1.6. 最近鄰#
sklearn.neighbors 提供基於鄰居的無監督和監督學習方法的功能。無監督最近鄰是許多其他學習方法的基礎,尤其是流形學習和譜聚類。基於監督鄰居的學習有兩種形式:用於具有離散標籤的資料的分類和用於具有連續標籤的資料的迴歸。
最近鄰方法背後的原則是找到與新點距離最近的預定義數量的訓練樣本,並從這些樣本中預測標籤。樣本數量可以是使用者定義的常數(k-最近鄰學習),也可以根據點的局部密度而變化(基於半徑的鄰居學習)。距離通常可以是任何度量:最常見的選擇是標準歐幾里得距離。基於鄰居的方法被稱為非泛化機器學習方法,因為它們只是「記住」所有訓練資料(可能轉換為快速索引結構,例如Ball Tree或KD Tree)。
儘管它很簡單,但最近鄰在大量的分類和迴歸問題中都取得了成功,包括手寫數字和衛星影像場景。作為一種非參數方法,它通常在決策邊界非常不規則的分類情況下取得成功。
sklearn.neighbors 中的類別可以處理 NumPy 陣列或 scipy.sparse 矩陣作為輸入。對於密集矩陣,支援大量的可能距離度量。對於稀疏矩陣,支援用於搜尋的任意 Minkowski 度量。
有許多學習常式在其核心依賴最近鄰。一個範例是核密度估計,在密度估計章節中討論。
1.6.1. 無監督最近鄰#
NearestNeighbors 實現無監督的最近鄰學習。它作為三種不同最近鄰演算法的統一介面:BallTree、KDTree 和基於 sklearn.metrics.pairwise 中常式的暴力演算法。鄰居搜尋演算法的選擇透過關鍵字 'algorithm' 控制,該關鍵字必須是 ['auto', 'ball_tree', 'kd_tree', 'brute'] 之一。當傳遞預設值 'auto' 時,演算法會嘗試從訓練資料中確定最佳方法。有關每個選項的優缺點的討論,請參閱最近鄰演算法。
警告
關於最近鄰演算法,如果兩個鄰居 \(k+1\) 和 \(k\) 具有相同的距離但標籤不同,則結果將取決於訓練資料的順序。
1.6.1.1. 尋找最近鄰#
對於在兩組資料之間尋找最近鄰的簡單任務,可以使用 sklearn.neighbors 中的無監督演算法
>>> from sklearn.neighbors import NearestNeighbors
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
>>> distances, indices = nbrs.kneighbors(X)
>>> indices
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
>>> distances
array([[0. , 1. ],
[0. , 1. ],
[0. , 1.41421356],
[0. , 1. ],
[0. , 1. ],
[0. , 1.41421356]])
因為查詢集與訓練集匹配,所以每個點的最近鄰是點本身,距離為零。
也可以有效地產生一個稀疏圖,顯示相鄰點之間的連接
>>> nbrs.kneighbors_graph(X).toarray()
array([[1., 1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[0., 1., 1., 0., 0., 0.],
[0., 0., 0., 1., 1., 0.],
[0., 0., 0., 1., 1., 0.],
[0., 0., 0., 0., 1., 1.]])
資料集的結構使得索引順序中附近的點在參數空間中也附近,從而產生一個近似於 K-最近鄰的塊對角矩陣。這種稀疏圖在各種情況下都很有用,這些情況利用點之間的空間關係進行無監督學習:特別是,請參閱 Isomap、LocallyLinearEmbedding 和 SpectralClustering。
1.6.1.2. KDTree 和 BallTree 類別#
或者,可以直接使用 KDTree 或 BallTree 類別來尋找最近鄰。這是上面使用的 NearestNeighbors 類別封裝的功能。Ball Tree 和 KD Tree 具有相同的介面;我們將在這裡展示使用 KD Tree 的範例
>>> from sklearn.neighbors import KDTree
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> kdt = KDTree(X, leaf_size=30, metric='euclidean')
>>> kdt.query(X, k=2, return_distance=False)
array([[0, 1],
[1, 0],
[2, 1],
[3, 4],
[4, 3],
[5, 4]]...)
