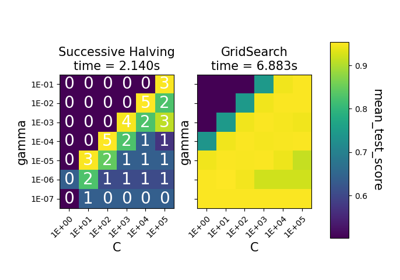
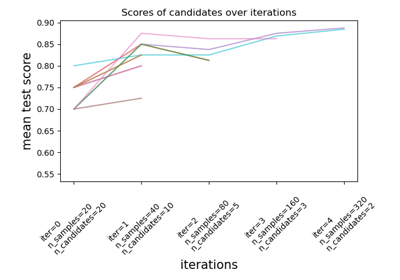
減半網格搜尋交叉驗證#
- class sklearn.model_selection.HalvingGridSearchCV(estimator, param_grid, *, factor=3, resource='n_samples', max_resources='auto', min_resources='exhaust', aggressive_elimination=False, cv=5, scoring=None, refit=True, error_score=nan, return_train_score=True, random_state=None, n_jobs=None, verbose=0)[來源]#
使用連續減半法搜尋指定的參數值。
此搜尋策略首先使用少量資源評估所有候選模型,然後迭代選擇最佳候選模型,並使用越來越多的資源。
請參閱使用者指南以了解更多資訊。
注意
此估算器目前仍為實驗性:預測和 API 可能會在沒有任何棄用週期下變更。若要使用它,您需要明確導入
enable_halving_search_cv>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> # now you can import normally from model_selection >>> from sklearn.model_selection import HalvingGridSearchCV
- 參數:
- estimator估算器物件
假設此物件實作了 scikit-learn 估算器介面。估算器需要提供
score函數,或者必須傳遞scoring。- param_grid字典或字典列表
字典以參數名稱(字串)作為鍵,並以要嘗試的參數設定列表作為值,或是此類字典的列表,在此情況下,會探索列表中每個字典所跨越的網格。這樣可以搜尋任何參數設定序列。
- factor整數或浮點數,預設值=3
「減半」參數,決定每次後續迭代中選取的候選模型比例。例如,
factor=3表示僅選取三分之一的候選模型。- resource
'n_samples'或字串,預設值='n_samples' 定義每次迭代中增加的資源。預設情況下,資源是樣本數。它也可以設定為基本估算器的任何接受正整數值的參數,例如梯度提升估算器的 'n_iterations' 或 'n_estimators'。在此情況下,
max_resources不能為 'auto' 且必須明確設定。- max_resources整數,預設值='auto'
任何候選模型在給定迭代中允許使用的最大資源量。預設情況下,當
resource='n_samples'(預設值)時,此值會設定為n_samples,否則會引發錯誤。- min_resources{‘exhaust’, ‘smallest’} 或整數,預設值='exhaust'
任何候選模型在給定迭代中允許使用的最小資源量。同樣地,這定義了第一次迭代時為每個候選模型配置的資源量
r0。當
resource='n_samples'時,「smallest」是一種將r0設定為小值的啟發式方法對於迴歸問題,設定為
n_splits * 2對於分類問題,設定為
n_classes * n_splits * 2,當resource='n_samples'時當
resource != 'n_samples'時,設定為1
「exhaust」會設定
r0,使最後一次迭代使用儘可能多的資源。也就是說,最後一次迭代將使用小於max_resources且為min_resources和factor的倍數的最大值。一般來說,使用「exhaust」會產生更準確的估算器,但會稍微耗費更多時間。
請注意,每次迭代中使用的資源量始終是
min_resources的倍數。- aggressive_elimination布林值,預設值=False
這僅在沒有足夠資源在最後一次迭代後將剩餘的候選模型減少到最多
factor的情況下才相關。如果為True,則搜尋過程將「重播」第一次迭代,直到候選模型數量足夠小。預設值為False,這表示最後一次迭代可能會評估超過factor個候選模型。請參閱積極消除候選模型以了解更多詳細資訊。- cv整數、交叉驗證產生器或可迭代物件,預設值=5
決定交叉驗證分割策略。cv 的可能輸入包括
整數,用於指定
(Stratified)KFold中的折數,一個可迭代的物件,產生 (訓練、測試) 分割作為索引陣列。
對於整數/None 輸入,如果估算器是分類器且
y是二元或多類別,則會使用StratifiedKFold。在所有其他情況下,則會使用KFold。這些分割器會以shuffle=False進行實例化,因此分割結果在多次呼叫之間會保持一致。請參考 使用者指南 以了解此處可以使用的各種交叉驗證策略。
注意
由於實作細節,
cv產生的折疊必須在多次呼叫cv.split()時保持一致。對於內建的scikit-learn迭代器,可以透過停用洗牌 (shuffle=False),或將cv的random_state參數設定為整數來達成。- scoringstr、可呼叫物件或 None,預設值為 None
用於評估測試集預測結果的單一字串 (請參閱 評分參數:定義模型評估規則) 或可呼叫物件 (請參閱 可呼叫的評分器)。如果為 None,則會使用估算器的 score 方法。
- refitbool,預設值為 True
如果為 True,則使用在整個資料集上找到的最佳參數重新擬合估算器。
重新擬合的估算器可在
best_estimator_屬性中取得,並允許直接在此HalvingGridSearchCV實例上使用predict。- error_score‘raise’ 或數值
如果估算器擬合時發生錯誤,則將此值指定給分數。如果設定為 'raise',則會引發錯誤。如果給定數值,則會引發 FitFailedWarning。此參數不會影響重新擬合步驟,該步驟將始終引發錯誤。預設值為
