2.1. 高斯混合模型#
sklearn.mixture 是一個套件,可讓您學習高斯混合模型(支援對角、球形、綁定和完整共變異數矩陣)、對其進行採樣,並從資料中估計它們。 還提供了幫助確定適當組件數的工具。
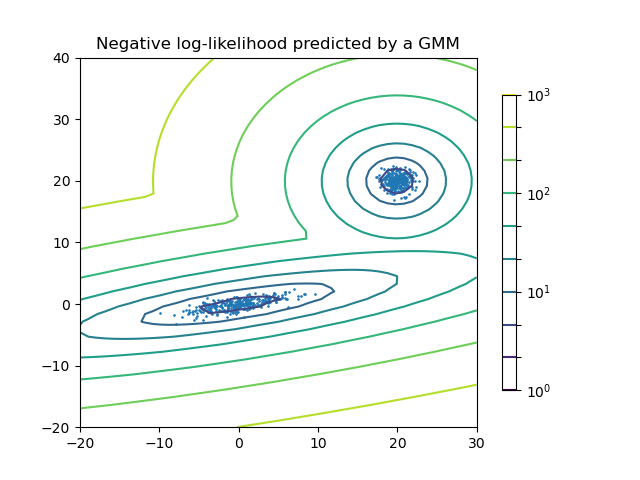
雙組件高斯混合模型:資料點和模型的等機率曲面。#
高斯混合模型是一種機率模型,它假設所有資料點都是由有限數量的具有未知參數的高斯分布的混合生成的。 可以將混合模型視為將 k-means 分群推廣到包含有關資料的共變異數結構以及潛在高斯的中心資訊。
Scikit-learn 實作了不同的類別來估計高斯混合模型,這些類別對應於不同的估計策略,詳述如下。
2.1.1. 高斯混合#
GaussianMixture 物件實作了用於擬合高斯混合模型的期望最大化 (EM) 演算法。 它還可以繪製多變數模型的信賴橢圓,並計算貝氏資訊準則以評估資料中的群集數。 提供了一個 GaussianMixture.fit 方法,該方法從訓練資料中學習高斯混合模型。 給定測試資料,它可以使用 GaussianMixture.predict 方法將每個樣本指定給它最有可能屬於的高斯分布。
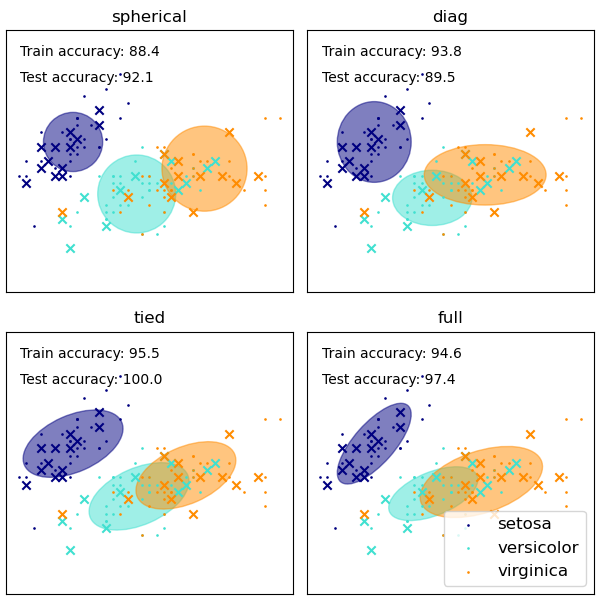
GaussianMixture 提供了不同的選項來約束估計的不同類別的共變異數:球形、對角、綁定或完整共變異數。
範例
GaussianMixture 類的優缺點#
優點
- 速度:
它是學習混合模型的最快演算法
- 不可知:
由於此演算法僅最大化可能性,因此它不會將均值偏向零,也不會將群集大小偏向具有可能適用或不適用的特定結構。