有關最近鄰搜尋可用選項的更多資訊,包括查詢策略、距離度量等的規範,請參閱 KDTree 和 BallTree 類別文件。有關有效度量的列表,請使用 KDTree.valid_metrics 和 BallTree.valid_metrics
>>> from sklearn.neighbors import KDTree, BallTree
>>> KDTree.valid_metrics
['euclidean', 'l2', 'minkowski', 'p', 'manhattan', 'cityblock', 'l1', 'chebyshev', 'infinity']
>>> BallTree.valid_metrics
['euclidean', 'l2', 'minkowski', 'p', 'manhattan', 'cityblock', 'l1', 'chebyshev', 'infinity', 'seuclidean', 'mahalanobis', 'hamming', 'canberra', 'braycurtis', 'jaccard', 'dice', 'rogerstanimoto', 'russellrao', 'sokalmichener', 'sokalsneath', 'haversine', 'pyfunc']
1.6.2. 最近鄰分類#
基於鄰居的分類是一種基於實例的學習或非泛化學習:它不嘗試建構一般的內部模型,而是簡單地儲存訓練資料的實例。分類是根據每個點的最近鄰的簡單多數投票來計算的:查詢點被分配到在該點的最近鄰中代表最多的資料類別。
scikit-learn 實現了兩種不同的最近鄰分類器:KNeighborsClassifier 實現基於每個查詢點的 \(k\) 個最近鄰的學習,其中 \(k\) 是使用者指定的整數值。RadiusNeighborsClassifier 實現基於每個訓練點的固定半徑 \(r\) 內鄰居數量的學習,其中 \(r\) 是使用者指定的浮點值。
KNeighborsClassifier 中的 \(k\)-鄰居分類是最常用的技術。值 \(k\) 的最佳選擇高度依賴於資料:通常,較大的 \(k\) 會抑制雜訊的影響,但會使分類邊界不太清晰。
在資料採樣不均勻的情況下,RadiusNeighborsClassifier 中基於半徑的鄰居分類可能是一個更好的選擇。使用者指定一個固定的半徑 \(r\),使得在較稀疏的鄰域中的點使用較少的最近鄰進行分類。對於高維參數空間,由於所謂的「維度詛咒」,此方法的效果會降低。
基本的最近鄰分類使用均勻權重:也就是說,分配給查詢點的值是根據最近鄰的簡單多數投票計算得出的。在某些情況下,最好對鄰居進行加權,使較近的鄰居對擬合的貢獻更大。這可以通過 weights 關鍵字來完成。預設值 weights = 'uniform' 會為每個鄰居分配均勻的權重。weights = 'distance' 會分配與查詢點距離成反比的權重。或者,可以提供使用者定義的距離函數來計算權重。
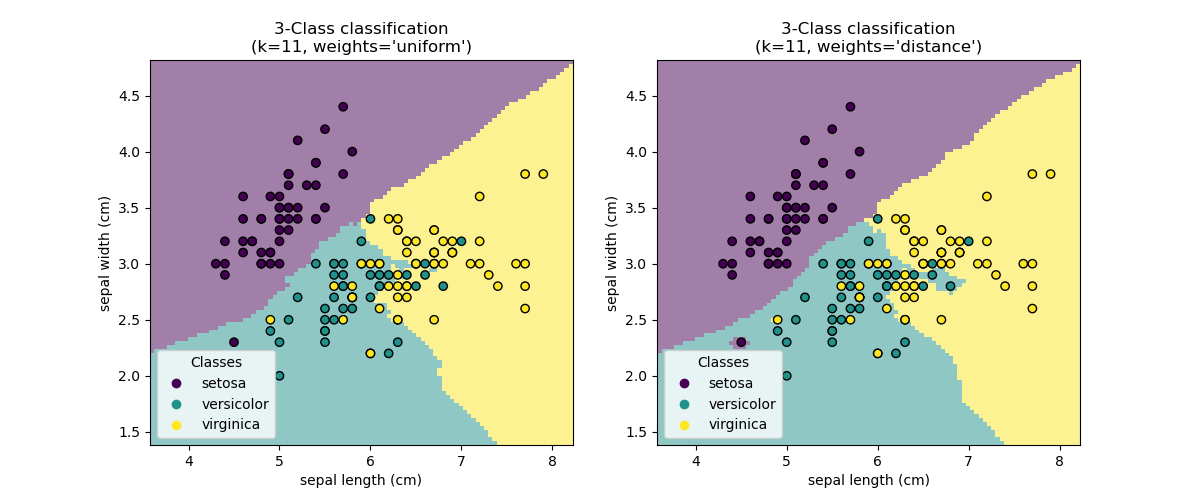
範例
最近鄰分類:一個使用最近鄰進行分類的範例。
1.6.3. 最近鄰迴歸#
基於鄰居的迴歸可用於資料標籤是連續變數而非離散變數的情況。分配給查詢點的標籤是根據其最近鄰的標籤的平均值計算得出的。
scikit-learn 實作了兩個不同的鄰居迴歸器:KNeighborsRegressor 實作了基於每個查詢點的 \(k\) 個最近鄰進行學習,其中 \(k\) 是使用者指定的整數值。RadiusNeighborsRegressor 實作了基於查詢點固定半徑 \(r\) 內的鄰居進行學習,其中 \(r\) 是使用者指定的浮點值。
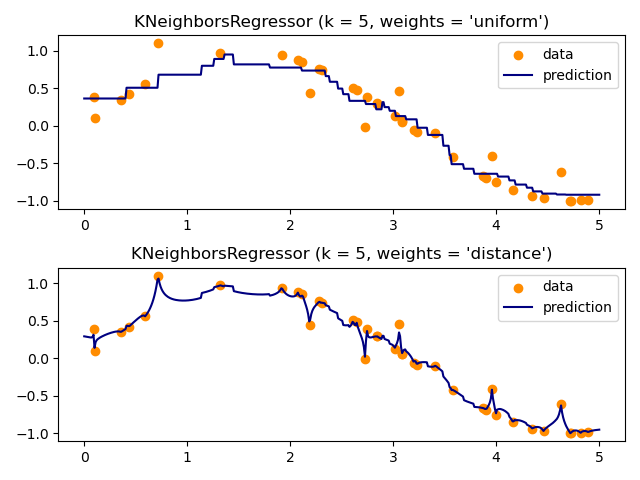
