1.7. 高斯過程#
高斯過程 (GP) 是一種非參數的監督式學習方法,用於解決迴歸和機率分類問題。
高斯過程的優點是
預測會內插觀測值(至少對於規則核函數而言)。
預測是機率性的(高斯分佈),因此可以計算經驗信賴區間,並根據這些區間決定是否應在某些感興趣的區域重新擬合(線上擬合、自適應擬合)預測。
多功能:可以指定不同的核函數。提供了常見的核函數,但也可以指定自定義的核函數。
高斯過程的缺點包括
我們的實作不是稀疏的,也就是說,它們使用所有樣本/特徵資訊來執行預測。
它們在高維空間中會失去效率 – 也就是說,當特徵數量超過幾十個時。
1.7.1. 高斯過程迴歸 (GPR)#
GaussianProcessRegressor 實現了用於迴歸目的的高斯過程 (GP)。為此,需要指定 GP 的先驗。GP 會根據訓練樣本結合此先驗和似然函數。它允許通過在預測時給出均值和標準差作為輸出,來給出預測的機率方法。
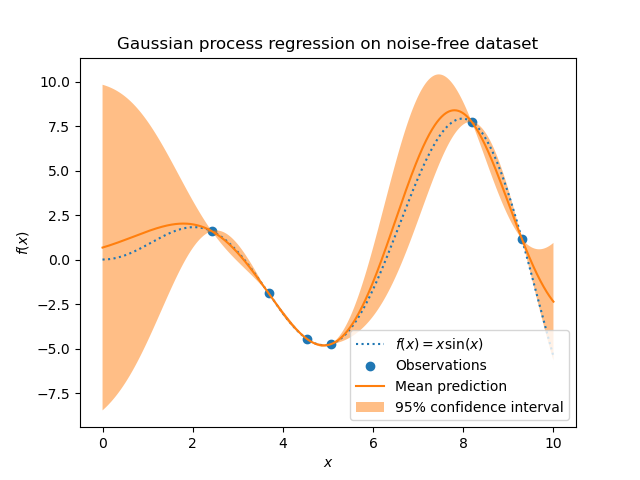
先驗均值被假定為常數且為零(對於 normalize_y=False)或訓練資料的均值(對於 normalize_y=True)。先驗的共變異數透過傳遞核函數物件來指定。當通過基於傳遞的 optimizer 最大化對數邊際似然 (LML) 來擬合 GaussianProcessRegressor 時,會優化核函數的超參數。由於 LML 可能具有多個局部最佳值,因此可以通過指定 n_restarts_optimizer 來重複啟動優化器。第一次執行始終從核函數的初始超參數值開始;後續執行從已從允許值的範圍中隨機選擇的超參數值開始。如果應該保持初始超參數固定,則可以將 None 作為優化器傳遞。
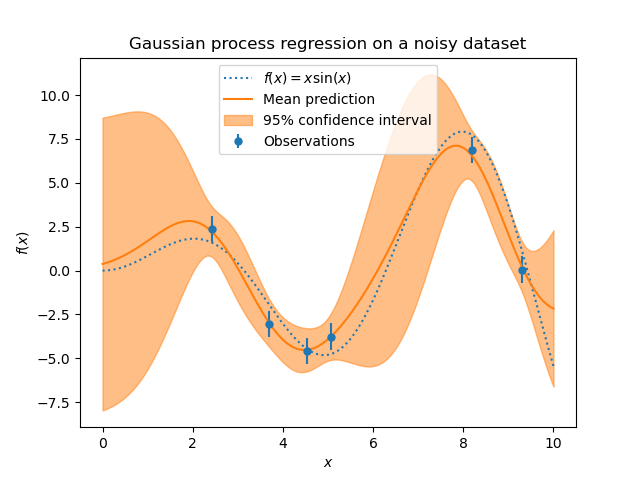
可以通過通過參數 alpha 傳遞目標中的雜訊水平來指定,可以是全域標量或每個資料點。請注意,適度的雜訊水平對於處理擬合期間的數值不穩定性也很有幫助,因為它實際上是作為 Tikhonov 正規化來實作的,也就是說,通過將其添加到核矩陣的對角線上。除了顯式指定雜訊水平之外,另一種方法是在核函數中包含一個 WhiteKernel 組件,它可以從資料中估計全域雜訊水平(請參閱下面的範例)。下圖顯示了通過設置參數 alpha 處理的雜訊目標的影響。
該實作基於 [RW2006] 的演算法 2.1。除了標準 scikit-learn 估計器的 API 之外,GaussianProcessRegressor
