7.3. 產生資料集#
此外,scikit-learn 還包含各種隨機樣本產生器,可用於建構大小和複雜度可控的人工資料集。
7.3.1. 用於分類和分群的產生器#
這些產生器會產生特徵矩陣和對應的離散目標。
7.3.1.1. 單一標籤#
make_blobs 會為每個類別分配一個常態分布的點集群,以建立多類別資料集。它可以控制每個集群的中心和標準差。此資料集用於示範分群。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=3, cluster_std=0.5, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.title("Three normally-distributed clusters")
plt.show()

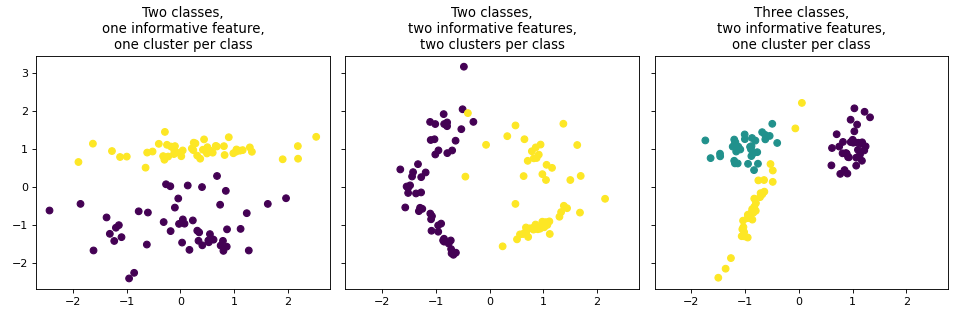
make_classification 也會建立多類別資料集,但專門透過以下方式引入雜訊:相關、冗餘和無訊息的特徵;每個類別的多個高斯集群;以及特徵空間的線性轉換。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True, sharex=True)
titles = ["Two classes,\none informative feature,\none cluster per class",
"Two classes,\ntwo informative features,\ntwo clusters per class",
"Three classes,\ntwo informative features,\none cluster per class"]
params = [
{"n_informative": 1, "n_clusters_per_class": 1, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 2, "n_classes": 2},
{"n_informative": 2, "n_clusters_per_class": 1, "n_classes": 3}
]
for i, param in enumerate(params):
X, Y = make_classification(n_features=2, n_redundant=0, random_state=1, **param)
axs[i].scatter(X[:, 0], X[:, 1], c=Y)
axs[i].set_title(titles[i])
plt.tight_layout()
plt.show()
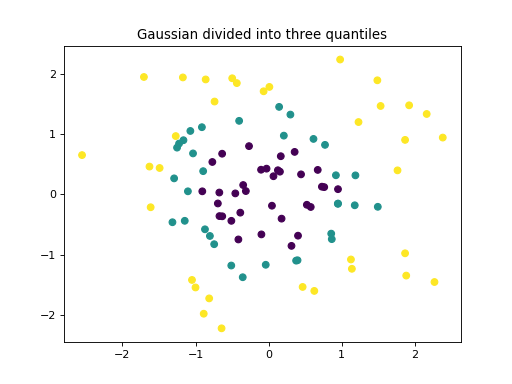
make_gaussian_quantiles 會將單一高斯集群劃分為由同心超球面分隔的近乎相等大小的類別。
import matplotlib.pyplot as plt
from sklearn.datasets import make_gaussian_quantiles
X, Y = make_gaussian_quantiles(n_features=2, n_classes=3, random_state=0)
