1.16. 機率校準#
在執行分類時,您通常不僅想要預測類別標籤,還想獲得相應標籤的機率。此機率會給您一些關於預測的信心。某些模型可能無法給出良好的類別機率估計,有些甚至不支援機率預測(例如,某些 SGDClassifier 的實例)。校準模組可讓您更好地校準給定模型的機率,或新增對機率預測的支援。
良好校準的分類器是機率分類器,其 predict_proba 方法的輸出可以直接解釋為信賴度。例如,良好校準的(二元)分類器應該對樣本進行分類,使得在給定 predict_proba 值接近(例如)0.8 的樣本中,大約 80% 實際上屬於正類別。
在我們展示如何重新校準分類器之前,我們首先需要一種方法來檢測分類器校準的良好程度。
注意
嚴格適當的機率預測評分規則,如 sklearn.metrics.brier_score_loss 和 sklearn.metrics.log_loss,同時評估模型的校準(可靠性)和區別能力(解析度),以及資料的隨機性(不確定性)。這遵循 Murphy [1] 的著名 Brier 分數分解。由於不清楚哪個術語佔主導地位,因此該分數對於單獨評估校準的用途有限(除非計算分解的每個術語)。例如,較低的 Brier 損失並不一定表示模型校準得更好,它也可能表示校準較差的模型具有更高的區別能力,例如使用更多的特徵。
1.16.1. 校準曲線#
校準曲線,也稱為可靠性圖(Wilks 1995 [2]),比較二元分類器的機率預測校準程度。它在 y 軸上繪製正標籤的頻率(更精確地說,是對條件事件機率 \(P(Y=1|\text{predict_proba})\) 的估計),並在 x 軸上繪製模型的預測機率 predict_proba。棘手的部分是獲取 y 軸的值。在 scikit-learn 中,這是通過對預測進行分箱來實現的,以便 x 軸表示每個箱中的平均預測機率。然後,y 軸是給定該箱預測的正例比例,即類別為正類別的樣本比例(在每個箱中)。
頂部校準曲線圖是使用 CalibrationDisplay.from_estimator 建立的,它使用 calibration_curve 來計算每個箱的平均預測機率和正例比例。CalibrationDisplay.from_estimator 將已擬合的分類器作為輸入,用於計算預測機率。因此,分類器必須具有 predict_proba 方法。對於少數沒有 predict_proba 方法的分類器,可以使用 CalibratedClassifierCV 來校準分類器輸出為機率。
底部直方圖顯示每個預測機率箱中的樣本數,從而深入了解每個分類器的行為。
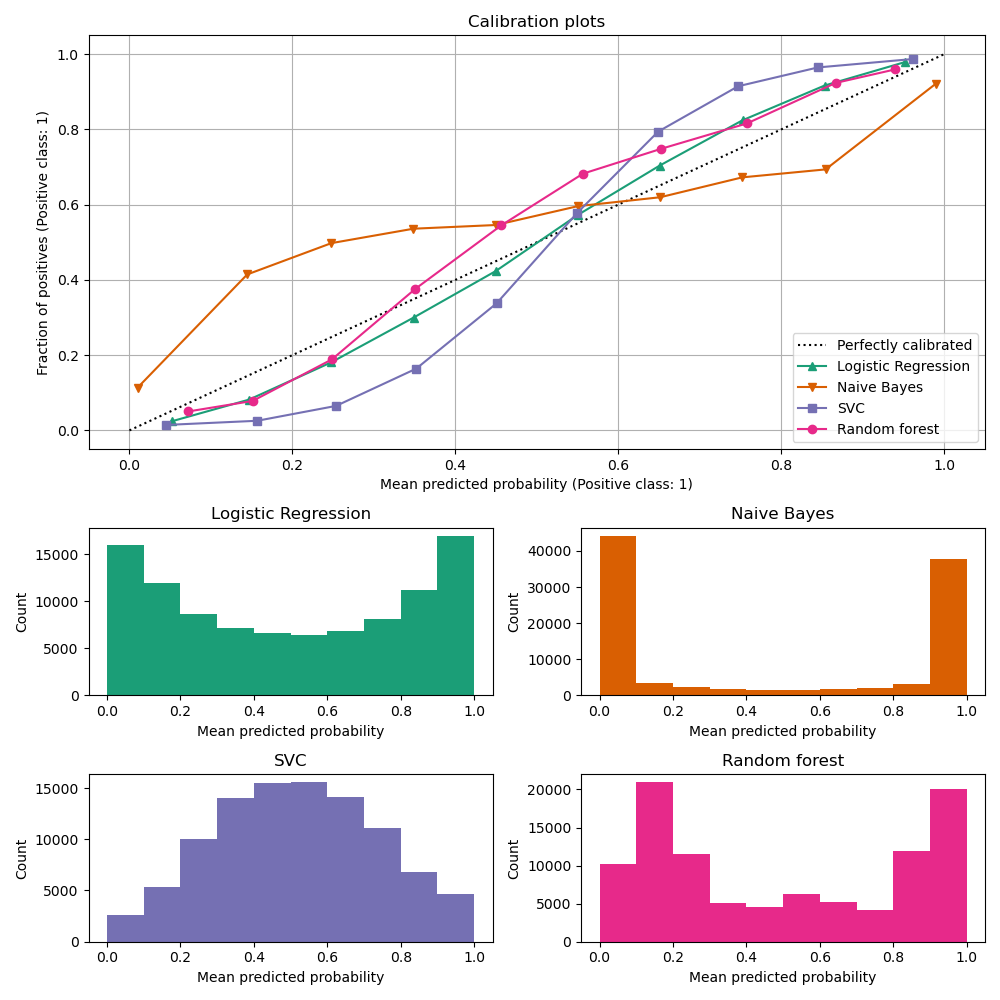
LogisticRegression 更可能自行返回良好校準的預測,因為它具有其損失的典型連結函數,即 Log 損失 的 logit 連結。在未懲罰的情況下,這會導致所謂的平衡性質,請參閱 [8] 和 羅吉斯迴歸。在上面的圖中,資料是根據線性機制產生的,這與 LogisticRegression 模型一致(模型是「良好指定的」),並且正則化參數 C 的值經過調整以適當(既不太強也不太低)。因此,此模型從其 predict_proba 方法返回準確的預測。與此相反,其他顯示的模型會返回有偏差的機率;每個模型的偏差不同。
GaussianNB(樸素貝氏)傾向於將機率推向 0 或 1(請注意直方圖中的計數)。這主要是因為它假設在給定類別的情況下特徵是有條件地獨立的,而此資料集中包含 2 個冗餘特徵,情況並非如此。