基本的最近鄰迴歸使用均勻權重:也就是說,局部鄰域中的每個點對查詢點的分類都做出均等的貢獻。在某些情況下,對點進行加權,使附近的點對迴歸的貢獻大於遠處的點可能是有利的。這可以通過 weights 關鍵字來完成。預設值 weights = 'uniform' 為所有點分配相等的權重。weights = 'distance' 會分配與查詢點距離成反比的權重。或者,可以提供使用者定義的距離函數,該函數將用於計算權重。
在使用多輸出估計器進行臉部補全中展示了使用多輸出最近鄰進行迴歸的應用。在此範例中,輸入 X 是臉部上半部的像素,輸出 Y 是臉部下半部的像素。

範例
最近鄰迴歸:一個使用最近鄰進行迴歸的範例。
使用多輸出估計器進行臉部補全:一個使用最近鄰進行多輸出迴歸的範例。
1.6.4. 最近鄰演算法#
1.6.4.1. 暴力搜尋法#
快速計算最近鄰是機器學習中一個活躍的研究領域。最簡單的鄰居搜尋實作涉及對資料集中所有點對之間的距離進行暴力計算:對於 \(D\) 維中的 \(N\) 個樣本,此方法的規模為 \(O[D N^2]\)。對於小型資料樣本,有效的暴力鄰居搜尋可能非常具有競爭力。但是,隨著樣本數量 \(N\) 的增長,暴力方法很快變得不可行。在 sklearn.neighbors 中的類別中,暴力鄰居搜尋使用關鍵字 algorithm = 'brute' 指定,並使用 sklearn.metrics.pairwise 中提供的常式進行計算。
1.6.4.2. K-D 樹#
為了解決暴力方法在計算效率上的問題,人們發明了各種基於樹的資料結構。總體而言,這些結構試圖通過有效地編碼樣本的聚合距離資訊來減少所需的距離計算次數。基本概念是,如果點 \(A\) 與點 \(B\) 非常遠,並且點 \(B\) 非常接近點 \(C\),那麼我們知道點 \(A\) 和 \(C\) 非常遠,而無需明確計算它們的距離。這樣,最近鄰搜尋的計算成本可以降低到 \(O[D N \log(N)]\) 或更好。對於較大的 \(N\),這比暴力方法有了顯著的改進。
早期利用這種聚合資訊的方法是 KD 樹 資料結構(K 維樹 的縮寫),它將二維的 四元樹 和三維的 八元樹 推廣到任意維數。KD 樹是一種二元樹結構,它沿資料軸遞迴地分割參數空間,將其劃分為巢狀正交區域,資料點被歸檔到這些區域中。KD 樹的建構速度非常快:由於分割僅沿資料軸執行,因此無需計算 \(D\) 維距離。一旦建構完成,查詢點的最近鄰就可以僅透過 \(O[\log(N)]\) 次距離計算來確定。儘管 KD 樹方法對於低維度 (\(D < 20\)) 的鄰居搜尋非常快,但隨著 \(D\) 變得非常大,它的效率會降低:這是所謂的「維度詛咒」的一種表現形式。在 scikit-learn 中,KD 樹鄰居搜尋使用關鍵字 algorithm = 'kd_tree' 指定,並使用類別 KDTree 進行計算。
參考文獻#
“用於關聯搜尋的多維二元搜尋樹”, Bentley, J.L., Communications of the ACM (1975)
1.6.4.3. 球樹#
為了解決 KD 樹在高維度上的效率問題,開發了 球樹 資料結構。KD 樹沿著笛卡爾軸分割資料,而球樹則在一系列巢狀超球體中分割資料。這使得樹的建構比 KD 樹更耗費成本,但會產生一種資料結構,即使在非常高的維度下,它也可以在高度結構化的資料上非常有效。
球樹將資料遞迴地劃分為由質心 \(C\) 和半徑 \(r\) 定義的節點,使得節點中的每個點都位於由 \(r\) 和 \(C\) 定義的超球體內。通過使用三角不等式 來減少鄰居搜尋的候選點數量
透過這種設定,只需計算測試點與質心之間的單一距離,即可確定節點內所有點距離的下限和上限。由於球樹節點的球形幾何結構,它在高維度上可以勝過 KD 樹,但實際效能高度取決於訓練資料的結構。在 scikit-learn 中,基於球樹的鄰近搜尋使用關鍵字 algorithm = 'ball_tree' 指定,並使用 BallTree 類別計算。或者,使用者可以直接使用 BallTree 類別。
