2.9. 神經網路模型(非監督式)#
2.9.1. 受限玻爾茲曼機#
受限玻爾茲曼機 (RBM) 是基於機率模型的非監督式非線性特徵學習器。 RBM 或 RBM 層次結構提取的特徵在饋入線性分類器(例如線性 SVM 或感知器)時,通常會產生良好的結果。
該模型假設輸入的分配。目前,scikit-learn 僅提供 BernoulliRBM,它假設輸入是二元值或介於 0 和 1 之間的值,每個值都編碼特定特徵開啟的機率。
RBM 嘗試使用特定的圖形模型最大化資料的可能性。所使用的參數學習演算法(隨機最大似然)可防止表示偏離輸入資料太遠,這使得它們捕獲有趣的規律性,但使得該模型對於小型資料集不太有用,並且通常對密度估計沒有用處。
該方法因使用獨立 RBM 的權重初始化深度神經網路而廣受歡迎。此方法稱為非監督式預訓練。

範例
2.9.1.1. 圖形模型和參數化#
RBM 的圖形模型是一個完全連接的二分圖。
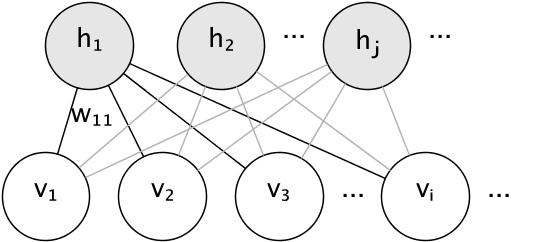
節點是隨機變數,其狀態取決於與之連接的其他節點的狀態。 因此,該模型由連接的權重以及每個可見和隱藏單元的一個截距(偏差)項參數化,為簡單起見,圖像中省略了這些項。
能量函數測量聯合分配的品質
在上面的公式中,\(\mathbf{b}\) 和 \(\mathbf{c}\) 分別是可見層和隱藏層的截距向量。 模型的聯合機率是根據能量定義的
受限一詞是指模型的二分結構,該結構禁止隱藏單元之間或可見單元之間的直接交互。 這表示假設以下條件獨立性
二分結構允許使用高效的區塊 Gibbs 採樣進行推論。
2.9.1.2. 柏努利受限玻爾茲曼機#
在 BernoulliRBM 中,所有單元都是二元隨機單元。 這表示輸入資料應該是二進位,或是介於 0 和 1 之間的實值,表示可見單元開啟或關閉的機率。 這是一個很好的字元識別模型,其中重點在於哪些像素是活躍的,哪些像素不是活躍的。 對於自然場景的圖像,由於背景、深度以及相鄰像素傾向於採用相同的值,因此它不再適用。
每個單元的條件機率分布由它接收的輸入的邏輯 Sigmoid 啟動函數給出
其中 \(\sigma\) 是邏輯 Sigmoid 函數
2.9.1.3. 隨機最大似然學習#
在 BernoulliRBM 中實現的訓練演算法稱為隨機最大似然 (SML) 或持久對比發散 (PCD)。 直接優化最大似然是不可行的,因為資料似然的形式為
為簡單起見,上面的方程式是針對單個訓練範例寫的。 相對於權重的梯度由兩個項組成,對應於上面的兩個項。 由於它們各自的符號,它們通常稱為正梯度和負梯度。 在此實作中,梯度是根據樣本的迷你批次估算的。
在最大化對數似然時,正梯度使模型偏愛與觀察到的訓練資料相容的隱藏狀態。 由於 RBM 的二分結構,可以有效率地計算它。 然而,負梯度是難以處理的。 其目標是降低模型偏愛的聯合狀態的能量,從而使其保持與資料的一致性。 可以使用區塊 Gibbs 採樣,透過反覆採樣 \(v\) 和 \(h\) 給定另一個來使用馬可夫鏈蒙地卡羅來近似它,直到鏈混合。 以這種方式產生的樣本有時被稱為虛擬粒子。 這是沒有效率的,並且很難確定馬可夫鏈是否混合。
對比發散方法建議在少量迭代 \(k\)(通常甚至為 1)之後停止鏈。 此方法快速且變異數低,但樣本遠離模型分布。
持久對比發散解決了這個問題。 在每次需要梯度時,我們不是啟動新的鏈並僅執行一個 Gibbs 採樣步驟,而是在 PCD 中,我們保留一些在每次權重更新後更新 \(k\) 個 Gibbs 步驟的鏈(虛擬粒子)。 這讓粒子可以更徹底地探索空間。
參考文獻
「深度信念網路的快速學習演算法」,G. Hinton、S. Osindero、Y.-W. Teh,2006
「使用似然梯度的近似值訓練受限玻爾茲曼機」,T. Tieleman,2008