8.2. 計算效能#
對於某些應用程式來說,估計器的效能(主要是預測時的延遲和吞吐量)至關重要。考慮訓練吞吐量也可能很有趣,但在生產環境中(通常離線進行)通常不那麼重要。
我們將在此檢閱您可以在不同情況下從許多 scikit-learn 估計器中預期的數量級,並提供一些技巧和訣竅來克服效能瓶頸。
預測延遲是衡量進行預測所需的時間(例如,以微秒為單位)。延遲通常被視為分佈,而營運工程師通常專注於此分佈的給定百分位數(例如,第 90 個百分位數)的延遲。
預測吞吐量定義為軟體在給定時間內可以交付的預測數量(例如,每秒預測次數)。
效能優化的重要方面也在於它可能會損害預測準確性。事實上,較簡單的模型(例如,線性而不是非線性,或參數較少)通常執行速度更快,但並不總是能夠像更複雜的模型那樣考慮到資料的相同確切屬性。
8.2.1. 預測延遲#
使用/選擇機器學習工具組時,人們可能最直接關心的問題之一是在生產環境中進行預測的延遲。
影響預測延遲的主要因素是:
特徵數量
輸入資料表示和稀疏性
模型複雜性
特徵提取
最後一個主要參數還是在批次或一次一個模式下進行預測的可能性。
8.2.1.1. 批次與原子模式#
一般來說,批次進行預測(同時處理多個實例)效率更高,原因有很多(分支可預測性、CPU 快取、線性代數函式庫最佳化等)。在這裡,我們看到在特徵很少的情況下,獨立於估計器的選擇,批次模式總是更快,對於某些估計器來說,速度快了 1 到 2 個數量級
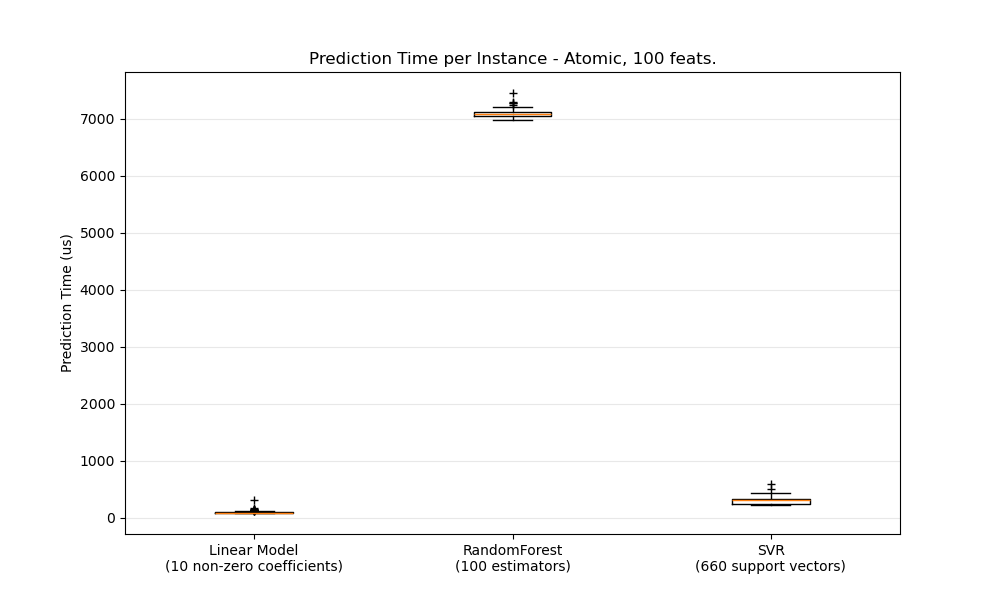
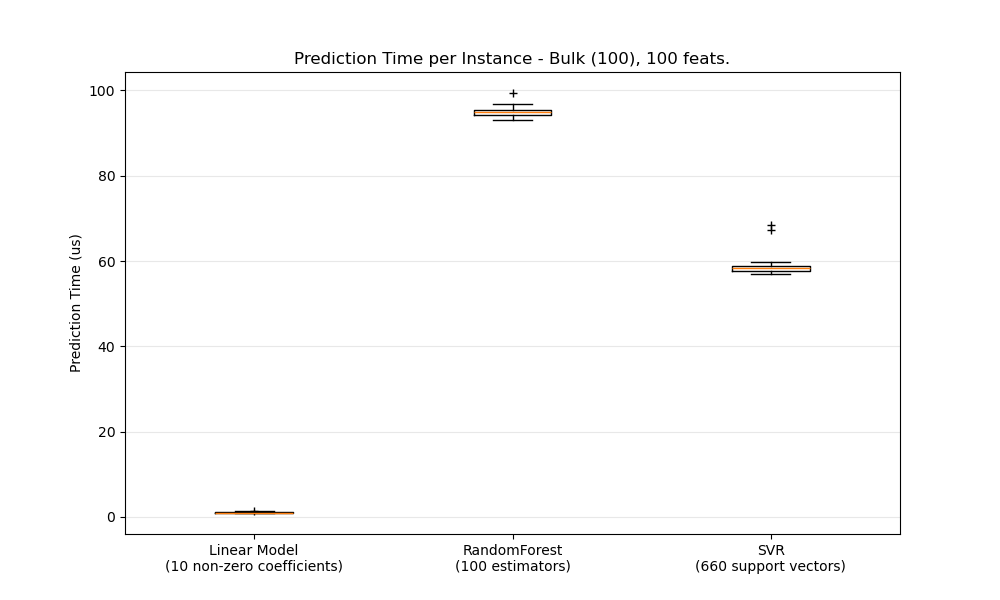
若要針對您的情況對不同的估計器進行基準測試,您可以簡單地更改此範例中的 n_features 參數:預測延遲。這應該會給您一個預測延遲數量級的估計。
8.2.1.2. 配置 Scikit-learn 以減少驗證開銷#