RandomForestClassifier 顯示相反的行為:直方圖在機率約 0.2 和 0.9 處顯示峰值,而接近 0 或 1 的機率非常罕見。Niculescu-Mizil 和 Caruana [3] 給出了解釋:「諸如 bagging 和隨機森林之類的方法,會平均一組基本模型的預測,因此難以做出接近 0 和 1 的預測,因為基礎模型中的變異會使應該接近零或一的預測值偏離這些值。由於預測值被限制在 [0,1] 的區間內,因此變異所造成的誤差在接近零和一時往往是單向的。例如,如果模型應該預測某個案例的 p = 0,則 bagging 實現此目的的唯一方法是所有 bagging 樹都預測為零。如果我們向 bagging 平均的樹中添加雜訊,則此雜訊將導致某些樹預測出大於 0 的值,從而使 bagged 集成模型的平均預測值偏離 0。我們在隨機森林中觀察到這種效應最為強烈,因為使用隨機森林訓練的基礎級樹由於特徵子集化而具有相對較高的變異數。」 因此,校準曲線顯示出特徵性的 S 形,表明分類器可以更信任其「直覺」,並返回通常更接近 0 或 1 的機率。
LinearSVC (SVC) 顯示出比隨機森林更明顯的 S 形曲線,這對於最大邊界方法來說是典型的(比較 Niculescu-Mizil 和 Caruana [3]),該方法側重於難以分類的樣本,這些樣本接近決策邊界(支援向量)。
1.16.2. 校準分類器#
校準分類器包括擬合一個迴歸器(稱為校準器),該迴歸器將分類器的輸出(由 decision_function 或 predict_proba 給出)映射到 [0, 1] 中的校準機率。用 \(f_i\) 表示給定樣本的分類器輸出,校準器嘗試預測條件事件機率 \(P(y_i = 1 | f_i)\)。
理想情況下,校準器在與最初用於擬合分類器的訓練數據獨立的數據集上進行擬合。這是因為分類器在其訓練數據上的表現會比新數據更好。因此,使用訓練數據的分類器輸出擬合校準器將導致有偏差的校準器,該校準器會映射到比應有的更接近 0 和 1 的機率。
1.16.3. 用法#
CalibratedClassifierCV 類別用於校準分類器。
CalibratedClassifierCV 使用交叉驗證方法,以確保始終使用無偏差的數據來擬合校準器。數據被分成 k 個 (train_set, test_set) 對(由 cv 確定)。當 ensemble=True(預設值)時,以下程序會針對每個交叉驗證分割獨立重複執行
base_estimator的克隆在訓練子集上進行訓練經過訓練的
base_estimator對測試子集進行預測預測值用於擬合校準器(sigmoid 或等張迴歸器)(當數據為多類別時,會為每個類別擬合校準器)
這會產生 k 個 (classifier, calibrator) 對的集成,其中每個校準器將其對應的分類器的輸出映射到 [0, 1]。每個對都暴露在 calibrated_classifiers_ 屬性中,其中每個條目都是一個經過校準的分類器,具有一個 predict_proba 方法,該方法輸出經過校準的機率。CalibratedClassifierCV 主要實例的 predict_proba 的輸出對應於 calibrated_classifiers_ 列表中 k 個估計器的預測機率的平均值。predict 的輸出是具有最高機率的類別。
當使用 ensemble=True 時,謹慎選擇 cv 非常重要。所有類別都應存在於每個分割的訓練和測試子集中。當訓練子集中不存在類別時,該分割的 (classifier, calibrator) 對該類別的預測機率將預設為 0。這會扭曲 predict_proba,因為它會在所有對中取平均值。當測試子集中不存在類別時,該類別的校準器(在該分割的 (classifier, calibrator) 對中)會使用沒有正類別的數據進行擬合。這會導致無效的校準。
當 ensemble=False 時,交叉驗證用於通過 cross_val_predict 獲取所有數據的「無偏差」預測。然後,這些無偏差預測值用於訓練校準器。屬性 calibrated_classifiers_ 僅包含一對 (classifier, calibrator) 對,其中分類器是使用所有數據訓練的 base_estimator。在這種情況下,CalibratedClassifierCV 的 predict_proba 的輸出是從單一 (classifier, calibrator) 對獲得的預測機率。
