2.6. 共變異數估計#
許多統計問題需要估計母體的共變異數矩陣,這可以視為估計資料集散佈圖的形狀。大多數時候,這種估計必須在樣本上完成,而樣本的屬性(大小、結構、同質性)對估計的品質有很大的影響。sklearn.covariance 套件提供了在各種設定下準確估計母體共變異數矩陣的工具。
我們假設觀測值是獨立且相同分佈的 (i.i.d.)。
2.6.1. 經驗共變異數#
已知資料集的共變異數矩陣可以透過古典的最大概似估計器(或「經驗共變異數」)很好地近似,前提是觀測值的數量相較於特徵(描述觀測值的變數)的數量足夠大。更精確地說,樣本的最大概似估計器是相應母體共變異數矩陣的漸近無偏估計器。
可以使用套件的 empirical_covariance 函式計算樣本的經驗共變異數矩陣,或者透過將 EmpiricalCovariance 物件與 EmpiricalCovariance.fit 方法擬合到資料樣本來計算。請注意,結果取決於資料是否已置中,因此您可能需要準確使用 assume_centered 參數。更精確地說,如果 assume_centered=False,則測試集應具有與訓練集相同的平均向量。如果沒有,則應由使用者將兩者置中,並應使用 assume_centered=True。
範例
請參閱 收縮共變異數估計:LedoitWolf vs OAS 與最大概似,以取得關於如何將
EmpiricalCovariance物件擬合到資料的範例。
2.6.2. 收縮共變異數#
2.6.2.1. 基本收縮#
儘管最大概似估計器是共變異數矩陣的漸近無偏估計器,但它並不是共變異數矩陣特徵值的良好估計器,因此從其反轉獲得的精度矩陣並不準確。有時,甚至會出現無法因數值原因反轉經驗共變異數矩陣的情況。為了避免此類反轉問題,引入了經驗共變異數矩陣的轉換:收縮。
在 scikit-learn 中,可以使用 shrunk_covariance 方法將此轉換(使用使用者定義的收縮係數)直接應用於預先計算的共變異數。此外,可以使用 ShrunkCovariance 物件及其 ShrunkCovariance.fit 方法,將共變異數的收縮估計器擬合到資料。同樣地,結果取決於資料是否已置中,因此您可能需要準確使用 assume_centered 參數。
在數學上,此收縮包括減少經驗共變異數矩陣的最小和最大特徵值之間的比例。可以透過根據給定的偏移簡單地移動每個特徵值來完成,這等效於尋找共變異數矩陣的 l2 懲罰最大概似估計器。在實務上,收縮歸結為一個簡單的凸轉換:\(\Sigma_{\rm shrunk} = (1-\alpha)\hat{\Sigma} + \alpha\frac{{\rm Tr}\hat{\Sigma}}{p}\rm Id\)。
