2 + \rho \|W\|_{1,1}\) |
1.1.11.3. 求解器#
類別 LogisticRegression 中實作的求解器為「lbfgs」、「liblinear」、「newton-cg」、「newton-cholesky」、「sag」和「saga」
下表總結了每個求解器支援的懲罰和多項多類別
求解器 |
|||||||
懲罰 |
‘lbfgs’ |
「liblinear」 |
「newton-cg」 |
「newton-cholesky」 |
「sag」 |
「saga」 |
|
L2 懲罰 |
是 |
否 |
是 |
否 |
是 |
是 |
|
L1 懲罰 |
否 |
是 |
否 |
否 |
否 |
是 |
|
彈性網路 (L1 + L2) |
否 |
否 |
否 |
否 |
否 |
是 |
|
無懲罰 (「none」) |
是 |
否 |
是 |
是 |
是 |
是 |
|
多類別支援 |
|||||||
多項多類別 |
是 |
否 |
是 |
否 |
是 |
是 |
|
行為 |
|||||||
懲罰截距 (不好) |
否 |
是 |
否 |
否 |
否 |
否 |
|
大型資料集速度更快 |
否 |
否 |
否 |
否 |
是 |
是 |
|
對未縮放的資料集具有穩健性 |
是 |
是 |
是 |
是 |
否 |
否 |
|
“lbfgs” 求解器因其穩健性而預設使用。對於大型資料集,“saga” 求解器通常更快。對於大型資料集,您也可以考慮使用 SGDClassifier 和 loss="log_loss",這可能會更快,但需要更多調整。
1.1.11.3.1. 求解器之間的差異#
當 fit_intercept=False 且擬合 coef_ (或) 要預測的資料為零時,使用 solver=liblinear 的 LogisticRegression 或 LinearSVC 與外部 liblinear 函式庫直接使用之間,所獲得的分數可能會有差異。這是因為對於 decision_function 為零的樣本,LogisticRegression 和 LinearSVC 預測負類別,而 liblinear 預測正類別。請注意,fit_intercept=False 且具有許多 decision_function 為零的樣本的模型,很可能是擬合不足的不良模型,建議您設定 fit_intercept=True 並增加 intercept_scaling。
求解器的詳細資訊#
“liblinear” 求解器使用坐標下降 (CD) 演算法,並依賴於與 scikit-learn 一起提供的優秀 C++ LIBLINEAR 函式庫。然而,liblinear 中實作的 CD 演算法無法學習真正的多項式(多類別)模型;相反地,最佳化問題以「一對其餘」的方式分解,因此會為所有類別訓練單獨的二元分類器。這在底層發生,因此使用此求解器的
LogisticRegression實例會表現為多類別分類器。對於 \(\ell_1\) 正規化,sklearn.svm.l1_min_c允許計算 C 的下限,以便獲得非「空」(所有特徵權重為零)的模型。“lbfgs”、“newton-cg” 和 “sag” 求解器僅支援 \(\ell_2\) 正規化或不正規化,並且發現對於某些高維資料收斂速度更快。將
multi_class設定為 “multinomial” 與這些求解器會學習真正的多項式邏輯回歸模型 [5],這表示其機率估計應該比預設的「一對其餘」設定校準得更好。“sag” 求解器使用隨機平均梯度下降法 [6]。當樣本數和特徵數都很大時,對於大型資料集,它比其他求解器更快。
