4.2. 置換特徵重要性#
置換特徵重要性是一種模型檢視技術,用於衡量每個特徵對已擬合模型在給定表格資料集上的統計效能的貢獻。此技術對於非線性或不透明的估計器特別有用,它涉及隨機混洗單一特徵的值,並觀察模型分數的隨之降低[1]。透過破壞特徵和目標之間的關係,我們判斷模型對該特定特徵的依賴程度。
在下圖中,我們觀察到置換特徵對特徵和目標之間相關性的影響,以及隨之對模型統計效能的影響。
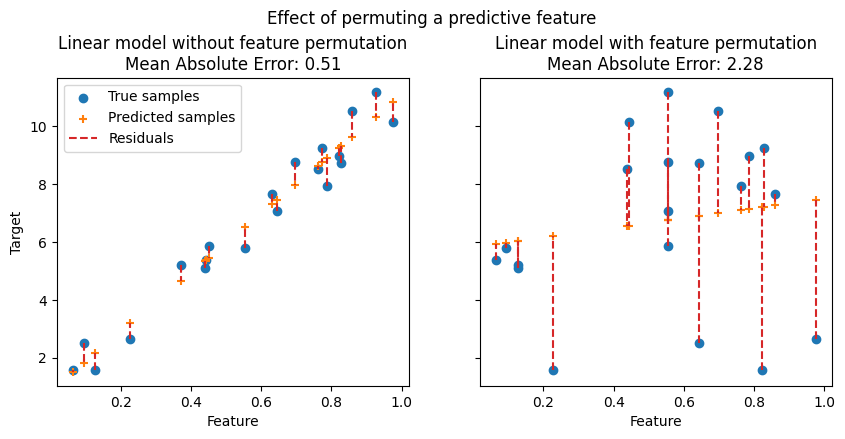
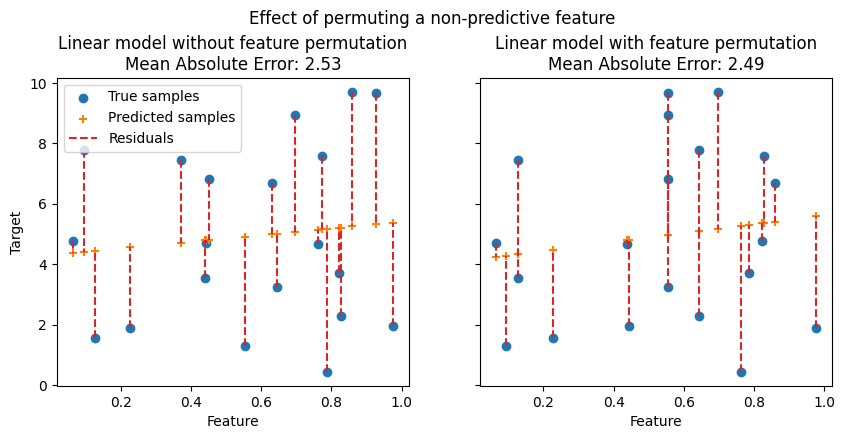
在上圖中,我們觀察到置換預測性特徵會破壞特徵和目標之間的相關性,並隨之降低模型的統計效能。在下圖中,我們觀察到置換非預測性特徵並不會顯著降低模型的統計效能。
置換特徵重要性的一個關鍵優勢在於它是模型無關的,也就是說,它可以應用於任何已擬合的估計器。此外,它可以透過不同的特徵置換計算多次,進一步提供針對特定訓練模型估計的特徵重要性的變異數衡量。
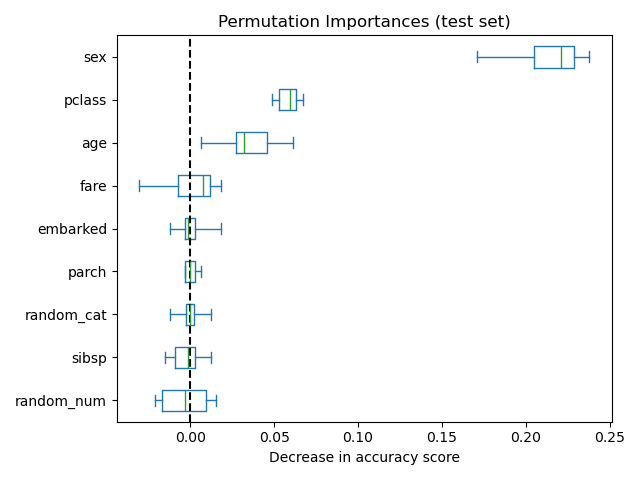
下圖顯示了在泰坦尼克號資料集的增強版本上訓練的RandomForestClassifier的置換特徵重要性,該版本包含random_cat和random_num特徵,也就是說,一個與目標變數沒有任何相關性的類別和數值特徵。
警告
對於不良模型(低交叉驗證分數)而言,被認為重要性較低的特徵對於良好模型可能非常重要。因此,在計算重要性之前,始終必須使用保留集(或更好的方式是交叉驗證)評估模型的預測能力。置換重要性並不反映特徵本身的固有預測值,而是此特徵對於特定模型的重要性。
permutation_importance函式計算給定資料集中估計器的特徵重要性。n_repeats參數設定隨機混洗特徵的次數,並傳回特徵重要性的樣本。
讓我們考慮以下已訓練的迴歸模型
>>> from sklearn.datasets import load_diabetes
>>> from sklearn.model_selection import train_test_split
>>> from sklearn.linear_model import Ridge
>>> diabetes = load_diabetes()
>>> X_train, X_val, y_train, y_val = train_test_split(
... diabetes.data, diabetes.target, random_state=0)
...