ensemble=True 的主要優勢是可以從傳統的集成效應中獲益(類似於 Bagging 元估計器)。產生的集成應既經過良好校準,又比 ensemble=False 稍微更準確。使用 ensemble=False 的主要優勢是計算方面的:它通過僅訓練單個基礎分類器和校準器對來減少總體擬合時間,減少最終模型大小並提高預測速度。
或者,可以通過使用 FrozenEstimator 作為 CalibratedClassifierCV(estimator=FrozenEstimator(estimator)) 來校準已經擬合的分類器。由使用者確保用於擬合分類器的數據與用於擬合迴歸器的數據是不相交的。用於擬合迴歸器的數據。
CalibratedClassifierCV 通過 method 參數支援使用兩種迴歸技術進行校準:"sigmoid" 和 "isotonic"。
1.16.3.1. Sigmoid#
sigmoid 迴歸器 method="sigmoid" 基於 Platt 的邏輯模型 [4]
其中 \(y_i\) 是樣本 \(i\) 的真實標籤,\(f_i\) 是樣本 \(i\) 的未校準分類器的輸出。\(A\) 和 \(B\) 是實數,在通過最大似然擬合迴歸器時確定。
sigmoid 方法假設 校準曲線 可以通過對原始預測應用 sigmoid 函數來校正。在 Platt 1999 年 [4] 的 2.1 節中,在各種基準數據集上使用常見核函數的 支援向量機 的情況下,已經從經驗上證明了這個假設是合理的,但不一定普遍成立。此外,如果校準誤差是對稱的,則邏輯模型效果最佳,這意味著每個二元類別的分類器輸出呈正態分佈且具有相同的變異數 [7]。這對於輸出沒有相同變異數的高度不平衡分類問題來說可能是一個問題。
一般來說,此方法對於小樣本量或當未校準模型不夠自信且對高輸出和低輸出具有相似的校準誤差時最有效。
1.16.3.2. 等張 (Isotonic)#
method="isotonic" 使用非參數的等張迴歸器,它會輸出一個階梯狀的非遞減函數,請參閱 sklearn.isotonic。它會最小化:
受限於當 \(\hat{f}_i \geq \hat{f}_j\) 時,\(f_i \geq f_j\) 成立。\(y_i\) 是樣本 \(i\) 的真實標籤,而 \(\hat{f}_i\) 是校準後分類器對於樣本 \(i\) 的輸出(即校準後的機率)。相較於 ‘sigmoid’,這種方法更為通用,因為唯一的限制是映射函數必須是單調遞增的。因此,它更強大,因為它可以修正未校準模型中的任何單調失真。然而,它更容易過度擬合,尤其是在小型數據集上 [6]。
總體而言,當有足夠的數據(大於約 1000 個樣本)以避免過度擬合時,‘isotonic’ 的表現會與 ‘sigmoid’ 一樣好或更好 [3]。
注意
對如 AUC 等排名指標的影響
通常預期校準不會影響諸如 ROC-AUC 等排名指標。但是,當使用 method="isotonic" 時,這些指標在校準後可能會有所不同,因為等張迴歸會在預測機率中引入聯繫 (ties)。這可以視為模型預測的不確定性範圍內。如果您嚴格想要保持排名,並因此保持 AUC 分數,請使用 method="sigmoid",它是一種嚴格單調的轉換,因此可以保持排名。
1.16.3.3. 多類別支援#
等張和 sigmoid 迴歸器都僅支援一維數據(例如,二元分類輸出),但如果 base_estimator 支援多類別預測,則會擴展到多類別分類。對於多類別預測,CalibratedClassifierCV 會以 OneVsRestClassifier 的方式為每個類別單獨校準 [5]。在預測機率時,每個類別的校準機率會單獨預測。由於這些機率不一定總和為 1,因此會執行後處理來正規化它們。
範例
參考文獻