參考文獻#
“Five Balltree Construction Algorithms”, Omohundro, S.M., International Computer Science Institute Technical Report (1989)
最近鄰演算法的選擇#
給定資料集的最佳演算法是一個複雜的選擇,取決於許多因素
樣本數 \(N\) (即
n_samples)和維度 \(D\) (即n_features)。暴力搜尋 的查詢時間會隨著 \(O[D N]\) 而增長
球樹 的查詢時間大約隨著 \(O[D \log(N)]\) 而增長
KD 樹 的查詢時間會隨著 \(D\) 而變化,難以精確描述。對於小的 \(D\) (小於 20 左右),成本大約為 \(O[D\log(N)]\),並且 KD 樹查詢可能非常有效率。對於較大的 \(D\),成本會增加到接近 \(O[DN]\),而樹狀結構所帶來的額外負荷可能會導致查詢速度比暴力搜尋慢。
對於小資料集(\(N\) 小於 30 左右),\(\log(N)\) 與 \(N\) 相當,暴力搜尋演算法可能比基於樹狀的方法更有效率。
KDTree和BallTree都透過提供一個 葉節點大小 參數來解決這個問題:這控制著查詢切換到暴力搜尋的樣本數量。這使得兩種演算法都能在小的 \(N\) 下接近暴力搜尋計算的效率。資料結構:資料的固有維度和/或資料的稀疏性。固有維度是指資料所在的流形的維度 \(d \le D\),它可以線性或非線性地嵌入到參數空間中。稀疏性是指資料填滿參數空間的程度(這與「稀疏」矩陣中使用的概念有所區別。資料矩陣可能沒有零項目,但 **結構** 在這種意義上仍然可以是「稀疏的」)。
暴力搜尋 的查詢時間不受資料結構影響。
球樹 和 KD 樹 的查詢時間會受到資料結構的極大影響。一般而言,具有較小固有維度的較稀疏資料會導致更快的查詢時間。由於 KD 樹的內部表示與參數軸對齊,因此對於任意結構的資料,它通常不會像球樹那樣顯示出那麼多的改進。
機器學習中使用的資料集往往結構非常良好,非常適合基於樹狀的查詢。
查詢點請求的鄰居數量 \(k\)。
暴力搜尋 的查詢時間在很大程度上不受 \(k\) 值影響
球樹 和 KD 樹 的查詢時間會隨著 \(k\) 的增加而變慢。這歸因於兩個影響:首先,較大的 \(k\) 會導致需要搜尋參數空間的較大區域。其次,使用 \(k > 1\) 需要在遍歷樹狀結構時對結果進行內部佇列。
當 \(k\) 相較於 \(N\) 變大時,基於樹狀查詢中修剪分支的能力會降低。在這種情況下,暴力搜尋查詢可能更有效率。
查詢點的數量。球樹和 KD 樹都需要一個建構階段。當攤銷到許多查詢時,此建構的成本可以忽略不計。但是,如果只執行少量查詢,則建構可能會佔總成本的很大一部分。如果只需要非常少的查詢點,則暴力搜尋比基於樹狀的方法更好。
目前,如果驗證了以下任何條件,algorithm = 'auto' 會選擇 'brute'
輸入資料是稀疏的
metric = 'precomputed'\(D > 15\)
\(k >= N/2\)
effective_metric_不在'kd_tree'或'ball_tree'的VALID_METRICS清單中
否則,它會從 'kd_tree' 和 'ball_tree' 中選擇第一個在 VALID_METRICS 清單中包含 effective_metric_ 的演算法。此啟發式方法基於以下假設
查詢點的數量至少與訓練點的數量相同
leaf_size接近其預設值30當 \(D > 15\) 時,資料的固有維度通常對於基於樹狀的方法來說太高了
leaf_size 的影響#