允許在不事先擬合的情況下進行預測(基於 GP 先驗)
提供了一個額外的方法
sample_y(X),它會在給定的輸入處評估從 GPR(先驗或後驗)中提取的樣本公開一個方法
log_marginal_likelihood(theta),可以將其外部用於其他選擇超參數的方法,例如,通過馬可夫鏈蒙特卡羅方法。
範例
1.7.2. 高斯過程分類 (GPC)#
GaussianProcessClassifier 實現了用於分類目的的高斯過程 (GP),更具體地說是用於機率分類,其中測試預測採用類別機率的形式。GaussianProcessClassifier 將 GP 先驗置於潛在函數 \(f\) 上,然後通過連結函數將其擠壓以獲得機率分類。潛在函數 \(f\) 是一個所謂的干擾函數,其值不可觀察並且本身不相關。它的目的是允許方便地制定模型,並且在預測期間會移除(積分掉)\(f\)。GaussianProcessClassifier 實現了邏輯連結函數,對於該函數,積分無法解析計算,但在二元情況下很容易近似。
與迴歸設定相反,即使對於 GP 先驗,潛在函數 \(f\) 的後驗也不是高斯的,因為高斯似然不適用於離散類別標籤。而是使用與邏輯連結函數 (logit) 對應的非高斯似然。GaussianProcessClassifier 基於拉普拉斯近似,用高斯近似非高斯後驗。有關更多詳細資訊,請參閱 [RW2006] 的第 3 章。
高斯過程 (GP) 先驗均值假設為零。先驗的共變異數由傳遞一個 核函數 (kernel) 物件來指定。在 GaussianProcessRegressor 的擬合過程中,核函數的超參數會根據傳遞的 optimizer,透過最大化對數邊際似然 (LML) 來優化。由於 LML 可能有多個局部最佳解,因此可以透過指定 n_restarts_optimizer 來重複啟動最佳化器。第一次執行總是從核函數的初始超參數值開始;後續執行則從允許範圍內隨機選擇的超參數值開始。如果初始超參數應保持固定,則可以將 None 作為最佳化器傳遞。
GaussianProcessClassifier 支援多類別分類,方法是執行一對多 (one-versus-rest) 或一對一 (one-versus-one) 的訓練和預測。在一對多中,會為每個類別擬合一個二元高斯過程分類器,該分類器會被訓練來將該類別與其餘類別分開。在「一對一」中,會為每對類別擬合一個二元高斯過程分類器,該分類器會被訓練來將這兩個類別分開。這些二元預測器的預測會被合併為多類別預測。有關詳細資訊,請參閱關於 多類別分類 的章節。