Scikit-learn 對資料進行一些驗證,這會增加每次呼叫 predict 和類似函式的開銷。特別是,檢查特徵是否為有限值(非 NaN 或無限值)涉及對資料進行完整遍歷。如果您確保您的資料是可以接受的,您可以在導入 scikit-learn 之前將環境變數 SKLEARN_ASSUME_FINITE 設定為非空字串,或在 Python 中使用 set_config 進行設定,來抑制對有限性的檢查。若要比這些全域設定進行更多控制,config_context 可讓您在指定的環境中設定此配置
>>> import sklearn
>>> with sklearn.config_context(assume_finite=True):
... pass # do learning/prediction here with reduced validation
請注意,這將影響在環境中對 assert_all_finite 的所有使用。
8.2.1.3. 特徵數量的影響#
顯然,當特徵數量增加時,每個範例的記憶體消耗也會增加。事實上,對於具有 \(N\) 個特徵的 \(M\) 個實例的矩陣,空間複雜度為 \(O(NM)\)。從計算的角度來看,這也意味著基本運算(例如,線性模型中向量-矩陣乘積的乘法)的次數也會增加。以下是預測延遲隨特徵數量演變的圖表
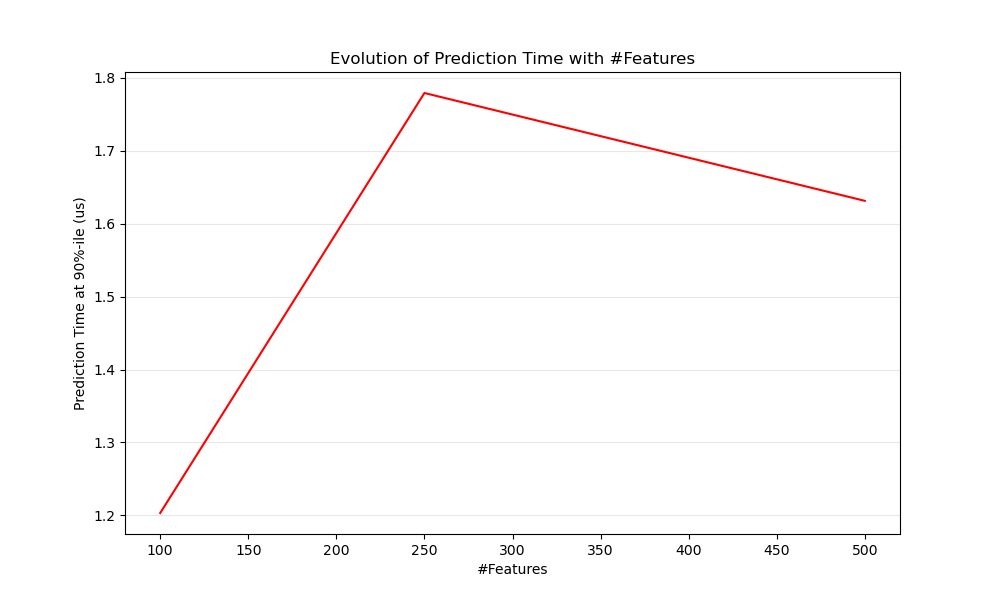
總體而言,您可以預期預測時間至少會隨著特徵數量線性增加(非線性情況可能會根據全域記憶體佔用空間和估計器而發生)。
8.2.1.4. 輸入資料表示的影響#
Scipy 提供針對儲存稀疏資料進行最佳化的稀疏矩陣資料結構。稀疏格式的主要特點是您不儲存零,因此如果您的資料是稀疏的,那麼您使用的記憶體會少得多。稀疏 (CSR 或 CSC) 表示中的非零值平均只會佔用一個 32 位元整數位置 + 64 位元浮點數值 + 矩陣中每列或每行的額外 32 位元。在密集(或稀疏)線性模型上使用稀疏輸入可以顯著加快預測速度,因為只有非零值特徵才會影響點積,進而影響模型預測。因此,如果您在 1e6 維空間中有 100 個非零值,您只需要 100 個乘法和加法運算,而不是 1e6 個。
