KNeighborsRegressor#
- class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)[原始碼]#
基於 k 個最近鄰的迴歸。
目標的預測是透過在訓練集中,最近鄰的目標值進行局部內插。
請在使用者指南中閱讀更多。
於 0.9 版本加入。
- 參數:
- n_neighborsint,預設值為 5
用於
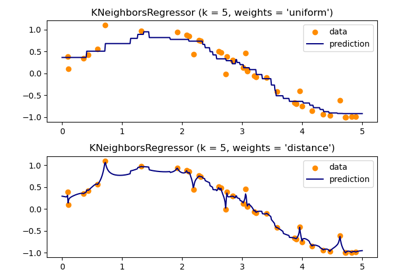
kneighbors查詢時,預設使用的鄰居數量。- weights{‘uniform’, ‘distance’}, 可呼叫或 None,預設值為 ‘uniform’
預測中使用的權重函數。可能的值有
‘uniform’:均勻權重。每個鄰域中的所有點的權重均相同。
‘distance’:依據點的距離的倒數來加權。在此情況下,查詢點的較近鄰居將比更遠的鄰居具有更大的影響。
[可呼叫]:使用者定義的函數,接受距離陣列,並回傳一個包含權重的相同形狀的陣列。
預設使用均勻權重。
請參閱以下範例,以示範不同加權方案對預測的影響:最近鄰迴歸。
- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 預設值為 ‘auto’
用於計算最近鄰的演算法
注意:在稀疏輸入上進行擬合將覆蓋此參數的設定,並使用暴力法。
- leaf_sizeint,預設值為 30
傳遞給 BallTree 或 KDTree 的葉節點大小。這會影響建構和查詢的速度,以及儲存樹所需的記憶體。最佳值取決於問題的性質。
- pfloat,預設值為 2
Minkowski 距離的冪參數。當 p = 1 時,這相當於使用 manhattan_distance (l1),而 p = 2 時則使用 euclidean_distance (l2)。對於任意 p,會使用 minkowski_distance (l_p)。
- metricstr、DistanceMetric 物件或可呼叫物件,預設值為 ‘minkowski’
用於距離計算的度量。預設值為 “minkowski”,當 p = 2 時,會產生標準歐幾里得距離。請參閱 scipy.spatial.distance 的文件和
distance_metrics中列出的度量,以取得有效的度量值。如果 metric 為 “precomputed”,則 X 會被假設為距離矩陣,並且在擬合期間必須為正方形。X 可以是稀疏圖,在這種情況下,只有「非零」元素可被視為鄰居。
如果 metric 是可呼叫的函數,它會將表示 1D 向量的兩個陣列作為輸入,並且必須回傳一個值,表示這些向量之間的距離。這適用於 Scipy 的度量,但效率不如以字串形式傳遞度量名稱。
如果 metric 是 DistanceMetric 物件,則會直接傳遞到基礎的計算常式。
- metric_paramsdict,預設值為 None
度量函數的其他關鍵字引數。
- n_jobsint,預設值為 None
用於鄰居搜尋的平行作業數。
None表示 1,除非在joblib.parallel_backend內容中。-1表示使用所有處理器。請參閱詞彙表以瞭解更多詳細資訊。不影響fit方法。
- 屬性:
- effective_metric_str 或可呼叫
要使用的距離度量。它將與
metric參數相同,或其同義詞,例如,如果metric參數設定為 ‘minkowski’ 且p參數設定為 2,則為 ‘euclidean’。- effective_metric_params_dict
度量函數的其他關鍵字引數。對於大多數度量,將與
metric_params參數相同,但也可能包含p參數值(如果effective_metric_屬性設定為 ‘minkowski’)。- n_features_in_int
在 fit 期間看到的特徵數量。
於 0.24 版本加入。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在fit期間看到的特徵名稱。僅當
X具有所有字串的特徵名稱時才定義。於 1.0 版本加入。
- n_samples_fit_int
擬合資料中的樣本數。
另請參閱
NearestNeighbors用於實作鄰居搜尋的非監督式學習器。
RadiusNeighborsRegressor基於固定半徑內的鄰居進行迴歸。