在高斯過程分類的情況下,「一對一」在計算上可能更便宜,因為它必須解決許多僅涉及整個訓練集子集的問題,而不是在整個資料集上解決較少的問題。由於高斯過程分類的規模與資料集的大小呈立方關係,因此這可能會快得多。但是,請注意,「一對一」不支援預測機率估計,而僅支援一般的預測。此外,請注意 GaussianProcessClassifier 本身尚未實作真正的多類別拉普拉斯近似,但如上所述,它是基於內部解決多個二元分類任務,這些任務使用一對多或一對一來合併。
1.7.3. GPC 範例#
1.7.3.1. 使用 GPC 的機率預測#
此範例說明 GPC 對於具有不同超參數選擇的 RBF 核函數的預測機率。第一張圖顯示了 GPC 的預測機率,其中使用了任意選擇的超參數以及與最大對數邊際似然 (LML) 相對應的超參數。
雖然透過優化 LML 選擇的超參數具有相當大的 LML,但根據測試資料的對數損失來看,它們的表現略遜一籌。該圖顯示,這是因為它們在類別邊界處呈現類別機率的陡峭變化(這是好的),但在遠離類別邊界的地方,預測的機率接近 0.5(這是壞的)。這種不良影響是由 GPC 內部使用的拉普拉斯近似引起的。
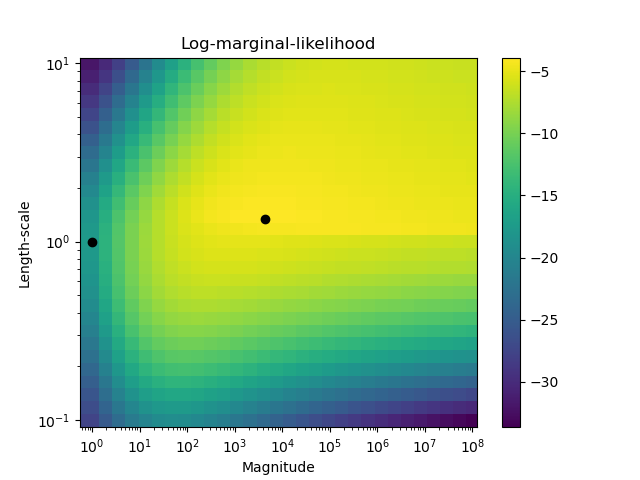
第二張圖顯示了不同核函數超參數選擇的對數邊際似然,並用黑點突出了第一張圖中使用的兩種超參數選擇。
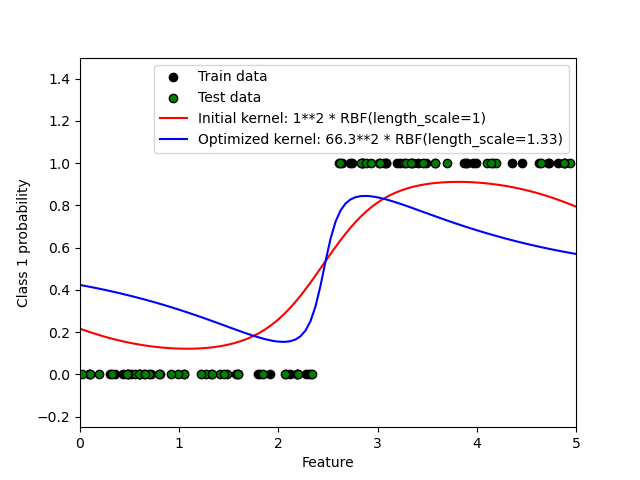
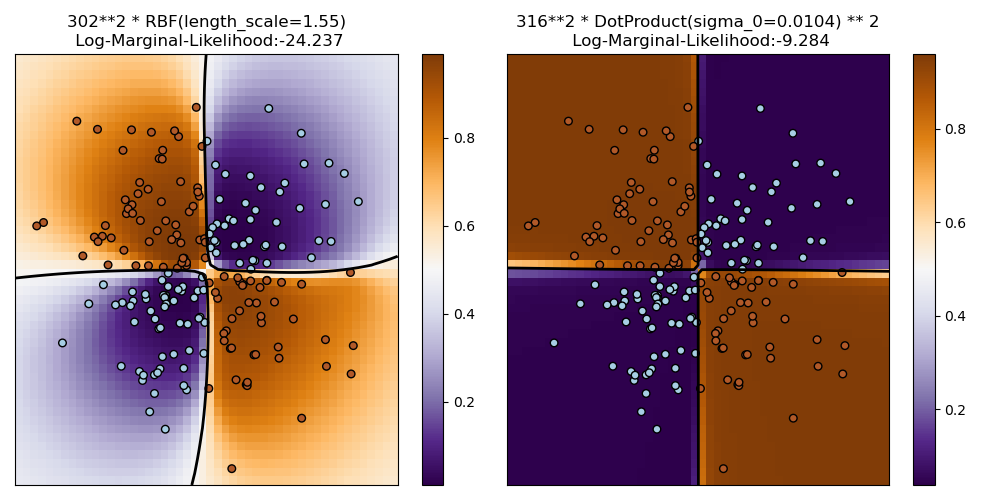
1.7.3.2. XOR 資料集上的 GPC 說明#
此範例說明 XOR 資料集上的 GPC。比較的是一個固定、等向核函數 (RBF) 和一個非固定核函數 (DotProduct)。在這個特定的資料集上,DotProduct 核函數獲得了明顯更好的結果,因為類別邊界是線性的,並且與座標軸重合。然而,在實務上,像 RBF 這樣的固定核函數通常會獲得更好的結果。
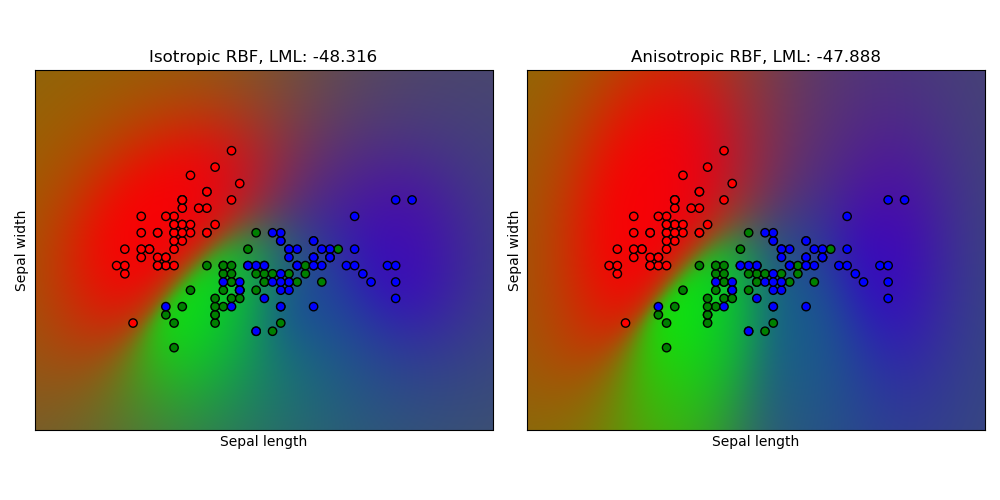
1.7.3.3. 鳶尾花資料集上的高斯過程分類 (GPC)#
此範例說明 GPC 對於鳶尾花資料集二維版本上,等向和異向 RBF 核函數的預測機率。這說明了 GPC 對於非二元分類的適用性。異向 RBF 核函數透過為兩個特徵維度分配不同的長度尺度,獲得了略高的對數邊際似然。
1.7.4. 高斯過程的核函數#
