6.3. 預處理資料#
sklearn.preprocessing 套件提供幾個常用的工具函式和轉換器類別,可將原始特徵向量變更為更適合下游估計器的表示形式。
一般而言,許多學習演算法(如線性模型)都受益於資料集的標準化(請參閱特徵縮放的重要性)。如果資料集中存在一些離群值,則使用穩健縮放器或其他轉換器可能更合適。在比較不同縮放器對含有離群值的資料的影響中,重點說明了不同縮放器、轉換器和正規化器在包含邊緣離群值的資料集上的行為。
6.3.1. 標準化,或均值移除和變異數縮放#
資料集的標準化是 scikit-learn 中實作的許多機器學習估計器的常見需求;如果個別特徵看起來或多或少不像標準常態分佈的資料:均值為零且變異數為一的高斯分佈,則它們的行為可能會很差。
實際上,我們通常會忽略分佈的形狀,而只是透過移除每個特徵的均值來轉換資料以將其置中,然後將非恆定的特徵除以其標準差來縮放資料。
例如,學習演算法的目標函式中使用的許多元素(例如支援向量機的 RBF 核或線性模型的 l1 和 l2 正規化器)可能會假設所有特徵都以零為中心或具有相同的變異數階數。如果某個特徵的變異數比其他特徵大幾個數量級,則它可能會主導目標函式,並使估計器無法正確地從其他特徵中學習。
preprocessing 模組提供 StandardScaler 工具類別,這是對類陣列資料集執行以下操作的快速簡便方法
>>> from sklearn import preprocessing
>>> import numpy as np
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> scaler
StandardScaler()
>>> scaler.mean_
array([1. ..., 0. ..., 0.33...])
>>> scaler.scale_
array([0.81..., 0.81..., 1.24...])
>>> X_scaled = scaler.transform(X_train)
>>> X_scaled
array([[ 0. ..., -1.22..., 1.33...],
[ 1.22..., 0. ..., -0.26...],
[-1.22..., 1.22..., -1.06...]])
縮放資料具有零均值和單位變異數
>>> X_scaled.mean(axis=0)
array([0., 0., 0.])
>>> X_scaled.std(axis=0)
array([1., 1., 1.])
此類別實作 Transformer API 以計算訓練集上的均值和標準差,以便稍後能夠將相同的轉換重新套用至測試集。因此,此類別適用於 Pipeline 的早期步驟
>>> from sklearn.datasets import make_classification
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> X, y = make_classification(random_state=42)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
>>> pipe = make_pipeline(StandardScaler(), LogisticRegression())
>>> pipe.fit(X_train, y_train) # apply scaling on training data
Pipeline(steps=[('standardscaler', StandardScaler()),
('logisticregression', LogisticRegression())])
>>> pipe.score(X_test, y_test) # apply scaling on testing data, without leaking training data.
0.96
可以透過傳遞 with_mean=False 或 with_std=False 至 StandardScaler 的建構函式來停用置中或縮放。
6.3.1.1. 將特徵縮放至範圍#
另一種標準化方法是將特徵縮放至給定的最小值和最大值之間,通常介於零和一之間,或使每個特徵的最大絕對值縮放至單位大小。這可以使用 MinMaxScaler 或 MaxAbsScaler 來實現。
使用此縮放的動機包括對特徵的非常小的標準差具有穩健性,並保留稀疏資料中的零項。
以下是一個範例,將玩具資料矩陣縮放到 [0, 1] 範圍
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[0.5 , 0. , 1. ],
[1. , 0.5 , 0.33333333],
[0. , 1. , 0. ]])
然後,轉換器的相同執行個體可以套用至在擬合呼叫期間未見過的一些新測試資料:將套用相同的縮放和移動操作,以與對訓練資料執行的轉換一致
>>> X_test = np.array([[-3., -1., 4.]])
>>> X_test_minmax = min_max_scaler.transform(X_test)
>>> X_test_minmax
array([[-1.5 , 0. , 1.66666667]])
可以檢查縮放器屬性以找出在訓練資料上學習的轉換的確切性質
>>> min_max_scaler.scale_
array([0.5 , 0.5 , 0.33...])
>>> min_max_scaler.min_
array([0. , 0.5 , 0.33...])
如果 MinMaxScaler 給定明確的 feature_range=(min, max),則完整公式為
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
MaxAbsScaler 的運作方式非常相似,但以將訓練資料置於 [-1, 1] 範圍內的方式進行縮放,方法是除以每個特徵中的最大值。它適用於已在零或稀疏資料處置中的資料。
以下是如何使用前一個範例中的玩具資料與此縮放器
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> max_abs_scaler = preprocessing.MaxAbsScaler()
>>> X_train_maxabs = max_abs_scaler.fit_transform(X_train)
>>> X_train_maxabs
array([[ 0.5, -1. , 1. ],
[ 1. , 0. , 0. ],
[ 0. , 1. , -0.5]])
>>> X_test = np.array([[ -3., -1., 4.]])
>>> X_test_maxabs = max_abs_scaler.transform(X_test)
>>> X_test_maxabs
array([[-1.5, -1. , 2. ]])
>>> max_abs_scaler.scale_
array([2., 1., 2.])