np.nan。- return_train_scorebool,預設值為 False
如果為
False,則cv_results_屬性將不會包含訓練分數。計算訓練分數用於深入了解不同的參數設定如何影響過擬合/欠擬合的權衡。然而,計算訓練集上的分數在計算上可能很昂貴,並且並非嚴格要求選擇產生最佳泛化效能的參數。- random_stateint、RandomState 實例或 None,預設值為 None
當
resources != 'n_samples'時,用於對資料集進行子取樣的虛擬隨機數產生器狀態。否則將忽略。傳遞一個 int 以在多次函數呼叫之間產生可重複的輸出。請參閱 術語表。- n_jobsint 或 None,預設值為 None
要平行執行的任務數量。
None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。請參閱 術語表 以取得更多詳細資訊。- verboseint
控制詳細程度:數值越高,訊息越多。
- 屬性:
- n_resources_int 的列表
每次迭代使用的資源量。
- n_candidates_int 的列表
每次迭代評估的候選參數數量。
- n_remaining_candidates_int
最後一次迭代後剩餘的候選參數數量。它對應於
ceil(n_candidates[-1] / factor)- max_resources_int
任何候選者在給定迭代中允許使用的最大資源量。請注意,由於每次迭代使用的資源數量必須是
min_resources_的倍數,因此最後一次迭代實際使用的資源數量可能會小於max_resources_。- min_resources_int
在第一次迭代時,為每個候選者分配的資源量。
- n_iterations_int
實際執行的迭代次數。如果
aggressive_elimination為True,則等於n_required_iterations_。否則,等於min(n_possible_iterations_, n_required_iterations_)。- n_possible_iterations_int
從
min_resources_資源開始,且不超過max_resources_的可能迭代次數。- n_required_iterations_int
從
min_resources_資源開始,在最後一次迭代結束時,需要讓候選者數量小於factor的迭代次數。當資源不足時,這會小於n_possible_iterations_。- cv_results_numpy (遮罩) ndarray 的字典
一個以欄標題為鍵、欄為值的字典,可以匯入到 pandas 的
DataFrame中。它包含用於分析搜尋結果的大量資訊。請參閱 使用者指南 以了解詳細資訊。- best_estimator_估算器或字典
搜尋選擇的最佳估計器,即在留出數據上給出最高分數(如果指定了則為最小損失)的估計器。 如果
refit=False,則不可用。- best_score_float
最佳估計器的平均交叉驗證分數。
- best_params_dict
在留出數據上產生最佳結果的參數設定。
- best_index_int
對應於最佳候選參數設定的索引(在
cv_results_陣列中)。search.cv_results_['params'][search.best_index_]中的字典給出了最佳模型的參數設定,該模型給出最高的平均分數 (search.best_score_)。- scorer_function 或 dict
用於在保留數據上選擇模型最佳參數的評分函數。
- n_splits_int
交叉驗證分割(折/迭代)的次數。
- refit_time_float
將最佳模型重新擬合到整個數據集所用的秒數。
僅當
refit不為 False 時才會出現。- multimetric_bool
評分器是否計算多個指標。
classes_形狀為 (n_classes,) 的 ndarray類別標籤。
n_features_in_int在 fit 期間看到的特徵數量。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。 僅當定義了
best_estimator_(有關詳細信息,請參閱refit參數的文檔),並且best_estimator_在擬合時公開feature_names_in_時定義。在 1.0 版本中新增。
另請參閱
減半隨機搜尋交叉驗證 (HalvingRandomSearchCV)使用連續減半在參數集上進行隨機搜尋。
注意事項
根據評分參數,選擇的參數是那些使保留數據分數最大化的參數。
所有評分為 NaN 的參數組合將共享最低排名。
範例
>>> from sklearn.datasets import load_iris >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> from sklearn.model_selection import HalvingGridSearchCV ... >>> X, y = load_iris(return_X_y=True) >>> clf = RandomForestClassifier(random_state=0) ... >>> param_grid = {"max_depth": [3, None], ... "min_samples_split": [5, 10]} >>> search = HalvingGridSearchCV(clf, param_grid, resource='n_estimators', ... max_resources=10, ... random_state=0).fit(X, y) >>> search.best_params_ {'max_depth': None, 'min_samples_split': 10, 'n_estimators': 9}
- property classes_#