如上所述,對於小樣本量,暴力搜尋可能比基於樹狀的查詢更有效率。球樹和 KD 樹透過在葉節點內切換到暴力搜尋來解決這個問題。此切換的級別可以使用參數 leaf_size 來指定。此參數選擇有很多影響
- 建構時間
較大的
leaf_size會導致更快的樹建構時間,因為需要建立的節點更少- 查詢時間
較大或較小的
leaf_size都可能導致次佳的查詢成本。對於接近 1 的leaf_size,遍歷節點所涉及的額外負荷會顯著降低查詢速度。對於接近訓練集大小的leaf_size,查詢本質上變成了暴力搜尋。一個很好的折衷方案是leaf_size = 30,這是參數的預設值。- 記憶體
隨著
leaf_size的增加,儲存樹狀結構所需的記憶體會減少。這在球樹的情況下尤其重要,球樹會為每個節點儲存一個 \(D\) 維的質心。BallTree的所需儲存空間約為訓練集大小的1 / leaf_size倍。
暴力搜尋查詢不會參考 leaf_size。
最近鄰演算法的有效度量#
如需取得可用度量(metrics)的清單,請參閱 DistanceMetric 類別的文件,以及 sklearn.metrics.pairwise.PAIRWISE_DISTANCE_FUNCTIONS 中列出的度量。請注意,「cosine」度量使用 cosine_distances。
可以使用上述任何演算法的 valid_metric 屬性來取得有效的度量清單。例如,可以透過以下方式產生 KDTree 的有效度量:
>>> from sklearn.neighbors import KDTree
>>> print(sorted(KDTree.valid_metrics))
['chebyshev', 'cityblock', 'euclidean', 'infinity', 'l1', 'l2', 'manhattan', 'minkowski', 'p']
1.6.5. 最近質心分類器#
NearestCentroid 分類器是一種簡單的演算法,它以每個類別的成員的質心來表示每個類別。實際上,這使其類似於 KMeans 演算法的標籤更新階段。它也沒有參數可選擇,使其成為一個良好的基準分類器。然而,當類別為非凸形時,以及當類別具有顯著不同的變異數時,它會受到影響,因為它假設所有維度中的變異數相等。有關不作此假設的更複雜方法,請參閱線性判別分析 (LinearDiscriminantAnalysis) 和二次判別分析 (QuadraticDiscriminantAnalysis)。使用預設的 NearestCentroid 非常簡單
>>> from sklearn.neighbors import NearestCentroid
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> y = np.array([1, 1, 1, 2, 2, 2])
>>> clf = NearestCentroid()
>>> clf.fit(X, y)
NearestCentroid()
>>> print(clf.predict([[-0.8, -1]]))
[1]
1.6.5.1. 最近收縮質心#
NearestCentroid 分類器有一個 shrink_threshold 參數,它實作最近收縮質心分類器。實際上,每個質心的每個特徵值都除以該特徵的類內變異數。然後,特徵值會減少 shrink_threshold。最值得注意的是,如果特定特徵值跨越零,則會將其設定為零。實際上,這會從影響分類中移除該特徵。例如,這對於移除雜訊特徵很有用。
在下面的範例中,使用較小的收縮閾值將模型的準確度從 0.81 提高到 0.82。
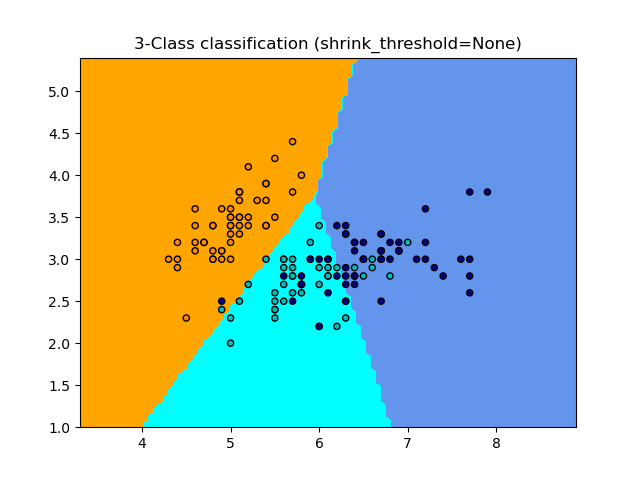
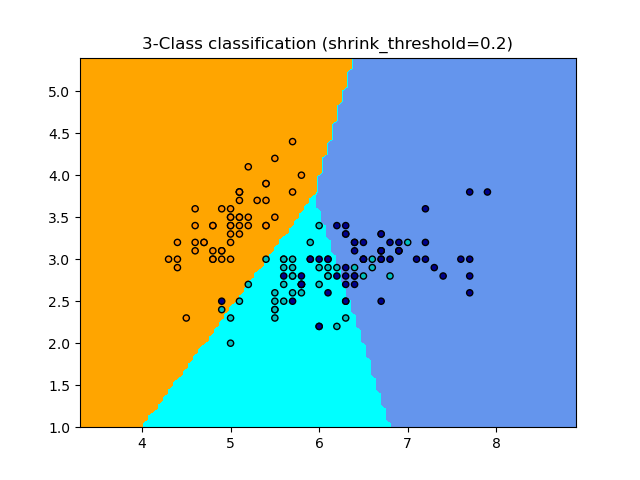
