8.1. 計算擴展策略:更大的資料#
對於某些應用程式,範例、特徵(或兩者)的數量,以及/或它們需要處理的速度,對傳統方法而言是具有挑戰性的。在這些情況下,scikit-learn 有一些選項可供您考慮,以使您的系統能夠擴展。
8.1.1. 使用核外學習來擴展實例#
核外(或「外部記憶體」)學習是一種用於從無法放入電腦主記憶體 (RAM) 的資料中學習的技術。
以下是旨在實現此目標的系統草圖
一種串流實例的方法
一種從實例中提取特徵的方法
一種增量演算法
8.1.1.1. 串流實例#
基本上,1. 可以是一個讀取器,它從硬碟上的檔案、資料庫、網路串流等產生實例。然而,關於如何實現這一點的詳細資訊超出了本文件的範圍。
8.1.1.2. 提取特徵#
2. 可以是任何在 scikit-learn 支援的不同特徵提取方法中提取特徵的相關方式。然而,當處理需要向量化且特徵或值集合事先未知時,應特別注意。一個很好的例子是文字分類,在訓練過程中可能會發現未知的詞語。如果從應用程式的角度來看,多次傳遞資料是合理的,則可以使用有狀態的向量化器。否則,可以使用無狀態的特徵提取器來增加難度。目前,執行此操作的首選方法是使用所謂的雜湊技巧,如 sklearn.feature_extraction.FeatureHasher 對於以 Python 字典清單表示的分類變數資料集,或 sklearn.feature_extraction.text.HashingVectorizer 對於文字文件實作的。
8.1.1.3. 增量學習#
最後,對於 3.,我們在 scikit-learn 內有一些選項。雖然並非所有演算法都可以增量學習(即無需一次看到所有實例),但所有實作 partial_fit API 的估計器都是候選項。實際上,從一批實例(有時稱為「線上學習」)中增量學習的能力是核外學習的關鍵,因為它保證在任何給定時間,主記憶體中都只有少量實例。選擇一個平衡相關性和記憶體佔用量的合適小批量大小可能需要進行一些調整[1]。
以下是針對不同任務的增量估計器清單
對於分類,一個需要注意的重要事項是,雖然無狀態的特徵提取常式可能能夠處理新的/未見過的屬性,但增量學習器本身可能無法處理新的/未見過的目標類別。在這種情況下,您必須使用 classes= 參數將所有可能的類別傳遞給第一個 partial_fit 呼叫。
選擇合適演算法時要考慮的另一個方面是,並非所有演算法都隨著時間的推移對每個範例都給予相同的重視。也就是說,即使在許多範例之後,Perceptron 仍然對錯誤標記的範例敏感,而 SGD* 和 PassiveAggressive* 系列對這類人工產物更具穩健性。相反,當顯著不同但正確標記的範例在串流中較晚出現時,後者也傾向於對它們給予較少的重視,因為它們的學習率會隨著時間的推移而降低。
8.1.1.4. 範例#
最後,我們有一個完整的範例,關於文字文件的核外分類。它旨在為想要建構核外學習系統的人員提供一個起點,並示範了上述討論的大部分概念。
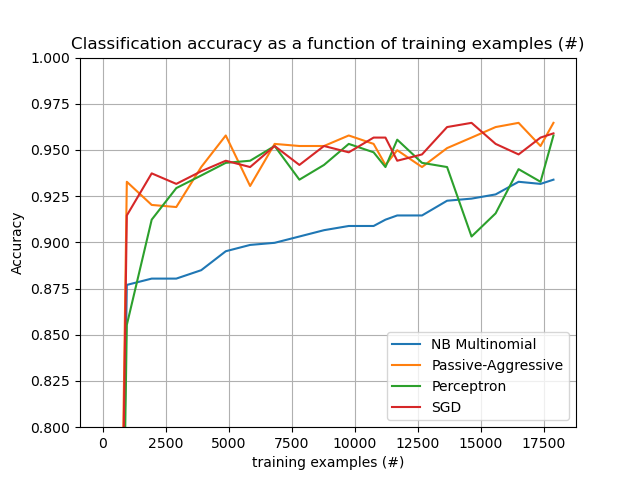
此外,它還展示了不同演算法的效能隨著處理範例數量的演變。
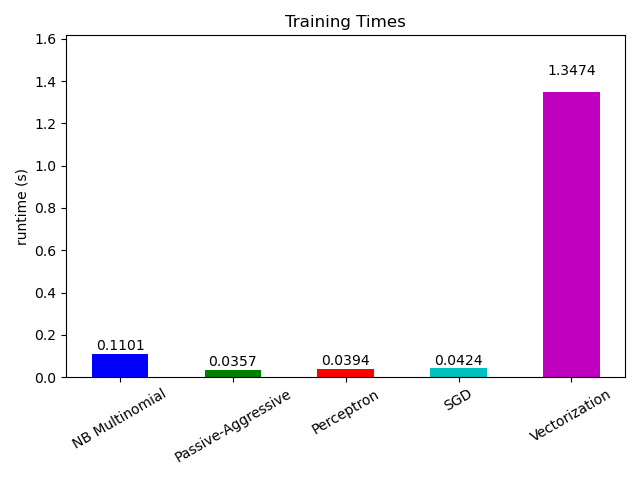
現在看看不同部分的計算時間,我們發現向量化的成本遠高於學習本身。從不同的演算法來看,MultinomialNB 的成本最高,但可以透過增加小批次的大小來緩解其開銷(練習:將程式中的 minibatch_size 變更為 100 和 10000 並比較)。