3.5. 驗證曲線:繪製分數以評估模型#
每個估計器都有其優點和缺點。其泛化誤差可以分解為偏差、變異和雜訊。估計器的偏差是其在不同訓練集上的平均誤差。估計器的變異表示它對不同訓練集的敏感程度。雜訊是資料的屬性。
在下圖中,我們看到一個函數 \(f(x) = \cos (\frac{3}{2} \pi x)\) 以及該函數的一些雜訊樣本。我們使用三個不同的估計器來擬合該函數:分別使用 1、4 和 15 次多項式特徵的線性迴歸。我們看到,第一個估計器最多只能對樣本和真實函數提供較差的擬合,因為它太簡單(高偏差),第二個估計器幾乎完美地逼近它,而最後一個估計器完美地逼近訓練資料,但對真實函數的擬合效果不佳,即它對不同訓練資料非常敏感(高變異)。
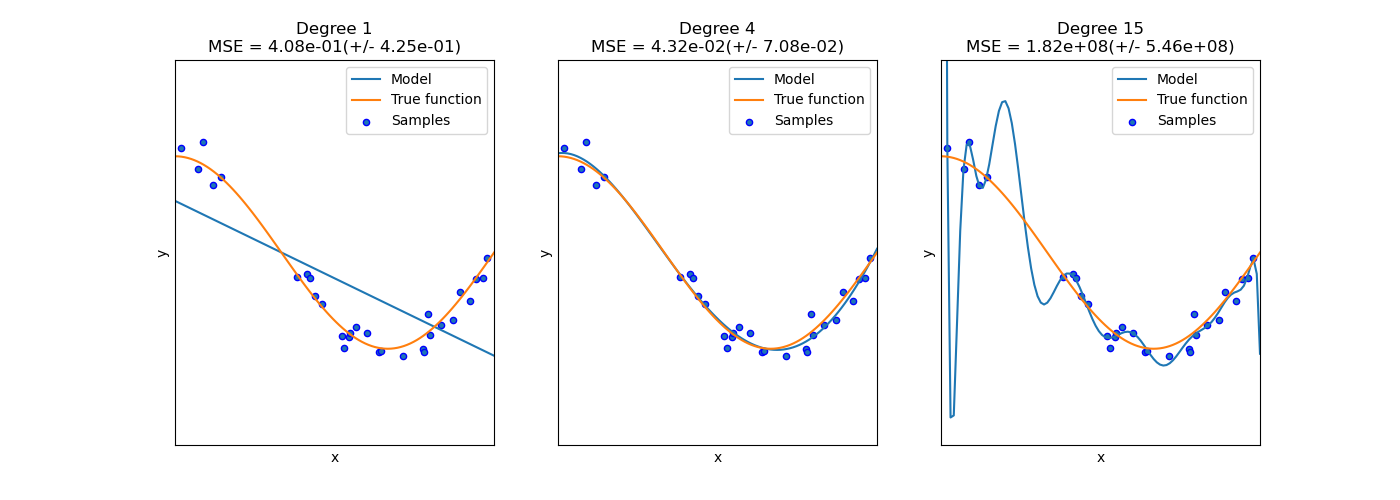
偏差和變異是估計器的固有屬性,我們通常必須選擇學習演算法和超參數,以使偏差和變異都盡可能低(參見偏差-變異困境)。降低模型變異的另一種方法是使用更多的訓練資料。但是,只有在真實函數太複雜而無法通過具有較低變異的估計器逼近時,才應收集更多的訓練資料。
在範例中看到的簡單一維問題中,很容易看出估計器是否受到偏差或變異的影響。但是,在高維空間中,模型可能很難視覺化。因此,通常使用以下描述的工具會很有幫助。
範例
3.5.1. 驗證曲線#
為了驗證模型,我們需要一個評分函數(參見指標和評分:量化預測品質),例如分類器的準確性。選擇估計器的多個超參數的正確方法當然是網格搜尋或類似的方法(參見調整估計器的超參數),這些方法選擇在驗證集或多個驗證集上具有最大分數的超參數。請注意,如果我們根據驗證分數優化超參數,則驗證分數會產生偏差,並且不再是對泛化的良好估計。為了獲得對泛化的正確估計,我們必須在另一個測試集上計算分數。
但是,有時繪製單個超參數對訓練分數和驗證分數的影響,以找出估計器是否對某些超參數值過擬合或欠擬合,會很有幫助。
在這種情況下,函數 validation_curve 可以提供幫助
>>> import numpy as np
>>> from sklearn.model_selection import validation_curve
>>> from sklearn.datasets import load_iris
>>> from sklearn.svm import SVC
>>> np.random.seed(0)
>>> X, y = load_iris(return_X_y=True)
>>> indices = np.arange(y.shape[0])
>>> np.random.shuffle(indices)
>>> X, y = X[indices], y[indices]
>>> train_scores, valid_scores = validation_curve(
... SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 3),
... )
>>> train_scores
array([[0.90..., 0.94..., 0.91..., 0.89..., 0.92...],
[0.9... , 0.92..., 0.93..., 0.92..., 0.93...],
[0.97..., 1... , 0.98..., 0.97..., 0.99...]])