範例
最近質心分類:使用不同收縮閾值的最近質心進行分類的範例。
1.6.6. 最近鄰轉換器#
許多 scikit-learn 估算器依賴於最近鄰:一些分類器和迴歸器,例如 KNeighborsClassifier 和 KNeighborsRegressor,還有一些群集方法,例如 DBSCAN 和 SpectralClustering,以及一些流形嵌入,例如 TSNE 和 Isomap。
所有這些估算器都可以在內部計算最近鄰,但它們中的大多數也接受預先計算的最近鄰 稀疏圖,如 kneighbors_graph 和 radius_neighbors_graph 所提供。在模式 mode='connectivity' 下,這些函式會傳回二元鄰接稀疏圖,例如在 SpectralClustering 中所要求的。而在 mode='distance' 下,它們會傳回距離稀疏圖,例如在 DBSCAN 中所要求的。若要在 scikit-learn 管線中包含這些函式,也可以使用相應的類別 KNeighborsTransformer 和 RadiusNeighborsTransformer。這種稀疏圖 API 的優點有很多。
首先,預先計算的圖可以多次重複使用,例如在變更估算器的參數時。這可以由使用者手動完成,也可以使用 scikit-learn 管線的快取屬性完成
>>> import tempfile
>>> from sklearn.manifold import Isomap
>>> from sklearn.neighbors import KNeighborsTransformer
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.datasets import make_regression
>>> cache_path = tempfile.gettempdir() # we use a temporary folder here
>>> X, _ = make_regression(n_samples=50, n_features=25, random_state=0)
>>> estimator = make_pipeline(
... KNeighborsTransformer(mode='distance'),
... Isomap(n_components=3, metric='precomputed'),
... memory=cache_path)
>>> X_embedded = estimator.fit_transform(X)
>>> X_embedded.shape
(50, 3)
其次,預先計算圖可以更精細地控制最近鄰估計,例如透過參數 n_jobs 啟用多處理,這可能並非在所有估算器中都可用。
最後,預先計算可以由自訂估算器執行,以使用不同的實作,例如近似最近鄰方法或具有特殊資料類型的實作。預先計算的鄰居 稀疏圖 需要按照 radius_neighbors_graph 輸出中的格式設定
一個 CSR 矩陣(儘管會接受 COO、CSC 或 LIL)。
僅顯式儲存每個樣本相對於訓練資料的最近鄰居。這應包括與查詢點距離為 0 的鄰居,包括在計算訓練資料本身之間的最近鄰居時的矩陣對角線。
每行的
data應按遞增順序儲存距離(可選。未排序的資料將會穩定排序,增加計算負擔)。資料中的所有值都應為非負數。
任何列中都不應有重複的
indices(請參閱 scipy/scipy#5807)。如果傳遞預先計算矩陣的演算法使用 k 個最近鄰居(而不是半徑鄰域),則每列中必須儲存至少 k 個鄰居(或 k+1,如下面註釋中所述)。
注意