“saga” 求解器 [7] 是 “sag” 的一種變體,也支援非平滑
penalty="l1"。因此,這是稀疏多項式邏輯回歸的首選求解器。它也是唯一支援penalty="elasticnet"的求解器。“lbfgs” 是一種最佳化演算法,它逼近 Broyden–Fletcher–Goldfarb–Shanno 演算法 [8],該演算法屬於準牛頓方法。因此,它可以處理各種不同的訓練資料,因此是預設的求解器。然而,它的效能在縮放不良的資料集以及具有罕見類別的單熱編碼分類特徵的資料集上會受到影響。
“newton-cholesky” 求解器是一種精確的牛頓求解器,它會計算 Hessian 矩陣並求解產生的線性系統。對於
n_samples>>n_features,它是一個非常好的選擇,但有一些缺點:僅支援 \(\ell_2\) 正規化。此外,由於 Hessian 矩陣是明確計算的,因此記憶體使用量與n_features以及n_classes具有二次依賴關係。因此,對於多類別情況,僅實作一對其餘方案。
有關其中一些求解器的比較,請參閱 [9]。
參考文獻
LogisticRegressionCV 實作具有內建交叉驗證支援的邏輯回歸,以根據 scoring 屬性尋找最佳 C 和 l1_ratio 參數。由於暖啟動(請參閱 詞彙表),“newton-cg”、“sag”、“saga” 和 “lbfgs” 求解器對於高維稠密資料速度更快。
1.1.12. 廣義線性模型#
廣義線性模型 (GLM) 以兩種方式擴展線性模型 [10]。首先,預測值 \(\hat{y}\) 通過反向連結函式 \(h\) 連結到輸入變數 \(X\) 的線性組合,如
其次,平方損失函式會被指數分佈族中分佈的單位偏差 \(d\) 取代(或更準確地說,是再生指數離散模型 (EDM) [11])。
最小化問題變成
其中 \(\alpha\) 是 L2 正規化懲罰。當提供樣本權重時,平均值會變成加權平均值。
下表列出一些特定的 EDM 及其單位偏差
分佈 |
目標域 |
單位偏差 \(d(y, \hat{y})\) |
|---|---|---|
常態 |
\(y \in (-\infty, \infty)\) |
\((y-\hat{y})^2\) |
白努利 |
\(y \in \{0, 1\}\) |
\(2({y}\log\frac{y}{\hat{y}}+({1}-{y})\log\frac{{1}-{y}}{{1}-\hat{y}})\) |
分類 |
\(y \in \{0, 1, ..., k\}\) |
\(2\sum_{i \in \{0, 1, ..., k\}} I(y = i) y_\text{i}\log\frac{I(y = i)}{\hat{I(y = i)}}\) |
卜瓦松 |
\(y \in [0, \infty)\) |
\(2(y\log\frac{y}{\hat{y}}-y+\hat{y})\) |
伽瑪 |
\(y \in (0, \infty)\) |
\(2(\log\frac{\hat{y}}{y}+\frac{y}{\hat{y}}-1)\) |
反向高斯 |
\(y \in (0, \infty)\) |
\(\frac{(y-\hat{y})^2}{y\hat{y}^2}\) |
這些分佈的機率密度函數 (PDF) 如以下圖所示,
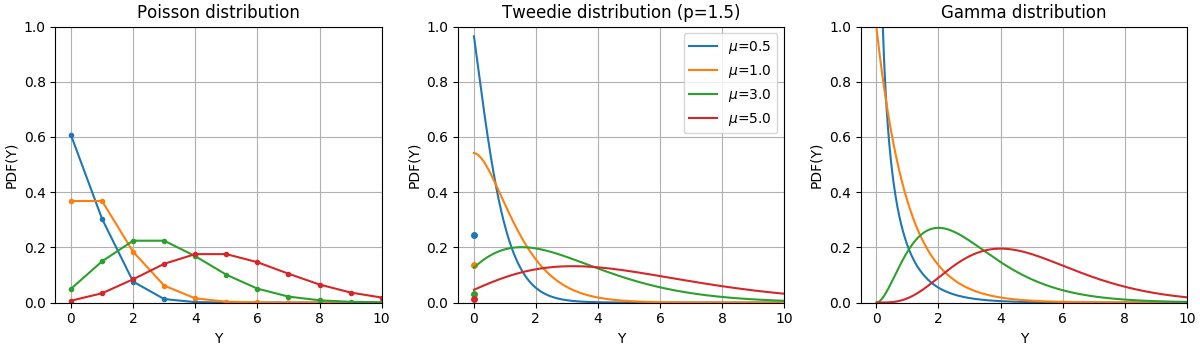