6.3.1.2. 縮放稀疏資料#
對稀疏資料進行置中會破壞資料中的稀疏結構,因此很少是明智之舉。但是,縮放稀疏輸入可能有意義,特別是當特徵位於不同尺度上時。
MaxAbsScaler 是專為縮放稀疏資料而設計的,並且是建議的執行方式。但是,只要將 with_mean=False 明確傳遞至建構函式,StandardScaler 就可以接受 scipy.sparse 矩陣作為輸入。否則,將引發 ValueError,因為靜默置中會破壞稀疏性,並且經常會因為意外分配過多的記憶體而導致執行崩潰。 RobustScaler 無法擬合稀疏輸入,但是您可以在稀疏輸入上使用 transform 方法。
請注意,縮放器接受壓縮稀疏列和壓縮稀疏欄格式(請參閱 scipy.sparse.csr_matrix 和 scipy.sparse.csc_matrix)。任何其他稀疏輸入都將轉換為壓縮稀疏列表示法。為了避免不必要的記憶體複製,建議在上游選擇 CSR 或 CSC 表示法。
最後,如果預期置中資料足夠小,則使用稀疏矩陣的 toarray 方法將輸入明確轉換為陣列是另一種選擇。
6.3.1.3. 使用離群值縮放資料#
如果您的資料包含許多離群值,則使用資料的均值和變異數進行縮放可能無法很好地工作。在這些情況下,您可以改為使用 RobustScaler 作為替代品。它使用更穩健的估計值來表示資料的中心和範圍。
參考文獻#
關於數據中心化和縮放重要性的進一步討論,請參考此常見問題解答:我應該對數據進行正規化/標準化/重新縮放嗎?
6.3.1.4. 中心化核矩陣#
如果你有一個核函數 \(K\) 的核矩陣,該核函數計算由函數 \(\phi(\cdot)\) 定義的特徵空間(可能是隱式)中的點積,則 KernelCenterer 可以轉換核矩陣,使其包含由 \(\phi\) 定義的特徵空間中的內積,然後移除該空間中的均值。換句話說,KernelCenterer 計算與正半定核函數 \(K\) 關聯的中心化格拉姆矩陣。
數學公式#
現在我們有了直覺,可以看一下數學公式。令 \(K\) 為從 \(X\) 計算出的形狀為 (n_samples, n_samples) 的核矩陣,\(X\) 是形狀為 (n_samples, n_features) 的數據矩陣,在 fit 步驟中計算。\(K\) 的定義為
\(\phi(X)\) 是將 \(X\) 映射到希爾伯特空間的函數。中心化核矩陣 \(\tilde{K}\) 的定義為
其中 \(\tilde{\phi}(X)\) 是將 \(\phi(X)\) 在希爾伯特空間中中心化所得的結果。
因此,可以使用函數 \(\phi(\cdot)\) 映射 \(X\) 並在此新空間中中心化數據,以計算 \(\tilde{K}\)。然而,之所以經常使用核函數,是因為它們允許一些代數計算,避免使用 \(\phi(\cdot)\) 明確計算此映射。事實上,可以如 [Scholkopf1998] 的附錄 B 所示隱式地進行中心化
\(1_{\text{n}_{samples}}\) 是一個形狀為 (n_samples, n_samples) 的矩陣,其中所有條目都等於 \(\frac{1}{\text{n}_{samples}}\)。在 transform 步驟中,核函數變為 \(K_{test}(X, Y)\),其定義為
\(Y\) 是形狀為 (n_samples_test, n_features) 的測試數據集,因此 \(K_{test}\) 的形狀為 (n_samples_test, n_samples)。在這種情況下,\(K_{test}\) 的中心化方式如下
\(1'_{\text{n}_{samples}}\) 是一個形狀為 (n_samples_test, n_samples) 的矩陣,其中所有條目都等於 \(\frac{1}{\text{n}_{samples}}\)。
參考文獻
B. Schölkopf、A. Smola 和 K.R. Müller,“Nonlinear component analysis as a kernel eigenvalue problem.” Neural computation 10.5 (1998): 1299-1319.
6.3.2. 非線性轉換#
有兩種類型的轉換可用:分位數轉換和冪轉換。分位數和冪轉換都基於特徵的單調轉換,因此保留了每個特徵上數值的排序。
分位數轉換根據公式 \(G^{-1}(F(X))\) 將所有特徵放入相同的期望分佈,其中 \(F\) 是特徵的累積分佈函數,\(G^{-1}\) 是所需輸出分佈 \(G\) 的分位數函數。此公式使用以下兩個事實:(i)如果 \(X\) 是具有連續累積分佈函數 \(F\) 的隨機變數,則 \(F(X)\) 在 \([0,1]\) 上均勻分佈;(ii) 如果 \(U\) 是在 \([0,1]\) 上均勻分佈的隨機變數,則 \(G^{-1}(U)\) 的分佈為 \(G\)。透過執行排序轉換,分位數轉換可以平滑異常分佈,並且比縮放方法受離群值的影響較小。但是,它確實會扭曲特徵內部和跨特徵的相關性和距離。
冪轉換是一系列參數轉換,旨在將來自任何分佈的數據映射到盡可能接近高斯分佈。
6.3.2.1. 映射到均勻分佈#
QuantileTransformer 提供了一種非參數轉換,將數據映射到值介於 0 和 1 之間的均勻分佈
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
>>> quantile_transformer = preprocessing.QuantileTransformer(random_state=0)
>>> X_train_trans = quantile_transformer.fit_transform(X_train)
>>> X_test_trans = quantile_transformer.transform(X_test)
>>> np.percentile(X_train[:, 0], [0, 25, 50, 75, 100])
array([ 4.3, 5.1, 5.8, 6.5, 7.9])
此特徵對應於以公分 (cm) 為單位的花萼長度。一旦應用了分位數轉換,這些地標就會接近先前定義的百分位數
>>> np.percentile(X_train_trans[:, 0], [0, 25, 50, 75, 100])
...
array([ 0.00... , 0.24..., 0.49..., 0.73..., 0.99... ])
這可以在具有類似標記的獨立測試集中確認
>>> np.percentile(X_test[:, 0], [0, 25, 50, 75, 100])
...
array([ 4.4 , 5.125, 5.75 , 6.175, 7.3 ])
>>> np.percentile(X_test_trans[:, 0], [0, 25, 50, 75, 100])
...
array([ 0.01..., 0.25..., 0.46..., 0.60... , 0.94...])