然而,對密集表示的計算可能會利用 BLAS 中高度最佳化的向量運算和多執行緒處理,並傾向於減少 CPU 快取未命中。因此,稀疏性通常應該相當高(最大 10% 的非零值,根據硬體檢查),稀疏輸入表示才會在具有許多 CPU 和最佳化 BLAS 實作的機器上比密集輸入表示更快。
以下是測試輸入稀疏性的範例程式碼
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))
根據經驗,您可以認為如果稀疏率大於 90%,您可能會從稀疏格式中獲益。請查看 Scipy 的稀疏矩陣格式文件,以取得有關如何建置(或將資料轉換為)稀疏矩陣格式的更多資訊。大多數情況下,CSR 和 CSC 格式的效果最佳。
8.2.1.5. 模型複雜性的影響#
一般來說,當模型複雜性增加時,預測能力和延遲應該會增加。提高預測能力通常很有趣,但對於許多應用程式來說,我們最好不要過度增加預測延遲。我們現在將針對不同的監督式模型系列檢閱這個想法。
對於 sklearn.linear_model(例如 Lasso、ElasticNet、SGDClassifier/Regressor、Ridge & RidgeClassifier、PassiveAggressiveClassifier/Regressor、LinearSVC、LogisticRegression...),在預測時套用的決策函數是相同的(點積),因此延遲應該是等效的。
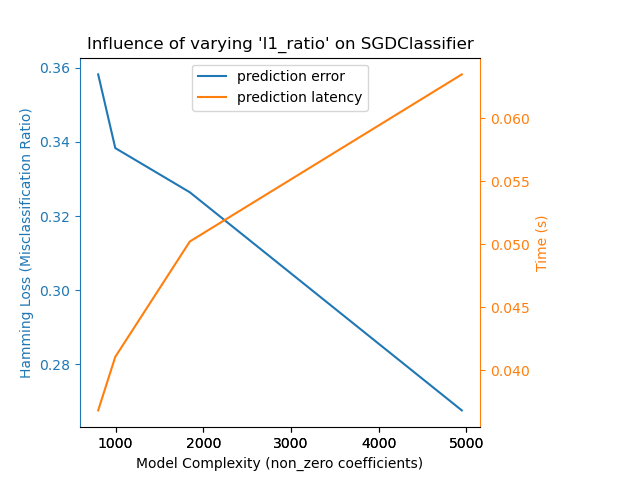
這裡有一個使用 SGDClassifier 和 elasticnet 懲罰項的範例。正則化強度由 alpha 參數全局控制。透過足夠高的 alpha 值,可以增加 elasticnet 的 l1_ratio 參數,以在模型係數中強制執行不同程度的稀疏性。這裡的較高稀疏性被解釋為較低的模型複雜度,因為我們需要較少的係數來完整描述它。當然,稀疏性反過來會影響預測時間,因為稀疏點積的時間大致與非零係數的數量成正比。
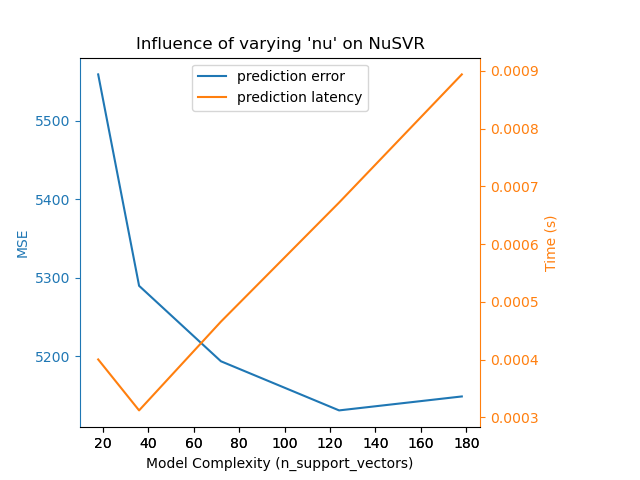