核函數 (在 GP 的上下文中也稱為「共變異數函數」) 是 GP 的一個關鍵要素,它決定了 GP 先驗和後驗的形狀。它們透過定義兩個資料點的「相似性」來編碼關於正在學習的函數的假設,並結合相似的資料點應具有相似目標值的假設。核函數可以分為兩類:固定核函數僅取決於兩個資料點的距離,而不取決於它們的絕對值 \(k(x_i, x_j)= k(d(x_i, x_j))\),因此對於輸入空間中的平移是不變的,而非固定核函數也取決於資料點的特定值。固定核函數可以進一步細分為等向和異向核函數,其中等向核函數對於輸入空間中的旋轉也是不變的。有關更多詳細資訊,請參閱 [RW2006] 的第 4 章。有關如何最佳組合不同核函數的指導,請參閱 [Duv2014]。
高斯過程核函數 API#
Kernel 的主要用途是計算資料點之間的 GP 共變異數。為此,可以呼叫核函數的 __call__ 方法。此方法可用於計算 2d 陣列 X 中所有資料點對的「自共變異數」,或計算 2d 陣列 X 中的資料點與 2d 陣列 Y 中的資料點的所有組合的「互共變異數」。以下恆等式對於所有核函數 k (除了 WhiteKernel 之外) 都成立:k(X) == K(X, Y=X)
如果僅使用自共變異數的對角線,則可以呼叫核函數的 diag() 方法,它比等效呼叫 __call__ 更有效率:np.diag(k(X, X)) == k.diag(X)
核函數由一個超參數向量 \(\theta\) 參數化。例如,這些超參數可以控制核函數的長度尺度或週期性 (見下文)。所有核函數都支援透過在 __call__ 方法中設定 eval_gradient=True 來計算核函數自共變異數關於 \(log(\theta)\) 的解析梯度。也就是說,會傳回一個 (len(X), len(X), len(theta)) 陣列,其中條目 [i, j, l] 包含 \(\frac{\partial k_\theta(x_i, x_j)}{\partial log(\theta_l)}\)。高斯過程 (迴歸器和分類器) 在計算對數邊際似然的梯度時會使用此梯度,而對數邊際似然的梯度又用於確定 \(\theta\) 的值,該值會透過梯度上升來最大化對數邊際似然。對於每個超參數,在建立核函數的實例時,需要指定初始值和邊界。可以透過核函數物件的 theta 屬性取得和設定 \(\theta\) 的目前值。此外,可以使用核函數的 bounds 屬性存取超參數的邊界。請注意,由於這些值通常更適合基於梯度的最佳化,因此兩個屬性 (theta 和 bounds) 都會傳回內部使用值的對數轉換值。每個超參數的規格都以 Hyperparameter 的實例形式儲存在各自的核函數中。請注意,使用名稱為「x」的超參數的核函數必須具有屬性 self.x 和 self.x_bounds。