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.title("Gaussian divided into three quantiles")
plt.show()
make_hastie_10_2 會產生一個類似的二元、10 維問題。
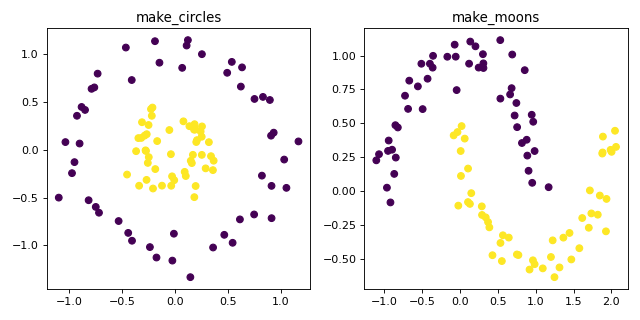
make_circles 和 make_moons 會產生 2D 二元分類資料集,這些資料集對某些演算法(例如,基於質心的分群或線性分類)構成挑戰,包括可選的高斯雜訊。它們對於視覺化很有用。make_circles 會產生具有球形決策邊界的二元分類高斯資料,而 make_moons 會產生兩個交錯的半圓。
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_moons
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
X, Y = make_circles(noise=0.1, factor=0.3, random_state=0)
ax1.scatter(X[:, 0], X[:, 1], c=Y)
ax1.set_title("make_circles")
X, Y = make_moons(noise=0.1, random_state=0)
ax2.scatter(X[:, 0], X[:, 1], c=Y)
ax2.set_title("make_moons")
plt.tight_layout()
plt.show()
7.3.1.2. 多標籤#
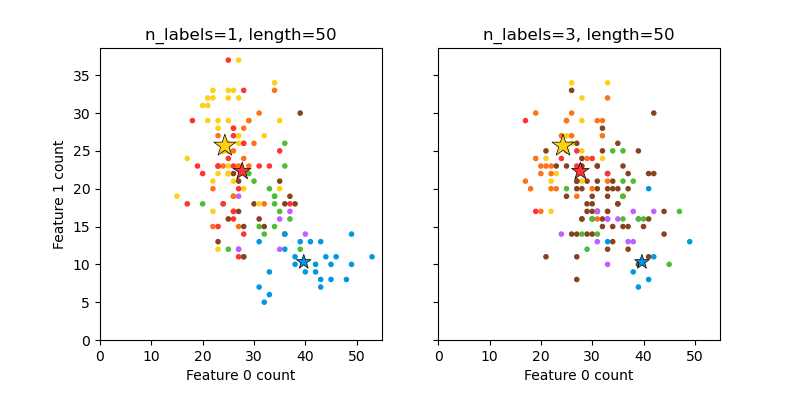
make_multilabel_classification 會產生具有多個標籤的隨機樣本,反映從主題混合中提取的詞袋。每個文件的主題數量是從卜瓦松分佈中提取的,而主題本身是從固定的隨機分佈中提取的。同樣地,單字數是從卜瓦松分佈中提取的,而單字是從多項式分佈中提取的,其中每個主題定義了單字的機率分佈。相對於真實詞袋混合的簡化包括
每個主題的單字分佈是獨立繪製的,但實際上所有分佈都會受到稀疏基礎分佈的影響,並且會相關。
對於從多個主題產生的文件,所有主題在產生其詞袋時的權重都相等。
沒有標籤的文件會從隨機位置提取單字,而不是從基礎分佈中提取。
7.3.1.3. 雙分群#
|
產生用於雙分群的常數區塊對角結構陣列。 |
|
產生具有區塊棋盤結構的陣列,以用於雙分群。 |
7.3.2. 用於迴歸的產生器#
make_regression 會將迴歸目標產生為具有雜訊的隨機特徵的可選稀疏隨機線性組合。其資訊性特徵可能是不相關的,或為低秩(少數特徵佔據大部分變異數)。
其他迴歸產生器會從隨機特徵確定性地產生函數。make_sparse_uncorrelated 會產生目標作為具有固定係數的四個特徵的線性組合。其他則明確編碼非線性關係:make_friedman1 與多項式和正弦轉換相關;make_friedman2 包含特徵乘法和倒數;而 make_friedman3 類似,但目標進行了反正切轉換。
7.3.3. 用於流形學習的產生器#
|
產生 S 曲線資料集。 |
|
產生瑞士捲資料集。 |
7.3.4. 用於分解的產生器#
|
產生具有鐘形奇異值的大部分低秩矩陣。 |
|
將訊號產生為字典元素的稀疏組合。 |
|
產生隨機對稱正定矩陣。 |
|
產生稀疏對稱正定矩陣。 |