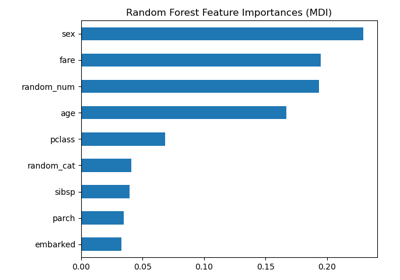
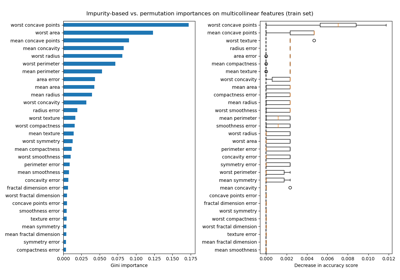
隨機森林分類器#(RandomForestClassifier#)
- class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None, monotonic_cst=None)[原始碼]#
隨機森林分類器。
隨機森林是一種元估計器,它在資料集的多個子樣本上擬合多個決策樹分類器,並使用平均來提高預測準確性並控制過度擬合。森林中的樹使用最佳分割策略,也就是相當於將
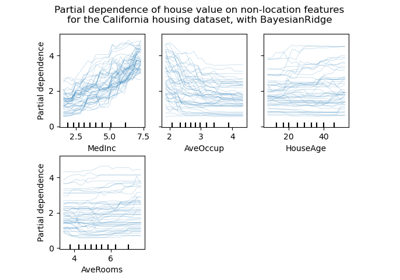
splitter="best"傳遞給底層的DecisionTreeClassifier。如果bootstrap=True(預設值),則子樣本大小由max_samples參數控制,否則整個資料集用於構建每棵樹。有關基於樹的集成模型的比較,請參閱範例 比較隨機森林和直方圖梯度提升模型。
在 使用者指南 中閱讀更多資訊。
- 參數:
- n_estimatorsint,預設值=100
森林中的樹木數量。
在版本 0.22 中變更:
n_estimators的預設值在 0.22 中從 10 更改為 100。- criterion{“gini”, “entropy”, “log_loss”}, 預設值=“gini”
衡量分割品質的函數。支援的標準是「gini」表示吉尼不純度,「log_loss」和「entropy」都表示香農資訊增益,請參閱 數學公式。注意:此參數是樹特定的。
- max_depthint,預設值=None
樹的最大深度。如果為 None,則會擴展節點,直到所有葉節點都是純的,或直到所有葉節點包含的樣本少於 min_samples_split 個。
- min_samples_splitint 或 float,預設值=2
分割內部節點所需的最小樣本數
如果為 int,則將
min_samples_split視為最小值。如果為 float,則
min_samples_split為一個分數,且ceil(min_samples_split * n_samples)為每次分割所需的最小樣本數。
在版本 0.18 中變更: 新增了分數的 float 值。
- min_samples_leafint 或 float,預設值=1
葉節點所需的最小樣本數。只有在左右分支中至少保留
min_samples_leaf個訓練樣本時,才會考慮任何深度的分割點。這可能會使模型平滑,尤其是在回歸中。如果為 int,則將
min_samples_leaf視為最小值。如果為 float,則
min_samples_leaf為一個分數,且ceil(min_samples_leaf * n_samples)為每個節點所需的最小樣本數。
在版本 0.18 中變更: 新增了分數的 float 值。
- min_weight_fraction_leaffloat,預設值=0.0
葉節點所需的權重總和(所有輸入樣本的總和)的最小加權分數。當未提供 sample_weight 時,樣本具有相等的權重。
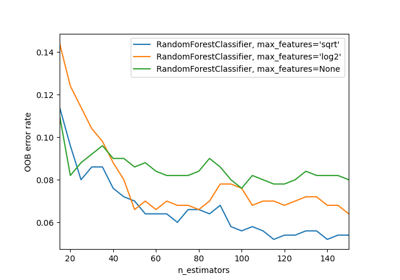
- max_features{“sqrt”, “log2”, None}, int 或 float,預設值=“sqrt”
尋找最佳分割時要考慮的特徵數量
如果為 int,則在每次分割時考慮
max_features個特徵。如果為 float,則
max_features為一個分數,且在每次分割時會考慮max(1, int(max_features * n_features_in_))個特徵。如果為「sqrt」,則
max_features=sqrt(n_features)。如果為「log2」,則
max_features=log2(n_features)。如果為 None,則
max_features=n_features。
在版本 1.1 中變更:
max_features的預設值從"auto"更改為"sqrt"。注意:分割的搜尋不會停止,直到找到至少一個節點樣本的有效分割,即使它需要實際檢查超過
