3.1. 交叉驗證:評估估計器效能#
學習預測函數的參數並在相同的資料上進行測試是一個方法上的錯誤:一個只會重複它剛剛看到的樣本標籤的模型將會擁有完美的分數,但無法預測任何在尚未看過的資料上有用的東西。這種情況稱為過擬合。為了避免這種情況,在執行(監督式)機器學習實驗時,通常的做法是保留一部分可用資料作為測試集 X_test, y_test。請注意,「實驗」一詞並非僅指學術用途,因為即使在商業環境中,機器學習通常也是從實驗開始的。以下是模型訓練中典型交叉驗證工作流程的流程圖。最佳參數可以透過網格搜尋技術來決定。
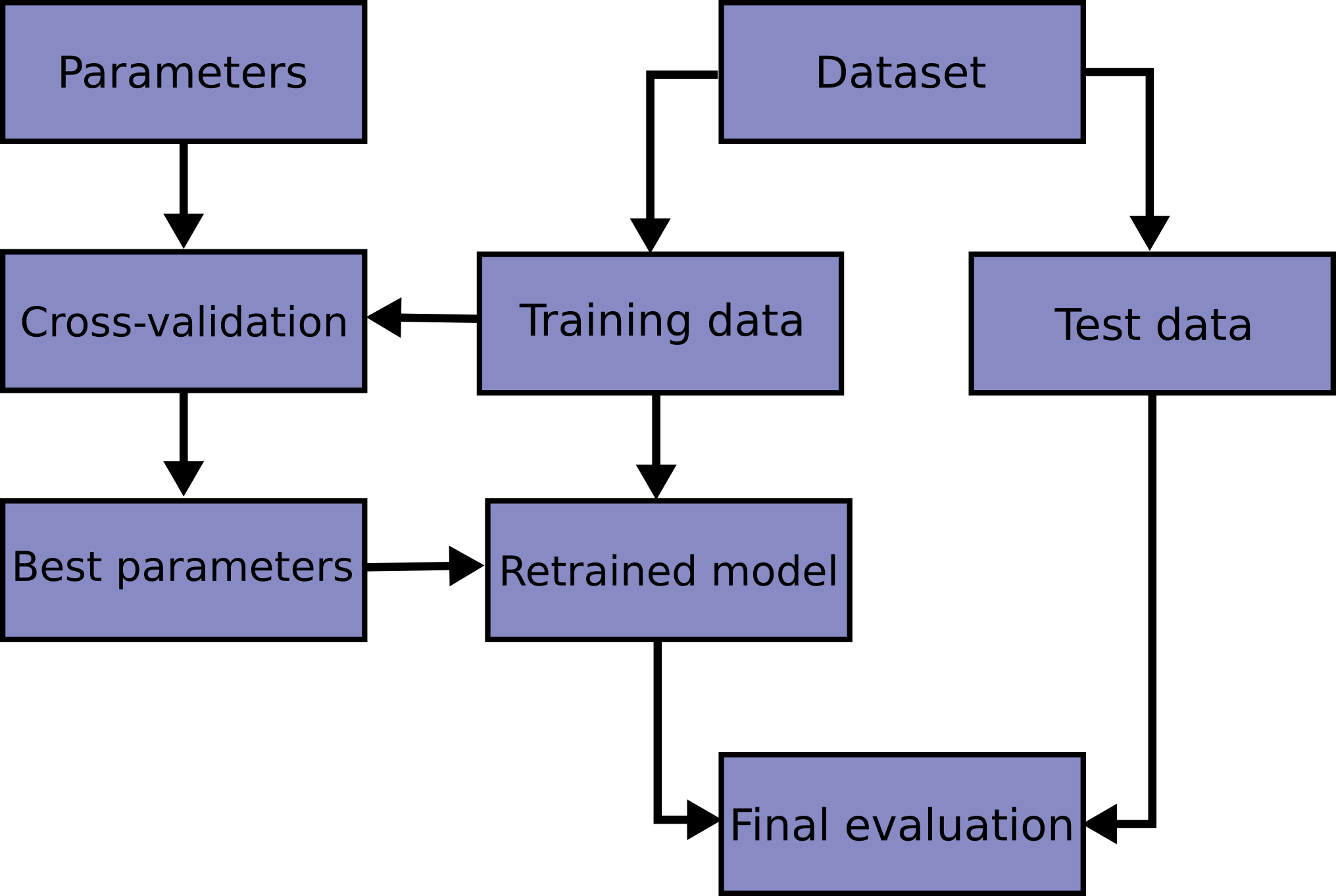
在 scikit-learn 中,可以使用train_test_split輔助函數快速計算隨機分為訓練集和測試集。讓我們載入鳶尾花資料集,以便在其上擬合線性支持向量機
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> X, y = datasets.load_iris(return_X_y=True)
>>> X.shape, y.shape
((150, 4), (150,))
我們現在可以快速取樣一個訓練集,同時保留 40% 的資料用於測試(評估)我們的分類器
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.4, random_state=0)
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
>>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.96...