6.3.2.2. 映射到高斯分佈#
在許多建模場景中,數據集中特徵的常態性是理想的。冪轉換是一系列參數化的單調轉換,旨在將來自任何分佈的數據映射到盡可能接近高斯分佈,以穩定變異數並最小化偏度。
PowerTransformer 目前提供了兩種此類冪轉換:Yeo-Johnson 轉換和 Box-Cox 轉換。
Yeo-Johnson 轉換#
Box-Cox 轉換#
Box-Cox 只能應用於嚴格正數的數據。在這兩種方法中,轉換都由 \(\lambda\) 參數化,該參數透過最大似然估計確定。以下是一個使用 Box-Cox 將從對數常態分佈中提取的樣本映射到常態分佈的範例
>>> pt = preprocessing.PowerTransformer(method='box-cox', standardize=False)
>>> X_lognormal = np.random.RandomState(616).lognormal(size=(3, 3))
>>> X_lognormal
array([[1.28..., 1.18..., 0.84...],
[0.94..., 1.60..., 0.38...],
[1.35..., 0.21..., 1.09...]])
>>> pt.fit_transform(X_lognormal)
array([[ 0.49..., 0.17..., -0.15...],
[-0.05..., 0.58..., -0.57...],
[ 0.69..., -0.84..., 0.10...]])
雖然上面的範例將 standardize 選項設定為 False,但 PowerTransformer 預設會對轉換後的輸出應用零均值、單位變異數正規化。
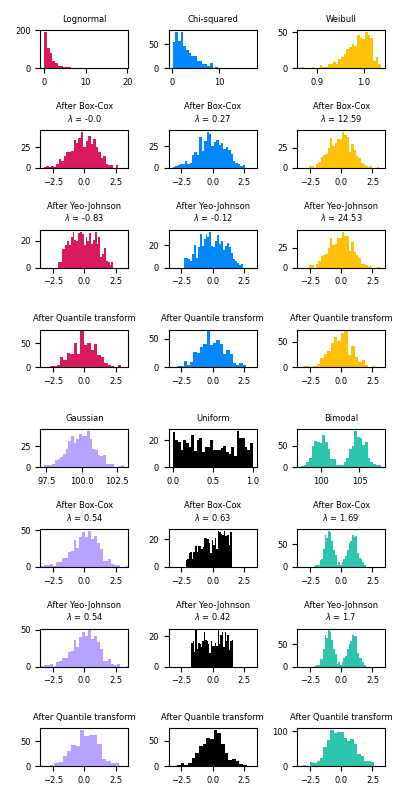
以下是 Box-Cox 和 Yeo-Johnson 應用於各種機率分佈的範例。請注意,當應用於某些分佈時,冪轉換會達到非常類似高斯的結果,但在其他分佈中,它們是無效的。這突顯了在轉換前後視覺化數據的重要性。
也可以透過設定 output_distribution='normal' 使用 QuantileTransformer 將數據映射到常態分佈。使用先前使用虹膜數據集的範例
>>> quantile_transformer = preprocessing.QuantileTransformer(
... output_distribution='normal', random_state=0)
>>> X_trans = quantile_transformer.fit_transform(X)
>>> quantile_transformer.quantiles_
array([[4.3, 2. , 1. , 0.1],
[4.4, 2.2, 1.1, 0.1],
[4.4, 2.2, 1.2, 0.1],
...,
[7.7, 4.1, 6.7, 2.5],
[7.7, 4.2, 6.7, 2.5],
[7.9, 4.4, 6.9, 2.5]])
因此,輸入的中位數變為輸出的平均值,居中於 0。常態輸出被裁剪,以便輸入的最小值和最大值(分別對應於 1e-7 和 1 - 1e-7 分位數)在轉換下不會變為無窮大。
6.3.3. 正規化#
正規化是將個別樣本縮放至單位範數的過程。如果您計劃使用二次形式(例如點積)或任何其他核函數來量化任何一對樣本的相似性,這個過程會很有用。
此假設是向量空間模型的基礎,該模型常被用於文本分類和聚類情境。
函數 normalize 提供了一種快速簡便的方法,可以對單個類數組的資料集執行此操作,可以使用 l1、l2 或 max 範數。
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
preprocessing 模組進一步提供了一個實用類別 Normalizer,它使用 Transformer API 實現相同的操作(即使在這種情況下 fit 方法無用:此類別是無狀態的,因為此操作獨立處理樣本)。
因此,此類別適合在 Pipeline 的早期步驟中使用。
>>> normalizer = preprocessing.Normalizer().fit(X) # fit does nothing
>>> normalizer
Normalizer()
正規化器實例隨後可以像任何轉換器一樣用於樣本向量。
>>> normalizer.transform(X)
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
>>> normalizer.transform([[-1., 1., 0.]])
array([[-0.70..., 0.70..., 0. ...]])