所有核函數的抽象基礎類別是 Kernel。Kernel 實作了與 BaseEstimator 相似的介面,提供 get_params()、set_params() 和 clone() 方法。這允許也透過諸如 Pipeline 或 GridSearchCV 之類的元估計器來設定核函數值。請注意,由於核函數的巢狀結構 (透過應用核函數運算子,請參見下文),核函數參數的名稱可能會變得相當複雜。通常,對於二元核函數運算子,左側運算元的參數會加上前綴 k1__,而右側運算元的參數則會加上前綴 k2__。另一個便利的方法是 clone_with_theta(theta),它會傳回核函數的複製版本,但超參數已設定為 theta。一個說明性範例
>>> from sklearn.gaussian_process.kernels import ConstantKernel, RBF
>>> kernel = ConstantKernel(constant_value=1.0, constant_value_bounds=(0.0, 10.0)) * RBF(length_scale=0.5, length_scale_bounds=(0.0, 10.0)) + RBF(length_scale=2.0, length_scale_bounds=(0.0, 10.0))
>>> for hyperparameter in kernel.hyperparameters: print(hyperparameter)
Hyperparameter(name='k1__k1__constant_value', value_type='numeric', bounds=array([[ 0., 10.]]), n_elements=1, fixed=False)
Hyperparameter(name='k1__k2__length_scale', value_type='numeric', bounds=array([[ 0., 10.]]), n_elements=1, fixed=False)
Hyperparameter(name='k2__length_scale', value_type='numeric', bounds=array([[ 0., 10.]]), n_elements=1, fixed=False)
