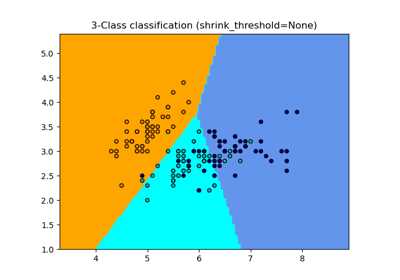
最近質心#
- class sklearn.neighbors.NearestCentroid(metric='euclidean', *, shrink_threshold=None, priors='uniform')[原始碼]#
最近質心分類器。
每個類別都以其質心表示,測試樣本會被分類到最近質心的類別。
在使用者指南中閱讀更多資訊。
- 參數:
- metric{“euclidean”, “manhattan”}, default=”euclidean”
用於計算距離的度量。
如果
metric="euclidean",則每個類別對應樣本的質心為算術平均值,可最小化平方 L1 距離的總和。如果metric="manhattan",則質心為各特徵的中位數,可最小化 L1 距離的總和。在 1.5 版本中變更:除了
"euclidean"和"manhattan"之外的所有度量標準均已棄用,現在會引發錯誤。在 0.19 版本中變更:
metric='precomputed'已棄用,現在會引發錯誤。- shrink_thresholdfloat,預設值=None
用於縮減質心以移除特徵的閾值。
- priors{"uniform", "empirical"} 或形狀為 (n_classes,) 的類陣列,預設值="uniform"
類別先驗機率。預設情況下,類別比例是從訓練資料中推斷而來。
在 1.6 版本中新增。
- 屬性:
- centroids_形狀為 (n_classes, n_features) 的類陣列
每個類別的質心。
- classes_形狀為 (n_classes,) 的陣列
唯一的類別標籤。
- n_features_in_int
在 fit 期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。只有當
X具有全部為字串的特徵名稱時才會定義。在 1.0 版本中新增。
- deviations_形狀為 (n_classes, n_features) 的 ndarray
每個類別的質心與整體質心的偏差(或縮減)。如果
shrink_threshold=None,則等於方程式 (18.4);否則等於 [2] 第 653 頁的 (18.5)。可用於識別用於分類的特徵。在 1.6 版本中新增。
- within_class_std_dev_形狀為 (n_features,) 的 ndarray
輸入資料的合併或類內標準差。
在 1.6 版本中新增。
- class_prior_形狀為 (n_classes,) 的 ndarray
類別先驗機率。
在 1.6 版本中新增。
另請參閱
K近鄰分類器最近鄰分類器。
註解
當用於具有 tf-idf 向量的文本分類時,此分類器也稱為 Rocchio 分類器。
參考文獻
[1] Tibshirani, R., Hastie, T., Narasimhan, B., & Chu, G. (2002). Diagnosis of multiple cancer types by shrunken centroids of gene expression. Proceedings of the National Academy of Sciences of the United States of America, 99(10), 6567-6572. The National Academy of Sciences.
[2] Hastie, T., Tibshirani, R., Friedman, J. (2009). The Elements of Statistical Learning Data Mining, Inference, and Prediction. 2nd Edition. New York, Springer.
範例
>>> from sklearn.neighbors import NearestCentroid >>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = NearestCentroid() >>> clf.fit(X, y) NearestCentroid() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[原始碼]#
將決策函數套用到樣本陣列。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
樣本陣列(測試向量)。
- 返回:
- y_scores形狀為 (n_samples,) 或 (n_samples, n_classes) 的 ndarray
每個樣本與每個類別相關的決策函數值。在二類情況下,形狀為
(n_samples,),給出正類的對數似然比。
- fit(X, y)[原始碼]#
根據給定的訓練資料擬合 NearestCentroid 模型。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
訓練向量,其中
n_samples是樣本數量,n_features是特徵數量。請注意,質心縮減不能與稀疏矩陣一起使用。- y形狀為 (n_samples,) 的類陣列
目標值。
- 返回:
- self物件
已擬合的估計器。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查閱使用手冊,了解路由機制如何運作。
- 返回:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設值=True
如果為 True,將會傳回此估計器及其包含的子物件(即估計器)的參數。
- 返回:
- paramsdict
對應到其值的參數名稱。
- predict(X)[原始碼]#
對測試向量
X的陣列執行分類。傳回
X中每個樣本的預測類別C。- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
輸入資料。
- 返回:
- y_pred形狀為 (n_samples,) 的 ndarray
預測的類別。
- predict_log_proba(X)[原始碼]#
估計對數類別機率。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
輸入資料。
- 返回:
- y_log_proba形狀為 (n_samples, n_classes) 的 ndarray
估計的對數機率。
- predict_proba(X)[原始碼]#
估計類別機率。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
輸入資料。
- 返回:
- y_proba形狀為 (n_samples, n_classes) 的 ndarray
模型中每個類別的樣本機率估計值,其中類別的順序與
self.classes_中的順序相同。
- score(X, y, sample_weight=None)[原始碼]#
返回給定測試數據和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為您需要每個樣本的每個標籤集都被正確預測。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
X的真實標籤。- sample_weight形狀為 (n_samples,) 的類陣列,預設值為 None
樣本權重。
- 返回:
- scorefloat
關於
y的self.predict(X)的平均準確度。
- set_params(**params)[原始碼]#
設定此估算器的參數。
此方法適用於簡單的估算器以及巢狀物件(例如
Pipeline)。後者的參數形式為<component>__<parameter>,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器參數。
- 返回:
- self估算器實例
估算器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') NearestCentroid[原始碼]#
請求傳遞給
score方法的中繼資料。請注意,只有當
enable_metadata_routing=True時此方法才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制如何運作。每個參數的選項為
True:請求中繼資料,如果提供,則傳遞給score。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估算器不會將其傳遞給score。None:不請求中繼資料,如果使用者提供,元估算器將引發錯誤。str:中繼資料應使用此給定別名傳遞給元估算器,而不是原始名稱。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您更改某些參數的請求,而不更改其他參數。在 1.3 版本中新增。
請注意
只有當此估算器用作元估算器的子估算器時,此方法才相關,例如在
Pipeline中使用。否則,它不會產生任何影響。- 參數:
- sample_weightstr、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的中繼資料路由。
- 返回:
- self物件
更新後的物件。