當評估估計器的不同設定(「超參數」)時,例如必須為 SVM 手動設定的 C 設定,仍然存在在測試集上過擬合的風險,因為可以調整參數直到估計器達到最佳效能。透過這種方式,關於測試集的知識可以「洩漏」到模型中,並且評估指標不再報告泛化效能。為了解決這個問題,可以保留資料集的另一部分作為所謂的「驗證集」:訓練在訓練集上進行,然後在驗證集上進行評估,並且當實驗看起來成功時,可以在測試集上進行最終評估。
然而,透過將可用資料劃分為三個集合,我們大幅減少了可用於學習模型的樣本數量,並且結果可能取決於(訓練,驗證)集合對的特定隨機選擇。
這個問題的解決方案是一種稱為交叉驗證(簡稱 CV)的程序。仍然應該保留一個測試集用於最終評估,但在執行 CV 時不再需要驗證集。在稱為 k 折 CV 的基本方法中,訓練集被分成 k 個較小的集合(其他方法如下所述,但通常遵循相同的原則)。對於每個 k 個「折疊」,都遵循以下程序
使用 \(k-1\) 個折疊作為訓練資料來訓練模型;
在資料的其餘部分驗證產生的模型(即,它被用作測試集來計算效能度量,例如準確度)。
k 折交叉驗證報告的效能度量是迴圈中計算的值的平均值。這種方法在計算上可能很昂貴,但不會浪費太多資料(如同固定任意驗證集的情況一樣),這在諸如逆向推論之類樣本數量非常少的問題中是一個主要的優勢。
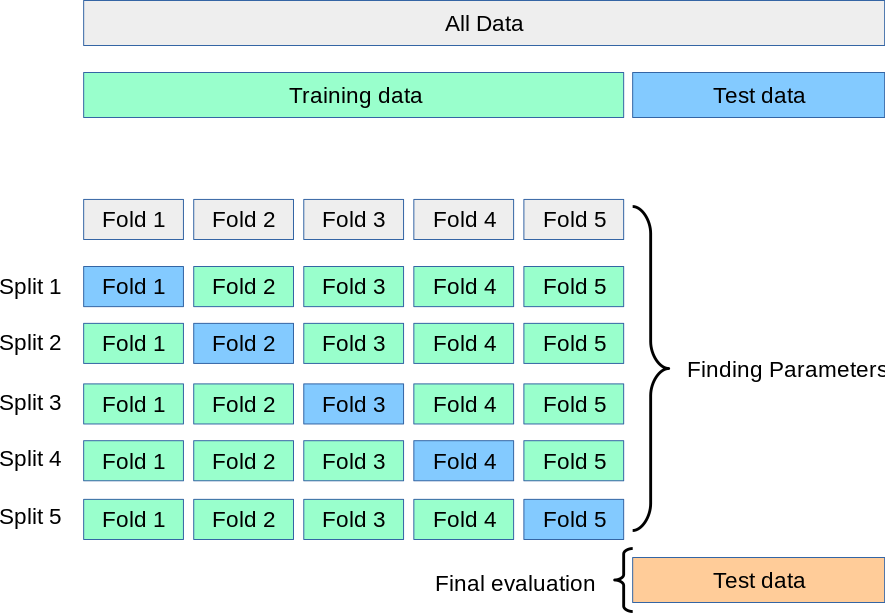
3.1.1. 計算交叉驗證的指標#
使用交叉驗證最簡單的方法是在估計器和資料集上呼叫cross_val_score輔助函數。
以下範例示範如何透過分割資料、擬合模型並連續計算分數 5 次(每次使用不同的分割)來估計線性核心支持向量機在鳶尾花資料集上的準確度
>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1, random_state=42)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores
array([0.96..., 1. , 0.96..., 0.96..., 1. ])
因此,平均分數和標準差由以下式子給出
>>> print("%0.2f accuracy with a standard deviation of %0.2f" % (scores.mean(), scores.std()))
0.98 accuracy with a standard deviation of 0.02
預設情況下,每次 CV 迭代時計算的分數是估計器的 score 方法。可以透過使用評分參數來更改此設定
>>> from sklearn import metrics
>>> scores = cross_val_score(
... clf, X, y, cv=5, scoring='f1_macro')
>>> scores
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
有關詳細資訊,請參閱評分參數:定義模型評估規則。在鳶尾花資料集的情況下,樣本在目標類別之間是平衡的,因此準確度和 F1 分數幾乎相等。
當 cv 引數為整數時,cross_val_score 預設使用 KFold 或 StratifiedKFold 策略,如果估計器源自 ClassifierMixin,則使用後者。
也可以透過傳遞交叉驗證迭代器來使用其他交叉驗證策略,例如
>>> from sklearn.model_selection import ShuffleSplit
>>> n_samples = X.shape[0]
>>> cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0)
>>> cross_val_score(clf, X, y, cv=cv)
array([0.977..., 0.977..., 1. ..., 0.955..., 1. ])
另一個選項是使用可迭代的產生 (訓練、測試) 分割作為索引陣列,例如
>>> def custom_cv_2folds(X):
... n = X.shape[0]
... i = 1
... while i <= 2:
... idx = np.arange(n * (i - 1) / 2, n * i / 2, dtype=int)
... yield idx, idx
... i += 1
...
>>> custom_cv = custom_cv_2folds(X)
>>> cross_val_score(clf, X, y, cv=custom_cv)
array([1. , 0.973...])