對於具有非線性核心的 sklearn.svm 演算法系列,延遲時間與支持向量的數量有關(支持向量越少,速度越快)。延遲時間和吞吐量應(漸近地)與 SVC 或 SVR 模型中的支持向量數量呈線性增長。核心函數也會影響延遲時間,因為它用於計算每個支持向量的輸入向量投影。在下圖中,NuSVR 的 nu 參數被用來影響支持向量的數量。
對於樹的 sklearn.ensemble (例如,RandomForest、GBT、ExtraTrees 等),樹的數量及其深度起著最重要的作用。延遲時間和吞吐量應與樹的數量呈線性關係。在這種情況下,我們直接使用了 GradientBoostingRegressor 的 n_estimators 參數。
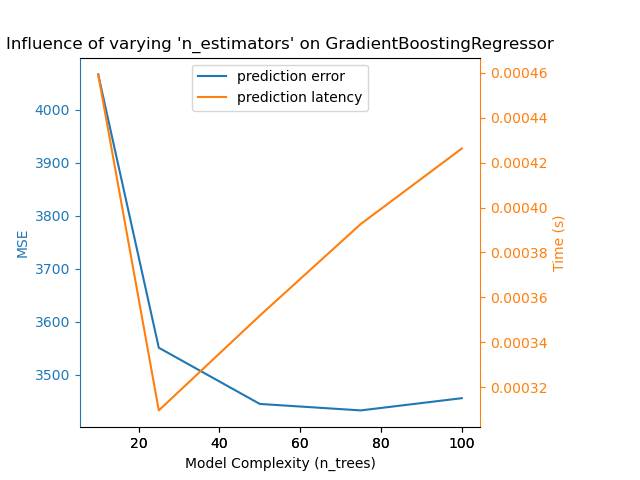
無論如何,請注意降低模型複雜度可能會損害準確性,如上所述。例如,一個非線性可分離的問題可以使用快速的線性模型來處理,但預測能力很可能會在這個過程中受到影響。
8.2.1.6. 特徵提取延遲#
大多數 scikit-learn 模型通常都非常快,因為它們是透過編譯過的 Cython 擴展或最佳化的計算函式庫實現的。另一方面,在許多現實世界的應用中,特徵提取過程(即將原始資料,如資料庫行或網路封包轉換為 numpy 陣列)決定了整體預測時間。例如,在路透社文字分類任務中,整個準備工作(讀取和解析 SGML 檔案,將文字符號化並將其雜湊到一個公共向量空間)所花費的時間比實際的預測程式碼多 100 到 500 倍,具體取決於所選的模型。
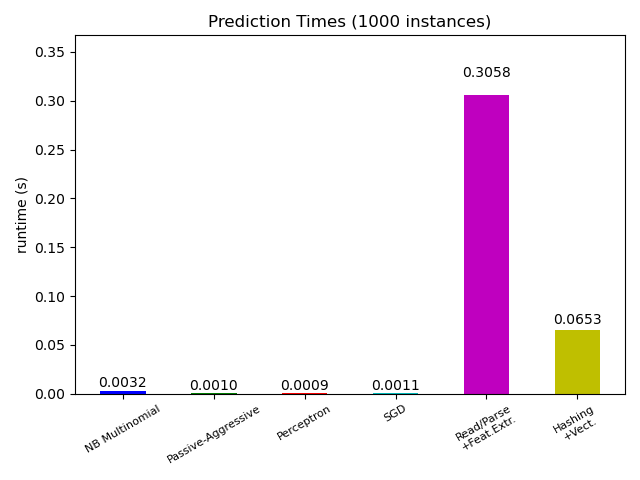
因此,在許多情況下,建議仔細計時並分析您的特徵提取程式碼,因為當您的整體延遲時間對於您的應用程式來說太慢時,這可能是一個很好的優化起點。
8.2.2. 預測吞吐量#
在調整生產系統大小時,另一個需要關心的重要指標是吞吐量,即在給定時間內可以進行的預測次數。以下是來自 預測延遲 範例的基準測試,該範例測量了多個估計器在合成資料上的這個量
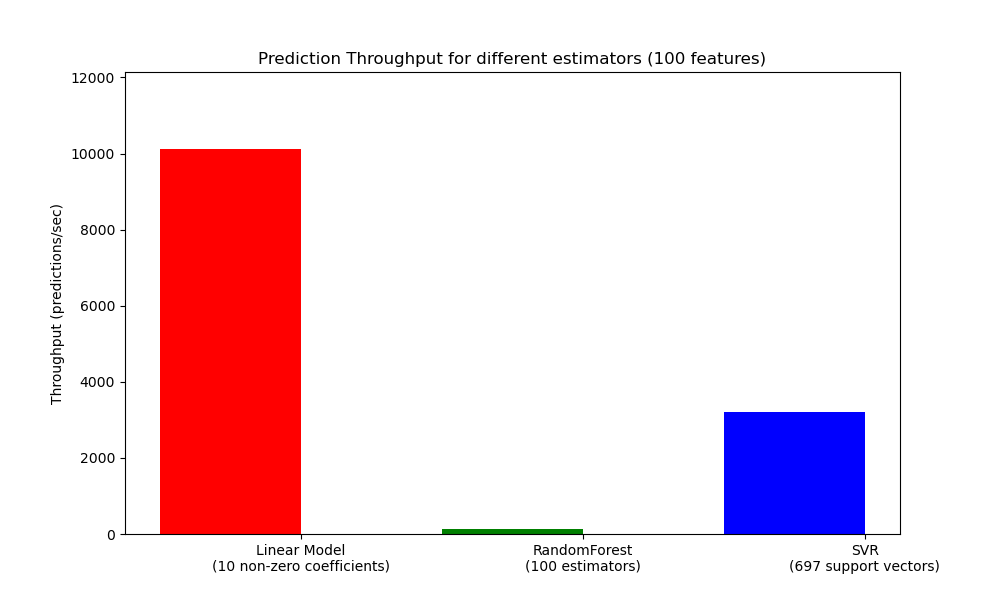
