6.6. 隨機投影#
sklearn.random_projection 模組實現了一種簡單且計算效率高的方法,可以通過犧牲一定程度的準確性(作為額外的變異數)來換取更快的處理時間和更小的模型大小,從而降低資料的維度。此模組實作了兩種非結構化隨機矩陣:高斯隨機矩陣 和 稀疏隨機矩陣。
隨機投影矩陣的維度和分佈受到控制,以保持資料集中任意兩個樣本之間的成對距離。因此,隨機投影是一種適用於基於距離的方法的近似技術。
參考文獻
Sanjoy Dasgupta. 2000. 隨機投影的實驗。 在人工智慧不確定性第十六屆會議論文集(UAI’00),Craig Boutilier 和 Moisés Goldszmidt(編)。Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 143-151。
Ella Bingham 和 Heikki Mannila. 2001. 降維中的隨機投影:圖像和文字資料的應用。 在第七屆 ACM SIGKDD 國際知識發現與資料探勘會議論文集(KDD ‘01)。ACM, New York, NY, USA, 245-250。
6.6.1. 強森-林登斯特勞斯引理#
隨機投影效率背後的主要理論結果是 強森-林登斯特勞斯引理(引用維基百科)
在數學中,強森-林登斯特勞斯引理是關於從高維空間到低維歐幾里得空間的點的低失真嵌入的結果。引理指出,高維空間中的一小組點可以嵌入到維度低得多的空間中,使得點之間的距離幾乎得以保留。用於嵌入的映射至少是利普希茨連續的,甚至可以採用正交投影。
僅知道樣本數量,johnson_lindenstrauss_min_dim 會保守地估計隨機子空間的最小大小,以保證隨機投影引入的有界失真
>>> from sklearn.random_projection import johnson_lindenstrauss_min_dim
>>> johnson_lindenstrauss_min_dim(n_samples=1e6, eps=0.5)
663
>>> johnson_lindenstrauss_min_dim(n_samples=1e6, eps=[0.5, 0.1, 0.01])
array([ 663, 11841, 1112658])
>>> johnson_lindenstrauss_min_dim(n_samples=[1e4, 1e5, 1e6], eps=0.1)
array([ 7894, 9868, 11841])
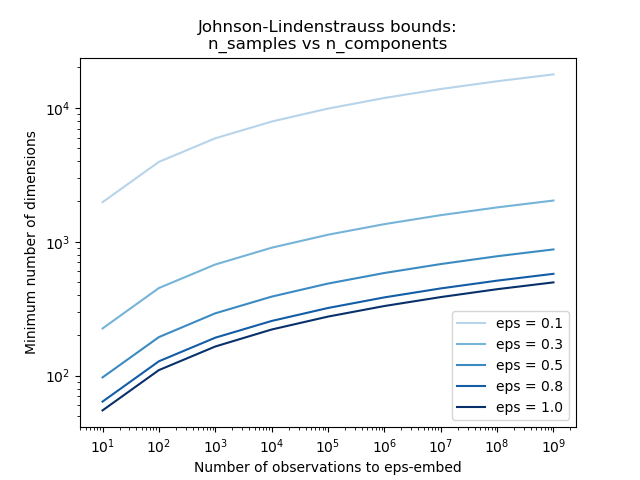
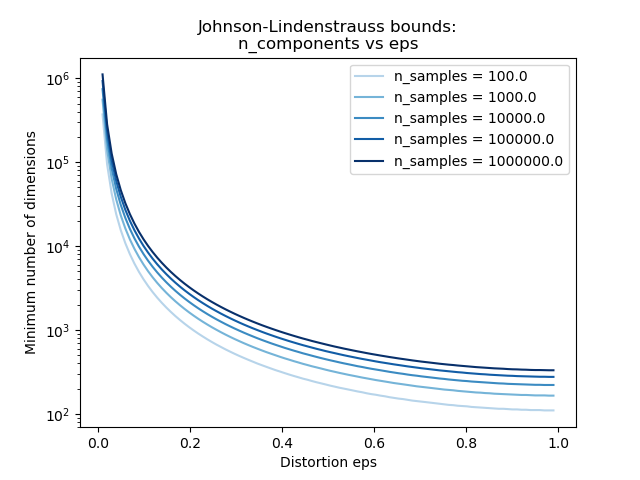
範例
請參閱 使用隨機投影嵌入的強森-林登斯特勞斯界限,以取得關於強森-林登斯特勞斯引理的理論說明以及使用稀疏隨機矩陣的實證驗證。
參考文獻
Sanjoy Dasgupta 和 Anupam Gupta, 1999. 強森-林登斯特勞斯引理的基本證明。
6.6.2. 高斯隨機投影#
GaussianRandomProjection 通過將原始輸入空間投影到隨機生成的矩陣上來降低維度,其中組件是從以下分佈中提取的 \(N(0, \frac{1}{n_{components}})\)。
以下是一個小片段,說明如何使用高斯隨機投影轉換器
>>> import numpy as np
>>> from sklearn import random_projection
>>> X = np.random.rand(100, 10000)
>>> transformer = random_projection.GaussianRandomProjection()
>>> X_new = transformer.fit_transform(X)