注意:L2 正規化也稱為空間符號預處理。
稀疏輸入#
normalize 和 Normalizer 接受來自 scipy.sparse 的密集類陣列和稀疏矩陣作為輸入。
對於稀疏輸入,資料在饋入高效的 Cython 常式之前,會轉換為壓縮稀疏行表示法(請參閱 scipy.sparse.csr_matrix)。為了避免不必要的記憶體複製,建議選擇上游的 CSR 表示法。
6.3.4. 編碼類別特徵#
特徵通常不是以連續值而是以類別形式給出。例如,一個人可能具有 ["男性", "女性"]、["來自歐洲", "來自美國", "來自亞洲"]、["使用 Firefox", "使用 Chrome", "使用 Safari", "使用 Internet Explorer"] 等特徵。此類特徵可以有效地編碼為整數,例如 ["男性", "來自美國", "使用 Internet Explorer"] 可以表示為 [0, 1, 3],而 ["女性", "來自亞洲", "使用 Chrome"] 則為 [1, 2, 1]。
為了將類別特徵轉換為此類整數代碼,我們可以使用 OrdinalEncoder。此估算器會將每個類別特徵轉換為一個新的整數特徵(0 到 n_categories - 1)。
>>> enc = preprocessing.OrdinalEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OrdinalEncoder()
>>> enc.transform([['female', 'from US', 'uses Safari']])
array([[0., 1., 1.]])
然而,此類整數表示不能直接用於所有 scikit-learn 估算器,因為這些估算器期望連續輸入,並且會將類別解釋為已排序,這通常不是預期的(即,瀏覽器組是任意排序的)。
預設情況下,OrdinalEncoder 也會傳遞由 np.nan 指示的遺失值。
>>> enc = preprocessing.OrdinalEncoder()
>>> X = [['male'], ['female'], [np.nan], ['female']]
>>> enc.fit_transform(X)
array([[ 1.],
[ 0.],
[nan],
[ 0.]])
OrdinalEncoder 提供一個參數 encoded_missing_value 來編碼遺失值,而無需建立管線並使用 SimpleImputer。
>>> enc = preprocessing.OrdinalEncoder(encoded_missing_value=-1)
>>> X = [['male'], ['female'], [np.nan], ['female']]
>>> enc.fit_transform(X)
array([[ 1.],
[ 0.],
[-1.],
[ 0.]])
上述處理等效於以下管線
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.impute import SimpleImputer
>>> enc = Pipeline(steps=[
... ("encoder", preprocessing.OrdinalEncoder()),
... ("imputer", SimpleImputer(strategy="constant", fill_value=-1)),
... ])
>>> enc.fit_transform(X)
array([[ 1.],
[ 0.],
[-1.],
[ 0.]])
將類別特徵轉換為可用於 scikit-learn 估算器的另一種方法是使用 one-of-K,也稱為 one-hot 或虛擬編碼。這種編碼類型可以使用 OneHotEncoder 獲得,它會將每個具有 n_categories 個可能值的類別特徵轉換為 n_categories 個二元特徵,其中一個為 1,其他所有為 0。
繼續上面的範例
>>> enc = preprocessing.OneHotEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder()
>>> enc.transform([['female', 'from US', 'uses Safari'],
... ['male', 'from Europe', 'uses Safari']]).toarray()
array([[1., 0., 0., 1., 0., 1.],
[0., 1., 1., 0., 0., 1.]])
預設情況下,每個特徵可以採用的值是從資料集中自動推斷出來的,並且可以在 categories_ 屬性中找到。
>>> enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
可以使用參數 categories 明確指定此項。在我們的資料集中,有兩個性別、四個可能的大陸和四個網頁瀏覽器。
>>> genders = ['female', 'male']
>>> locations = ['from Africa', 'from Asia', 'from Europe', 'from US']
>>> browsers = ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari']
>>> enc = preprocessing.OneHotEncoder(categories=[genders, locations, browsers])
>>> # Note that for there are missing categorical values for the 2nd and 3rd
>>> # feature
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(categories=[['female', 'male'],
['from Africa', 'from Asia', 'from Europe',
'from US'],
['uses Chrome', 'uses Firefox', 'uses IE',
'uses Safari']])
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0.]])
如果訓練資料可能缺少類別特徵,則通常最好指定 handle_unknown='infrequent_if_exist' 而不是像上面一樣手動設定 categories。當指定 handle_unknown='infrequent_if_exist' 並且在轉換期間遇到未知類別時,不會引發錯誤,但此特徵產生的 one-hot 編碼欄位將全部為零,或者如果啟用,則將視為不常使用的類別。(僅 one-hot 編碼支援 handle_unknown='infrequent_if_exist')
>>> enc = preprocessing.OneHotEncoder(handle_unknown='infrequent_if_exist')
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(handle_unknown='infrequent_if_exist')
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 0., 0., 0.]])
也可以透過使用 drop 參數將每個欄位編碼為 n_categories - 1 個欄位而不是 n_categories 個欄位。此參數允許使用者指定要捨棄的每個特徵的類別。這有助於避免某些分類器中輸入矩陣的共線性。此類功能很有用,例如,當使用非正規化的迴歸(LinearRegression)時,因為共線性會導致共變異數矩陣不可逆。
>>> X = [['male', 'from US', 'uses Safari'],
... ['female', 'from Europe', 'uses Firefox']]
>>> drop_enc = preprocessing.OneHotEncoder(drop='first').fit(X)
>>> drop_enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object),
array(['uses Firefox', 'uses Safari'], dtype=object)]
>>> drop_enc.transform(X).toarray()
array([[1., 1., 1.],
[0., 0., 0.]])