>>> params = kernel.get_params()
>>> for key in sorted(params): print("%s : %s" % (key, params[key]))
k1 : 1**2 * RBF(length_scale=0.5)
k1__k1 : 1**2
k1__k1__constant_value : 1.0
k1__k1__constant_value_bounds : (0.0, 10.0)
k1__k2 : RBF(length_scale=0.5)
k1__k2__length_scale : 0.5
k1__k2__length_scale_bounds : (0.0, 10.0)
k2 : RBF(length_scale=2)
k2__length_scale : 2.0
k2__length_scale_bounds : (0.0, 10.0)
>>> print(kernel.theta) # Note: log-transformed
[ 0. -0.69314718 0.69314718]
>>> print(kernel.bounds) # Note: log-transformed
[[ -inf 2.30258509]
[ -inf 2.30258509]
[ -inf 2.30258509]]
所有高斯過程核函數都可與 sklearn.metrics.pairwise 互相操作,反之亦然:Kernel 子類的實例可以作為 metric 傳遞給 sklearn.metrics.pairwise 中的 pairwise_kernels。此外,可以使用封裝類 PairwiseKernel 將來自 pairwise 的核函數用作 GP 核函數。唯一的限制是,超參數的梯度不是解析的而是數值的,並且所有這些核函數僅支持各向同性的距離。參數 gamma 被認為是一個超參數,並且可以進行最佳化。其他核函數參數在初始化時直接設定,並保持固定。
1.7.4.1. 基本核函數#
ConstantKernel 核函數可以用作 Product 核函數的一部分,在其中它可以縮放另一個因子(核函數)的大小,或者可以用作 Sum 核函數的一部分,在其中它可以修改高斯過程的均值。它取決於一個參數 \(constant\_value\)。其定義為