>>> X_new.shape
(100, 3947)
6.6.3. 稀疏隨機投影#
SparseRandomProjection 通過使用稀疏隨機矩陣投影原始輸入空間來降低維度。
稀疏隨機矩陣是密集高斯隨機投影矩陣的替代方法,它保證了相似的嵌入品質,同時具有更高的記憶體效率,並允許更快地計算投影資料。
如果我們定義 s = 1 / 密度,則隨機矩陣的元素是從
其中 \(n_{\text{components}}\) 是投影子空間的大小。預設情況下,非零元素的密度設定為 Ping Li 等人建議的最小密度:\(1 / \sqrt{n_{\text{features}}}\)。
以下是一個小片段,說明如何使用稀疏隨機投影轉換器
>>> import numpy as np
>>> from sklearn import random_projection
>>> X = np.random.rand(100, 10000)
>>> transformer = random_projection.SparseRandomProjection()
>>> X_new = transformer.fit_transform(X)
>>> X_new.shape
(100, 3947)
參考文獻
D. Achlioptas. 2003. 資料庫友善的隨機投影:帶有二元硬幣的強森-林登斯特勞斯。《電腦與系統科學雜誌》66 (2003) 671-687。
Ping Li、Trevor J. Hastie 和 Kenneth W. Church. 2006. 非常稀疏的隨機投影。 在第十二屆 ACM SIGKDD 國際知識發現與資料探勘會議論文集(KDD ‘06)。ACM, New York, NY, USA, 287-296。
6.6.4. 反向轉換#
隨機投影轉換器具有 compute_inverse_components 參數。當設定為 True 時,在擬合期間建立隨機 components_ 矩陣之後,轉換器會計算此矩陣的偽逆矩陣,並將其儲存為 inverse_components_。inverse_components_ 矩陣的形狀為 \(n_{features} \times n_{components}\),它始終是一個密集矩陣,無論組件矩陣是稀疏還是密集。因此,根據特徵和組件的數量,它可能會使用大量記憶體。
當調用 inverse_transform 方法時,它會計算輸入 X 和逆組件的轉置的乘積。如果在擬合期間已計算逆組件,則每次調用 inverse_transform 時都會重複使用它們。否則,每次都會重新計算它們,這可能會很耗費資源。結果始終是密集的,即使 X 是稀疏的。
以下是一個小程式碼範例,說明如何使用反向轉換功能
>>> import numpy as np
>>> from sklearn.random_projection import SparseRandomProjection
>>> X = np.random.rand(100, 10000)
>>> transformer = SparseRandomProjection(
... compute_inverse_components=True
... )
...
>>> X_new = transformer.fit_transform(X)
>>> X_new.shape
(100, 3947)
>>> X_new_inversed = transformer.inverse_transform(X_new)
>>> X_new_inversed.shape
(100, 10000)
>>> X_new_again = transformer.transform(X_new_inversed)
>>> np.allclose(X_new, X_new_again)
True