max_features個特徵。- max_leaf_nodesint,預設值=None
以最佳優先方式,使用
max_leaf_nodes來成長樹。最佳節點定義為雜質的相對減少量。如果為 None,則葉節點數量不受限制。- min_impurity_decreasefloat,預設值為 0.0
如果分裂導致雜質的減少量大於或等於此值,則會分裂節點。
加權雜質減少量的方程式如下:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
其中
N是樣本總數,N_t是目前節點的樣本數,N_t_L是左子節點中的樣本數,而N_t_R是右子節點中的樣本數。如果傳遞了
sample_weight,N、N_t、N_t_R和N_t_L都指的是加權總和。於 0.19 版本新增。
- bootstrapbool,預設值為 True
是否在使用建立樹時使用自舉樣本。如果為 False,則會使用整個資料集來建立每棵樹。
- oob_scorebool 或 callable,預設值為 False
是否使用袋外 (out-of-bag) 樣本來估計泛化分數。預設情況下,會使用
accuracy_score。提供一個簽名為metric(y_true, y_pred)的可呼叫物件以使用自訂指標。僅在bootstrap=True時可用。- n_jobsint,預設值為 None
要並行運行的作業數量。
fit、predict、decision_path和apply都會在樹上進行並行處理。None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。詳情請參閱詞彙表。- random_stateint、RandomState 實例或 None,預設值為 None
控制在建立樹時使用的樣本自舉的隨機性(如果
bootstrap=True)以及在尋找每個節點的最佳分裂時要考慮的特徵的抽樣(如果max_features < n_features)。詳情請參閱詞彙表。- verboseint,預設值為 0
控制擬合和預測時的詳細程度。
- warm_startbool,預設值為 False
當設為
True時,重複使用先前的擬合呼叫的解,並將更多估計器添加到集成中,否則,僅擬合一個全新的森林。詳情請參閱詞彙表和擬合其他樹。- class_weight{“balanced”, “balanced_subsample”}、dict 或 dicts 的列表,預設值為 None
以
{class_label: weight}形式與類別相關聯的權重。如果未給定,則假設所有類別的權重皆為 1。對於多輸出問題,可以按照 y 的列的順序提供 dicts 的列表。請注意,對於多輸出(包括多標籤),應為其自身 dict 中的每一列的每個類別定義權重。例如,對於四類多標籤分類,權重應為 [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] 而不是 [{1:1}, {2:5}, {3:1}, {4:1}]。
“balanced” 模式使用 y 的值,以與輸入資料中類別頻率成反比的方式自動調整權重,計算方式為
n_samples / (n_classes * np.bincount(y))“balanced_subsample” 模式與 “balanced” 模式相同,不同之處在於權重是根據每個成長的樹的自舉樣本計算的。
對於多輸出,y 的每列的權重將會相乘。
請注意,如果指定了 sample_weight,這些權重將與 sample_weight(透過 fit 方法傳遞)相乘。
- ccp_alpha非負浮點數,預設值為 0.0
用於最小成本複雜度剪枝的複雜度參數。將會選擇成本複雜度小於
ccp_alpha的最大成本複雜度子樹。預設情況下,不執行剪枝。詳情請參閱最小成本複雜度剪枝。有關此類剪枝的範例,請參閱使用成本複雜度剪枝對決策樹進行後剪枝。於 0.22 版本新增。
- max_samplesint 或 float,預設值為 None
如果 bootstrap 為 True,則要從 X 中抽取以訓練每個基底估計器的樣本數。
如果為 None(預設值),則抽取