WhiteKernel 核函數的主要用例是作為總和核函數的一部分,在其中它解釋訊號的雜訊成分。調整其參數 \(noise\_level\) 對應於估計雜訊水平。其定義為
1.7.4.2. 核函數運算符#
核函數運算符採用一個或兩個基本核函數,並將它們組合成一個新的核函數。Sum 核函數採用兩個核函數 \(k_1\) 和 \(k_2\),並透過 \(k_{sum}(X, Y) = k_1(X, Y) + k_2(X, Y)\) 將它們組合起來。Product 核函數採用兩個核函數 \(k_1\) 和 \(k_2\),並透過 \(k_{product}(X, Y) = k_1(X, Y) * k_2(X, Y)\) 將它們組合起來。Exponentiation 核函數採用一個基本核函數和一個純量參數 \(p\),並透過 \(k_{exp}(X, Y) = k(X, Y)^p\) 將它們組合起來。請注意,Kernel 物件會覆寫魔術方法 __add__、__mul___ 和 __pow__,因此可以使用例如 RBF() + RBF() 作為 Sum(RBF(), RBF()) 的快捷方式。
1.7.4.3. 徑向基函數 (RBF) 核函數#
RBF 核函數是一個穩定的核函數。它也稱為「平方指數」核函數。它由一個長度尺度參數 \(l>0\) 參數化,該參數可以是純量(核函數的各向同性變體)或與輸入 \(x\) 具有相同維度的向量(核函數的各向異性變體)。核函數由下式給出
其中 \(d(\cdot, \cdot)\) 是歐氏距離。此核函數是無限可微分的,這表示以該核函數作為共變異數函數的 GP 具有所有階的均方導數,因此非常平滑。以下圖顯示了 RBF 核函數產生之 GP 的先驗和後驗
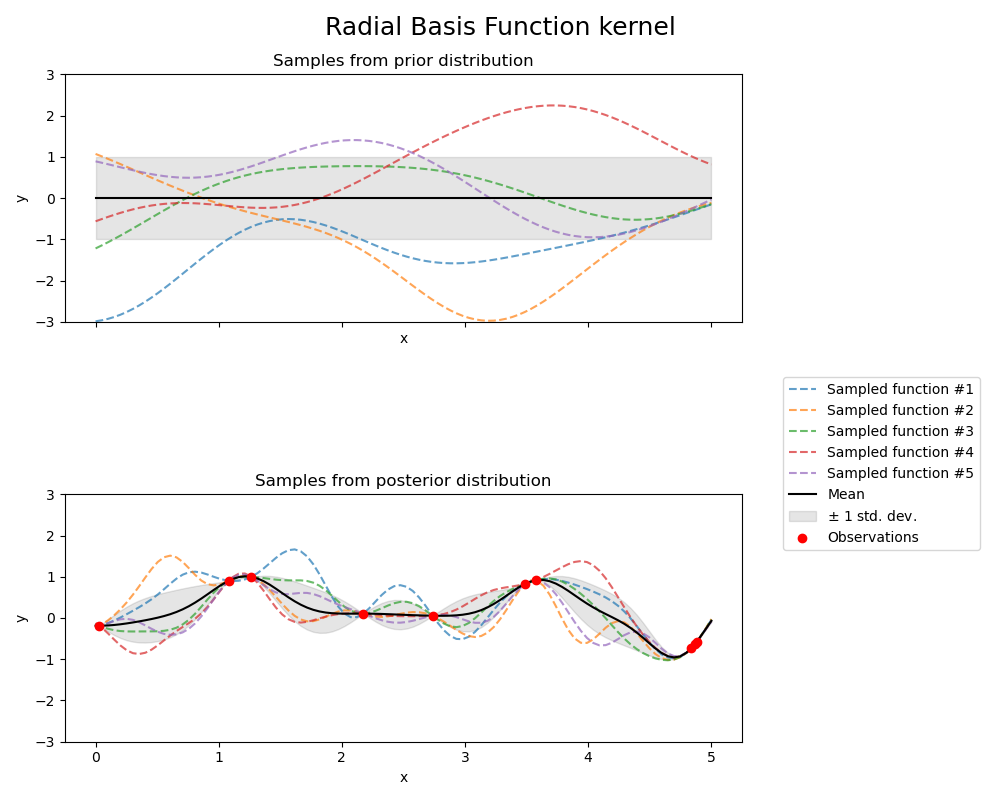
1.7.4.4. Matérn 核函數#
Matern 核函數是一個穩定的核函數,也是 RBF 核函數的推廣。它有一個額外的參數 \(\nu\),用於控制結果函數的平滑度。它由一個長度尺度參數 \(l>0\) 參數化,該參數可以是純量(核函數的各向同性變體)或與輸入 \(x\) 具有相同維度的向量(核函數的各向異性變體)。
Matérn 核函數的數學實作#
核函數由下式給出
其中 \(d(\cdot,\cdot)\) 是歐氏距離,\(K_\nu(\cdot)\) 是修正的貝索函數,而 \(\Gamma(\cdot)\) 是伽瑪函數。當 \(\nu\rightarrow\infty\) 時,Matérn 核函數會收斂到 RBF 核函數。當 \(\nu = 1/2\) 時,Matérn 核函數會變得與絕對指數核函數相同,即
