1.3. 核脊迴歸#
核脊迴歸(KRR)[M2012]結合了脊迴歸和分類(帶有 l2 範數正規化的線性最小平方)與核技巧。因此,它在各自的核和資料所誘導的空間中學習線性函數。對於非線性核,這對應於原始空間中的非線性函數。
KernelRidge學習的模型形式與支持向量迴歸(SVR)相同。然而,使用了不同的損失函數:KRR 使用平方誤差損失,而支持向量迴歸使用\(\epsilon\)不敏感損失,兩者都與 l2 正規化結合。與SVR相比,擬合KernelRidge可以以封閉形式完成,並且對於中等大小的資料集通常更快。另一方面,學習的模型是非稀疏的,因此比SVR慢,後者對於\(\epsilon > 0\)學習稀疏模型,在預測時也是如此。
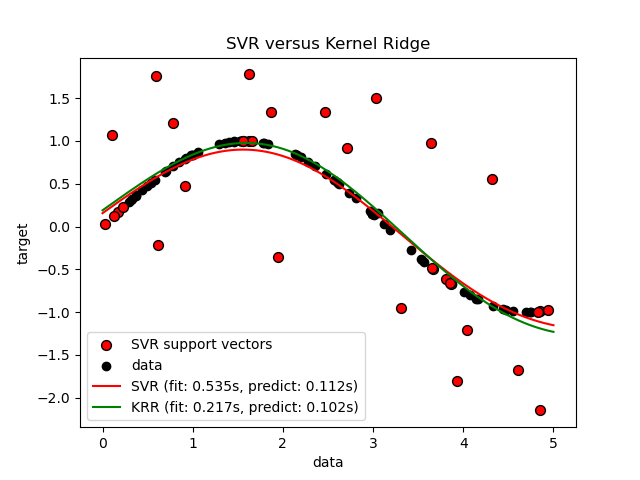
下圖比較了在人工資料集上KernelRidge和SVR,該資料集由正弦目標函數組成,並在每第五個資料點添加強烈雜訊。KernelRidge和SVR學習的模型被繪製出來,其中 RBF 核的複雜度/正規化和頻寬都使用網格搜尋進行了最佳化。學習的函數非常相似;然而,擬合KernelRidge比擬合SVR快大約七倍(兩者都使用網格搜尋)。但是,使用SVR預測 100000 個目標值快三倍以上,因為它學習了稀疏模型,僅使用大約 100 個訓練資料點中的 1/3 作為支持向量。
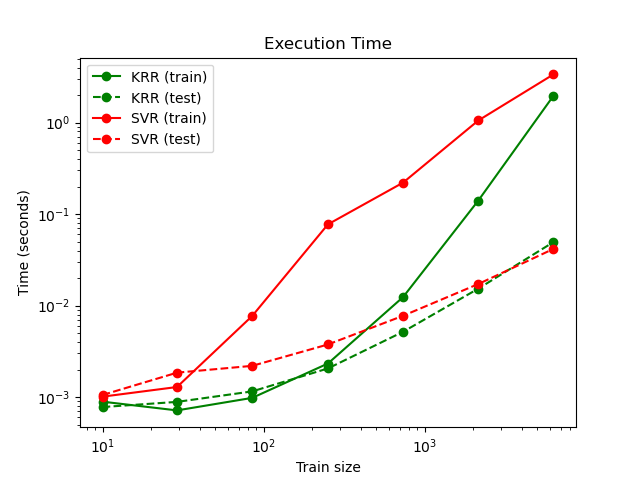
下圖比較了對於不同大小的訓練集,擬合和預測KernelRidge和SVR的時間。對於中等大小的訓練集(少於 1000 個樣本),擬合KernelRidge比SVR快;但是,對於較大的訓練集,SVR的擴展性更好。關於預測時間,由於學習了稀疏解,SVR對於所有大小的訓練集都比KernelRidge快。請注意,稀疏程度以及因此的預測時間取決於SVR的參數\(\epsilon\)和\(C\);\(\epsilon = 0\)將對應於密集模型。
範例
參考文獻
“機器學習:機率視角”,Murphy, K. P. - 第 14.4.3 章,第 492-493 頁,麻省理工學院出版社,2012