缺點
- 奇異性:
當每個混合的點數不足時,估計共變異數矩陣會變得困難,並且已知演算法會發散並找到具有無限可能性的解,除非對共變異數進行人工正規化。
- 組件數:
此演算法將始終使用它有權存取的所有組件,需要保留資料或資訊理論標準來決定在沒有外部線索的情況下使用多少組件。
在經典高斯混合模型中選擇組件數#
估計演算法期望最大化#
從未標記的資料中學習高斯混合模型的主要困難在於,人們通常不知道哪些點來自哪個潛在組件(如果可以存取此資訊,則很容易將單獨的高斯分布擬合到每組點)。 期望最大化是一種完善的統計演算法,它通過迭代過程來解決此問題。 首先,假設隨機組件(隨機以資料點為中心、從 k-means 學習或甚至只是在原點附近呈常態分佈),並計算每個點由模型每個組件生成的機率。 然後,調整參數以在給定這些分配的情況下最大化資料的可能性。 重複此過程保證始終會收斂到局部最優值。
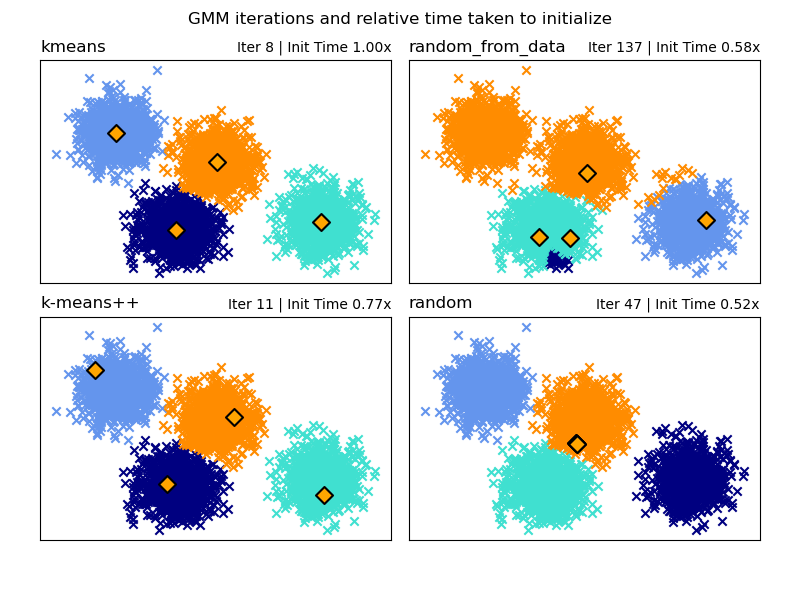
初始化方法的選擇#
有四種初始化方法的選擇(以及輸入使用者定義的初始均值)來為模型組件生成初始中心
- k-means(預設)
這會套用傳統的 k-means 分群演算法。 與其他初始化方法相比,這在計算上可能很昂貴。
- k-means++
這使用 k-means 分群的初始化方法:k-means++。 這將從資料中隨機選取第一個中心。 後續的中心將從資料的加權分佈中選取,該分佈偏向於遠離現有中心的點。 k-means++ 是 k-means 的預設初始化,因此會比執行完整的 k-means 快,但對於具有許多組件的大型資料集,仍然可能需要大量時間。
- random_from_data