隨機變數 Y 的 PDF,遵循具有不同平均值 (\(\mu\)) 的卜瓦松、Tweedie (power=1.5) 和伽瑪分佈。觀察卜瓦松分佈和 Tweedie (power=1.5) 分佈在 \(Y=0\) 處的點質量,但伽瑪分佈沒有,伽瑪分佈具有嚴格的正目標域。#
白努利分佈是一種離散機率分佈,用於建模白努利試驗 - 一個只有兩個互斥結果的事件。分類分佈是白努利分佈對於分類隨機變數的推廣。雖然白努利分佈中的隨機變數有兩個可能的結果,但分類隨機變數可以採用 K 個可能的類別之一,每個類別的機率單獨指定。
分佈的選擇取決於手邊的問題
如果目標值 \(y\) 是計數值(非負整數值)或相對頻率(非負),您可以使用具有對數連結的卜瓦松分佈。
如果目標值是正值且偏斜,您可以嘗試具有對數連結的伽瑪分佈。
如果目標值似乎比伽瑪分佈具有更重的尾部,您可以嘗試反向高斯分佈(甚至更高變異數的 Tweedie 族的冪)。
如果目標值 \(y\) 是機率,您可以使用白努利分布。具有 logit 連接的白努利分布可用於二元分類。具有 softmax 連接的類別分布可用於多類別分類。
使用案例範例#
農業/天氣建模:每年降雨事件次數(Poisson)、每次事件的降雨量(Gamma)、每年總降雨量(Tweedie / 複合 Poisson Gamma)。
風險建模/保險政策定價:每年每位保戶的理賠事件次數(Poisson)、每次事件的成本(Gamma)、每年每位保戶的總成本(Tweedie / 複合 Poisson Gamma)。
信用違約:貸款無法償還的機率(白努利)。
詐欺偵測:現金轉帳等金融交易為詐欺交易的機率(白努利)。
預測性維護:每年生產中斷事件的次數(Poisson)、中斷持續時間(Gamma)、每年總中斷時間(Tweedie / 複合 Poisson Gamma)。
醫學藥物測試:一組試驗中治癒患者的機率,或患者出現副作用的機率(白努利)。
新聞分類:將新聞文章分類為三個類別,即商業新聞、政治和娛樂新聞(類別)。
參考文獻
1.1.12.1. 用法#
TweedieRegressor 實現了 Tweedie 分布的廣義線性模型,允許使用適當的 power 參數對上述任何分布進行建模。特別是
power = 0:常態分布。在這種情況下,諸如Ridge、ElasticNet等特定估計器通常更合適。power = 1:Poisson 分布。PoissonRegressor為方便起見而公開。然而,它嚴格等同於TweedieRegressor(power=1, link='log')。power = 2:Gamma 分布。GammaRegressor為方便起見而公開。然而,它嚴格等同於TweedieRegressor(power=2, link='log')。power = 3:反高斯分布。
連結函數由 link 參數決定。
使用範例
>>> from sklearn.linear_model import TweedieRegressor
>>> reg = TweedieRegressor(power=1, alpha=0.5, link='log')
>>> reg.fit([[0, 0], [0, 1], [2, 2]], [0, 1, 2])
TweedieRegressor(alpha=0.5, link='log', power=1)
>>> reg.coef_
array([0.2463..., 0.4337...])
>>> reg.intercept_
-0.7638...