選擇收縮量 \(\alpha\) 相當於設定偏差/變異數的權衡,這將在下面討論。
範例
請參閱 收縮共變異數估計:LedoitWolf vs OAS 與最大概似,以取得關於如何將
ShrunkCovariance物件擬合到資料的範例。
2.6.2.2. Ledoit-Wolf 收縮#
在他們 2004 年的論文 [1] 中,O. Ledoit 和 M. Wolf 提出了一個公式來計算最佳收縮係數 \(\alpha\),該係數可最小化估計和真實共變異數矩陣之間的均方誤差。
可以使用 ledoit_wolf 函式在樣本上計算共變異數矩陣的 Ledoit-Wolf 估計器,也可以透過將 LedoitWolf 物件擬合到同一樣本來獲得。
注意
母體共變異數矩陣為等向性時的情況
務必注意,當樣本數遠大於特徵數時,人們會預期不需要收縮。其背後的直覺是,如果母體共變異數是滿秩的,當樣本數增加時,樣本共變異數也會變成正定。因此,不需要收縮,而該方法應會自動執行此操作。
然而,當母體共變異數恰好是單位矩陣的倍數時,Ledoit-Wolf 程序的情況並非如此。在這種情況下,隨著樣本數量的增加,Ledoit-Wolf 收縮估計值會接近 1。這表示在 Ledoit-Wolf 的意義下,共變異數矩陣的最佳估計值是單位矩陣的倍數。由於母體共變異數已經是單位矩陣的倍數,因此 Ledoit-Wolf 解確實是一個合理的估計。
範例
請參閱收縮共變異數估計:LedoitWolf vs OAS 和最大似然法,其中有關於如何將
LedoitWolf物件擬合到資料,以及如何視覺化 Ledoit-Wolf 估計器在似然性方面的效能。
參考文獻
2.6.2.3. 神諭近似收縮#
在假設資料呈高斯分佈的情況下,Chen 等人 [2] 推導出一個公式,旨在選擇一個收縮係數,該係數會產生比 Ledoit 和 Wolf 公式所給定的均方誤差更小的均方誤差。由此產生的估計器稱為共變異數的神諭收縮近似估計器。
共變異數的 OAS 估計器可以在樣本上使用 oas 函數計算,該函數來自 sklearn.covariance 套件,或者可以透過將 OAS 物件擬合到同一個樣本中來獲得。
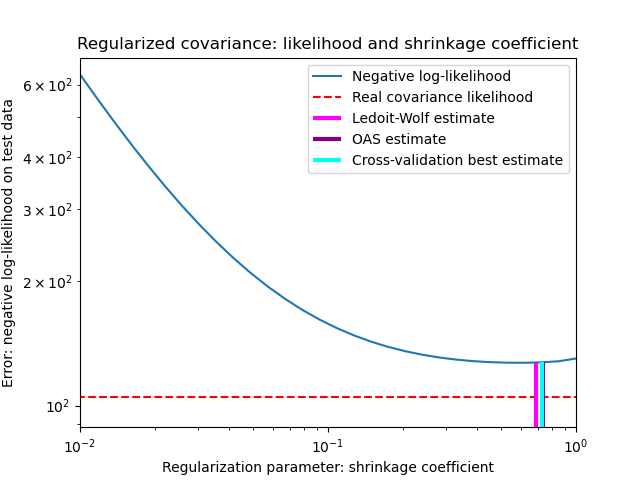
設定收縮時的偏差-變異數權衡:比較 Ledoit-Wolf 和 OAS 估計器的選擇#