可能只想為具有 2 個類別的特徵捨棄兩個欄位中的一個。在這種情況下,您可以設定參數 drop='if_binary'。
>>> X = [['male', 'US', 'Safari'],
... ['female', 'Europe', 'Firefox'],
... ['female', 'Asia', 'Chrome']]
>>> drop_enc = preprocessing.OneHotEncoder(drop='if_binary').fit(X)
>>> drop_enc.categories_
[array(['female', 'male'], dtype=object), array(['Asia', 'Europe', 'US'], dtype=object),
array(['Chrome', 'Firefox', 'Safari'], dtype=object)]
>>> drop_enc.transform(X).toarray()
array([[1., 0., 0., 1., 0., 0., 1.],
[0., 0., 1., 0., 0., 1., 0.],
[0., 1., 0., 0., 1., 0., 0.]])
在轉換後的 X 中,第一欄是使用類別「男性」/「女性」編碼的特徵,而其餘 6 個欄是分別具有 3 個類別的 2 個特徵的編碼。
當 handle_unknown='ignore' 且 drop 不是 None 時,未知類別將編碼為全零。
>>> drop_enc = preprocessing.OneHotEncoder(drop='first',
... handle_unknown='ignore').fit(X)
>>> X_test = [['unknown', 'America', 'IE']]
>>> drop_enc.transform(X_test).toarray()
array([[0., 0., 0., 0., 0.]])
在轉換期間,X_test 中的所有類別都是未知的,並且將對應至全零。這表示未知類別將具有與捨棄的類別相同的對應。如果捨棄類別,OneHotEncoder.inverse_transform 會將所有零對應至捨棄的類別;如果未捨棄類別,則對應至 None。
>>> drop_enc = preprocessing.OneHotEncoder(drop='if_binary', sparse_output=False,
... handle_unknown='ignore').fit(X)
>>> X_test = [['unknown', 'America', 'IE']]
>>> X_trans = drop_enc.transform(X_test)
>>> X_trans
array([[0., 0., 0., 0., 0., 0., 0.]])
>>> drop_enc.inverse_transform(X_trans)
array([['female', None, None]], dtype=object)
支援含有遺失值的類別特徵#
OneHotEncoder 透過將遺失值視為一個額外的類別,來支援含有遺失值的類別特徵。
>>> X = [['male', 'Safari'],
... ['female', None],
... [np.nan, 'Firefox']]
>>> enc = preprocessing.OneHotEncoder(handle_unknown='error').fit(X)
>>> enc.categories_
[array(['female', 'male', nan], dtype=object),
array(['Firefox', 'Safari', None], dtype=object)]
>>> enc.transform(X).toarray()
array([[0., 1., 0., 0., 1., 0.],
[1., 0., 0., 0., 0., 1.],
[0., 0., 1., 1., 0., 0.]])
如果一個特徵同時包含 np.nan 和 None,它們將被視為不同的類別。
>>> X = [['Safari'], [None], [np.nan], ['Firefox']]
>>> enc = preprocessing.OneHotEncoder(handle_unknown='error').fit(X)
>>> enc.categories_
[array(['Firefox', 'Safari', None, nan], dtype=object)]
>>> enc.transform(X).toarray()
array([[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.],
[1., 0., 0., 0.]])
請參閱從字典載入特徵,了解以字典而非純量表示的類別特徵。
6.3.4.1. 不常出現的類別#
OneHotEncoder 和 OrdinalEncoder 支援將不常出現的類別聚合到每個特徵的單一輸出中。啟用不常出現類別收集的參數是 min_frequency 和 max_categories。
min_frequency要嘛是等於或大於 1 的整數,要嘛是介於(0.0, 1.0)之間的浮點數。如果min_frequency是整數,則基數小於min_frequency的類別將被視為不常出現。如果min_frequency是浮點數,則基數小於樣本總數此分數的類別將被視為不常出現。預設值為 1,表示每個類別都個別編碼。max_categories要嘛是None,要嘛是任何大於 1 的整數。此參數為每個輸入特徵設定輸出特徵數量的上限。max_categories包含合併不常出現類別的特徵。
在以下使用 OrdinalEncoder 的範例中,類別 'dog' 和 'snake' 被視為不常出現
>>> X = np.array([['dog'] * 5 + ['cat'] * 20 + ['rabbit'] * 10 +
... ['snake'] * 3], dtype=object).T
>>> enc = preprocessing.OrdinalEncoder(min_frequency=6).fit(X)
>>> enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
>>> enc.transform(np.array([['dog'], ['cat'], ['rabbit'], ['snake']]))
array([[2.],
[0.],
[1.],
[2.]])
OrdinalEncoder 的 max_categories 並**不**將遺失或未知的類別納入考量。將 unknown_value 或 encoded_missing_value 設定為整數,將會使獨特的整數碼數量各增加 1。這最多可能會產生 max_categories + 2 個整數碼。在以下範例中,「a」和「d」被視為不常出現,並被分組到單一類別中,「b」和「c」則有自己的類別,未知值編碼為 3,遺失值編碼為 4。
>>> X_train = np.array(
... [["a"] * 5 + ["b"] * 20 + ["c"] * 10 + ["d"] * 3 + [np.nan]],
... dtype=object).T
>>> enc = preprocessing.OrdinalEncoder(
... handle_unknown="use_encoded_value", unknown_value=3,
... max_categories=3, encoded_missing_value=4)
>>> _ = enc.fit(X_train)
>>> X_test = np.array([["a"], ["b"], ["c"], ["d"], ["e"], [np.nan]], dtype=object)
>>> enc.transform(X_test)
array([[2.],
[0.],
[1.],
[2.],
[3.],
[4.]])