X.shape[0]個樣本。如果為 int,則抽取
max_samples個樣本。如果為 float,則抽取
max(round(n_samples * max_samples), 1)個樣本。因此,max_samples應該在(0.0, 1.0]的區間內。
於 0.22 版本新增。
- monotonic_cst形狀為 (n_features) 的 int 類陣列,預設值為 None
- 指示要對每個特徵強制執行的單調性約束。
1:單調遞增
0:無約束
-1:單調遞減
如果 monotonic_cst 為 None,則不套用任何約束。
- 單調性約束不支援用於
多類別分類 (即當
n_classes > 2時),多輸出分類 (即當
n_outputs_ > 1時),以及使用含有遺失值的資料訓練的分類。
這些約束適用於正類別的機率。
請在使用者指南中閱讀更多資訊。
在 1.4 版本中新增。
- 屬性:
- estimator_
DecisionTreeClassifier 用於建立已擬合子估計器集合的子估計器模板。
在 1.2 版本中新增:
base_estimator_已重新命名為estimator_。- estimators_DecisionTreeClassifier 的列表
已擬合子估計器的集合。
- classes_形狀為 (n_classes,) 的 ndarray 或此類陣列的列表
類別標籤 (單輸出問題),或類別標籤陣列的列表 (多輸出問題)。
- n_classes_int 或 list
類別的數量 (單輸出問題),或包含每個輸出類別數量的列表 (多輸出問題)。
- n_features_in_int
在 擬合 期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 擬合 期間看到的特徵名稱。 僅當
X具有全部為字串的特徵名稱時才定義。在 1.0 版本中新增。
- n_outputs_int
執行
fit時的輸出數量。feature_importances_形狀為 (n_features,) 的 ndarray基於雜質的特徵重要性。
- oob_score_float
使用袋外估計取得的訓練資料集分數。僅當
oob_score為 True 時,此屬性才存在。- oob_decision_function_形狀為 (n_samples, n_classes) 或 (n_samples, n_classes, n_outputs) 的 ndarray
使用訓練集上的袋外估計計算的決策函數。如果 n_estimators 很小,則可能發生在 bootstrap 期間從未遺漏資料點的情況。在這種情況下,
oob_decision_function_可能包含 NaN。僅當oob_score為 True 時,此屬性才存在。estimators_samples_陣列的列表每個基本估計器所繪製的樣本子集。
- estimator_
另請參閱
sklearn.tree.DecisionTreeClassifier決策樹分類器。
sklearn.ensemble.ExtraTreesClassifier極端隨機樹分類器的集成。
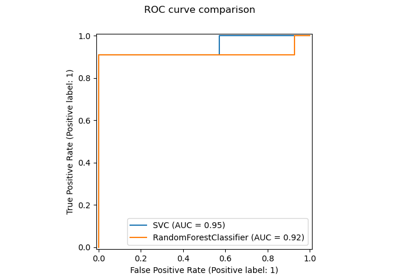
sklearn.ensemble.HistGradientBoostingClassifier基於直方圖的梯度提升分類樹,對於大型資料集非常快速 (n_samples >= 10_000)。
注意事項
控制樹大小的參數 (例如
max_depth、min_samples_leaf等) 的預設值會導致完全成長且未修剪的樹,這些樹在某些資料集上可能非常大。為了減少記憶體消耗,應該透過設定這些參數值來控制樹的複雜性和大小。在每次分割時,特徵始終會隨機排列。因此,即使使用相同的訓練資料、
max_features=n_features和bootstrap=False,所找到的最佳分割也可能會有所不同,如果準則的改進對於在搜尋最佳分割期間列舉的幾個分割是相同的。為了在擬合期間獲得確定性行為,必須固定random_state。參考文獻
[1]Breiman, “Random Forests”, Machine Learning, 45(1), 5-32, 2001.