>>> model = Ridge(alpha=1e-2).fit(X_train, y_train)
>>> model.score(X_val, y_val)
0.356...
其透過\(R^2\)分數衡量的驗證效能顯著高於機會水準。這使得可以使用permutation_importance函式來探查哪些特徵最具預測性
>>> from sklearn.inspection import permutation_importance
>>> r = permutation_importance(model, X_val, y_val,
... n_repeats=30,
... random_state=0)
...
>>> for i in r.importances_mean.argsort()[::-1]:
... if r.importances_mean[i] - 2 * r.importances_std[i] > 0:
... print(f"{diabetes.feature_names[i]:<8}"
... f"{r.importances_mean[i]:.3f}"
... f" +/- {r.importances_std[i]:.3f}")
...
s5 0.204 +/- 0.050
bmi 0.176 +/- 0.048
bp 0.088 +/- 0.033
sex 0.056 +/- 0.023
請注意,頂端特徵的重要性值佔參考分數 0.356 的很大一部分。
可以在訓練集或保留的測試或驗證集上計算置換重要性。使用保留集可以突顯哪些特徵對受檢視模型的泛化能力貢獻最大。在訓練集上重要但在保留集上不重要的特徵可能會導致模型過度擬合。
置換特徵重要性取決於使用scoring引數指定的評分函式。此引數接受多個評分器,這比多次使用不同的評分器依序呼叫permutation_importance更有效率,因為它可以重複使用模型預測。
使用多個評分器的置換特徵重要性範例#
在下面的範例中,我們使用度量列表,但可以使用更多的輸入格式,如使用多個度量評估中所述。
>>> scoring = ['r2', 'neg_mean_absolute_percentage_error', 'neg_mean_squared_error']
>>> r_multi = permutation_importance(
... model, X_val, y_val, n_repeats=30, random_state=0, scoring=scoring)
...
>>> for metric in r_multi:
... print(f"{metric}")
... r = r_multi[metric]
... for i in r.importances_mean.argsort()[::-1]:
... if r.importances_mean[i] - 2 * r.importances_std[i] > 0:
... print(f" {diabetes.feature_names[i]:<8}"
... f"{r.importances_mean[i]:.3f}"
... f" +/- {r.importances_std[i]:.3f}")
...
r2
s5 0.204 +/- 0.050