類似地,OneHotEncoder 可以設定為將不常出現的類別分組在一起
>>> enc = preprocessing.OneHotEncoder(min_frequency=6, sparse_output=False).fit(X)
>>> enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
>>> enc.transform(np.array([['dog'], ['cat'], ['rabbit'], ['snake']]))
array([[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
將 handle_unknown 設定為 'infrequent_if_exist',未知的類別將被視為不常出現
>>> enc = preprocessing.OneHotEncoder(
... handle_unknown='infrequent_if_exist', sparse_output=False, min_frequency=6)
>>> enc = enc.fit(X)
>>> enc.transform(np.array([['dragon']]))
array([[0., 0., 1.]])
OneHotEncoder.get_feature_names_out 使用「infrequent」作為不常出現的特徵名稱
>>> enc.get_feature_names_out()
array(['x0_cat', 'x0_rabbit', 'x0_infrequent_sklearn'], dtype=object)
當 'handle_unknown' 設定為 'infrequent_if_exist' 且在轉換中遇到未知類別時
如果沒有設定不常出現的類別支援,或在訓練期間沒有不常出現的類別,則此特徵產生的獨熱編碼欄位將全為零。在反轉換中,未知類別將表示為
None。如果在訓練期間有不常出現的類別,則未知類別將被視為不常出現。在反轉換中,「infrequent_sklearn」將用於表示不常出現的類別。
也可以使用 max_categories 來設定不常出現的類別。在以下範例中,我們設定 max_categories=2 來限制輸出中的特徵數量。這會導致除了 'cat' 類別之外的所有類別都被視為不常出現,產生兩個特徵,一個用於 'cat',另一個用於不常出現的類別 - 即所有其他類別
>>> enc = preprocessing.OneHotEncoder(max_categories=2, sparse_output=False)
>>> enc = enc.fit(X)
>>> enc.transform([['dog'], ['cat'], ['rabbit'], ['snake']])
array([[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.]])
如果 max_categories 和 min_frequency 都為非預設值,則會先根據 min_frequency 來選擇類別,然後保留 max_categories 個類別。在以下範例中,min_frequency=4 會將只有 snake 視為不常出現,但 max_categories=3 會強制將 dog 也視為不常出現
>>> enc = preprocessing.OneHotEncoder(min_frequency=4, max_categories=3, sparse_output=False)
>>> enc = enc.fit(X)
>>> enc.transform([['dog'], ['cat'], ['rabbit'], ['snake']])
array([[0., 0., 1.],
[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
如果在 max_categories 的截止點有相同基數的不常出現類別,則會根據字典順序取前 max_categories 個類別。在以下範例中,「b」、「c」和「d」具有相同的基數,並且在 max_categories=2 的情況下,「b」和「c」因為具有較高的字典順序而屬於不常出現。
>>> X = np.asarray([["a"] * 20 + ["b"] * 10 + ["c"] * 10 + ["d"] * 10], dtype=object).T
>>> enc = preprocessing.OneHotEncoder(max_categories=3).fit(X)
>>> enc.infrequent_categories_
[array(['b', 'c'], dtype=object)]
6.3.4.2. 目標編碼器#
TargetEncoder 使用以類別特徵為條件的目標平均值來編碼無序的類別,即名義類別 [PAR] [MIC]。此編碼方案適用於具有高基數的類別特徵,其中獨熱編碼會膨脹特徵空間,使下游模型處理的成本更高。高基數類別的典型範例是基於位置的類別,例如郵遞區號或地區。
二元分類目標#
對於二元分類目標,目標編碼由以下公式給出
其中 \(S_i\) 是類別 \(i\) 的編碼,\(n_{iY}\) 是 \(Y=1\) 和類別 \(i\) 的觀察值數量,\(n_i\) 是類別 \(i\) 的觀察值數量,\(n_Y\) 是 \(Y=1\) 的觀察值數量,\(n\) 是觀察值數量,而 \(\lambda_i\) 是類別 \(i\) 的縮減因子。縮減因子由以下公式給出
其中 \(m\) 是一個平滑因子,可以使用 TargetEncoder 中的 smooth 參數來控制。較大的平滑因子會將更多權重放在全域平均值上。當 smooth="auto" 時,平滑因子會計算為經驗貝氏估計:\(m=\sigma_i^2/\tau^2\),其中 \(\sigma_i^2\) 是類別 \(i\) 中 y 的變異數,而 \(\tau^2\) 是 y 的全域變異數。
多類別分類目標#
對於多類別分類目標,公式與二元分類類似
其中 \(S_{ij}\) 是類別 \(i\) 和類別 \(j\) 的編碼,\(n_{iY_j}\) 是 \(Y=j\) 和類別 \(i\) 的觀察值數量,\(n_i\) 是類別 \(i\) 的觀察值數量,\(n_{Y_j}\) 是 \(Y=j\) 的觀察值數量,\(n\) 是觀察值數量,而 \(\lambda_i\) 是類別 \(i\) 的縮減因子。
