4.1. 部分依賴圖和個別條件期望圖#
部分依賴圖 (Partial dependence plots, PDP) 和個別條件期望 (Individual conditional expectation, ICE) 圖可以用來視覺化和分析目標響應 [1] 和一組感興趣的輸入特徵之間的互動。
PDP [H2009] 和 ICE [G2015] 都假設感興趣的輸入特徵與其餘特徵獨立,但在實務中這個假設常常被違反。因此,在特徵相關的情況下,我們會建立荒謬的資料點來計算 PDP/ICE [M2019]。
4.1.1. 部分依賴圖#
部分依賴圖 (PDP) 顯示目標響應與一組感興趣的輸入特徵之間的依賴關係,並將所有其他輸入特徵(「互補」特徵)的值邊緣化。直觀上,我們可以將部分依賴性解釋為作為感興趣的輸入特徵的函數的預期目標響應。
由於人類感知的限制,感興趣的輸入特徵集的大小必須很小(通常是一個或兩個),因此感興趣的輸入特徵通常從最重要的特徵中選擇。
下圖顯示了腳踏車共享資料集的兩個單向和一個雙向部分依賴圖,使用的是 HistGradientBoostingRegressor
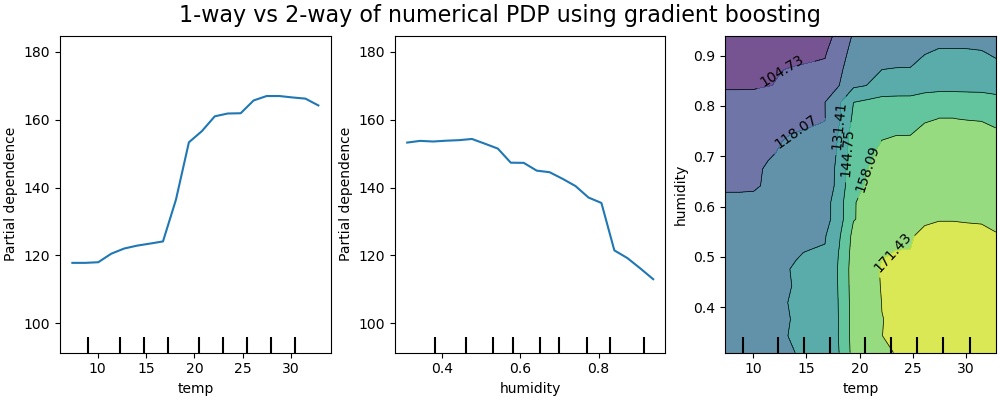
單向 PDP 告訴我們目標響應與感興趣的輸入特徵之間的互動(例如線性、非線性)。上圖中的左圖顯示了溫度對腳踏車租賃數量的影響;我們可以清楚地看到較高的溫度與較高的腳踏車租賃數量相關。同樣地,我們可以分析濕度對腳踏車租賃數量的影響(中間圖)。因此,這些解釋是邊緣化的,一次只考慮一個特徵。
具有兩個感興趣輸入特徵的 PDP 顯示了這兩個特徵之間的互動。例如,上圖中的雙變量 PDP 顯示了腳踏車租賃數量對溫度和濕度聯合值的依賴性。我們可以清楚地看到這兩個特徵之間的互動:當溫度高於攝氏 20 度時,主要濕度對腳踏車租賃數量有很大的影響。對於較低的溫度,溫度和濕度都會影響腳踏車租賃數量。
sklearn.inspection 模組提供了一個方便的函式 from_estimator 來建立單向和雙向部分依賴圖。在下面的範例中,我們展示如何建立部分依賴圖的網格:特徵 0 和 1 的兩個單向 PDP,以及這兩個特徵之間的雙向 PDP
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> from sklearn.inspection import PartialDependenceDisplay
>>> X, y = make_hastie_10_2(random_state=0)
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X, y)
>>> features = [0, 1, (0, 1)]
>>> PartialDependenceDisplay.from_estimator(clf, X, features)
<...>
您可以使用 plt.gcf() 和 plt.gca() 存取新建立的圖形和軸物件。
若要建立具有類別特徵的部分依賴圖,您需要使用參數 categorical_features 來指定哪些特徵是類別特徵。此參數接受類別特徵的索引、名稱或布林遮罩的列表。類別特徵的部分依賴圖的圖形表示是長條圖或二維熱圖。
多類別分類的 PDP#
對於多類別分類,您需要透過 target 引數設定應該為其建立 PDP 的類別標籤
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
>>> mc_clf = GradientBoostingClassifier(n_estimators=10,