這將從輸入資料中隨機選取資料點作為初始中心。 這是一種非常快速的初始化方法,但如果選取的點彼此太接近,則可能會產生不收斂的結果。
- random
中心選取為稍微偏離所有資料均值的小擾動。 此方法很簡單,但可能會導致模型需要更長的時間才能收斂。
範例
有關在高斯混合中使用不同初始化的範例,請參閱 GMM 初始化方法。
2.1.2. 變分貝氏高斯混合#
BayesianGaussianMixture 物件實作了帶有變分推論演算法的高斯混合模型變體。 API 與 GaussianMixture 定義的類似。
估計演算法:變分推論
變分推論是期望最大化演算法的延伸,它最大化模型證據(包含先驗)的下界,而不是數據似然性。變分方法背後的原理與期望最大化相同(即兩者都是迭代演算法,在尋找每個點由每個混合成分生成的機率和將混合成分擬合到這些分配的點之間交替進行),但變分方法透過整合來自先驗分布的資訊來增加正規化。這避免了期望最大化解中常見的奇異性,但會對模型引入一些細微的偏差。推論通常明顯較慢,但通常不會慢到無法實際使用。
由於其貝氏性質,變分演算法需要比期望最大化更多的超參數,其中最重要的是濃度參數 weight_concentration_prior。為濃度先驗指定較低的值會使模型將大部分權重放在少數幾個成分上,並將其餘成分的權重設定為非常接近零。濃度先驗的較高值將允許更多成分在混合中處於活動狀態。
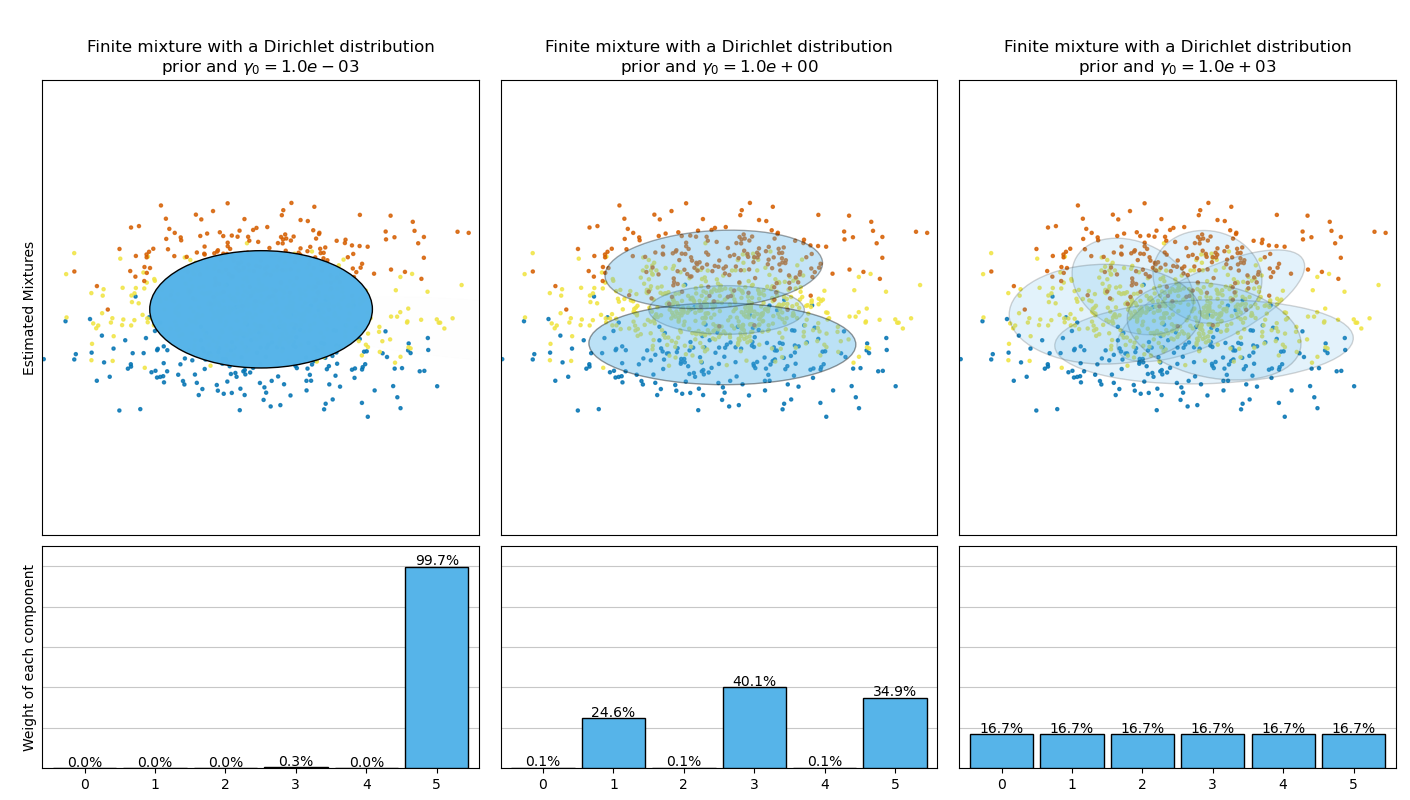
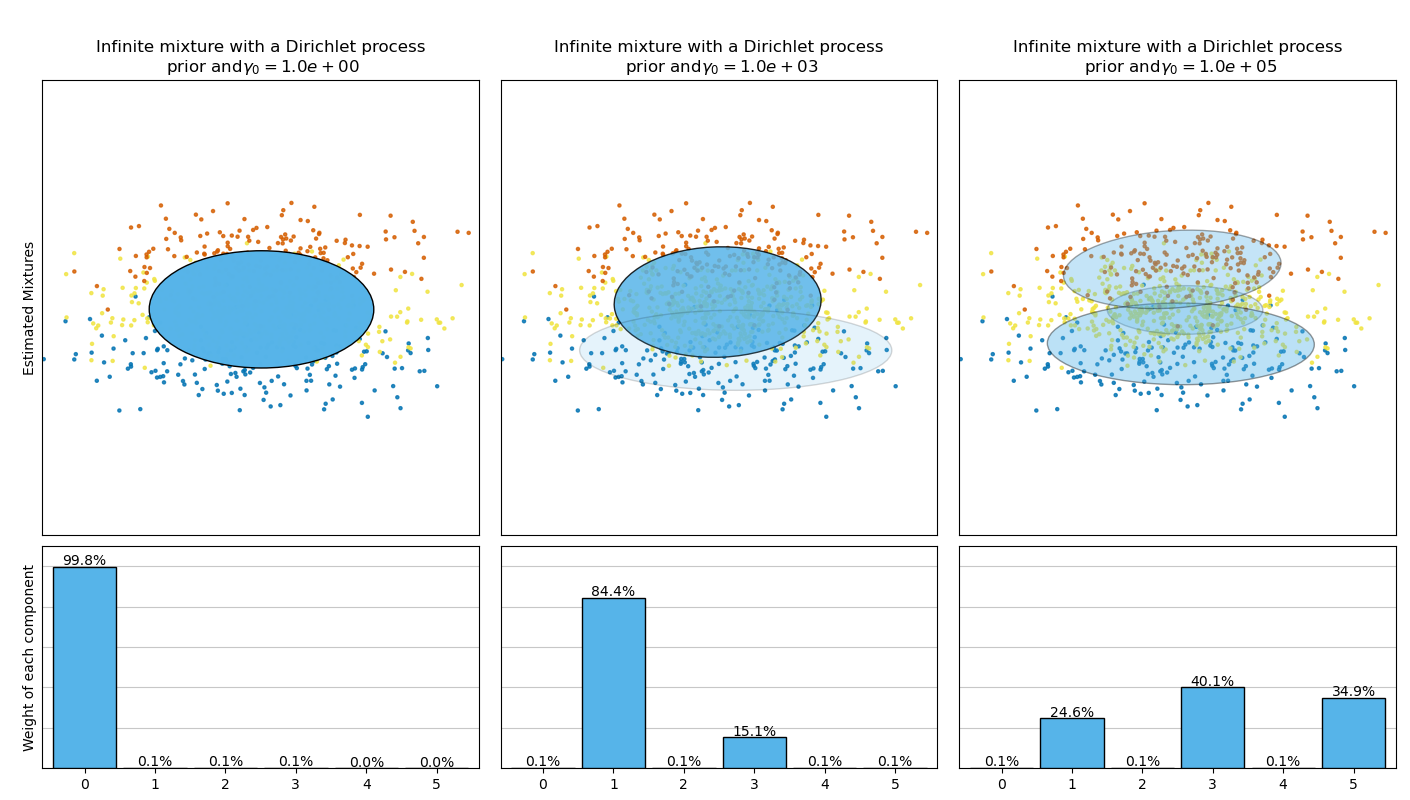