參考文獻
範例
請參閱收縮共變異數估計:LedoitWolf vs OAS 和最大似然法,其中有關於如何將
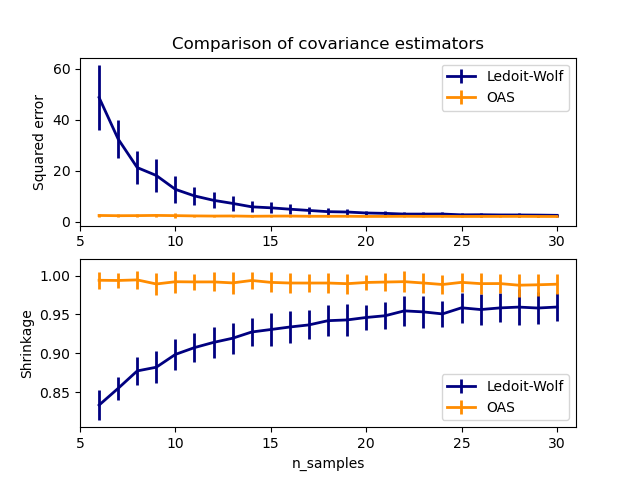
OAS物件擬合到資料的範例。請參閱Ledoit-Wolf 與 OAS 估計,以視覺化
LedoitWolf和OAS共變異數估計器之間均方誤差的差異。
2.6.3. 稀疏逆共變異數#
共變異數矩陣的矩陣逆矩陣(通常稱為精確度矩陣)與偏相關矩陣成正比。它給出了偏獨立關係。換句話說,如果兩個特徵在其他特徵的條件下是獨立的,則精確度矩陣中的相應係數將為零。這就是為什麼估計稀疏精確度矩陣有意義的原因:透過從資料中學習獨立關係,可以更好地條件化共變異數矩陣的估計。這被稱為共變異數選擇。
在小樣本情況下,其中 n_samples 的數量級為 n_features 或更小,稀疏逆共變異數估計器往往比收縮共變異數估計器效果更好。然而,在相反的情況下,或者對於高度相關的資料,它們在數值上可能不穩定。此外,與收縮估計器不同,稀疏估計器能夠恢復非對角結構。
GraphicalLasso 估計器使用 l1 懲罰來強制精確度矩陣的稀疏性:其 alpha 參數越高,精確度矩陣就越稀疏。相應的 GraphicalLassoCV 物件使用交叉驗證來自動設定 alpha 參數。
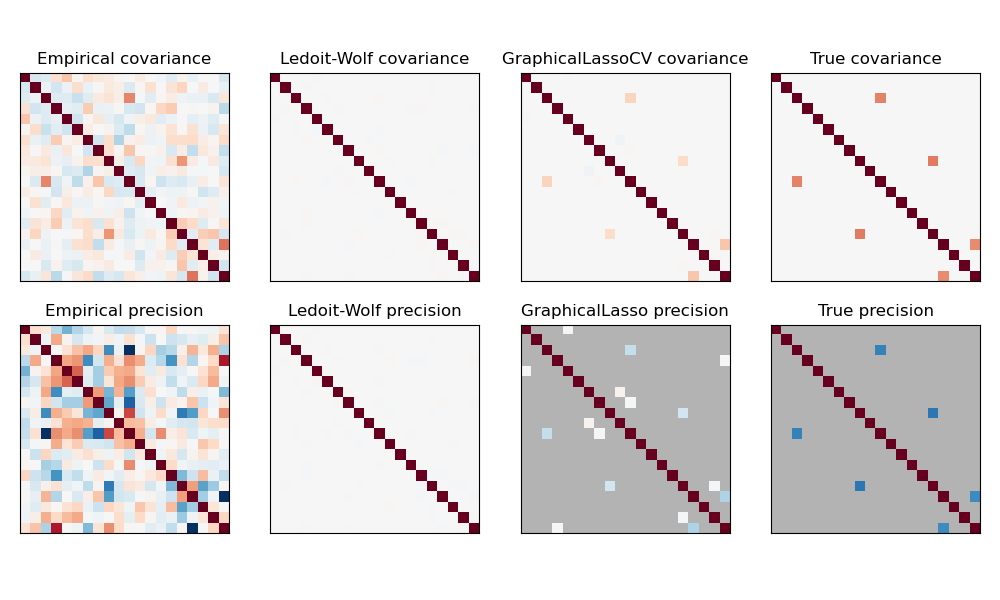
在非常小的樣本設定中,對共變異數和精確度矩陣的最大似然、收縮和稀疏估計進行比較。#
注意
結構復原
從資料中的相關性復原圖形結構是一項具有挑戰性的事情。如果您對此類復原感興趣,請記住
從相關矩陣復原比從共變異數矩陣復原更容易:在執行
GraphicalLasso之前,先將您的觀察結果標準化如果底層圖的節點具有比平均節點多得多的連線,則演算法將會遺漏其中一些連線。
如果您的觀察數量與底層圖中的邊緣數量相比不大,則您將無法復原它。
即使您處於有利的復原條件下,交叉驗證所選擇的 alpha 參數(例如使用
GraphicalLassoCV物件)也會導致選擇過多的邊緣。但是,相關的邊緣將具有比不相關的邊緣更大的權重。
數學公式如下
其中 \(K\) 是要估計的精確度矩陣,而 \(S\) 是樣本共變異數矩陣。\(\|K\|_1\) 是 \(K\) 的非對角係數絕對值的總和。用於解決此問題的演算法是 Friedman 2008 年《生物統計學》論文中的 GLasso 演算法。它與 R glasso 套件中的演算法相同。