這些吞吐量是在單個進程上實現的。提高應用程式吞吐量的一個顯而易見的方法是產生額外的實例(通常是 Python 中的進程,因為 GIL),這些實例共享相同的模型。也可以添加機器來分散負載。但關於如何實現這一點的詳細說明超出了本文件的範圍。
8.2.3. 提示與技巧#
8.2.3.1. 線性代數函式庫#
由於 scikit-learn 在很大程度上依賴於 Numpy/Scipy 和一般的線性代數,因此有必要明確關注這些函式庫的版本。基本上,您應該確保 Numpy 是使用最佳化的 BLAS / LAPACK 函式庫建構的。
並非所有模型都受益於最佳化的 BLAS 和 Lapack 實作。例如,基於(隨機)決策樹的模型通常不依賴於其內部迴圈中的 BLAS 呼叫,核心 SVM 也不依賴(SVC、SVR、NuSVC、NuSVR)。另一方面,使用 BLAS DGEMM 呼叫(透過 numpy.dot)實現的線性模型通常會從經過調整的 BLAS 實作中獲得巨大收益,並且相對於非最佳化的 BLAS 可以帶來數個數量級的加速。
您可以使用以下命令顯示您的 NumPy / SciPy / scikit-learn 安裝使用的 BLAS / LAPACK 實作
python -c "import sklearn; sklearn.show_versions()"
最佳化的 BLAS / LAPACK 實作包括
Atlas(需要透過在目標機器上重新建構來進行硬體特定的調整)
OpenBLAS
MKL
Apple Accelerate 和 vecLib 框架(僅限 OSX)
有關更多資訊,請參閱 NumPy 安裝頁面 和 Daniel Nouri 的這篇部落格文章,其中包含 Debian / Ubuntu 的一些不錯的逐步安裝說明。
8.2.3.2. 限制工作記憶體#
某些使用標準 numpy 向量化操作實現的計算涉及使用大量臨時記憶體。這可能會耗盡系統記憶體。在可以以固定記憶體區塊執行計算的地方,我們會嘗試這樣做,並允許使用者使用 set_config 或 config_context 提示此工作記憶體的最大大小(預設為 1GB)。以下建議將臨時工作記憶體限制為 128 MiB