範例
實際考量#
在擬合之前,應將特徵矩陣 X 標準化。這確保懲罰對待特徵的公平性。
由於線性預測器 \(Xw\) 可以為負值,而 Poisson、Gamma 和反高斯分布不支援負值,因此有必要應用逆連結函數來保證非負性。例如,使用 link='log',逆連結函數變為 \(h(Xw)=\exp(Xw)\)。
如果您想要對相對頻率建模,即每次暴露(時間、體積、...)的計數,您可以透過使用 Poisson 分布並傳遞 \(y=\frac{\mathrm{counts}}{\mathrm{exposure}}\) 作為目標值,並將 \(\mathrm{exposure}\) 作為樣本權重來實現。有關具體範例,請參閱例如保險理賠的 Tweedie 迴歸。
當為 TweedieRegressor 的 power 參數執行交叉驗證時,建議指定明確的 scoring 函數,因為預設評分器 TweedieRegressor.score 本身是 power 的函數。
1.1.13. 隨機梯度下降 - SGD#
隨機梯度下降是一種簡單但非常有效的方法,用於擬合線性模型。當樣本數量(以及特徵數量)非常大時,它尤其有用。partial_fit 方法允許線上/核心外學習。
類別 SGDClassifier 和 SGDRegressor 提供使用不同的(凸)損失函數和不同的懲罰來擬合分類和迴歸線性模型的功能。例如,使用 loss="log",SGDClassifier 擬合邏輯迴歸模型,而使用 loss="hinge" 則擬合線性支援向量機(SVM)。
您可以參考專用的隨機梯度下降 文件章節以了解更多詳細資訊。
1.1.14. 感知器#
Perceptron 是另一種適用於大規模學習的簡單分類演算法。預設情況下
它不需要學習率。
它不會被正規化(懲罰)。
它僅在錯誤時更新其模型。
最後一個特徵表示,與使用 hinge 損失的 SGD 相比,感知器的訓練速度稍快,並且產生的模型更稀疏。
實際上,Perceptron 是使用感知器損失和恆定學習率的 SGDClassifier 類別的包裝器。有關更多詳細資訊,請參閱 SGD 程序的數學章節。
1.1.15. 被動攻擊演算法#
被動攻擊演算法是一系列用於大規模學習的演算法。它們與感知器類似,因為它們不需要學習率。然而,與感知器相反,它們包含正規化參數 C。
對於分類,PassiveAggressiveClassifier 可以與 loss='hinge' (PA-I) 或 loss='squared_hinge' (PA-II) 一起使用。對於迴歸,PassiveAggressiveRegressor 可以與 loss='epsilon_insensitive' (PA-I) 或 loss='squared_epsilon_insensitive' (PA-II) 一起使用。
參考文獻#
「線上被動攻擊演算法」 K. Crammer、O. Dekel、J. Keshat、S. Shalev-Shwartz、Y. Singer - JMLR 7 (2006)
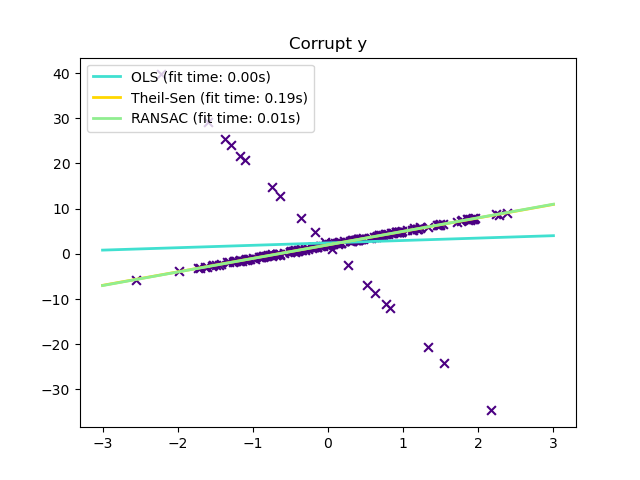
1.1.16. 穩健迴歸:離群值和建模誤差#
穩健迴歸旨在在存在損壞資料的情況下擬合迴歸模型:離群值或模型中的誤差。
1.1.16.1. 不同的情境和有用的概念#
在處理被離群值損壞的資料時,有不同的事情需要記住
X 或 y 中的離群值?