BayesianGaussianMixture 類的參數實作針對權重分布提出了兩種先驗類型:具有狄利克雷分布的有限混合模型,以及具有狄利克雷過程的無限混合模型。實際上,狄利克雷過程推論演算法是近似的,並使用具有固定最大成分數(稱為截斷表示)的截斷分布。實際使用的成分數量幾乎總是取決於數據。
下圖比較了針對不同權重濃度先驗類型(參數 weight_concentration_prior_type)在不同的 weight_concentration_prior 值下獲得的結果。在這裡,我們可以看到 weight_concentration_prior 參數的值對獲得的有效活動成分數有很大的影響。我們還可以注意到,當先驗類型為 'dirichlet_distribution' 時,較大的濃度權重先驗值會導致更均勻的權重,而對於 'dirichlet_process' 類型(預設使用)則不一定如此。
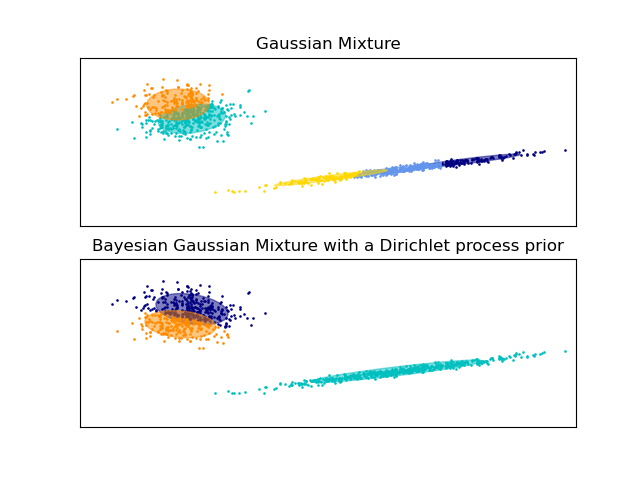
下面的範例比較了具有固定成分數的高斯混合模型,與具有狄利克雷過程先驗的變分高斯混合模型。在這裡,經典的高斯混合模型使用 5 個成分擬合到由 2 個群集組成的數據集。我們可以看到,具有狄利克雷過程先驗的變分高斯混合模型能夠將自己限制為僅 2 個成分,而高斯混合模型則使用必須由用戶預先設定的固定成分數來擬合數據。在這種情況下,使用者選擇了 n_components=5,這與此玩具數據集的真實生成分布不符。請注意,在觀察次數非常少的情況下,具有狄利克雷過程先驗的變分高斯混合模型可能會採取保守的立場,僅擬合一個成分。
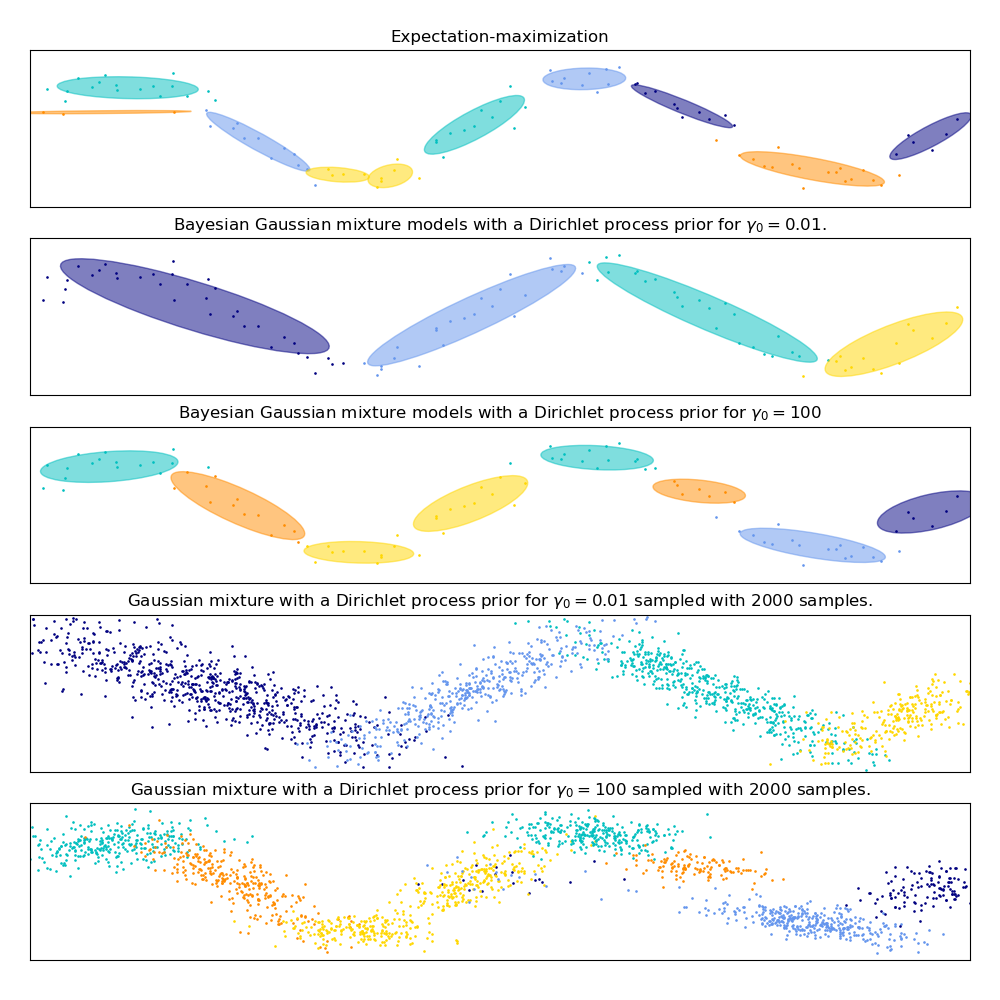