使用保留資料進行資料轉換#
正如在訓練中保留的資料上測試預測器很重要一樣,預處理(例如標準化、特徵選擇等)和類似的資料轉換也應該從訓練集中學習,並應用於保留的資料以進行預測
>>> from sklearn import preprocessing
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.4, random_state=0)
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> X_train_transformed = scaler.transform(X_train)
>>> clf = svm.SVC(C=1).fit(X_train_transformed, y_train)
>>> X_test_transformed = scaler.transform(X_test)
>>> clf.score(X_test_transformed, y_test)
0.9333...
Pipeline 可以更輕鬆地組合估計器,在交叉驗證下提供此行為
>>> from sklearn.pipeline import make_pipeline
>>> clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))
>>> cross_val_score(clf, X, y, cv=cv)
array([0.977..., 0.933..., 0.955..., 0.933..., 0.977...])
請參閱管線和複合估計器。
3.1.1.1. cross_validate 函數和多個指標評估#
cross_validate 函數與 cross_val_score 函數的不同之處在於以下兩個方面
它允許指定多個指標進行評估。
除了測試分數外,它還會回傳一個字典,其中包含擬合時間、評分時間(以及可選的訓練分數、擬合的估計器、訓練-測試分割索引)。
對於單一指標評估,其中 scoring 參數是字串、可呼叫物件或 None,則索引鍵會是 - ['test_score', 'fit_time', 'score_time']
對於多重指標評估,回傳值會是一個字典,其索引鍵如下 - ['test_<scorer1_name>', 'test_<scorer2_name>', 'test_<scorer...>', 'fit_time', 'score_time']
return_train_score 預設設定為 False 以節省計算時間。若要同時評估訓練集的分數,您需要將其設定為 True。您也可以透過設定 return_estimator=True 來保留每個訓練集上擬合的估計器。同樣地,您可以設定 return_indices=True 來保留用於將資料集分割成訓練集和測試集的訓練和測試索引,用於每個交叉驗證分割。
多重指標可以指定為預定義評分器名稱的列表、元組或集合。
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import recall_score
>>> scoring = ['precision_macro', 'recall_macro']
>>> clf = svm.SVC(kernel='linear', C=1, random_state=0)
>>> scores = cross_validate(clf, X, y, scoring=scoring)
>>> sorted(scores.keys())
['fit_time', 'score_time', 'test_precision_macro', 'test_recall_macro']
>>> scores['test_recall_macro']
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
或是將評分器名稱映射到預定義或自訂評分函數的字典。
>>> from sklearn.metrics import make_scorer
>>> scoring = {'prec_macro': 'precision_macro',
... 'rec_macro': make_scorer(recall_score, average='macro')}
>>> scores = cross_validate(clf, X, y, scoring=scoring,
... cv=5, return_train_score=True)
>>> sorted(scores.keys())
['fit_time', 'score_time', 'test_prec_macro', 'test_rec_macro',
'train_prec_macro', 'train_rec_macro']
>>> scores['train_rec_macro']
array([0.97..., 0.97..., 0.99..., 0.98..., 0.98...])
以下是使用單一指標的 cross_validate 範例
>>> scores = cross_validate(clf, X, y,
... scoring='precision_macro', cv=5,
... return_estimator=True)
>>> sorted(scores.keys())
['estimator', 'fit_time', 'score_time', 'test_score']
3.1.1.2. 透過交叉驗證取得預測#
函數 cross_val_predict 有類似於 cross_val_score 的介面,但會針對輸入中的每個元素,回傳該元素在測試集中所獲得的預測。僅能使用將所有元素恰好分配到測試集一次的交叉驗證策略(否則會引發例外)。
警告
關於不當使用 cross_val_predict 的注意事項
cross_val_predict 的結果可能與使用 cross_val_score 獲得的結果不同,因為元素以不同的方式分組。cross_val_score 函數會對交叉驗證折疊取平均值,而 cross_val_predict 只是回傳來自幾個不同模型的標籤(或機率),並未加以區分。因此,cross_val_predict 不是泛化誤差的適當度量。
- 函數
cross_val_predict適用於 視覺化從不同模型獲得的預測。
模型融合:當一個監督估計器的預測被用於訓練集成方法中的另一個估計器時。
以下章節介紹可用的交叉驗證迭代器。
範例
3.1.2. 交叉驗證迭代器#
以下章節列出可產生索引的工具,這些索引可用於根據不同的交叉驗證策略產生資料集分割。
3.1.2.1. 適用於 i.i.d. 資料的交叉驗證迭代器#
假設某些資料是獨立同分布(i.i.d.),就是假設所有樣本都來自相同的生成過程,且該生成過程假設不記得過去產生的樣本。
在這種情況下可以使用以下交叉驗證器。
注意
雖然 i.i.d. 資料是機器學習理論中的常見假設,但在實務中很少成立。如果知道樣本是使用時間相依過程產生的,則使用時間序列感知交叉驗證方案會比較安全。同樣地,如果知道生成過程具有群組結構(從不同的受試者、實驗、測量裝置收集的樣本),則使用群組式交叉驗證會比較安全。
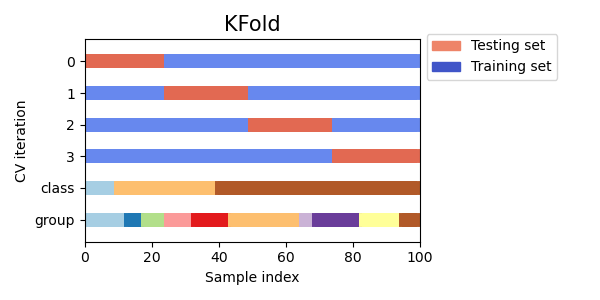
3.1.2.1.1. K 折#
KFold 將所有樣本分成 \(k\) 組樣本,稱為折疊(如果 \(k = n\),這相當於留一法策略),大小相等(如果可能)。預測函數是使用 \(k - 1\) 個折疊來學習,而留出的折疊則用於測試。
在具有 4 個樣本的資料集上進行 2 折交叉驗證的範例
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
以下是交叉驗證行為的可視化。請注意,KFold 不受類別或群組的影響。
每個折疊由兩個陣列組成:第一個與訓練集相關,第二個與測試集相關。因此,可以使用 numpy 索引建立訓練/測試集
>>> X = np.array([[0., 0.], [1., 1.], [-1., -1.], [2., 2.]])