y 方向的離群值
X 方向的離群值
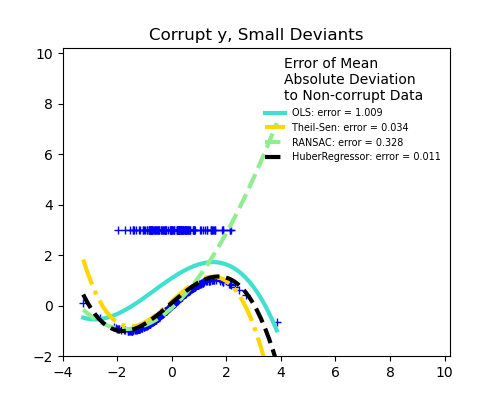
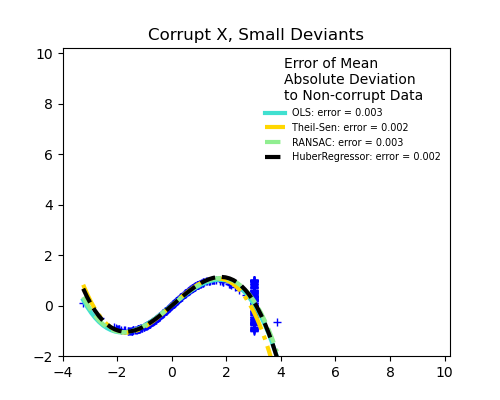
離群值的分數與誤差幅度
離群點的數量很重要,但它們的離群程度也很重要。
小離群值
大離群值
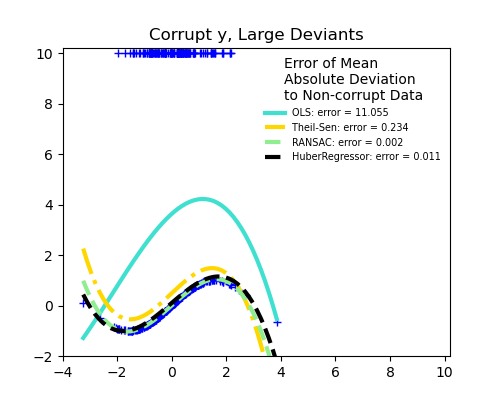
穩健擬合的一個重要概念是擊穿點:對於擬合開始遺漏內部資料來說,可以作為離群值的資料分數。
請注意,一般而言,在高維度設定(大的 n_features)中進行穩健擬合非常困難。此處的穩健模型可能無法在這些設定中運作。
1.1.16.2. RANSAC:隨機抽樣一致性 (RANdom SAmple Consensus)#
RANSAC(隨機抽樣一致性)從完整數據集中內點的隨機子集擬合模型。
RANSAC 是一種非確定性演算法,僅以一定的機率產生合理的結果,該機率取決於迭代次數(請參閱 max_trials 參數)。它通常用於線性和非線性迴歸問題,並且在攝影測量電腦視覺領域特別受歡迎。
該演算法將完整的輸入樣本數據分成一組內點(可能受到雜訊干擾)和離群值(例如,由錯誤測量或關於數據的無效假設引起)。然後僅從確定的內點估計所得模型。
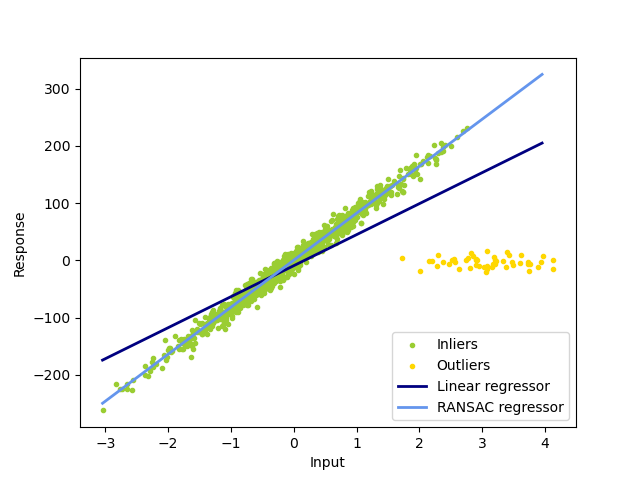
範例
演算法的詳細資訊#
每次迭代執行以下步驟
從原始數據中選擇
min_samples個隨機樣本,並檢查數據集是否有效(請參閱is_data_valid)。將模型擬合到隨機子集 (
estimator.fit),並檢查估計的模型是否有效(請參閱is_model_valid)。透過計算估計模型的殘差(
estimator.predict(X) - y)將所有數據分類為內點或離群值 - 所有絕對殘差小於或等於residual_threshold的數據樣本都被視為內點。如果內點樣本的數量最大,則將擬合模型儲存為最佳模型。如果當前估計的模型具有相同的內點數量,則僅當其具有更好的分數時才將其視為最佳模型。
這些步驟會執行最大次數 (max_trials),或者直到滿足其中一個特殊的停止條件為止(請參閱 stop_n_inliers 和 stop_score)。最後的模型是使用先前確定的最佳模型的所有內點樣本(共識集)進行估計的。
is_data_valid 和 is_model_valid 函數允許識別和拒絕隨機子樣本的退化組合。如果不需要估計模型來識別退化情況,則應使用 is_data_valid,因為它會在擬合模型之前被呼叫,因此可以提高計算效能。
參考文獻#
“隨機抽樣一致性:一種用於模型擬合的範例,應用於影像分析和自動製圖” Martin A. Fischler 和 Robert C. Bolles - SRI International (1981)
“RANSAC 系列的效能評估” Sunglok Choi、Taemin Kim 和 Wonpil Yu - BMVC (2009)
1.1.16.3. Theil-Sen 估計器:基於廣義中位數的估計器#
TheilSenRegressor 估計器使用多維中位數的推廣。因此,它對多變數離群值具有穩健性。但是請注意,估計器的穩健性會隨著問題的維度迅速降低。它會失去其穩健性,在高維度中不會比普通的最小平方法更好。