>>> import sklearn
>>> with sklearn.config_context(working_memory=128):
... pass # do chunked work here
符合此設定的區塊操作範例是 pairwise_distances_chunked,它有助於計算成對距離矩陣的逐行縮減。
8.2.3.3. 模型壓縮#
目前 scikit-learn 中的模型壓縮僅涉及線性模型。在這種情況下,這表示我們要控制模型稀疏性(即模型向量中非零座標的數量)。通常,將模型稀疏性與稀疏輸入資料表示相結合是一個好主意。
以下範例程式碼說明了 sparsify() 方法的使用
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
在此範例中,我們首選 elasticnet 懲罰項,因為它通常是模型緊湊性和預測能力之間的一個很好的折衷方案。還可以進一步調整 l1_ratio 參數(與正則化強度 alpha 結合使用)來控制這種權衡。
一個典型的合成資料 基準測試在模型和輸入都是稀疏的情況下(非零係數比率分別為 0.000024 和 0.027400),延遲時間會降低 >30%。您的結果可能會因您的資料和模型的稀疏性和大小而異。此外,稀疏化對於減少部署在生產伺服器上的預測模型的記憶體使用量非常有用。
8.2.3.4. 模型重塑#
模型重塑是指僅選擇可用特徵的一部分來擬合模型。換句話說,如果模型在學習階段捨棄了特徵,我們就可以從輸入中去除這些特徵。這有幾個好處。首先,它可以減少模型本身的記憶體(因此也減少了時間)開銷。一旦我們知道要從上次執行中保留哪些特徵,它也允許捨棄管道中的顯式特徵選擇元件。最後,它可以透過不收集和建構被模型捨棄的特徵,幫助減少資料存取和特徵提取層的上游處理時間和 I/O 使用量。例如,如果原始資料來自資料庫,則可以透過使查詢返回更輕的記錄,從而編寫更簡單、更快的查詢或減少 I/O 使用量。目前,在 scikit-learn 中需要手動執行重塑。在稀疏輸入的情況下(特別是 CSR 格式),通常足以不產生相關特徵,而將其列留空。