>>> y = np.array([0, 1, 0, 1])
>>> X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test]
3.1.2.1.2. 重複 K 折#
RepeatedKFold 將 K 折重複 n 次。當需要執行 KFold n 次,並在每次重複中產生不同的分割時,可以使用它。
重複 2 次的 2 折 K 折範例
>>> import numpy as np
>>> from sklearn.model_selection import RepeatedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> random_state = 12883823
>>> rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state)
>>> for train, test in rkf.split(X):
... print("%s %s" % (train, test))
...
[2 3] [0 1]
[0 1] [2 3]
[0 2] [1 3]
[1 3] [0 2]
同樣地,RepeatedStratifiedKFold 將分層 K 折重複 n 次,每次重複都有不同的隨機化。
3.1.2.1.3. 留一法 (LOO)#
LeaveOneOut(或 LOO)是一種簡單的交叉驗證。每個學習集都是透過取出除了其中一個以外的所有樣本來建立的,而測試集則是留出的樣本。因此,對於 \(n\) 個樣本,我們有 \(n\) 個不同的訓練集和 \(n\) 個不同的測試集。此交叉驗證程序不會浪費太多資料,因為只會從訓練集中移除一個樣本
>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
... print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
LOO 用於模型選擇的潛在使用者應該權衡一些已知的注意事項。與 \(k\) 折交叉驗證相比,它會從 \(n\) 個樣本建構 \(n\) 個模型,而不是 \(k\) 個模型,其中 \(n > k\)。此外,每個模型都是在 \(n - 1\) 個樣本上訓練,而不是在 \((k-1) n / k\) 個樣本上訓練。無論在哪種方式中,假設 \(k\) 不是太大且 \(k < n\),則 LOO 比 \(k\) 折交叉驗證的計算成本更高。
就準確性而言,LOO 通常會導致測試誤差的估計器產生高變異數。直觀地說,由於 \(n\) 個樣本中的 \(n - 1\) 個樣本用於建構每個模型,因此從折疊建構的模型實際上彼此相同,並且與從整個訓練集建構的模型相同。
但是,如果學習曲線對於所討論的訓練大小來說很陡峭,則 5 折或 10 折交叉驗證可能會高估泛化誤差。
一般而言,大多數作者和經驗證據都建議,5 折或 10 折交叉驗證應優先於 LOO。
參考文獻#
http://www.faqs.org/faqs/ai-faq/neural-nets/part3/section-12.html;
T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning, Springer 2009
L. Breiman, P. Spector Submodel selection and evaluation in regression: The X-random case, International Statistical Review 1992;
R. Kohavi, A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection, Intl. Jnt. Conf. AI
R. Bharat Rao, G. Fung, R. Rosales, On the Dangers of Cross-Validation. An Experimental Evaluation, SIAM 2008;
G. James, D. Witten, T. Hastie, R Tibshirani, 統計學習導論, Springer 2013。
3.1.2.1.4. 留 P 法 (LPO)#
LeavePOut 與 LeaveOneOut 非常相似,它會從完整數據集中移除 \(p\) 個樣本,藉此建立所有可能的訓練/測試集。對於 \(n\) 個樣本,這會產生 \({n \choose p}\) 個訓練-測試對。與 LeaveOneOut 和 KFold 不同的是,當 \(p > 1\) 時,測試集會重疊。
在具有 4 個樣本的數據集上使用留 2 法的範例
>>> from sklearn.model_selection import LeavePOut
>>> X = np.ones(4)
>>> lpo = LeavePOut(p=2)
>>> for train, test in lpo.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
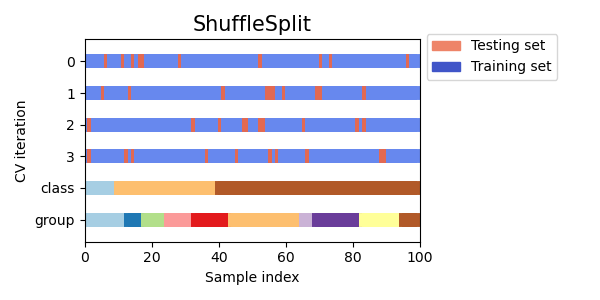
3.1.2.1.5. 隨機排列交叉驗證,又稱混洗與分割#
