6.7. 核函數近似#
此子模組包含近似於某些核函數的特徵映射的函數,例如在支援向量機中使用(請參閱支持向量機)。以下特徵函數執行輸入的非線性轉換,可以作為線性分類或其他演算法的基礎。
相較於核技巧(隱式使用特徵映射),使用近似顯式特徵映射的優點在於,顯式映射更適合線上學習,並且可以顯著降低使用非常大的資料集進行學習的成本。標準的核化支援向量機不適合擴展到大型資料集,但是使用近似核映射可以使用更有效率的線性支援向量機。特別是,將核映射近似與SGDClassifier結合使用可以使大型資料集上的非線性學習成為可能。
由於使用近似嵌入的經驗工作不多,因此建議在可能的情況下將結果與精確的核方法進行比較。
另請參閱
多項式迴歸:使用基底函數擴展線性模型,以獲得精確的多項式轉換。
6.7.1. 核函數近似的 Nystroem 方法#
Nystroem 中實作的 Nystroem 方法是一種用於降低核函數秩近似的通用方法。它透過在評估核函數的資料上,不重複地對列/欄進行子取樣來實現此目的。儘管精確方法的計算複雜度為 \(\mathcal{O}(n^3_{\text{samples}})\),但近似的複雜度為 \(\mathcal{O}(n^2_{\text{components}} \cdot n_{\text{samples}})\),其中可以設定 \(n_{\text{components}} \ll n_{\text{samples}}\) 而不會顯著降低效能 [WS2001]。
我們可以根據資料的特徵建構核矩陣 \(K\) 的特徵分解,然後將其分為取樣和未取樣的資料點。
其中
\(U\) 是正交的
\(\Lambda\) 是特徵值的對角矩陣
\(U_1\) 是所選取樣的正交矩陣
\(U_2\) 是未選取樣的正交矩陣
假設可以透過矩陣 \(K_{11}\) 的正交化獲得 \(U_1 \Lambda U_1^T\),並且可以評估 \(U_2 \Lambda U_1^T\)(及其轉置),則唯一剩餘要闡明的項是 \(U_2 \Lambda U_2^T\)。為此,我們可以根據已經評估的矩陣來表示它
在 fit 期間,類別 Nystroem 會評估基底 \(U_1\),並計算歸一化常數 \(K_{11}^{-\frac12}\)。稍後,在 transform 期間,會確定基底(由 components_ 屬性給定)和新資料點 X 之間的核矩陣。然後將此矩陣乘以 normalization_ 矩陣以獲得最終結果。
預設情況下,Nystroem 使用 rbf 核函數,但它可以使用任何核函數或預先計算的核矩陣。使用的取樣數量(也是計算特徵的維度)由參數 n_components 給定。
範例
6.7.2. 徑向基底函數核函數#
RBFSampler 構建徑向基底函數核函數的近似映射,也稱為隨機廚房水槽 [RR2007]。此轉換可用於在套用線性演算法(例如線性支援向量機)之前,明確地對核映射進行建模。
>>> from sklearn.kernel_approximation import RBFSampler
>>> from sklearn.linear_model import SGDClassifier
>>> X = [[0, 0], [1, 1], [1, 0], [0, 1]]
>>> y = [0, 0, 1, 1]
>>> rbf_feature = RBFSampler(gamma=1, random_state=1)