範例
>>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.datasets import make_classification >>> X, y = make_classification(n_samples=1000, n_features=4, ... n_informative=2, n_redundant=0, ... random_state=0, shuffle=False) >>> clf = RandomForestClassifier(max_depth=2, random_state=0) >>> clf.fit(X, y) RandomForestClassifier(...) >>> print(clf.predict([[0, 0, 0, 0]])) [1]
- apply(X)[原始碼]#
將森林中的樹應用於 X,傳回葉索引。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
輸入樣本。在內部,其 dtype 將轉換為
dtype=np.float32。如果提供稀疏矩陣,它將轉換為稀疏csr_matrix。
- 傳回值:
- X_leaves形狀為 (n_samples, n_estimators) 的 ndarray
對於 X 中的每個資料點 x 以及森林中的每棵樹,傳回 x 最終所在的葉的索引。
- decision_path(X)[原始碼]#
傳回森林中的決策路徑。
在 0.18 版本中新增。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
輸入樣本。在內部,其 dtype 將轉換為
dtype=np.float32。如果提供稀疏矩陣,它將轉換為稀疏csr_matrix。
- 傳回值:
- indicator形狀為 (n_samples, n_nodes) 的稀疏矩陣
傳回節點指示器矩陣,其中非零元素表示樣本通過節點。矩陣的格式為 CSR。
- n_nodes_ptr形狀為 (n_estimators + 1,) 的 ndarray
indicator[n_nodes_ptr[i]:n_nodes_ptr[i+1]] 中的各列給出第 i 個估計器的指示器值。
- property estimators_samples_#
每個基本估計器所繪製的樣本子集。
傳回一個動態產生的索引列表,識別用於擬合集成中每個成員的樣本,即袋內樣本。
注意:列表會在每次呼叫屬性時重新建立,以便透過不儲存取樣資料來減少物件記憶體佔用。因此,擷取屬性可能會比預期的慢。
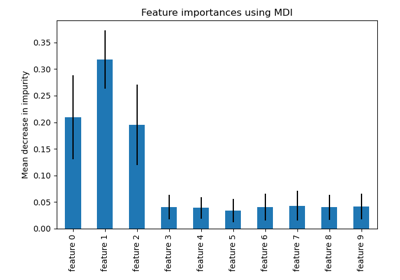
- property feature_importances_#
基於雜質的特徵重要性。
越高,表示特徵越重要。特徵的重要性計算為該特徵帶來的準則 (正規化) 總降低。它也稱為 Gini 重要性。
警告:基於雜質的特徵重要性對於高基數特徵 (許多唯一值) 可能具有誤導性。請參閱
sklearn.inspection.permutation_importance作為替代方案。- 傳回值:
- feature_importances_形狀為 (n_features,) 的 ndarray
除非所有樹都是僅由根節點組成的單節點樹,否則此陣列的值總和為 1。如果所有樹都是單節點樹,則它會是一個零陣列。
- fit(X, y, sample_weight=None)[原始碼]#
從訓練集 (X, y) 建立樹的森林。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
訓練輸入樣本。在內部,其 dtype 將會轉換為
dtype=np.float32。如果提供稀疏矩陣,則會將其轉換為稀疏csc_matrix。- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
目標值(分類中的類別標籤,迴歸中的實數)。
- sample_weight形狀為 (n_samples,) 的類陣列,預設為 None
樣本權重。如果為 None,則樣本權重相等。在每個節點中搜尋分割時,將忽略會建立淨權重為零或負值的子節點的分割。在分類的情況下,如果分割會導致任何單一類別在任一子節點中具有負權重,則也會忽略分割。
- 傳回值:
- self物件
已擬合的估計器。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制如何運作。
- 傳回值:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設為 True
如果為 True,將會傳回此估計器和其中所包含的子物件 (屬於估計器) 的參數。
- 傳回值:
- paramsdict
參數名稱對應到其值。
- predict(X)[原始碼]#
預測 X 的類別。
輸入樣本的預測類別是森林中樹的投票結果,並根據其機率估計值加權。也就是說,預測類別是樹木中具有最高平均機率估計值的類別。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
輸入樣本。在內部,其 dtype 將轉換為
dtype=np.float32。如果提供稀疏矩陣,它將轉換為稀疏csr_matrix。
- 傳回值:
