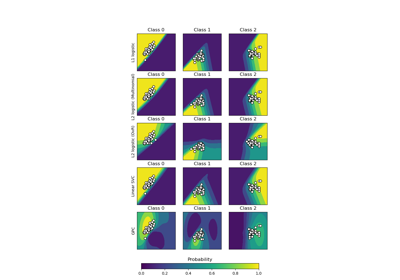
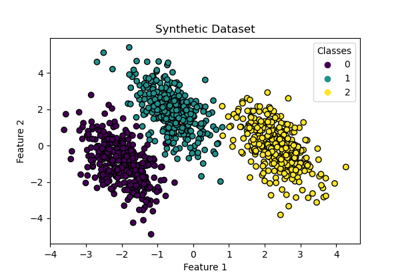
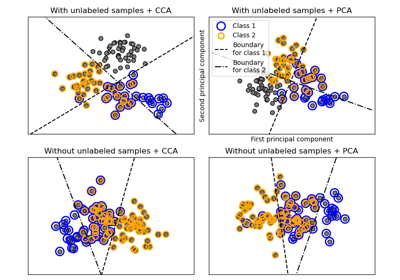
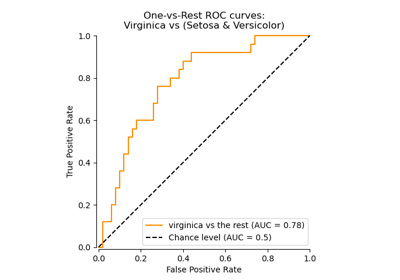
一對多分類器#
- class sklearn.multiclass.OneVsRestClassifier(estimator, *, n_jobs=None, verbose=0)[原始碼]#
一對多 (One-vs-the-rest, OvR) 多類別策略。
此策略又稱為一對全 (one-vs-all),其作法是針對每個類別訓練一個分類器。對於每個分類器,該類別會與所有其他類別進行擬合。除了計算效率高(只需要
n_classes個分類器)之外,此方法的一個優點是其可解釋性。由於每個類別僅由一個分類器表示,因此可以透過檢查其對應的分類器來了解該類別。這是多類別分類最常用的策略,也是一個合理的預設選擇。OneVsRestClassifier 也可用於多標籤分類。若要使用此功能,請在呼叫
.fit時提供目標y的指示矩陣。換句話說,目標標籤應格式化為 2D 二元 (0/1) 矩陣,其中 [i, j] == 1 表示樣本 i 中存在標籤 j。此估算器使用二元相關方法來執行多標籤分類,該方法涉及針對每個標籤獨立訓練一個二元分類器。請在使用者指南中閱讀更多資訊。
- 參數:
- estimator估算器物件
實作 fit 的迴歸器或分類器。當傳遞分類器時,將優先使用 decision_function,如果不可用,則會回退到 predict_proba。當傳遞迴歸器時,將使用 predict。
- n_jobsint,預設值=None
用於計算的作業數:
n_classes個一對多問題會平行計算。None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。請參閱詞彙表以了解更多詳細資訊。在 0.20 版本中變更:
n_jobs預設值從 1 變更為 None- verboseint,預設值=0
詳細程度,如果非零,則會列印進度訊息。低於 50 時,輸出會傳送到 stderr。否則,輸出會傳送到 stdout。訊息的頻率會隨著詳細程度增加,在 10 時回報所有迭代。請參閱
joblib.Parallel以了解更多詳細資訊。在 1.1 版本中新增。
- 屬性:
- estimators_
n_classes個估算器的清單 用於預測的估算器。
- classes_陣列,形狀 = [
n_classes] 類別標籤。
n_classes_int類別數量。
- label_binarizer_LabelBinarizer 物件
用於將多類別標籤轉換為二元標籤及其反向轉換的物件。
multilabel_布林值是否為多標籤分類器。
- n_features_in_int
在 fit 期間看到的特徵數量。只有在底層估算器在 fit 時公開此屬性時才會定義。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。只有在底層估算器在 fit 時公開此屬性時才會定義。
在 1.0 版本中新增。
- estimators_
另請參閱
一對一分類器 (OneVsOneClassifier)一對一多類別策略。
輸出碼分類器 (OutputCodeClassifier)(錯誤校正) 輸出碼多類別策略。
sklearn.multioutput.MultiOutputClassifier擴展估算器以進行多標籤分類的替代方法。
sklearn.preprocessing.MultiLabelBinarizer將可迭代項的迭代轉換為二元指示矩陣。
範例
>>> import numpy as np >>> from sklearn.multiclass import OneVsRestClassifier >>> from sklearn.svm import SVC >>> X = np.array([ ... [10, 10], ... [8, 10], ... [-5, 5.5], ... [-5.4, 5.5], ... [-20, -20], ... [-15, -20] ... ]) >>> y = np.array([0, 0, 1, 1, 2, 2]) >>> clf = OneVsRestClassifier(SVC()).fit(X, y) >>> clf.predict([[-19, -20], [9, 9], [-5, 5]]) array([2, 0, 1])
- decision_function(X)[原始碼]#
OneVsRestClassifier 的決策函數。
傳回每個樣本與每個類別決策邊界的距離。這只能與實作
decision_function方法的估算器一起使用。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入資料。
- 傳回值:
- T形狀為 (n_samples, n_classes) 或 (n_samples,)(用於二元分類)的類陣列。
呼叫最終估算器的
decision_function的結果。在 0.19 版本中變更:輸出形狀變更為
(n_samples,)以符合 scikit-learn 對於二元分類的慣例。
- fit(X, y, **fit_params)[原始碼]#
擬合底層估算器。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
資料。
- y形狀為 (n_samples,) 或 (n_samples, n_classes) 的 {類陣列、稀疏矩陣}
多類別目標。指示矩陣會開啟多標籤分類。
- **fit_paramsdict
傳遞給每個子估計器的
estimator.fit方法的參數。1.4 版本新增: 僅當
enable_metadata_routing=True時可用。詳情請參閱 Metadata Routing 使用者指南。
- 傳回值:
- self物件
已擬合估計器的實例。
- get_metadata_routing()[原始碼]#
取得此物件的元數據路由。
請查看使用者指南,了解路由機制如何運作。
1.4 版本新增。
- 傳回值:
- routingMetadataRouter
一個封裝路由資訊的
MetadataRouter。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設為 True
如果為 True,將返回此估計器和包含的子物件(為估計器)的參數。