ShuffleSplit 迭代器將生成使用者定義數量的獨立訓練/測試數據集分割。樣本會先被混洗,然後分成一對訓練集和測試集。
可以透過顯式設定 random_state 虛擬亂數產生器的種子來控制隨機性,以實現結果的可重現性。
以下是一個使用範例
>>> from sklearn.model_selection import ShuffleSplit
>>> X = np.arange(10)
>>> ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0)
>>> for train_index, test_index in ss.split(X):
... print("%s %s" % (train_index, test_index))
[9 1 6 7 3 0 5] [2 8 4]
[2 9 8 0 6 7 4] [3 5 1]
[4 5 1 0 6 9 7] [2 3 8]
[2 7 5 8 0 3 4] [6 1 9]
[4 1 0 6 8 9 3] [5 2 7]
以下是交叉驗證行為的可視化。請注意,ShuffleSplit 不受類別或群組的影響。
因此,ShuffleSplit 是 KFold 交叉驗證的一個很好的替代方案,它允許更精細地控制迭代次數以及訓練/測試分割的每一側的樣本比例。
3.1.2.2. 基於類別標籤的分層交叉驗證迭代器#
某些分類問題可能會出現目標類別分佈嚴重不平衡的情況:例如,負樣本的數量可能是正樣本的數倍。在這種情況下,建議使用 StratifiedKFold 和 StratifiedShuffleSplit 中實作的分層抽樣,以確保每個訓練和驗證折疊中相對的類別頻率大致保持不變。
3.1.2.2.1. 分層 k 折#
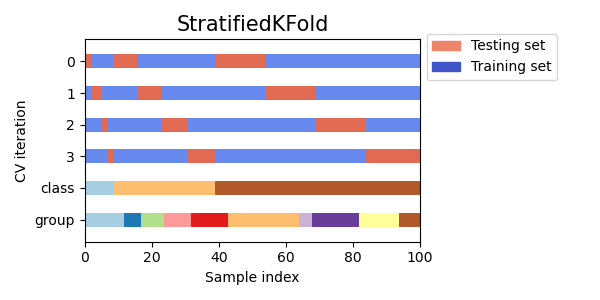
StratifiedKFold 是 k 折 的變體,它會返回分層折疊:每個集合包含與完整集合中每個目標類別的樣本百分比大致相同的樣本。
以下是在具有兩個不平衡類別的 50 個樣本的數據集上進行分層 3 折交叉驗證的範例。我們展示了每個類別中的樣本數量,並與 KFold 進行比較。
>>> from sklearn.model_selection import StratifiedKFold, KFold
>>> import numpy as np
>>> X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
>>> skf = StratifiedKFold(n_splits=3)
>>> for train, test in skf.split(X, y):
... print('train - {} | test - {}'.format(
... np.bincount(y[train]), np.bincount(y[test])))
train - [30 3] | test - [15 2]
train - [30 3] | test - [15 2]
train - [30 4] | test - [15 1]
>>> kf = KFold(n_splits=3)
>>> for train, test in kf.split(X, y):
... print('train - {} | test - {}'.format(
... np.bincount(y[train]), np.bincount(y[test])))
train - [28 5] | test - [17]
train - [28 5] | test - [17]
train - [34] | test - [11 5]
我們可以發現 StratifiedKFold 在訓練和測試數據集中都保留了類別比例(約 1 / 10)。
以下是交叉驗證行為的可視化。
RepeatedStratifiedKFold 可用於重複進行多次分層 K 折,每次重複使用不同的隨機化。
3.1.2.2.2. 分層混洗分割#
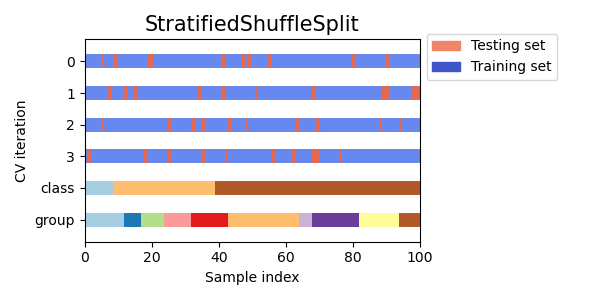
StratifiedShuffleSplit 是 ShuffleSplit 的變體,它返回分層分割,即透過保留與完整集合中每個目標類別相同的百分比來建立分割。
以下是交叉驗證行為的可視化。
3.1.2.3. 預定義的折疊分割/驗證集#
對於某些數據集,數據預先定義了分割成訓練和驗證折疊,或是分割成幾個交叉驗證折疊。使用 PredefinedSplit 可以使用這些折疊,例如在搜尋超參數時。
例如,當使用驗證集時,將屬於驗證集的所有樣本的 test_fold 設定為 0,並將所有其他樣本設定為 -1。
3.1.2.4. 分組數據的交叉驗證迭代器#
如果底層生成過程產生依賴樣本的群組,則 i.i.d. 假設會被打破。
這種數據分組是特定於領域的。一個範例是從多個患者收集的醫療數據,每個患者有多個樣本。而這些數據很可能取決於個別群組。在我們的範例中,每個樣本的患者 ID 將是其群組識別碼。
在這種情況下,我們想知道在特定群組集合上訓練的模型是否能很好地泛化到未見過的群組。為了衡量這一點,我們需要確保驗證折疊中的所有樣本都來自配對訓練折疊中根本沒有表示的群組。