特別地,\(\nu = 3/2\)
和 \(\nu = 5/2\)
是學習非無限可微分(如 RBF 核函數所假設)但至少可微分一次(\(\nu = 3/2\))或兩次可微分(\(\nu = 5/2\))的函數的常見選擇。
透過 \(\nu\) 控制學習函數的平滑度的彈性,可以適應真實基礎函數關係的特性。
以下圖顯示了 Matérn 核函數產生之 GP 的先驗和後驗
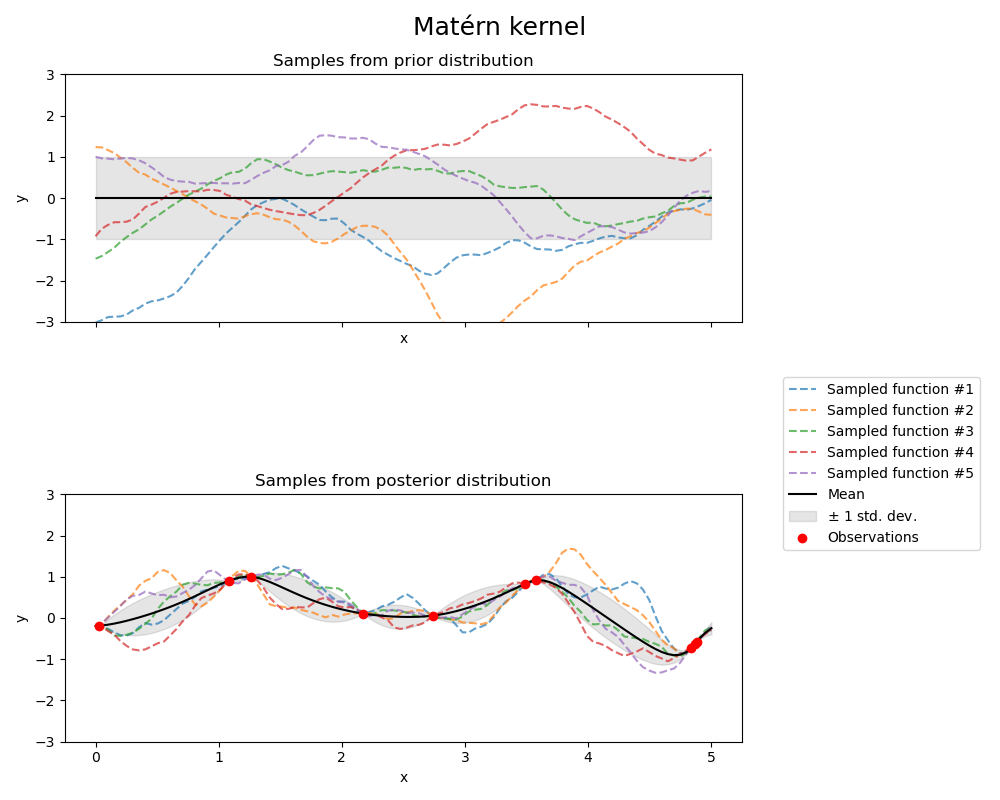
有關 Matérn 核函數的不同變體的更多詳細資訊,請參閱 [RW2006],第 84 頁。
1.7.4.5. 有理二次核函數#
RationalQuadratic 核函數可以看作是具有不同特徵長度尺度的 RBF 核函數的尺度混合(無限和)。它由一個長度尺度參數 \(l>0\) 和一個尺度混合參數 \(\alpha>0\) 參數化。目前僅支援 \(l\) 為純量的各向同性變體。核函數由下式給出
以下圖顯示了 RationalQuadratic 核函數產生之 GP 的先驗和後驗
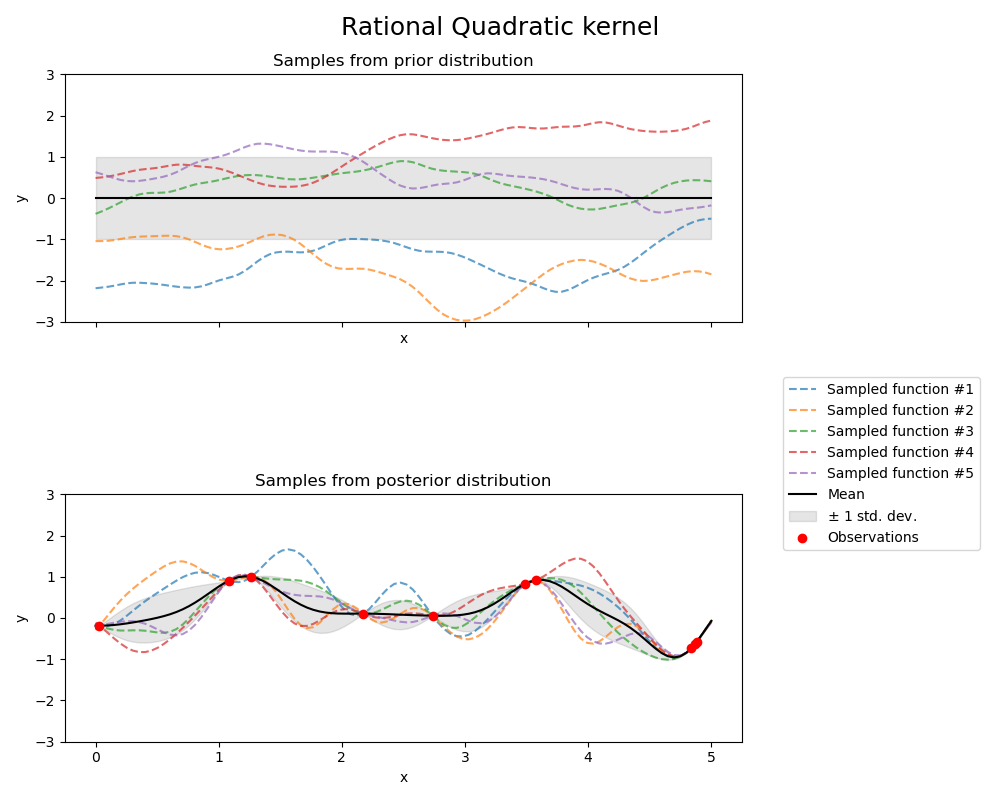
1.7.4.6. Exp-Sine-Squared 核函數#
ExpSineSquared 核函數允許對週期性函數進行建模。它由一個長度尺度參數 \(l>0\) 和一個週期性參數 \(p>0\) 進行參數化。目前僅支援 \(l\) 為純量的等向變體。該核函數由下式給出:
使用 ExpSineSquared 核函數的 GP 所產生的先驗和後驗如下圖所示
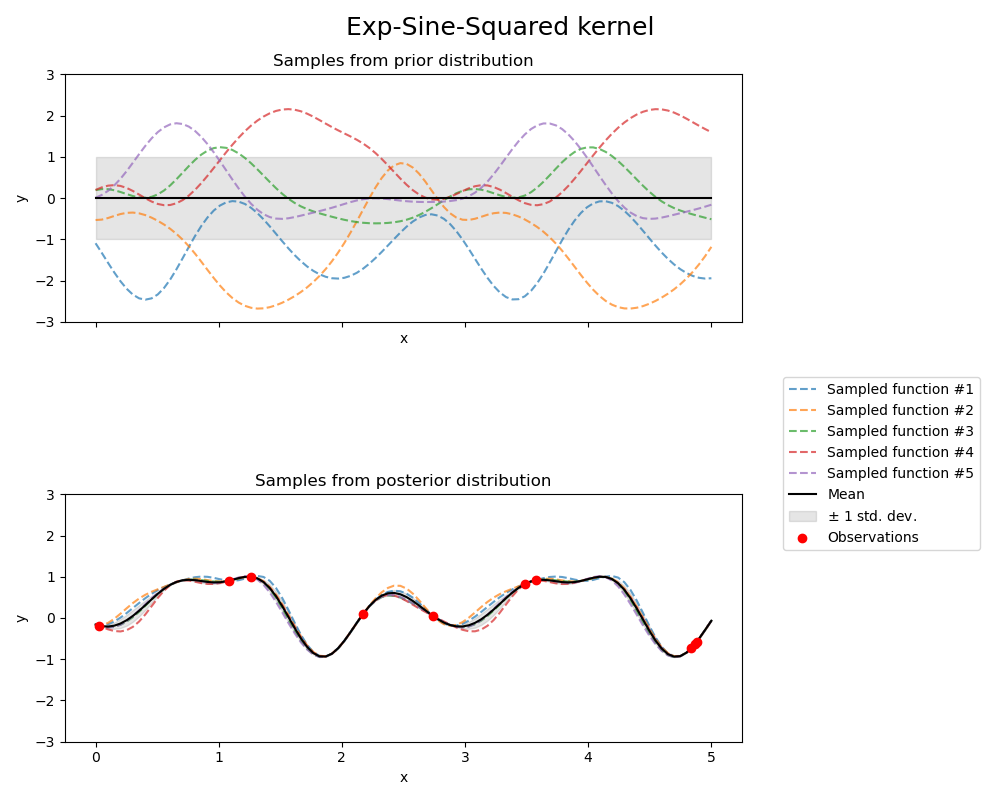
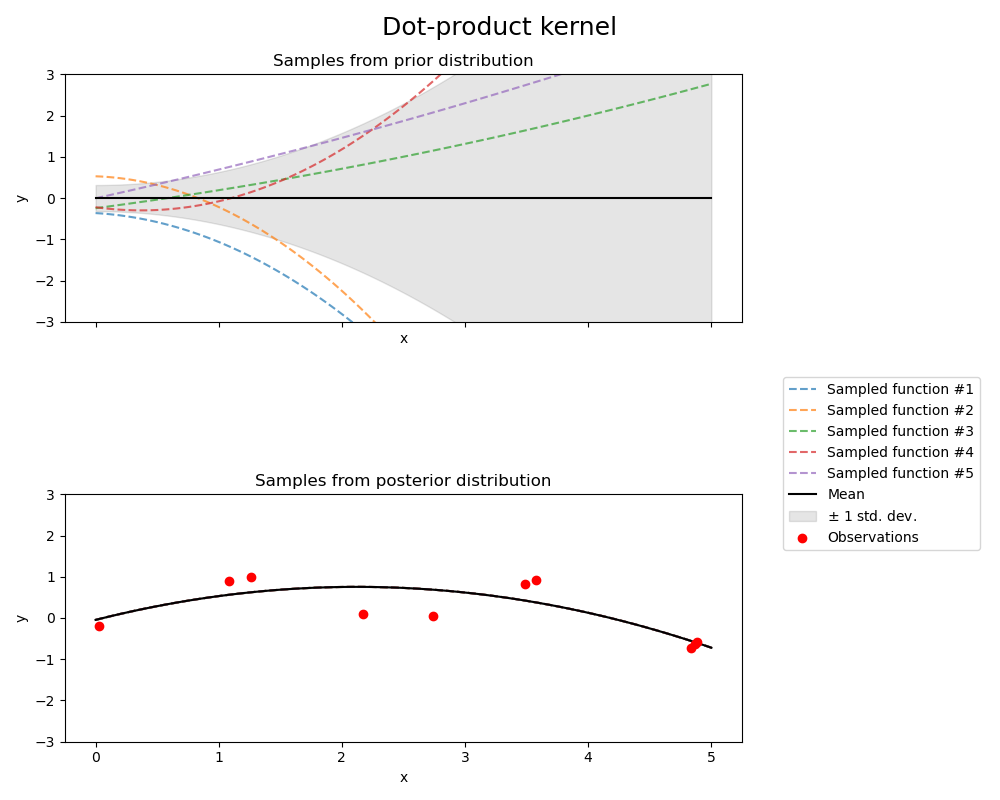
1.7.4.7. 點積核函數#
DotProduct 核函數是非靜態的,並且可以通過對 \(x_d (d = 1, . . . , D)\) 的係數設定 \(N(0, 1)\) 先驗,並對偏差設定 \(N(0, \sigma_0^2)\) 先驗,從線性迴歸中獲得。DotProduct 核函數對於座標原點的旋轉是不變的,但對於平移則不適用。它由參數 \(\sigma_0^2\) 參數化。對於 \(\sigma_0^2 = 0\),該核函數稱為齊次線性核函數,否則為非齊次線性核函數。該核函數由下式給出:
DotProduct 核函數通常與指數運算結合使用。以下圖顯示了指數為 2 的範例