連續目標值#
對於連續目標值,其公式與二元分類相似
其中 \(L_i\) 是類別為 \(i\) 的觀測值集合,而 \(n_i\) 是類別為 \(i\) 的觀測值數量。
fit_transform 內部依賴於交叉擬合方案,以防止目標資訊洩漏到訓練時的表示中,特別是對於無資訊的高基數類別變數,並有助於防止下游模型過度擬合虛假的相關性。請注意,因此,fit(X, y).transform(X) 不等於 fit_transform(X, y)。在 fit_transform 中,訓練資料會被分割成 k 個摺疊(由 cv 參數決定),並且每個摺疊都使用其他 k-1 個摺疊學習到的編碼進行編碼。以下圖表顯示了 fit_transform 中預設 cv=5 的交叉擬合方案

fit_transform 還使用整個訓練集學習「完整資料」編碼。這從未使用於 fit_transform 中,而是儲存到屬性 encodings_ 中,以便在呼叫 transform 時使用。請注意,在交叉擬合方案期間為每個摺疊學習的編碼不會儲存到屬性中。
fit 方法不使用任何交叉擬合方案,而是在整個訓練集上學習一個編碼,該編碼用於編碼 transform 中的類別。此編碼與在 fit_transform 中學習的「完整資料」編碼相同。
注意
TargetEncoder 將缺失值(例如 np.nan 或 None)視為另一個類別,並像其他任何類別一樣對其進行編碼。在 fit 期間未見到的類別會使用目標均值(即 target_mean_)進行編碼。
範例
參考文獻
6.3.5. 離散化#
離散化(也稱為量化或分箱)提供了一種將連續特徵分割為離散值的方法。具有連續特徵的某些資料集可能會受益於離散化,因為離散化可以將連續屬性的資料集轉換為僅具有名義屬性的資料集。
One-hot 編碼的離散化特徵可以使模型更具表現力,同時保持可解釋性。例如,使用離散器進行預處理可以為線性模型引入非線性。如需更進階的可能性,特別是平滑的可能性,請參閱下方產生多項式特徵。
6.3.5.1. K-bins 離散化#
KBinsDiscretizer 將特徵離散化為 k 個分箱
>>> X = np.array([[ -3., 5., 15 ],
... [ 0., 6., 14 ],
... [ 6., 3., 11 ]])
>>> est = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X)
預設情況下,輸出會進行 one-hot 編碼為稀疏矩陣(請參閱編碼類別特徵),並且可以使用 encode 參數進行配置。對於每個特徵,分箱邊緣會在 fit 期間計算,並且會與分箱數量一起定義間隔。因此,對於目前範例,這些間隔定義如下
特徵 1: \({[-\infty, -1), [-1, 2), [2, \infty)}\)
特徵 2: \({[-\infty, 5), [5, \infty)}\)
特徵 3: \({[-\infty, 14), [14, \infty)}\)
根據這些分箱間隔,X 會轉換如下
>>> est.transform(X)
array([[ 0., 1., 1.],
[ 1., 1., 1.],
[ 2., 0., 0.]])
產生的資料集包含序數屬性,可以在 Pipeline 中進一步使用。
離散化類似於為連續資料建構直方圖。但是,直方圖側重於計算落入特定分箱中的特徵,而離散化則側重於將特徵值分配給這些分箱。
KBinsDiscretizer 實作了不同的分箱策略,可以使用 strategy 參數進行選擇。「uniform」策略使用恆定寬度的分箱。「quantile」策略使用分位數值,使每個特徵中的分箱都均勻填充。「kmeans」策略根據對每個特徵獨立執行的 k-means 分群程序來定義分箱。
請注意,可以透過將定義離散化策略的可呼叫物件傳遞給 FunctionTransformer 來指定自訂分箱。例如,我們可以使用 Pandas 函式 pandas.cut
>>> import pandas as pd
>>> import numpy as np
>>> from sklearn import preprocessing
>>>
>>> bins = [0, 1, 13, 20, 60, np.inf]
>>> labels = ['infant', 'kid', 'teen', 'adult', 'senior citizen']
>>> transformer = preprocessing.FunctionTransformer(
... pd.cut, kw_args={'bins': bins, 'labels': labels, 'retbins': False}
... )
>>> X = np.array([0.2, 2, 15, 25, 97])
>>> transformer.fit_transform(X)
['infant', 'kid', 'teen', 'adult', 'senior citizen']
Categories (5, object): ['infant' < 'kid' < 'teen' < 'adult' < 'senior citizen']
範例
6.3.5.2. 特徵二元化#
特徵二元化是將數值特徵設定閾值以取得布林值的過程。這對於下游機率估計器很有用,該估計器假設輸入資料根據多變數伯努利分佈進行分佈。例如,BernoulliRBM 就是這種情況。
即使在實踐中,標準化的計數(又名詞頻)或 TF-IDF 值特徵通常表現得稍好,但在文字處理社群中,使用二元特徵值也很常見(可能是為了簡化機率推理)。
至於 Normalizer,實用類別 Binarizer 旨在用於 Pipeline 的早期階段。fit 方法不執行任何操作,因為每個範例都會獨立於其他範例進行處理
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer()
>>> binarizer.transform(X)
array([[1., 0., 1.],
[1., 0., 0.],
[0., 1., 0.]])
可以調整二元器的閾值
>>> binarizer = preprocessing.Binarizer(threshold=1.1)
>>> binarizer.transform(X)
array([[0., 0., 1.],
[1., 0., 0.],
[0., 0., 0.]])