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的 ndarray
預測的類別。
- predict_log_proba(X)[原始碼]#
預測 X 的類別對數機率。
輸入樣本的預測類別對數機率計算方式為森林中樹的平均預測類別機率的對數。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
輸入樣本。在內部,其 dtype 將轉換為
dtype=np.float32。如果提供稀疏矩陣,它將轉換為稀疏csr_matrix。
- 傳回值:
- p形狀為 (n_samples, n_classes) 的 ndarray,或此類陣列的列表
輸入樣本的類別機率。類別的順序與屬性 classes_ 中的順序對應。
- predict_proba(X)[原始碼]#
預測 X 的類別機率。
輸入樣本的預測類別機率計算方式為森林中樹的平均預測類別機率。單棵樹的類別機率是葉子中相同類別樣本的分數。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列,稀疏矩陣}
輸入樣本。在內部,其 dtype 將轉換為
dtype=np.float32。如果提供稀疏矩陣,它將轉換為稀疏csr_matrix。
- 傳回值:
- p形狀為 (n_samples, n_classes) 的 ndarray,或此類陣列的列表
輸入樣本的類別機率。類別的順序與屬性 classes_ 中的順序對應。
- score(X, y, sample_weight=None)[原始碼]#
傳回給定測試資料和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為您需要針對每個樣本正確預測每個標籤集。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
X的真實標籤。- sample_weight形狀為 (n_samples,) 的類陣列,預設為 None
樣本權重。
- 傳回值:
- scorefloat
self.predict(X)相對於y的平均準確度。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RandomForestClassifier[原始碼]#
請求傳遞至
fit方法的中繼資料。請注意,此方法僅在
enable_metadata_routing=True時才相關(請參閱sklearn.set_config)。請參閱使用者指南,了解路由機制如何運作。每個參數的選項為
True:請求中繼資料,如果提供,則將其傳遞給fit。如果未提供中繼資料,則忽略請求。False:不請求中繼資料,且 meta-estimator 不會將其傳遞給fit。None:不請求中繼資料,如果使用者提供,則 meta-estimator 會引發錯誤。str:中繼資料應使用此給定的別名而不是原始名稱傳遞給 meta-estimator。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留現有的請求。這允許您變更某些參數的請求,而不變更其他參數的請求。在 1.3 版本中新增。
注意
僅當此估算器用作 meta-estimator 的子估算器時,此方法才相關,例如在
Pipeline中使用。否則,它沒有任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight參數的中繼資料路由。
- 傳回值:
- self物件
更新後的物件。
- set_params(**params)[原始碼]#
設定此估算器的參數。
此方法適用於簡單的估算器以及巢狀物件(例如
Pipeline)。後者具有<component>__<parameter>形式的參數,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器參數。
- 傳回值:
- self估算器執行個體
估算器執行個體。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RandomForestClassifier[原始碼]#
請求傳遞給
score方法的中繼資料。請注意,此方法僅在
enable_metadata_routing=True時才相關(請參閱sklearn.set_config)。請參閱使用者指南,了解路由機制如何運作。每個參數的選項為
True:請求中繼資料,如果提供,則將其傳遞給score。如果未提供中繼資料,則忽略請求。False:不請求中繼資料,且 meta-estimator 不會將其傳遞給score。None:不請求中繼資料,如果使用者提供,則 meta-estimator 會引發錯誤。str:中繼資料應使用此給定的別名而不是原始名稱傳遞給 meta-estimator。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留現有的請求。這允許您變更某些參數的請求,而不變更其他參數的請求。在 1.3 版本中新增。
注意
僅當此估算器用作 meta-estimator 的子估算器時,此方法才相關,例如在
Pipeline中使用。否則,它沒有任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的中繼資料路由。
- 傳回值:
- self物件
更新後的物件。