>>> X_features = rbf_feature.fit_transform(X)
>>> clf = SGDClassifier(max_iter=5)
>>> clf.fit(X_features, y)
SGDClassifier(max_iter=5)
>>> clf.score(X_features, y)
1.0
此映射依賴於核值的蒙地卡羅近似。fit 函數執行蒙地卡羅取樣,而 transform 方法執行資料的映射。由於該過程固有的隨機性,因此在不同的 fit 函數呼叫之間,結果可能會有所不同。
fit 函數採用兩個引數:n_components,它是特徵轉換的目標維度;以及 gamma,即 RBF 核函數的參數。較高的 n_components 將產生更好的核函數近似,並產生與核函數支援向量機產生的結果更相似的結果。請注意,「擬合」特徵函數實際上並不取決於提供給 fit 函數的資料。僅使用資料的維度。有關該方法的詳細資訊,請參閱 [RR2007]。
對於給定的 n_components 值,RBFSampler 通常不如 Nystroem 準確。RBFSampler 的計算成本較低,因此可以更有效率地使用更大的特徵空間。
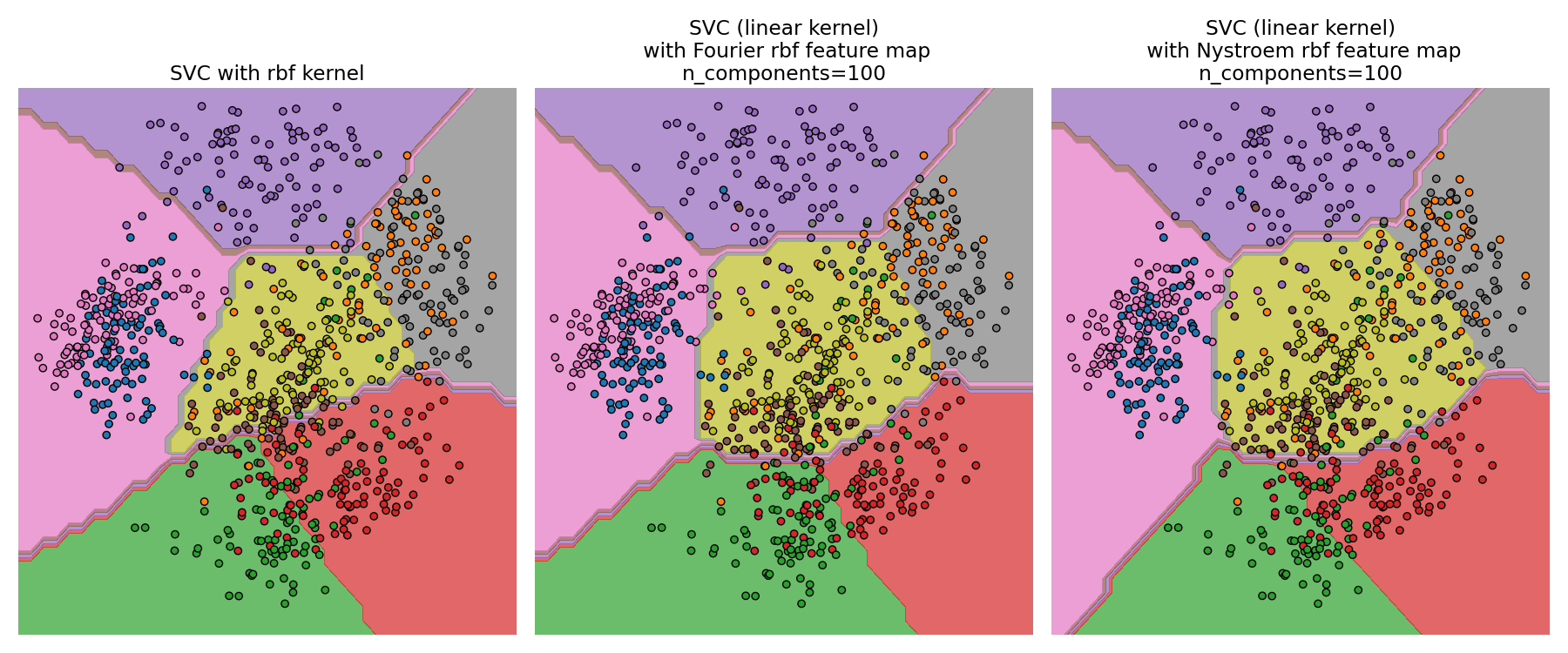
比較精確的 RBF 核函數(左)與近似值(右)#
範例
6.7.3. 加性卡方核函數#
加性卡方核函數是一種用於直方圖的核函數,常用於電腦視覺。
此處使用的加性卡方核函數由下式給出
這與 sklearn.metrics.pairwise.additive_chi2_kernel 並不完全相同。[VZ2010] 的作者偏好上述版本,因為它始終是正定的。由於此核函數是加性的,因此可以單獨處理所有分量 \(x_i\) 以進行嵌入。這使得可以按規律間隔採樣傅立葉變換,而不是使用蒙特卡羅採樣進行近似。
類別 AdditiveChi2Sampler 實現了這種分量式的確定性採樣。每個分量被採樣 \(n\) 次,每個輸入維度產生 \(2n+1\) 個維度(乘以 2 源於傅立葉變換的實部和虛部)。在文獻中,\(n\) 通常選擇為 1 或 2,將資料集轉換為大小 n_samples * 5 * n_features(在 \(n=2\) 的情況下)。
AdditiveChi2Sampler 提供的近似特徵映射可以與 RBFSampler 提供的近似特徵映射結合,以產生指數卡方核函數的近似特徵映射。有關詳細資訊,請參閱 [VZ2010],以及與 RBFSampler 結合的相關內容,請參閱 [VVZ2010]。
6.7.4. 偏斜卡方核函數#
偏斜卡方核函數由下式給出
它具有與電腦視覺中常用的指數卡方核函數相似的屬性,但允許對特徵映射進行簡單的蒙特卡羅近似。
SkewedChi2Sampler 的用法與上面針對 RBFSampler 所述的用法相同。唯一的區別在於稱為 \(c\) 的自由參數。有關此映射的動機和數學細節,請參閱 [LS2010]。
6.7.5. 透過張量草圖的 polynomial 核函數近似#
polynomial 核函數 是一種流行的核函數類型,由下式給出
其中
x、y是輸入向量d是核函數的次數
直觀地說,次數為 d 的 polynomial 核函數的特徵空間由輸入特徵之間所有可能的 d 次乘積組成,這使得使用此核函數的學習演算法能夠考慮特徵之間的交互作用。