bmi 0.176 +/- 0.048
bp 0.088 +/- 0.033
sex 0.056 +/- 0.023
neg_mean_absolute_percentage_error
s5 0.081 +/- 0.020
bmi 0.064 +/- 0.015
bp 0.029 +/- 0.010
neg_mean_squared_error
s5 1013.866 +/- 246.445
bmi 872.726 +/- 240.298
bp 438.663 +/- 163.022
sex 277.376 +/- 115.123
即使重要性值的尺度非常不同,不同度量的特徵排序也大致相同。但是,這並不能保證,不同的度量可能會導致顯著不同的特徵重要性,尤其是對於針對不平衡分類問題訓練的模型,其中分類度量的選擇至關重要。
4.2.1. 置換重要性演算法的概述#
輸入:已擬合預測模型 \(m\),表格資料集(訓練或驗證) \(D\)。
計算模型 \(m\) 在資料 \(D\) 上的參考分數 \(s\)(例如,分類器的準確度或迴歸器的 \(R^2\))。
對於每個特徵 \(j\)(\(D\) 的列)
對於 \({1, ..., K}\) 中的每個重複 \(k\)
隨機混洗資料集 \(D\) 的第 \(j\) 行,以產生名為 \(\tilde{D}_{k,j}\) 的損毀資料版本。
計算模型 \(m\) 在損毀資料 \(\tilde{D}_{k,j}\) 上的分數 \(s_{k,j}\)。
計算特徵 \(f_j\) 的重要性 \(i_j\),定義為
\[i_j = s - \frac{1}{K} \sum_{k=1}^{K} s_{k,j}\]
4.2.2. 與樹狀結構中基於雜質的重要性之間的關係#
基於樹的模型提供另一種衡量基於雜質平均降低量 (MDI) 的特徵重要性的方法。雜質由決策樹的分裂準則(吉尼、對數損失或均方誤差)量化。但是,當模型過度擬合時,此方法可能會將高重要性給予對未見資料可能沒有預測性的特徵。另一方面,基於置換的特徵重要性避免了這個問題,因為它可以在未見資料上計算。
此外,樹的基於雜質的特徵重要性具有很強的偏差,並且偏好高基數特徵(通常是數值特徵)而不是低基數特徵,例如二元特徵或具有少量可能類別的類別變數。
基於置換的特徵重要性沒有這種偏差。此外,置換特徵重要性可以使用模型預測的任何效能指標進行計算,並且可以用於分析任何模型類別(而不僅僅是基於樹的模型)。
以下範例突顯了基於雜質的特徵重要性與基於排列的特徵重要性之間的限制:排列重要性 vs 隨機森林特徵重要性 (MDI)。
4.2.3. 強相關特徵上的誤導值#
當兩個特徵相關時,且其中一個特徵被置換,模型仍然可以透過其相關特徵存取後者。這會導致兩個特徵的報告重要性值較低,儘管它們可能實際上很重要。
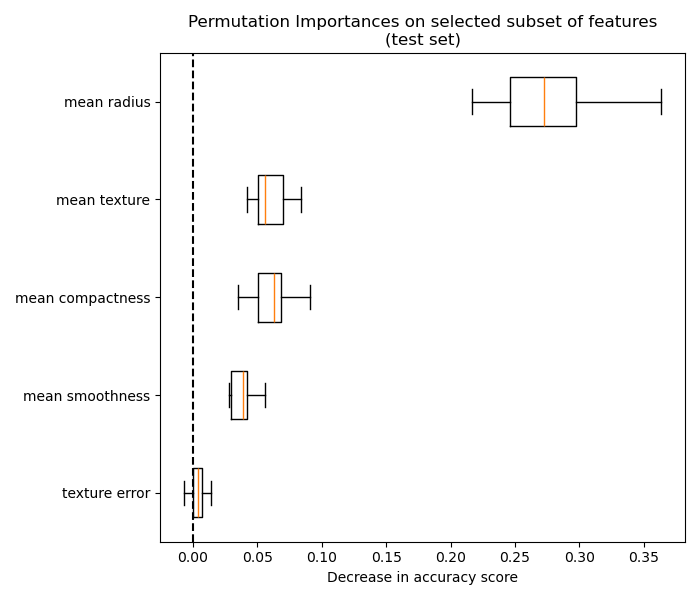
下圖顯示了使用乳癌威斯康辛 (診斷) 資料集訓練的RandomForestClassifier的排列特徵重要性,該資料集包含強相關特徵。一種天真的解釋會認為所有特徵都不重要。
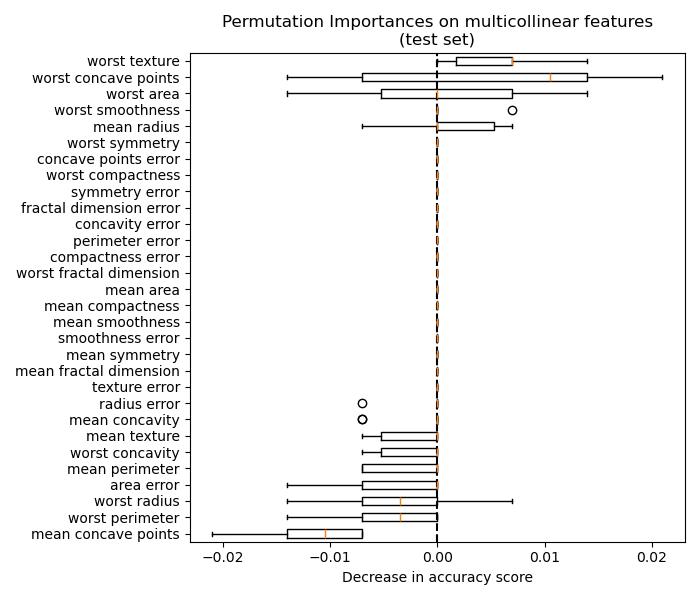
處理這個問題的一種方法是將相關的特徵分群,並僅從每個群組中保留一個特徵。
有關此策略的更多詳細資訊,請參閱範例具有多重共線性或相關特徵的排列重要性。
範例
參考文獻