範例
理論考量#
TheilSenRegressor 在漸近效率和作為無偏估計器方面可與普通最小平方法 (OLS) 相提並論。與 OLS 相比,Theil-Sen 是一種非參數方法,這意味著它不對數據的基礎分佈做任何假設。由於 Theil-Sen 是一種基於中位數的估計器,因此它對損壞的數據(又稱離群值)更具穩健性。在單變量設定中,Theil-Sen 在簡單線性迴歸的情況下具有約 29.3% 的崩潰點,這意味著它可以容忍高達 29.3% 的任意損壞數據。
scikit-learn 中 TheilSenRegressor 的實作遵循對多變數線性迴歸模型的推廣[14],該模型使用空間中位數,它是中位數對多個維度的推廣 [15]。
在時間和空間複雜度方面,Theil-Sen 的規模如下:
這使得無法將其詳盡地應用於具有大量樣本和特徵的問題。因此,可以透過僅考慮所有可能組合的隨機子集來選擇子群體的大小,以限制時間和空間複雜度。
參考文獻
另請參閱維基百科頁面
1.1.16.4. Huber 迴歸#
HuberRegressor 與 Ridge 不同,因為它將線性損失應用於被分類為離群值的樣本。如果樣本的絕對誤差小於某個閾值,則該樣本將被分類為內點。它與 TheilSenRegressor 和 RANSACRegressor 不同,因為它不會忽略離群值的影響,而是給予它們較小的權重。
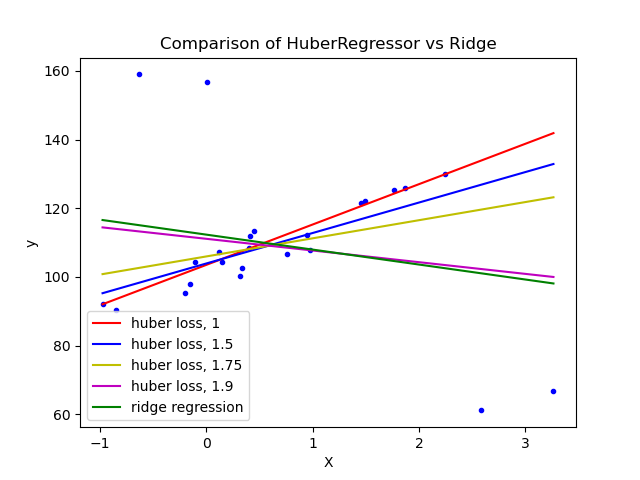
範例
數學細節#
HuberRegressor 最小化的損失函數由下式給出
其中
建議將參數 epsilon 設定為 1.35,以實現 95% 的統計效率。
參考文獻
Peter J. Huber,Elvezio M. Ronchetti:穩健統計,伴隨尺度估計,第 172 頁
HuberRegressor 與使用損失設定為 huber 的 SGDRegressor 的不同之處如下。
HuberRegressor具有尺度不變性。一旦設定了epsilon,無論將X和y按不同數值縮放放大,其對於離群值的穩健性仍與之前相同。 相較之下,SGDRegressor在X和y被縮放時,則需要重新設定epsilon。當資料樣本數較少時,使用
HuberRegressor應更有效率,而SGDRegressor則需要多次迭代訓練資料才能產生相同的穩健性。
請注意,此估計器與 R 語言實作的穩健迴歸不同(https://stats.oarc.ucla.edu/r/dae/robust-regression/),因為 R 的實作是執行加權最小平方,並根據每個樣本殘差超出特定閾值的程度來給予權重。
1.1.17. 分位數迴歸#
分位數迴歸估計在給定 \(X\) 條件下,\(y\) 的中位數或其他分位數,而普通最小平方法 (OLS) 則是估計條件平均值。
如果我們有興趣預測區間而不是點預測,則分位數迴歸可能很有用。有時,預測區間的計算是基於預測誤差呈常態分佈,且具有零均值和恆定變異數的假設。即使誤差具有非恆定(但可預測)變異數或非常態分佈,分位數迴歸也能提供合理的預測區間。
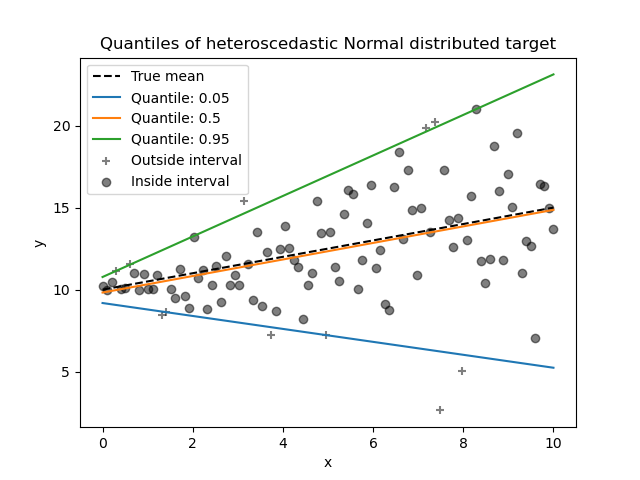