在下圖中,我們正在擬合一個高斯混合模型難以描述的數據集。調整 BayesianGaussianMixture 的參數 weight_concentration_prior 會控制用於擬合此數據的成分數量。我們還在最後兩個圖表中展示了從兩個產生的混合中隨機採樣的樣本。
範例
有關繪製
GaussianMixture和BayesianGaussianMixture的信賴橢圓體的範例,請參閱 高斯混合模型橢圓體。高斯混合模型正弦曲線 顯示使用
GaussianMixture和BayesianGaussianMixture來擬合正弦波。有關使用不同的參數
weight_concentration_prior值,繪製具有不同weight_concentration_prior_type的BayesianGaussianMixture的信賴橢圓體的範例,請參閱 變分貝氏高斯混合的濃度先驗類型分析。
使用 BayesianGaussianMixture 的變分推論的優缺點#
優點
- 自動選擇:
當
weight_concentration_prior夠小時,且n_components大於模型認為必要的數目時,變分貝氏混合模型會自然地趨於將一些混合權重值設定為接近零。這使得模型可以自動選擇合適的有效成分數。只需要提供此數字的上限。但是請注意,「理想」的活動成分數非常特定於應用,並且通常在資料探索設定中定義不明確。- 對參數數量的敏感度較低:
與幾乎總是盡可能使用所有成分的有限模型不同,因此會針對不同成分數量產生截然不同的解,具有狄利克雷過程先驗的變分推論(
weight_concentration_prior_type='dirichlet_process')不會隨著參數的變化而有太大改變,從而帶來更高的穩定性和更少的調整。- 正規化:
由於結合了先驗資訊,變分解比期望最大化解具有更少的不良特殊情況。
缺點
- 速度:
變分推論所需的額外參數化會使推論速度變慢,但並不多。
- 超參數:
此演算法需要額外的超參數,可能需要透過交叉驗證進行實驗性調整。
- 偏差:
推論演算法中存在許多隱含的偏差(如果使用狄利克雷過程,則也存在隱含偏差),並且每當這些偏差與數據不符時,都有可能使用有限混合擬合更好的模型。
2.1.2.1. 狄利克雷過程#
在這裡,我們描述狄利克雷過程混合的變分推論演算法。狄利克雷過程是關於 *具有無限、無界數量的分割的群集* 的先驗機率分布。與有限高斯混合模型相比,變分技術讓我們幾乎可以在不影響推論時間的情況下,將這種先驗結構納入高斯混合模型中。
一個重要的問題是,狄利克雷過程如何使用無限、無界的群集數量,並且仍然保持一致性。雖然完整的解釋不適合本手冊,但可以思考它的 切棍過程 類比來幫助理解它。切棍過程是狄利克雷過程的產生故事。我們從一個單位長度的棍子開始,並在每個步驟中折斷剩餘棍子的一部分。每次,我們都將棍子的長度與落入混合群組的點的比例相關聯。最後,為了表示無限混合,我們將棍子的最後剩餘部分與不屬於所有其他群組的點的比例相關聯。每一段的長度都是一個隨機變數,其機率與濃度參數成正比。濃度值較小會將單位長度分成較大的棍子片段(定義更集中的分布)。較大的濃度值會產生較小的棍子片段(增加具有非零權重的成分數量)。
狄利克雷過程的變分推論技術仍然使用此無限混合模型的有限近似值,但是不必預先指定要使用的成分數量,而只需指定濃度參數和混合成分數量的上限(假設此上限高於「真實」成分數,則此上限僅影響演算法複雜性,而不影響實際使用的成分數)。