類別標籤。
僅當
refit=True且估計器為分類器時才可用。
- decision_function(X)[原始碼]#
使用找到的最佳參數在估計器上呼叫 decision_function。
僅當
refit=True且底層估計器支援decision_function時才可用。- 參數:
- X可索引,長度為 n_samples
必須滿足底層估計器的輸入假設。
- 返回:
- y_score形狀為 (n_samples,) 或 (n_samples, n_classes) 或 (n_samples, n_classes * (n_classes-1) / 2) 的 ndarray
基於具有最佳找到參數的估計器,針對
X的決策函數結果。
- fit(X, y=None, **params)[原始碼]#
使用所有參數集執行擬合。
- 參數:
- X類陣列,形狀 (n_samples, n_features)
訓練向量,其中
n_samples是樣本數,n_features是特徵數。- y類陣列,形狀為 (n_samples,) 或 (n_samples, n_output),可選
相對於 X 的分類或迴歸目標;對於無監督學習,則為 None。
- **params字串 -> 物件的 dict
傳遞給估計器的
fit方法的參數。
- 返回:
- self物件
已擬合估計器的實例。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用指南,了解路由機制如何運作。
在 1.4 版本中新增。
- 返回:
- routingMetadataRouter
封裝路由資訊的
MetadataRouter。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,將傳回此估計器和所包含的子物件(即估計器)的參數。
- 返回:
- paramsdict
參數名稱對應到它們的值。
- inverse_transform(X=None, Xt=None)[原始碼]#
使用找到的最佳參數在估計器上呼叫 inverse_transform。
僅在底層估算器實作了
inverse_transform且refit=True時可用。- 參數:
- X可索引,長度為 n_samples
必須滿足底層估計器的輸入假設。
- Xt可索引,長度為 n_samples
必須滿足底層估計器的輸入假設。
自 1.5 版本起已棄用:
Xt在 1.5 版本中已棄用,並將在 1.7 版本中移除。請改用X。
- 返回:
- X形狀為 (n_samples, n_features) 的 {ndarray, 稀疏矩陣}
基於具有最佳找到參數的估算器,對
Xt執行inverse_transform函數的結果。
- predict(X)[原始碼]#
對具有最佳找到參數的估算器呼叫 predict。
僅在
refit=True且底層估算器支援predict時可用。- 參數:
- X可索引,長度為 n_samples
必須滿足底層估計器的輸入假設。
- 返回:
- y_pred形狀為 (n_samples,) 的 ndarray
基於具有最佳找到參數的估算器,對
X的預測標籤或值。
- predict_log_proba(X)[原始碼]#
對具有最佳找到參數的估算器呼叫 predict_log_proba。
僅在
refit=True且底層估算器支援predict_log_proba時可用。- 參數:
- X可索引,長度為 n_samples
必須滿足底層估計器的輸入假設。
- 返回:
- y_pred形狀為 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
基於具有最佳找到參數的估算器,對
X的預測類別對數機率。類別的順序對應到已擬合屬性 classes_ 中的順序。
- predict_proba(X)[原始碼]#
對具有最佳找到參數的估算器呼叫 predict_proba。
僅在
refit=True且底層估算器支援predict_proba時可用。- 參數:
- X可索引,長度為 n_samples
必須滿足底層估計器的輸入假設。
- 返回:
- y_pred形狀為 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
基於具有最佳找到參數的估算器,對
X的預測類別機率。類別的順序對應到已擬合屬性 classes_ 中的順序。
- score(X, y=None, **params)[原始碼]#
如果估算器已重新擬合,則傳回給定資料的分數。
這會使用提供的
scoring所定義的分數,否則使用best_estimator_.score方法。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入資料,其中
n_samples是樣本數量,而n_features是特徵數量。- y形狀為 (n_samples, n_output) 或 (n_samples,) 的類陣列,預設值為 None
相對於 X 的分類或迴歸目標;對於無監督學習,則為 None。
- **paramsdict
要傳遞給底層評分器的一個或多個參數。
在 1.4 版本中新增:僅在
enable_metadata_routing=True時可用。如需更多詳細資訊,請參閱中繼資料路由使用者指南。
- 返回:
- scorefloat
如果已提供,則為
scoring所定義的分數,否則為best_estimator_.score方法。
- score_samples(X)[原始碼]#
對具有最佳找到參數的估算器呼叫 score_samples。
僅在
refit=True且底層估算器支援score_samples時可用。在 0.24 版本中新增。
- 參數:
- X可迭代物件
要進行預測的資料。必須符合底層估算器的輸入要求。
- 返回:
- y_score形狀為 (n_samples,) 的 ndarray
best_estimator_.score_samples方法。