基於最小化 pinball 損失,條件分位數也可以透過線性模型以外的模型來估計。例如,如果將 GradientBoostingRegressor 的參數 loss 設定為 "quantile",且參數 alpha 設定為應預測的分位數,則 GradientBoostingRegressor 可以預測條件分位數。請參閱 梯度提升迴歸的預測區間 中的範例。
分位數迴歸的大多數實作都是基於線性規劃問題。目前的實作是基於 scipy.optimize.linprog。
範例
數學細節#
作為線性模型,QuantileRegressor 給出第 \(q\) 個分位數的線性預測值 \(\hat{y}(w, X) = Xw\),其中 \(q \in (0, 1)\)。權重或係數 \(w\) 透過以下最小化問題求得
此式包含 pinball 損失(也稱為線性損失),另請參閱 mean_pinball_loss,
以及由參數 alpha 控制的 L1 正規化,類似於 Lasso。
由於 pinball 損失在殘差中僅為線性,因此分位數迴歸比基於平方誤差的平均值估計對離群值更穩健。介於兩者之間的是 HuberRegressor。
參考文獻#
Koenker, R., & Bassett Jr, G. (1978). 迴歸分位數。計量經濟學:計量經濟學會期刊,33-50。
Portnoy, S., & Koenker, R. (1997). 高斯野兔與拉普拉斯烏龜:平方誤差估計器與絕對誤差估計器的可計算性。統計科學,12,279-300。
Koenker, R. (2005). 分位數迴歸。劍橋大學出版社。
1.1.18. 多項式迴歸:使用基底函數擴展線性模型#
機器學習中一種常見的模式是使用在資料的非線性函數上訓練的線性模型。這種方法保持了線性方法通常快速的效能,同時允許它們擬合更廣泛的資料。
數學細節#
例如,可以透過從係數建構多項式特徵來擴展簡單的線性迴歸。在標準線性迴歸情況下,對於二維資料,您可能會得到如下的模型
如果我們想將拋物面擬合到資料而不是平面,我們可以將特徵組合為二階多項式,以便模型看起來像這樣
(有時令人驚訝的)觀察結果是,這仍然是一個線性模型:要看到這一點,請想像建立一組新的特徵
透過重新標記資料,我們的問題可以寫成
我們看到產生的多項式迴歸與我們上面考慮的線性模型屬於同一類(即,模型在 \(w\) 中是線性的),並且可以通過相同的技術解決。透過考慮使用這些基底函數建立的更高維空間中的線性擬合,該模型具有擬合更廣泛資料的靈活性。
以下是將此想法應用於一維資料的範例,使用不同次數的多項式特徵
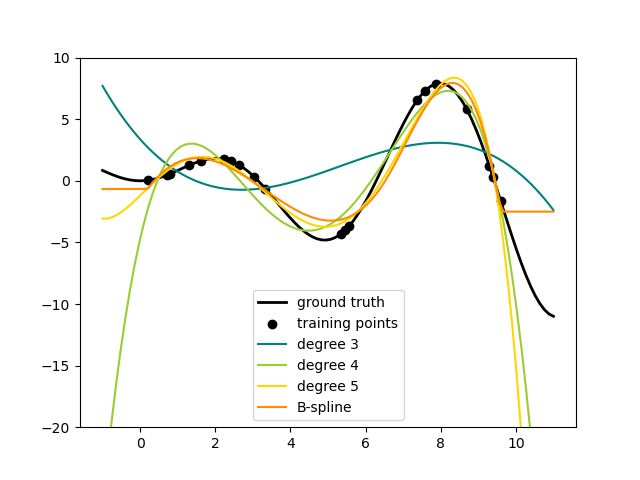
此圖是使用 PolynomialFeatures 轉換器建立的,它將輸入資料矩陣轉換為給定次數的新資料矩陣。它可以使用如下
>>> from sklearn.preprocessing import PolynomialFeatures
>>> import numpy as np
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(degree=2)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