... max_depth=1).fit(iris.data, iris.target)
>>> features = [3, 2, (3, 2)]
>>> PartialDependenceDisplay.from_estimator(mc_clf, X, features, target=0)
<...>
相同的參數 target 用於指定多輸出迴歸設定中的目標。
如果您需要部分依賴函數的原始值而不是圖表,您可以使用 sklearn.inspection.partial_dependence 函式
>>> from sklearn.inspection import partial_dependence
>>> results = partial_dependence(clf, X, [0])
>>> results["average"]
array([[ 2.466..., 2.466..., ...
>>> results["grid_values"]
[array([-1.624..., -1.592..., ...
應該評估部分依賴性的值直接從 X 產生。對於雙向部分依賴性,會產生值的二維網格。由 sklearn.inspection.partial_dependence 傳回的 values 欄位給出網格中每個感興趣的輸入特徵所使用的實際值。它們也對應於圖表的軸。
4.1.2. 個別條件期望 (ICE) 圖#
與 PDP 類似,個別條件期望 (ICE) 圖顯示目標函數與感興趣的輸入特徵之間的依賴關係。然而,與顯示輸入特徵平均效果的 PDP 不同,ICE 圖會視覺化每個樣本的預測對特徵的依賴性,每個樣本一條線。由於人類感知的限制,ICE 圖僅支援一個感興趣的輸入特徵。
下圖顯示了腳踏車共享資料集的兩個 ICE 圖,使用的是 HistGradientBoostingRegressor。這些圖將對應的 PD 線疊加在 ICE 線上。
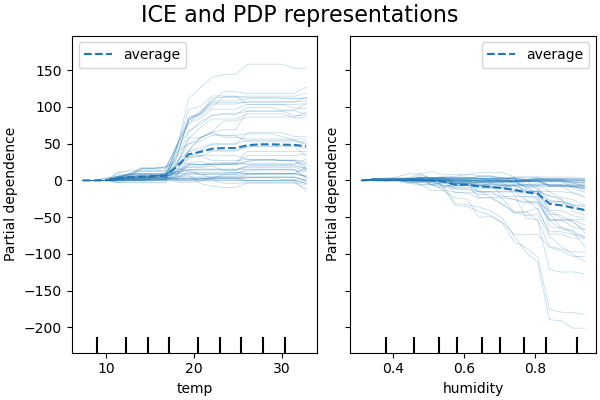
雖然 PDP 擅長顯示目標特徵的平均效果,但它們可能會模糊互動產生的異質關係。當存在互動時,ICE 圖將提供更多見解。例如,我們看到溫度特徵的 ICE 給了我們一些額外的資訊:一些 ICE 線是平坦的,而另一些則顯示溫度高於攝氏 35 度時依賴性會降低。我們觀察到濕度特徵的類似模式:當濕度高於 80% 時,一些 ICE 線會急劇下降。
sklearn.inspection 模組的 PartialDependenceDisplay.from_estimator 便利函式可以用於透過設定 kind='individual' 來建立 ICE 圖。在下面的範例中,我們展示如何建立 ICE 圖的網格
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> from sklearn.inspection import PartialDependenceDisplay
>>> X, y = make_hastie_10_2(random_state=0)
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X, y)
>>> features = [0, 1]
>>> PartialDependenceDisplay.from_estimator(clf, X, features,
... kind='individual')
<...>
在 ICE 圖中,可能不容易看到感興趣的輸入特徵的平均效果。因此,建議將 ICE 圖與 PDP 一起使用。它們可以使用 kind='both' 一起繪製。