可以使用以下交叉驗證分割器來執行此操作。樣本的分組識別碼是透過 groups 參數指定的。
3.1.2.4.1. 分組 k 折#
GroupKFold 是 k 折的變體,它確保相同的群組不會同時出現在測試集和訓練集中。例如,如果數據是從不同受試者那裡獲得的,每個受試者有多個樣本,並且如果模型足夠靈活,可以從高度個人化的特徵中學習,則它可能無法泛化到新的受試者。GroupKFold 可以檢測這種過度擬合的情況。
假設您有三個受試者,每個受試者都有一個從 1 到 3 的關聯數字
>>> from sklearn.model_selection import GroupKFold
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
>>> groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
>>> gkf = GroupKFold(n_splits=3)
>>> for train, test in gkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
每個受試者都在不同的測試折疊中,並且同一個受試者永遠不會同時出現在測試和訓練中。請注意,由於數據不平衡,折疊的大小並不完全相同。如果需要在折疊之間平衡類別比例,則 StratifiedGroupKFold 是一個更好的選擇。
以下是交叉驗證行為的可視化。
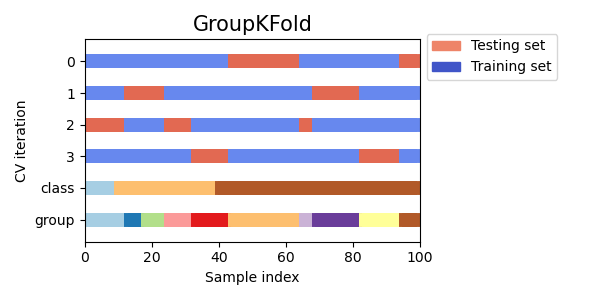
與 KFold 類似,來自 GroupKFold 的測試集將形成所有數據的完整分割。
當 shuffle=False 時,GroupKFold 嘗試在每個折疊中放置相同數量的樣本,而當 shuffle=True 時,它嘗試在每個折疊中放置相等數量的不同群組(但不考慮群組大小)。
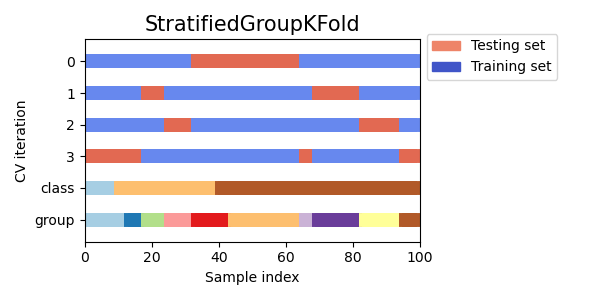
3.1.2.4.2. 分層分組 K 折#
StratifiedGroupKFold 是一種結合了 StratifiedKFold 和 GroupKFold 的交叉驗證方案。 其概念是嘗試在每個分割中保留類別的分布,同時將每個群組保留在單一分割中。 當您有不平衡的資料集時,這可能很有用,因為僅使用 GroupKFold 可能會產生偏差的分割。
範例
>>> from sklearn.model_selection import StratifiedGroupKFold
>>> X = list(range(18))
>>> y = [1] * 6 + [0] * 12
>>> groups = [1, 2, 3, 3, 4, 4, 1, 1, 2, 2, 3, 4, 5, 5, 5, 6, 6, 6]
>>> sgkf = StratifiedGroupKFold(n_splits=3)
>>> for train, test in sgkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[ 0 2 3 4 5 6 7 10 11 15 16 17] [ 1 8 9 12 13 14]
[ 0 1 4 5 6 7 8 9 11 12 13 14] [ 2 3 10 15 16 17]
[ 1 2 3 8 9 10 12 13 14 15 16 17] [ 0 4 5 6 7 11]
實作注意事項#
在目前的實作中,大多數情況下無法進行完整洗牌。當 shuffle=True 時,會發生以下情況:
所有群組都會被洗牌。
使用穩定排序,依照類別的標準差對群組進行排序。
迭代已排序的群組,並將其分配到摺疊 (folds) 中。
這表示只有類別分佈標準差相同的群組才会被洗牌,當每個群組只有單一類別時,這可能很有用。
該演算法會貪婪地將每個群組分配到 n_splits 個測試集之一,並選擇可以最小化測試集之間類別分佈變異數的測試集。 群組分配會從類別頻率變異數最高到最低的群組進行,也就是說,優先分配在一個或少數類別中達到峰值的大群組。
這種分割在某種意義上來說是次優的,即使可以實現完美的分層,也可能會產生不平衡的分割。如果每個群組中的類別分佈相對接近,則使用
GroupKFold會更好。
這是針對不均勻群組的交叉驗證行為視覺化
3.1.2.4.3. 留一組交叉驗證#
LeaveOneGroupOut 是一種交叉驗證方案,其中每個分割都保留屬於特定群組的樣本。群組資訊透過一個陣列提供,該陣列會編碼每個樣本的群組。
因此,每個訓練集都由除了與特定群組相關的樣本以外的所有樣本組成。這與 LeavePGroupsOut 且 n_groups=1 的情況相同,並且與 GroupKFold 且 n_splits 等於傳遞給 groups 參數的唯一標籤數量的情況相同。
例如,在多個實驗的情況下,可以使用 LeaveOneGroupOut 來建立基於不同實驗的交叉驗證:我們使用除了一個實驗之外的所有實驗的樣本來建立訓練集
>>> from sklearn.model_selection import LeaveOneGroupOut
>>> X = [1, 5, 10, 50, 60, 70, 80]
>>> y = [0, 1, 1, 2, 2, 2, 2]
>>> groups = [1, 1, 2, 2, 3, 3, 3]