X 的特徵已從 \([x_1, x_2]\) 轉換為 \([1, x_1, x_2, x_1^2, x_1 x_2, x_2^2]\),現在可以在任何線性模型中使用。
可以使用 Pipeline 工具來簡化此類預處理。可以建立和使用代表簡單多項式迴歸的單個物件,如下所示
>>> from sklearn.preprocessing import PolynomialFeatures
>>> from sklearn.linear_model import LinearRegression
>>> from sklearn.pipeline import Pipeline
>>> import numpy as np
>>> model = Pipeline([('poly', PolynomialFeatures(degree=3)),
... ('linear', LinearRegression(fit_intercept=False))])
>>> # fit to an order-3 polynomial data
>>> x = np.arange(5)
>>> y = 3 - 2 * x + x ** 2 - x ** 3
>>> model = model.fit(x[:, np.newaxis], y)
>>> model.named_steps['linear'].coef_
array([ 3., -2., 1., -1.])
在多項式特徵上訓練的線性模型能夠精確地恢復輸入的多項式係數。
在某些情況下,不需要包括任何單個特徵的較高次方,而只需包括最多將 \(d\) 個不同特徵相乘的所謂交互特徵。這些可以從 PolynomialFeatures 中,透過設定 interaction_only=True 取得。
例如,當處理布林特徵時,對於所有 \(n\),\(x_i^n = x_i\),因此沒有用;但 \(x_i x_j\) 代表兩個布林值的結合。透過這種方式,我們可以使用線性分類器解決 XOR 問題
>>> from sklearn.linear_model import Perceptron
>>> from sklearn.preprocessing import PolynomialFeatures
>>> import numpy as np
>>> X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
>>> y = X[:, 0] ^ X[:, 1]
>>> y
array([0, 1, 1, 0])
>>> X = PolynomialFeatures(interaction_only=True).fit_transform(X).astype(int)
>>> X
array([[1, 0, 0, 0],
[1, 0, 1, 0],
[1, 1, 0, 0],
[1, 1, 1, 1]])
>>> clf = Perceptron(fit_intercept=False, max_iter=10, tol=None,
... shuffle=False).fit(X, y)
分類器的「預測」是完美的
>>> clf.predict(X)
array([0, 1, 1, 0])
>>> clf.score(X, y)
1.0