>>> PartialDependenceDisplay.from_estimator(clf, X, features,
... kind='both')
<...>
如果 ICE 圖中有太多線條,可能難以看出個別樣本之間的差異,並解釋模型。將 ICE 圖的中心點設定在 x 軸上的第一個值,會產生中心化的個別條件期望 (cICE) 圖 [G2015]。這樣可以強調個別條件期望與平均線的差異,從而更容易探索異質關係。可以透過設定 centered=True 來繪製 cICE 圖。
>>> PartialDependenceDisplay.from_estimator(clf, X, features,
... kind='both', centered=True)
<...>
4.1.3. 數學定義#
令 \(X_S\) 為感興趣的輸入特徵集(即 features 參數),並令 \(X_C\) 為其補集。
在點 \(x_S\) 處,響應 \(f\) 的部分依賴定義為
其中 \(f(x_S, x_C)\) 是給定樣本的響應函數(predict、predict_proba 或 decision_function),該樣本的值由 \(X_S\) 中特徵的 \(x_S\) 定義,以及由 \(X_C\) 中特徵的 \(x_C\) 定義。請注意,\(x_S\) 和 \(x_C\) 可能是元組。
計算 \(x_S\) 的各種值的此積分會產生如上的 PDP 圖。ICE 線定義為在 \(x_{S}\) 處評估的單個 \(f(x_{S}, x_{C}^{(i)})\)。
4.1.4. 計算方法#
有兩種主要方法可以近似上述積分,分別是「brute」和「recursion」方法。method 參數控制要使用哪種方法。
「brute」方法是一種通用方法,適用於任何估計器。請注意,僅在「brute」方法中支援計算 ICE 圖。它透過計算 X 資料的平均值來近似上述積分
其中 \(x_C^{(i)}\) 是 \(X_C\) 中特徵的第 i 個樣本的值。對於每個 \(x_S\) 值,此方法都需要完整掃描資料集 X,這需要大量的計算。
每個 \(f(x_{S}, x_{C}^{(i)})\) 對應於在 \(x_{S}\) 處評估的一條 ICE 線。對 \(x_{S}\) 的多個值進行此計算,可獲得完整的 ICE 線。正如可以看到的,ICE 線的平均值對應於部分依賴線。
「recursion」方法比「brute」方法更快,但僅有某些基於樹的估計器支援使用此方法來繪製 PDP 圖。它的計算方式如下:對於給定點 \(x_S\),會執行加權樹遍歷:如果分割節點涉及感興趣的輸入特徵,則遵循相應的左分支或右分支;否則會遵循兩個分支,每個分支的權重是進入該分支的訓練樣本比例。最後,部分依賴由所有已訪問葉子值的加權平均值給出。
使用「brute」方法時,參數 X 同時用於產生值網格 \(x_S\) 和補充特徵值 \(x_C\)。但是,使用「recursion」方法時,X 僅用於網格值:隱含地,\(x_C\) 值是訓練資料的值。
預設情況下,對於支援繪製 PDP 圖的基於樹的估計器,會使用「recursion」方法,而對於其餘的則使用「brute」方法。
注意
雖然通常這兩種方法應該很接近,但在某些特定設定中它們可能會有所不同。「brute」方法假設存在資料點 \((x_S, x_C^{(i)})\)。當特徵相關時,此類人為樣本的機率質量可能非常低。「brute」和「recursion」方法可能會在部分依賴值方面有所不同,因為它們會以不同的方式處理這些不太可能的樣本。但是,請記住,解釋 PDP 的主要假設是特徵應該是獨立的。
範例
註腳
參考文獻