>>> logo = LeaveOneGroupOut()
>>> for train, test in logo.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[2 3 4 5 6] [0 1]
[0 1 4 5 6] [2 3]
[0 1 2 3] [4 5 6]
另一個常見的應用是使用時間資訊:例如,群組可以是樣本的收集年份,因此可以針對基於時間的分割進行交叉驗證。
3.1.2.4.4. 留 P 組交叉驗證#
LeavePGroupsOut 與 LeaveOneGroupOut 相似,但會針對每個訓練/測試集移除與 \(P\) 個群組相關的樣本。所有 \(P\) 個群組的可能組合都會被排除在外,這表示對於 \(P>1\),測試集會重疊。
留 2 組交叉驗證的範例
>>> from sklearn.model_selection import LeavePGroupsOut
>>> X = np.arange(6)
>>> y = [1, 1, 1, 2, 2, 2]
>>> groups = [1, 1, 2, 2, 3, 3]
>>> lpgo = LeavePGroupsOut(n_groups=2)
>>> for train, test in lpgo.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]
3.1.2.4.5. 群組洗牌分割#
GroupShuffleSplit 迭代器的行為像是 ShuffleSplit 和 LeavePGroupsOut 的組合,並且會產生一系列隨機分割,其中每個分割都會排除群組的子集。 每個訓練/測試分割都是獨立執行的,這表示連續測試集之間沒有保證的關係。
以下是一個使用範例
>>> from sklearn.model_selection import GroupShuffleSplit
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "a"]
>>> groups = [1, 1, 2, 2, 3, 3, 4, 4]
>>> gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0)
>>> for train, test in gss.split(X, y, groups=groups):
... print("%s %s" % (train, test))
...
[0 1 2 3] [4 5 6 7]
[2 3 6 7] [0 1 4 5]
[2 3 4 5] [0 1 6 7]
[4 5 6 7] [0 1 2 3]
以下是交叉驗證行為的可視化。
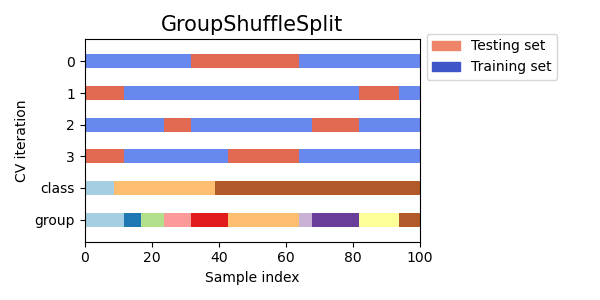
當需要 LeavePGroupsOut 的行為,但群組數量很大,以至於生成所有排除 \(P\) 個群組的可能分割將會非常昂貴時,此類別很有用。 在這種情況下,GroupShuffleSplit 會提供 LeavePGroupsOut 產生的訓練/測試分割的隨機樣本(帶有替換)。
3.1.2.5. 使用交叉驗證迭代器分割訓練集和測試集#
上面的群組交叉驗證函數也可用於將資料集分割成訓練和測試子集。 請注意,方便函數 train_test_split 是 ShuffleSplit 的包裝函式,因此僅允許分層分割(使用類別標籤),而無法考慮群組。
若要執行訓練和測試分割,請使用交叉驗證分割器的 split() 方法產生的產生器輸出所產生的訓練和測試子集的索引。 例如
>>> import numpy as np
>>> from sklearn.model_selection import GroupShuffleSplit
>>> X = np.array([0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001])
>>> y = np.array(["a", "b", "b", "b", "c", "c", "c", "a"])
>>> groups = np.array([1, 1, 2, 2, 3, 3, 4, 4])
>>> train_indx, test_indx = next(
... GroupShuffleSplit(random_state=7).split(X, y, groups)
... )
>>> X_train, X_test, y_train, y_test = \
... X[train_indx], X[test_indx], y[train_indx], y[test_indx]
>>> X_train.shape, X_test.shape
((6,), (2,))
>>> np.unique(groups[train_indx]), np.unique(groups[test_indx])
(array([1, 2, 4]), array([3]))
3.1.2.6. 時間序列資料的交叉驗證#