範例
參考文獻
Friedman 等人,“使用圖形 Lasso 進行稀疏逆共變異數估計”,《生物統計學》9,第 432 頁,2008 年
2.6.4. 穩健共變異數估計#
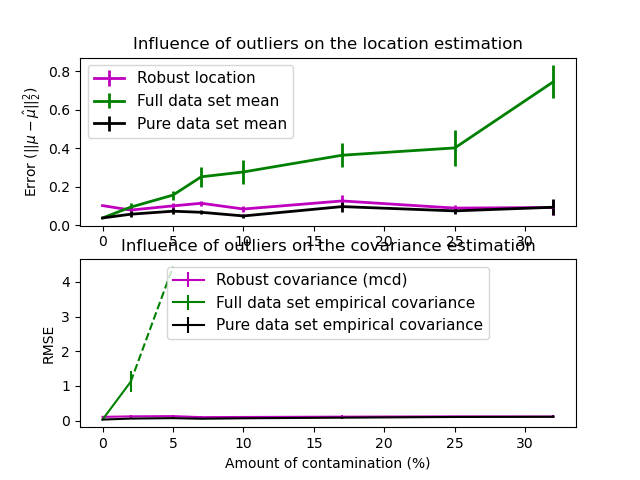
真實資料集通常容易受到測量或記錄錯誤的影響。由於各種原因,也可能出現規律但不常見的觀察結果。非常不常見的觀察結果稱為離群值。上面介紹的經驗共變異數估計器和收縮共變異數估計器對資料中離群值的存在非常敏感。因此,應使用穩健的共變異數估計器來估計其實際資料集的共變異數。或者,穩健的共變異數估計器可用於執行離群值檢測,並根據資料的進一步處理來丟棄/降低某些觀察結果的權重。
sklearn.covariance 套件實作了共變異數的穩健估計器,即最小共變異數行列式 [3]。
2.6.4.1. 最小共變異數行列式#
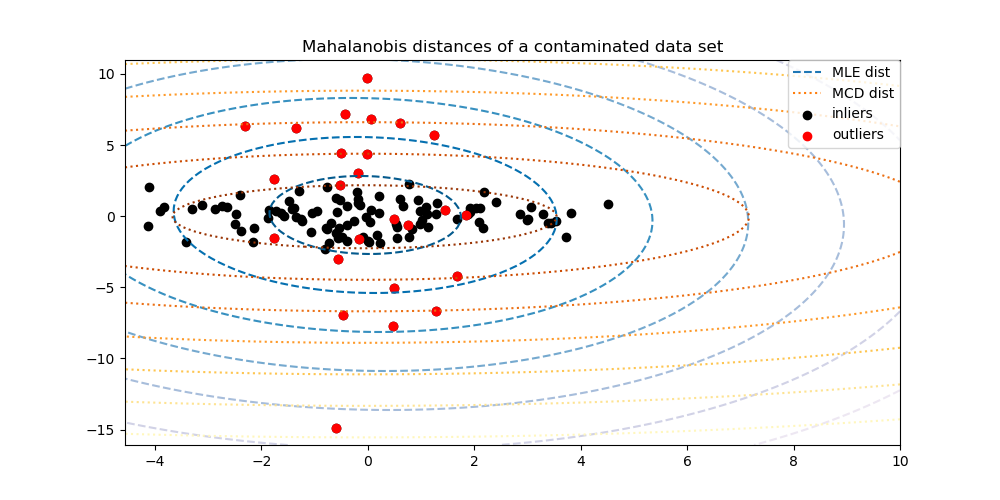
最小共變異數行列式估計器是 P.J. Rousseeuw 在 [3] 中引入的資料集共變異數的穩健估計器。其概念是找到給定比例 (h) 的「良好」觀察結果(不是離群值)並計算其經驗共變異數矩陣。然後對此經驗共變異數矩陣進行縮放,以補償所執行的觀察結果選擇(「一致性步驟」)。在計算最小共變異數行列式估計器之後,可以根據其馬氏距離來給予觀察結果權重,從而產生資料集的共變異數矩陣的重新加權估計(「重新加權步驟」)。
Rousseeuw 和 Van Driessen [4] 開發了 FastMCD 演算法,以計算最小共變異數行列式(Minimum Covariance Determinant,MCD)。當將 MCD 物件擬合到資料時,scikit-learn 中會使用此演算法。FastMCD 演算法同時也會計算資料集位置的穩健估計。
原始估計值可以透過 raw_location_ 和 raw_covariance_ 屬性存取,這些屬性是 MinCovDet 穩健共變異數估計器物件的屬性。
參考文獻
範例
請參閱 穩健對經驗共變異數估計,以了解如何將
MinCovDet物件擬合到資料,並了解即使存在離群值,估計值如何保持準確。請參閱 穩健共變異數估計和馬氏距離相關性,以視覺化
EmpiricalCovariance和MinCovDet共變異數估計器在馬氏距離方面的差異 (因此我們也能得到更精確的精度矩陣估計)。
離群值對位置和共變異數估計的影響 |
使用馬氏距離分離內部值和離群值 |
|---|---|
|
|