當查詢特定數量的鄰居時(使用 KNeighborsTransformer),n_neighbors 的定義是模糊的,因為它可以將每個訓練點包含為它自己的鄰居,或排除它們。這兩個選擇都不完美,因為包含它們會導致訓練和測試期間的非自身鄰居數量不同,而排除它們會導致 fit(X).transform(X) 和 fit_transform(X) 之間存在差異,這與 scikit-learn API 相悖。在 KNeighborsTransformer 中,我們使用將每個訓練點包含為自身鄰居的 n_neighbors 計數的定義。然而,為了與使用其他定義的其他估算器相容,當 mode == 'distance' 時,將會計算一個額外的鄰居。為了最大限度地與所有估算器相容,一個安全的選擇是在自訂最近鄰估算器中始終包含一個額外的鄰居,因為不必要的鄰居將被後續的估算器篩選掉。
範例
TSNE 中的近似最近鄰:使用管線
KNeighborsTransformer和TSNE的範例。也提出了兩個基於外部套件的自訂最近鄰估算器。快取最近鄰:一個使用管道 (pipelining)
KNeighborsTransformer和KNeighborsClassifier的範例,以在超參數網格搜尋期間啟用鄰居圖的快取。
1.6.7. 鄰域成分分析#
鄰域成分分析 (Neighborhood Components Analysis, NCA, NeighborhoodComponentsAnalysis) 是一種距離度量學習演算法,旨在提高最近鄰分類的準確性,相較於標準歐幾里得距離。該演算法直接最大化在訓練集上的留一法 k 最近鄰 (KNN) 分數的隨機變體。它還可以學習數據的低維線性投影,可用於數據視覺化和快速分類。
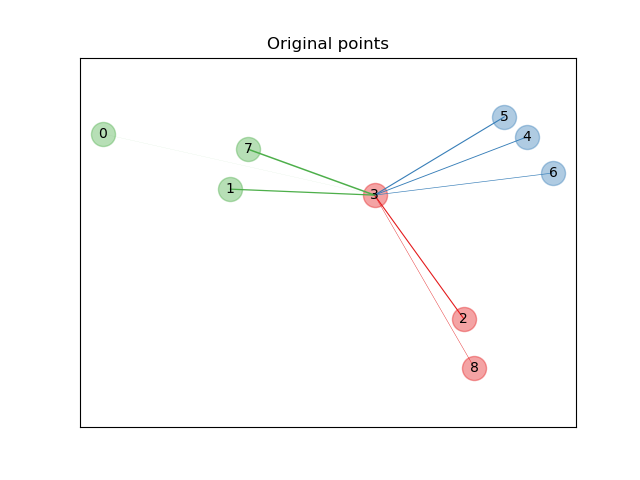
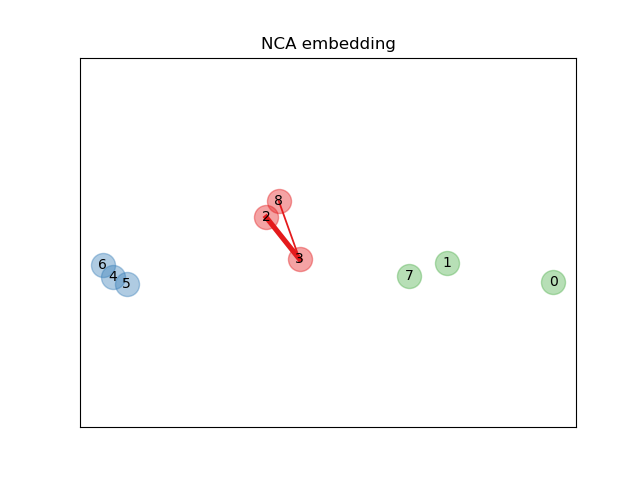
在上面的說明圖中,我們考慮來自隨機生成數據集的一些點。我們著重於點 3 的隨機 KNN 分類。樣本 3 和另一個點之間的連結粗細與它們之間的距離成正比,並且可以看作是隨機最近鄰預測規則將分配給該點的相對權重(或機率)。在原始空間中,樣本 3 有許多來自不同類別的隨機鄰居,因此正確的類別不太可能。但是,在 NCA 學習的投影空間中,唯一具有不可忽略權重的隨機鄰居與樣本 3 屬於同一類別,從而保證後者將被正確分類。有關更多詳細資訊,請參閱數學公式。
1.6.7.1. 分類#
與最近鄰分類器 (KNeighborsClassifier) 結合使用時,NCA 對於分類很有吸引力,因為它可以自然地處理多類別問題,而不會增加模型大小,並且不會引入需要用戶微調的額外參數。
NCA 分類已證明在實務中適用於各種大小和難度的數據集。與線性判別分析等相關方法相反,NCA 不會對類別分佈做出任何假設。最近鄰分類可以自然地產生高度不規則的決策邊界。
要使用此模型進行分類,需要將一個學習最佳轉換的 NeighborhoodComponentsAnalysis 實例與在投影空間中執行分類的 KNeighborsClassifier 實例結合。這是一個使用兩個類別的範例
>>> from sklearn.neighbors import (NeighborhoodComponentsAnalysis,
... KNeighborsClassifier)
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.pipeline import Pipeline
>>> X, y = load_iris(return_X_y=True)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y,
... stratify=y, test_size=0.7, random_state=42)
>>> nca = NeighborhoodComponentsAnalysis(random_state=42)