時間序列資料的特點是時間上接近的觀測值之間存在相關性(自相關)。 但是,諸如 KFold 和 ShuffleSplit 之類的傳統交叉驗證技術假設樣本是獨立且相同分布的,並且會在時間序列資料上產生訓練和測試實例之間不合理的相關性(導致泛化誤差的估計不佳)。 因此,針對時間序列資料,在最不像用於訓練模型的「未來」觀測值上評估我們的模型非常重要。 為了實現這一點,TimeSeriesSplit 提供了一個解決方案。
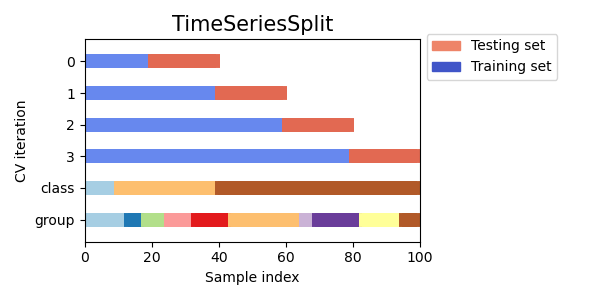
3.1.2.6.1. 時間序列分割#
TimeSeriesSplit 是 k 折的變體,它會傳回前 \(k\) 個摺疊作為訓練集,並將第 \((k+1)\) 個摺疊作為測試集。 請注意,與標準交叉驗證方法不同,連續的訓練集是先前的訓練集的超集。 此外,它會將所有剩餘資料新增到第一個訓練分割,該分割始終用於訓練模型。
此類別可用於交叉驗證以固定時間間隔觀察到的時間序列資料樣本。
在具有 6 個樣本的資料集上進行 3 向分割時間序列交叉驗證的範例
>>> from sklearn.model_selection import TimeSeriesSplit
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4, 5, 6])
>>> tscv = TimeSeriesSplit(n_splits=3)
>>> print(tscv)
TimeSeriesSplit(gap=0, max_train_size=None, n_splits=3, test_size=None)
>>> for train, test in tscv.split(X):
... print("%s %s" % (train, test))
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
以下是交叉驗證行為的可視化。
3.1.3. 關於洗牌的注意事項#
如果資料排序並非任意的(例如,具有相同類別標籤的樣本是連續的),那麼首先對其進行洗牌對於獲得有意義的交叉驗證結果可能至關重要。然而,如果樣本不是獨立且相同分佈的,則情況可能恰恰相反。例如,如果樣本對應於新聞文章,並且按照發布時間排序,那麼對資料進行洗牌很可能會導致模型過擬合和誇大的驗證分數:它將在與訓練樣本在時間上人為相似(接近)的樣本上進行測試。
一些交叉驗證迭代器,例如 KFold,具有內建的選項可以在分割它們之前對資料索引進行洗牌。請注意,
這樣做比直接洗牌資料消耗更少的記憶體。
預設情況下,不會進行任何洗牌,包括透過指定
cv=some_integer給cross_val_score、網格搜尋等執行的(分層)K 折交叉驗證。請記住,train_test_split仍然會返回一個隨機分割。random_state參數預設為None,這表示每次迭代KFold(..., shuffle=True)時,洗牌都會不同。然而,GridSearchCV會為每次由單次呼叫其fit方法驗證的參數集使用相同的洗牌。要為每個分割獲得相同的結果,請將
random_state設定為整數。
有關如何控制交叉驗證分割器的隨機性並避免常見陷阱的更多詳細資訊,請參閱 控制隨機性。
3.1.4. 交叉驗證和模型選擇#
交叉驗證迭代器也可以用於直接執行模型選擇,使用網格搜尋來尋找模型的最佳超參數。這是下一節的主題:調整估計器的超參數。
3.1.5. 置換檢定分數#
permutation_test_score 提供了另一種評估分類器效能的方法。它提供了基於置換的 p 值,代表分類器觀察到的效能有多大機率是偶然獲得的。此檢定的虛無假設是分類器未能利用特徵和標籤之間的任何統計依賴性,來對留出的資料做出正確的預測。permutation_test_score 透過計算資料的 n_permutations 個不同的置換來產生虛無分佈。在每個置換中,標籤都會被隨機洗牌,從而消除特徵和標籤之間的任何依賴性。輸出的 p 值是模型獲得的平均交叉驗證分數優於使用原始資料的模型獲得的交叉驗證分數的置換分數。為了獲得可靠的結果,n_permutations 通常應大於 100,且 cv 應介於 3 到 10 折之間。
較低的 p 值提供了證據,表明資料集包含特徵和標籤之間的真實依賴性,並且分類器能夠利用這一點來獲得良好的結果。較高的 p 值可能是由於特徵和標籤之間缺乏依賴性(類別之間特徵值沒有差異),或者因為分類器無法使用資料中的依賴性。在後一種情況下,使用能夠利用資料結構的更合適的分類器將會導致較低的 p 值。
交叉驗證提供了有關分類器泛化能力的資訊,特別是分類器預期誤差的範圍。然而,在沒有結構的高維資料集上訓練的分類器,仍然可能僅僅由於巧合,在交叉驗證中表現得比預期的更好。這通常會發生在樣本少於數百個的小型資料集上。permutation_test_score 提供了有關分類器是否找到真實類別結構的資訊,並有助於評估分類器的效能。
重要的是要注意,即使資料中只有微弱的結構,此檢定也已被證明會產生較低的 p 值,因為在相應的置換資料集中,絕對沒有任何結構。因此,此檢定只能顯示模型何時可靠地勝過隨機猜測。
最後,permutation_test_score 是使用暴力法計算的,並在內部擬合 (n_permutations + 1) * n_cv 個模型。因此,它僅適用於擬合單個模型非常快速的小型資料集。
範例
參考文獻#
Ojala 和 Garriga。 用於研究分類器效能的置換檢定。 J. Mach. Learn. Res. 2010。