至於 Normalizer 類別,預處理模組提供了一個配套函式 binarize,以便在不需要轉換器 API 時使用。
請注意,當 k = 2 且 bin 的邊界值位於 threshold 時,Binarizer 與 KBinsDiscretizer 相似。
6.3.6. 遺失值的填補#
關於填補遺失值的工具,請參考 遺失值的填補。
6.3.7. 產生多項式特徵#
通常,透過考慮輸入資料的非線性特徵來增加模型的複雜度是很有用的。我們展示了兩種基於多項式的可能性:第一種使用純粹的多項式,第二種使用樣條曲線,即分段多項式。
6.3.7.1. 多項式特徵#
一種簡單且常用的方法是使用多項式特徵,它可以取得特徵的高階項和交互作用項。它在 PolynomialFeatures 中實作。
>>> import numpy as np
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(2)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
X 的特徵已從 \((X_1, X_2)\) 轉換為 \((1, X_1, X_2, X_1^2, X_1X_2, X_2^2)\)。
在某些情況下,只需要特徵之間的交互作用項,可以使用設定 interaction_only=True 來取得。
>>> X = np.arange(9).reshape(3, 3)
>>> X
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> poly = PolynomialFeatures(degree=3, interaction_only=True)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 2., 0., 0., 2., 0.],
[ 1., 3., 4., 5., 12., 15., 20., 60.],
[ 1., 6., 7., 8., 42., 48., 56., 336.]])
X 的特徵已從 \((X_1, X_2, X_3)\) 轉換為 \((1, X_1, X_2, X_3, X_1X_2, X_1X_3, X_2X_3, X_1X_2X_3)\)。
請注意,當使用多項式 核函數 時,多項式特徵會隱式地用於核方法(例如,SVC、KernelPCA)。
請參閱 多項式和樣條曲線內插,了解如何使用建立的多項式特徵進行嶺迴歸。
6.3.7.2. 樣條轉換器#
另一種添加非線性項的方法,而不是使用特徵的純多項式,是使用 SplineTransformer 為每個特徵產生樣條基底函數。樣條是分段多項式,其參數為多項式的次數和節點的位置。SplineTransformer 實作了 B 樣條基底,請參閱下方的參考文獻。
注意
SplineTransformer 會單獨處理每個特徵,也就是說,它不會提供交互作用項。
樣條曲線相較於多項式的一些優點如下:
如果您保持固定的低次數(通常為 3)並謹慎地調整節點數量,B 樣條曲線非常靈活且穩健。多項式需要更高的次數,這會導致下一個重點。
B 樣條曲線在邊界處不像多項式那樣具有振盪行為(次數越高,情況越糟)。這被稱為 龍格現象。
B 樣條曲線為超出邊界(即超出擬合值範圍)的推斷提供了良好的選項。請查看選項
extrapolation。B 樣條曲線會產生具有帶狀結構的特徵矩陣。對於單個特徵,每行僅包含
degree + 1個非零元素,這些元素會連續出現,甚至為正數。這會產生一個具有良好數值特性的矩陣,例如,與多項式矩陣(稱為 范德蒙矩陣)形成鮮明對比的低條件數。低條件數對於線性模型的穩定演算法很重要。
以下程式碼片段顯示了樣條曲線的實際應用
>>> import numpy as np
>>> from sklearn.preprocessing import SplineTransformer
>>> X = np.arange(5).reshape(5, 1)
>>> X
array([[0],
[1],
[2],
[3],
[4]])
>>> spline = SplineTransformer(degree=2, n_knots=3)
>>> spline.fit_transform(X)
array([[0.5 , 0.5 , 0. , 0. ],
[0.125, 0.75 , 0.125, 0. ],
[0. , 0.5 , 0.5 , 0. ],
[0. , 0.125, 0.75 , 0.125],
[0. , 0. , 0.5 , 0.5 ]])
由於 X 已排序,因此可以輕鬆看到帶狀矩陣輸出。對於 degree=2,只有三個中間對角線是非零的。次數越高,樣條曲線的重疊就越多。
有趣的是,當 knots = strategy 時,degree=0 的 SplineTransformer 與 encode='onehot-dense' 且 n_bins = n_knots - 1 的 KBinsDiscretizer 相同。
範例
參考文獻#
Eilers, P., & Marx, B. (1996). 使用 B 樣條曲線和懲罰的彈性平滑。Statist. Sci. 11 (1996), no. 2, 89–121。
Perperoglou, A., Sauerbrei, W., Abrahamowicz, M. 等人 R 中樣條函數程序的評論。BMC Med Res Methodol 19, 46 (2019)。
6.3.8. 自訂轉換器#
通常,您會希望將現有的 Python 函數轉換為轉換器,以協助資料清理或處理。您可以使用 FunctionTransformer 從任意函數實作轉換器。例如,要建立一個在管道中應用對數轉換的轉換器,請執行以下操作:
>>> import numpy as np
>>> from sklearn.preprocessing import FunctionTransformer
>>> transformer = FunctionTransformer(np.log1p, validate=True)
>>> X = np.array([[0, 1], [2, 3]])
>>> # Since FunctionTransformer is no-op during fit, we can call transform directly
>>> transformer.transform(X)
array([[0. , 0.69314718],
[1.09861229, 1.38629436]])
您可以透過設定 check_inverse=True 並在 transform 之前呼叫 fit 來確保 func 和 inverse_func 彼此反向。請注意,會引發警告,並且可以使用 filterwarnings 將其轉換為錯誤
>>> import warnings
>>> warnings.filterwarnings("error", message=".*check_inverse*.",
... category=UserWarning, append=False)
如需示範如何使用 FunctionTransformer 從文字資料中提取特徵的完整程式碼範例,請參閱 具有異質資料來源的資料行轉換器 和 與時間相關的特徵工程。