>>> valid_scores
array([[0.9..., 0.9... , 0.9... , 0.96..., 0.9... ],
[0.9..., 0.83..., 0.96..., 0.96..., 0.93...],
[1.... , 0.93..., 1.... , 1.... , 0.9... ]])
如果您只想繪製驗證曲線,則類別 ValidationCurveDisplay 比在呼叫 validation_curve 的結果上手動使用 matplotlib 更直接。您可以像使用 validation_curve 一樣,使用 from_estimator 方法來生成並繪製驗證曲線
from sklearn.datasets import load_iris
from sklearn.model_selection import ValidationCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
ValidationCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 10)
)
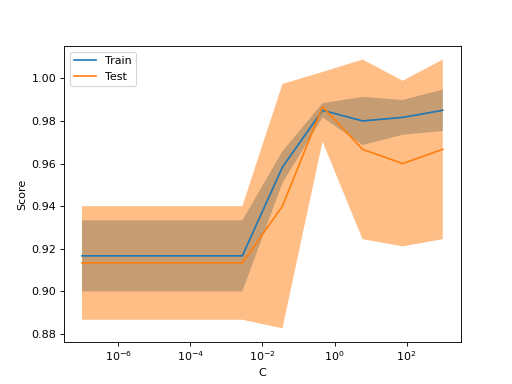
如果訓練分數和驗證分數都很低,則估計器將會欠擬合。如果訓練分數很高而驗證分數很低,則估計器會過擬合,否則它會運作得很好。通常不可能出現訓練分數低而驗證分數高的情況。
3.5.2. 學習曲線#
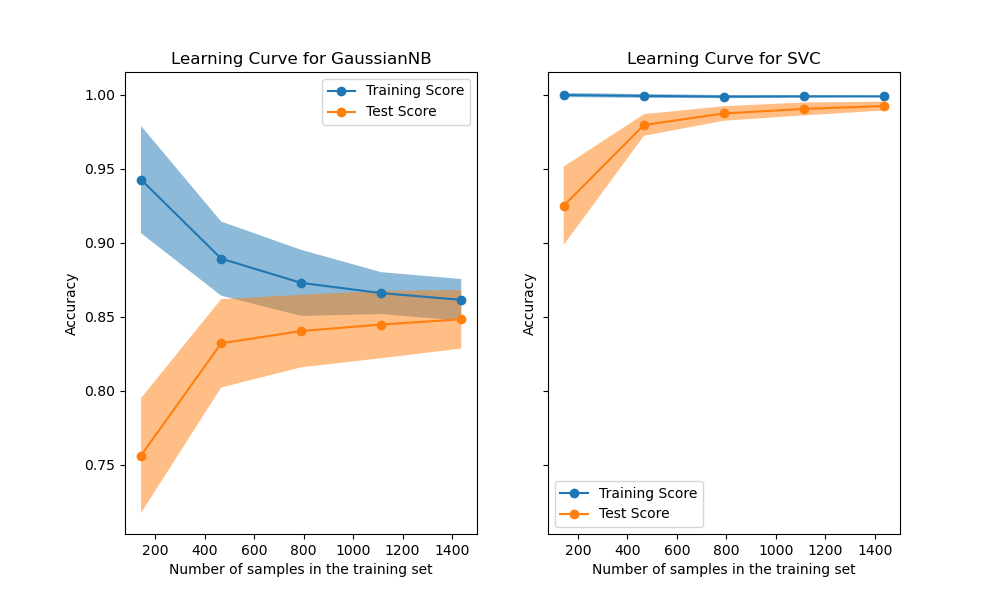
學習曲線顯示了估計器在不同數量的訓練樣本下的驗證和訓練分數。它是一種工具,可以找出從添加更多訓練資料中獲得多少好處,以及估計器是否更多地遭受變異誤差或偏差誤差的影響。考慮以下範例,其中我們繪製了樸素貝氏分類器和 SVM 的學習曲線。
對於樸素貝氏分類器,隨著訓練集大小的增加,驗證分數和訓練分數都收斂到一個相當低的值。因此,我們可能不會從更多訓練資料中獲得太多好處。
相反,對於少量資料,SVM 的訓練分數遠大於驗證分數。添加更多訓練樣本很可能會提高泛化能力。
我們可以使用函數 learning_curve 來生成繪製此類學習曲線所需的值(已使用的樣本數、訓練集上的平均分數和驗證集上的平均分數)
>>> from sklearn.model_selection import learning_curve
>>> from sklearn.svm import SVC
>>> train_sizes, train_scores, valid_scores = learning_curve(
... SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5)
>>> train_sizes
array([ 50, 80, 110])
>>> train_scores
array([[0.98..., 0.98 , 0.98..., 0.98..., 0.98...],
[0.98..., 1. , 0.98..., 0.98..., 0.98...],
[0.98..., 1. , 0.98..., 0.98..., 0.99...]])
>>> valid_scores
array([[1. , 0.93..., 1. , 1. , 0.96...],
[1. , 0.96..., 1. , 1. , 0.96...],
[1. , 0.96..., 1. , 1. , 0.96...]])
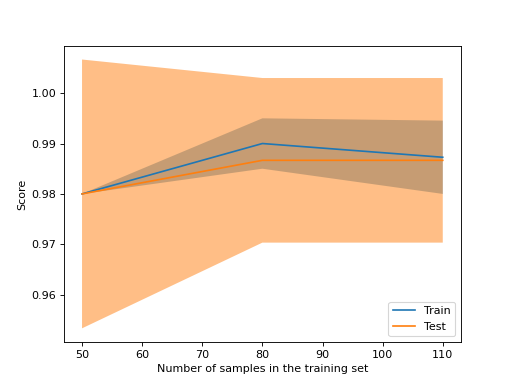
如果您只想繪製學習曲線,則類別 LearningCurveDisplay 將更易於使用。您可以像使用 learning_curve 一樣,使用 from_estimator 方法來生成並繪製學習曲線
from sklearn.datasets import load_iris
from sklearn.model_selection import LearningCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
LearningCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, train_sizes=[50, 80, 110], cv=5)
範例
有關使用學習曲線檢查預測模型可擴展性的範例,請參見繪製學習曲線並檢查模型的可擴展性。