- 傳回值:
- paramsdict
參數名稱對應到其值。
- property multilabel_#
是否為多標籤分類器。
- property n_classes_#
類別數量。
- partial_fit(X, y, classes=None, **partial_fit_params)[原始碼]#
部分擬合底層估計器。
當記憶體不足以訓練所有數據時應使用此方法。可以通過多次迭代傳入數據區塊。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
資料。
- y形狀為 (n_samples,) 或 (n_samples, n_classes) 的 {類陣列、稀疏矩陣}
多類別目標。指示矩陣會開啟多標籤分類。
- classes陣列,形狀 (n_classes, )
所有 partial_fit 呼叫的類別。可通過
np.unique(y_all)獲得,其中 y_all 是整個資料集的目標向量。此參數僅在第一次呼叫 partial_fit 時需要,在後續呼叫中可以省略。- **partial_fit_paramsdict
傳遞給每個子估計器的
estimator.partial_fit方法的參數。1.4 版本新增: 僅當
enable_metadata_routing=True時可用。詳情請參閱 Metadata Routing 使用者指南。
- 傳回值:
- self物件
部分擬合估計器的實例。
- predict(X)[原始碼]#
使用底層估計器預測多類目標。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
資料。
- 傳回值:
- y形狀為 (n_samples,) 或 (n_samples, n_classes) 的 {類陣列、稀疏矩陣}
預測的多類目標。
- predict_proba(X)[原始碼]#
機率估計。
所有類別的返回估計值都按類別標籤排序。
請注意,在多標籤的情況下,每個樣本可以有任意數量的標籤。這返回給定樣本具有該標籤的邊際機率。例如,兩個標籤都有 90% 的機率適用於給定樣本是完全一致的。
在單標籤多類別的情況下,返回矩陣的行總和為 1。
- 參數:
- X形狀為 (n_samples, n_features) 的 {類陣列、稀疏矩陣}
輸入資料。
- 傳回值:
- T類似陣列,形狀為 (n_samples, n_classes)
返回模型中每個類別的樣本機率,其中類別的排序方式與
self.classes_中相同。
- score(X, y, sample_weight=None)[原始碼]#
返回給定測試數據和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為你需要正確預測每個樣本的每個標籤集。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。
- y類似陣列,形狀為 (n_samples,) 或 (n_samples, n_outputs)
X的真實標籤。- sample_weight類似陣列,形狀為 (n_samples,),預設為 None
樣本權重。
- 傳回值:
- scorefloat
self.predict(X)相對於y的平均準確度。
- set_params(**params)[原始碼]#
設定此估計器的參數。
此方法適用於簡單的估算器,以及巢狀物件 (例如
Pipeline)。後者的參數形式為<component>__<parameter>,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器的參數。
- 傳回值:
- self估算器實例
估算器實例。
- set_partial_fit_request(*, classes: bool | None | str = '$UNCHANGED$') OneVsRestClassifier[原始碼]#
請求傳遞到
partial_fit方法的中繼資料。請注意,只有當
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制的運作方式。每個參數的選項如下:
True:請求中繼資料,如果提供則傳遞到partial_fit。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估算器不會將其傳遞到partial_fit。None:不請求中繼資料,如果使用者提供,則元估算器會引發錯誤。str:中繼資料應以給定的別名而非原始名稱傳遞到元估算器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您變更某些參數的請求,而不變更其他參數的請求。在 1.3 版本中新增。
注意
只有當此估算器用作元估算器的子估算器時,此方法才相關,例如在
Pipeline內部使用。否則,它沒有任何效果。- 參數:
- classesstr、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
用於
partial_fit中classes參數的中繼資料路由。
- 傳回值:
- self物件
更新後的物件。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') OneVsRestClassifier[原始碼]#
請求傳遞到
score方法的中繼資料。請注意,只有當
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制的運作方式。每個參數的選項如下:
True:請求中繼資料,如果提供則傳遞到score。如果未提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估算器不會將其傳遞到score。None:不請求中繼資料,如果使用者提供,則元估算器會引發錯誤。str:中繼資料應以給定的別名而非原始名稱傳遞到元估算器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 會保留現有的請求。這允許您變更某些參數的請求,而不變更其他參數的請求。在 1.3 版本中新增。
注意
只有當此估算器用作元估算器的子估算器時,此方法才相關,例如在
Pipeline內部使用。否則,它沒有任何效果。- 參數:
- sample_weightstr、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
用於
score中sample_weight參數的中繼資料路由。
- 傳回值:
- self物件
更新後的物件。