>>> knn = KNeighborsClassifier(n_neighbors=3)
>>> nca_pipe = Pipeline([('nca', nca), ('knn', knn)])
>>> nca_pipe.fit(X_train, y_train)
Pipeline(...)
>>> print(nca_pipe.score(X_test, y_test))
0.96190476...
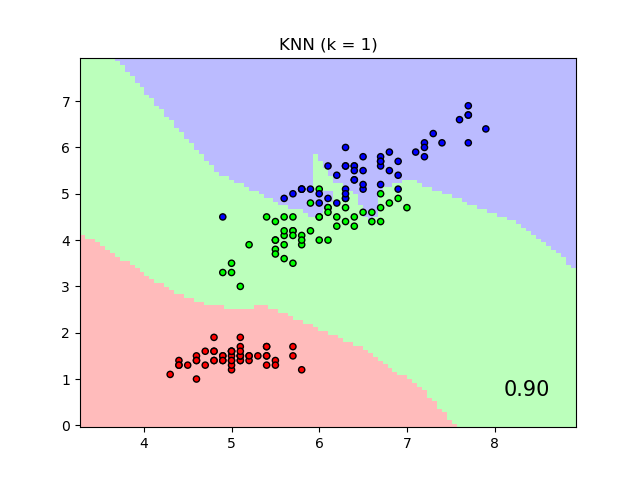
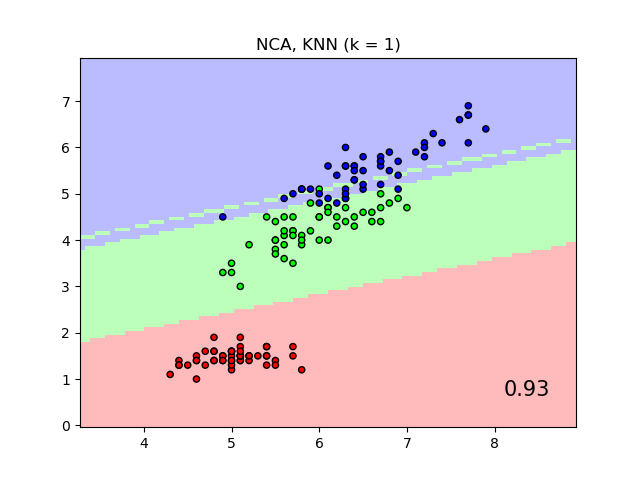
該圖顯示了在鳶尾花數據集上使用最近鄰分類和鄰域成分分析分類的決策邊界,為了視覺化目的,僅在兩個特徵上進行訓練和評分。
1.6.7.2. 降維#
NCA 可用於執行監督式降維。輸入數據會投影到一個線性子空間,該子空間包含最小化 NCA 目標的方向。可以使用參數 n_components 設定所需的維度。例如,下圖顯示了在 Digits 數據集上,使用主成分分析 (PCA)、線性判別分析 (LinearDiscriminantAnalysis) 和鄰域成分分析 (NeighborhoodComponentsAnalysis) 進行降維的比較。Digits 數據集的大小為 \(n_{samples} = 1797\) 和 \(n_{features} = 64\)。該數據集分為大小相等的訓練集和測試集,然後進行標準化。為了進行評估,在每種方法找到的 2 維投影點上計算 3 最近鄰分類準確度。每個數據樣本屬於 10 個類別之一。
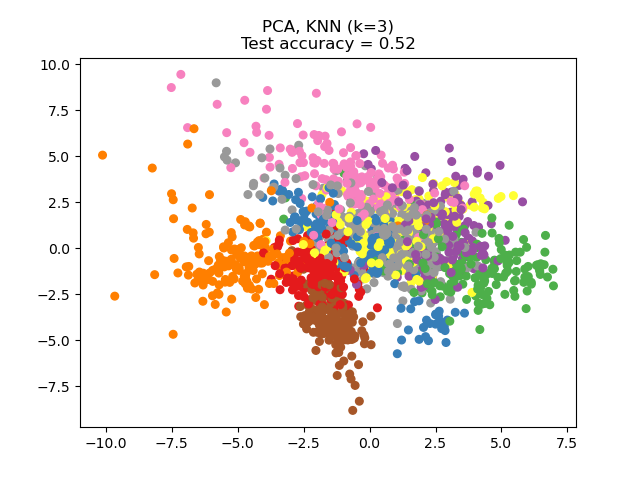
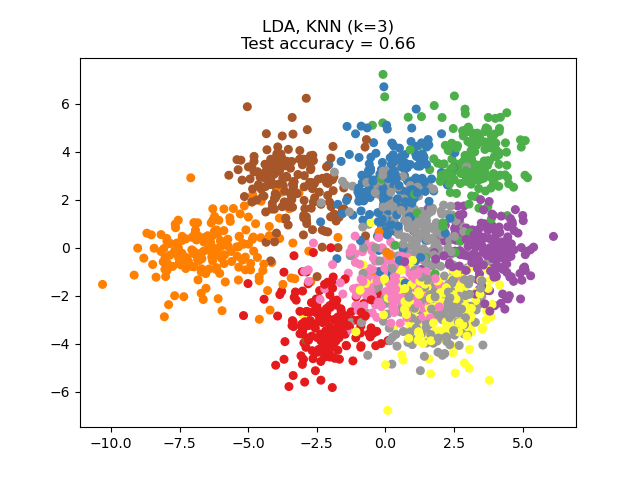
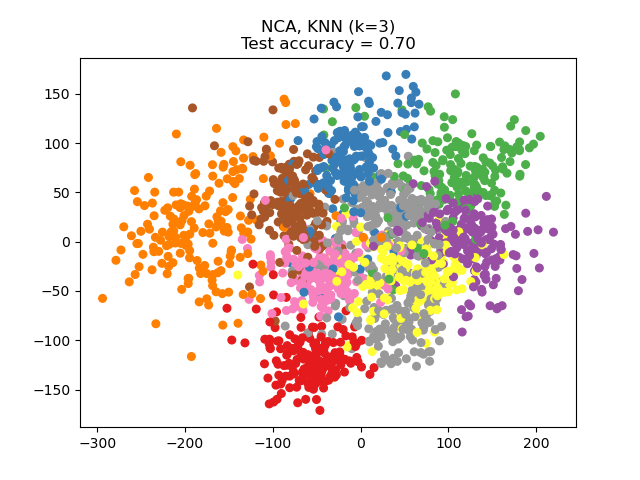
範例
1.6.7.3. 數學公式#
NCA 的目標是學習大小為 (n_components, n_features) 的最佳線性轉換矩陣,該矩陣最大化所有樣本 \(i\) 的機率 \(p_i\) 的總和,即 \(i\) 被正確分類,即
其中 \(N\) = n_samples,而 \(p_i\) 是樣本 \(i\) 根據學習嵌入空間中的隨機最近鄰規則被正確分類的機率
其中 \(C_i\) 是與樣本 \(i\) 屬於同一類別的點的集合,而 \(p_{i j}\) 是嵌入空間中歐幾里得距離的 softmax
馬氏距離#
NCA 可以看作是學習(平方)馬氏距離度量
其中 \(M = L^T L\) 是大小為 (n_features, n_features) 的對稱正半定矩陣。
1.6.7.4. 實作#
此實作遵循原始論文 [1] 中解釋的內容。對於最佳化方法,目前使用 scipy 的 L-BFGS-B,並在每次迭代時進行完整梯度計算,以避免調整學習率並提供穩定的學習。
有關更多資訊,請參閱下面的範例和 NeighborhoodComponentsAnalysis.fit 的 docstring。
1.6.7.5. 複雜度#
1.6.7.5.1. 訓練#
NCA 儲存成對距離矩陣,佔用 n_samples ** 2 的記憶體。時間複雜度取決於最佳化演算法執行的迭代次數。但是,可以使用參數 max_iter 設定最大迭代次數。對於每次迭代,時間複雜度為 O(n_components x n_samples x min(n_samples, n_features))。
1.6.7.5.2. 轉換#
此處的 transform 操作返回 \(LX^T\),因此其時間複雜度等於 n_components * n_features * n_samples_test。此操作沒有額外的空間複雜度。
參考文獻