TensorSketch [PP2013] 方法(如在 PolynomialCountSketch 中實作的)是一種可擴展的、獨立於輸入資料的 polynomial 核函數近似方法。它基於 Count sketch [WIKICS] [CCF2002] 的概念,這是一種類似於特徵雜湊的降維技術,但它使用多個獨立的雜湊函數。TensorSketch 獲取兩個向量(或一個向量與自身)的外積的 Count Sketch,可用作 polynomial 核函數特徵空間的近似值。特別是,TensorSketch 不是顯式計算外積,而是計算向量的 Count Sketch,然後使用透過快速傅立葉變換進行的 polynomial 乘法來計算其外積的 Count Sketch。
方便的是,TensorSketch 的訓練階段僅包括初始化一些隨機變數。因此,它獨立於輸入資料,即它僅取決於輸入特徵的數量,而不取決於資料值。此外,此方法可以在 \(\mathcal{O}(n_{\text{samples}}(n_{\text{features}} + n_{\text{components}} \log(n_{\text{components}})))\) 時間內轉換樣本,其中 \(n_{\text{components}}\) 是所需的輸出維度,由 n_components 決定。
範例
6.7.6. 數學細節#
諸如支援向量機或核化 PCA 之類的核方法依賴於再生核希爾伯特空間的屬性。對於任何正定核函數 \(k\)(所謂的 Mercer 核函數),可以保證存在一個到希爾伯特空間 \(\mathcal{H}\) 的映射 \(\phi\),使得
其中 \(\langle \cdot, \cdot \rangle\) 表示希爾伯特空間中的內積。
如果諸如線性支援向量機或 PCA 之類的演算法僅依賴於資料點 \(x_i\) 的純量積,則可以使用 \(k(x_i, x_j)\) 的值,這相當於將演算法應用於映射的資料點 \(\phi(x_i)\)。使用 \(k\) 的優點是從來不需要顯式計算映射 \(\phi\),這允許任意大的特徵(甚至是無限的)。
核方法的一個缺點是,在最佳化過程中可能需要儲存許多核函數值 \(k(x_i, x_j)\)。如果將核化分類器應用於新資料 \(y_j\),則需要計算 \(k(x_i, y_j)\) 來進行預測,這可能會對訓練集中的許多不同的 \(x_i\) 進行計算。
此子模組中的類別允許近似嵌入 \(\phi\),從而顯式使用表示 \(\phi(x_i)\),這避免了應用核函數或儲存訓練範例的需要。
參考文獻
“使用 Nyström 方法加速核機器” Williams, C.K.I.; Seeger, M. - 2001.
“偏斜乘法直方圖核函數的隨機傅立葉近似” Li, F.、Ionescu, C. 和 Sminchisescu, C. - 模式識別,DAGM 2010,電腦科學講義。
“用於高效檢測的廣義 RBF 特徵映射” Vempati, S. 和 Vedaldi, A. 和 Zisserman, A. 和 Jawahar, CV - 2010
“透過顯式特徵映射實現快速且可擴展的 polynomial 核函數” Pham, N., & Pagh, R. - 2013
“在資料流中尋找頻繁項目” Charikar, M.、Chen, K. 和 Farach-Colton - 2002