KNeighborsClassifier實作 k 最近鄰投票的分類器。
RadiusNeighborsClassifier實作給定半徑內鄰居投票的分類器。
注意
請參閱線上文件中的 最近鄰,以討論
algorithm和leaf_size的選擇。警告
關於最近鄰演算法,如果發現兩個鄰居(鄰居
k+1和k)具有相同的距離但標籤不同,則結果將取決於訓練資料的順序。https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
範例
>>> X = [[0], [1], [2], [3]] >>> y = [0, 0, 1, 1] >>> from sklearn.neighbors import KNeighborsRegressor >>> neigh = KNeighborsRegressor(n_neighbors=2) >>> neigh.fit(X, y) KNeighborsRegressor(...) >>> print(neigh.predict([[1.5]])) [0.5]
- fit(X, y)[原始碼]#
從訓練資料集擬合 k 最近鄰迴歸器。
- 參數:
- X形狀為 (n_samples, n_features) 或 (n_samples, n_samples) 的 {類陣列,稀疏矩陣},如果 metric=’precomputed’
訓練資料。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的 {類陣列,稀疏矩陣}
目標值。
- 回傳值:
- selfKNeighborsRegressor
擬合的 k 最近鄰迴歸器。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,了解路由機制如何運作。
- 回傳值:
- routingMetadataRequest
一個封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
若為 True,將回傳此估算器及其包含的子物件(也是估算器)的參數。
- 回傳值:
- paramsdict
參數名稱對應到其值的字典。
- kneighbors(X=None, n_neighbors=None, return_distance=True)[原始碼]#
尋找一個點的 K 個鄰居。
回傳每個點的鄰居索引和距離。
- 參數:
- X{類陣列, 稀疏矩陣},形狀 (n_queries, n_features),或如果 metric == ‘precomputed’ 則為 (n_queries, n_indexed),預設值為 None
查詢點或點的集合。如果未提供,則會回傳每個索引點的鄰居。在這種情況下,查詢點不會被視為自己的鄰居。
- n_neighborsint,預設值為 None
每個樣本所需的鄰居數量。預設值為傳遞給建構子的值。
- return_distancebool,預設值為 True
是否回傳距離。
- 回傳值:
- neigh_dist形狀為 (n_queries, n_neighbors) 的 ndarray
表示到點的長度的陣列,僅在 return_distance=True 時存在。
- neigh_ind形狀為 (n_queries, n_neighbors) 的 ndarray
母體矩陣中最近點的索引。
範例
在以下範例中,我們從代表我們資料集的陣列建構一個 NearestNeighbors 類別,並詢問哪個點離 [1,1,1] 最近
>>> samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=1) >>> neigh.fit(samples) NearestNeighbors(n_neighbors=1) >>> print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]]))
如您所見,它回傳 [[0.5]] 和 [[2]],這表示該元素距離為 0.5,並且是樣本的第三個元素(索引從 0 開始)。您也可以查詢多個點
>>> X = [[0., 1., 0.], [1., 0., 1.]] >>> neigh.kneighbors(X, return_distance=False) array([[1], [2]]...)
- kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')[原始碼]#
計算 X 中點的 k-鄰居(加權)圖。
- 參數:
- X{類陣列, 稀疏矩陣},形狀 (n_queries, n_features),或如果 metric == ‘precomputed’ 則為 (n_queries, n_indexed),預設值為 None
查詢點或點的集合。如果未提供,則會回傳每個索引點的鄰居。在這種情況下,查詢點不會被視為自己的鄰居。對於
metric='precomputed',形狀應為 (n_queries, n_indexed)。否則,形狀應為 (n_queries, n_features)。- n_neighborsint,預設值為 None
每個樣本的鄰居數量。預設值為傳遞給建構子的值。
- mode{‘connectivity’, ‘distance’},預設值為 ‘connectivity’
回傳矩陣的類型:‘connectivity’ 將回傳包含 1 和 0 的連接矩陣,在 ‘distance’ 中,邊是點之間的距離,距離的類型取決於 NearestNeighbors 類別中選取的 metric 參數。
- 回傳值:
- A形狀為 (n_queries, n_samples_fit) 的稀疏矩陣
n_samples_fit是擬合資料中的樣本數。A[i, j]給出連接i到j的邊的權重。矩陣為 CSR 格式。
另請參閱
NearestNeighbors.radius_neighbors_graph計算 X 中點的鄰居(加權)圖。
範例
>>> X = [[0], [3], [1]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=2) >>> neigh.fit(X) NearestNeighbors(n_neighbors=2) >>> A = neigh.kneighbors_graph(X) >>> A.toarray() array([[1., 0., 1.], [0., 1., 1.], [1., 0., 1.]])
- predict(X)[原始碼]#
預測所提供資料的目標值。
- 參數:
- X{類陣列, 稀疏矩陣},形狀 (n_queries, n_features),或如果 metric == ‘precomputed’ 則為 (n_queries, n_indexed),或 None
測試樣本。如果為
None,則會回傳所有索引點的預測;在這種情況下,點不會被視為自己的鄰居。
- 回傳值:
- y形狀為 (n_queries,) 或 (n_queries, n_outputs) 的 ndarray,dtype=int
目標值。
- score(X, y, sample_weight=None)[原始碼]#
回傳預測的決定係數。
決定係數 \(R^2\) 定義為 \((1 - \frac{u}{v})\),其中 \(u\) 是殘差平方和
((y_true - y_pred)** 2).sum(),而 \(v\) 是總平方和((y_true - y_true.mean()) ** 2).sum()。最佳可能分數為 1.0,且可能為負數(因為模型可能任意地更差)。一個總是預測y的預期值,而不考慮輸入特徵的常數模型,將獲得 0.0 的 \(R^2\) 分數。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。對於某些估算器,這可能是預先計算的核矩陣或形狀為
(n_samples, n_samples_fitted)的通用物件清單,其中n_samples_fitted是估算器擬合中使用的樣本數。- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
X的真實值。- sample_weight形狀為 (n_samples,) 的類陣列,預設值為 None
樣本權重。
- 回傳值:
- scorefloat
self.predict(X)相對於y的 \(R^2\)。
注意
當在回歸器上呼叫
score時使用的 \(R^2\) 分數,從 0.23 版本開始使用multioutput='uniform_average',以與r2_score的預設值保持一致。這會影響所有多輸出回歸器的score方法(除了MultiOutputRegressor)。
- set_params(**params)[原始碼]#
設定此估算器的參數。
此方法適用於簡單的估算器以及巢狀物件(例如
Pipeline)。後者的參數形式為<component>__<parameter>,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器參數。
- 回傳值:
- self估算器實例
估算器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KNeighborsRegressor[原始碼]#
請求傳遞給
score方法的中繼資料。請注意,只有在
enable_metadata_routing=True時此方法才相關(請參閱sklearn.set_config)。請參閱使用者指南,了解路由機制如何運作。每個參數的選項如下
True:請求元數據,如果提供,則傳遞給score。如果未提供元數據,則會忽略請求。False:不請求元數據,且元估計器不會將其傳遞給score。None:不請求元數據,如果使用者提供元數據,則元估計器會引發錯誤。str:應使用此指定的別名,而不是原始名稱,將元數據傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留現有的請求。這允許您更改某些參數的請求,而不更改其他參數。在 1.3 版本中新增。
注意
只有當此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline- 參數:
- sample_weightstr、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
用於
score中sample_weight參數的元數據路由。
- 回傳值:
- selfobject
更新後的物件。