3.3. 調整類別預測的決策閾值#
分類最好分為兩個部分
學習模型以預測(理想情況下)類別機率的統計問題;
根據這些機率預測採取具體行動的決策問題。
讓我們舉一個與天氣預報相關的簡單例子:第一點與回答「明天下雨的機率是多少?」有關,而第二點與回答「明天我應該帶雨傘嗎?」有關。
當談到 scikit-learn API 時,第一點是使用 predict_proba 或 decision_function 提供分數來解決。前者為每個類別返回條件機率估計 \(P(y|X)\),而後者為每個類別返回決策分數。
對應於標籤的決策是透過 predict 獲得的。在二元分類中,決策規則或行動是透過對分數進行閾值化來定義,從而導致每個樣本預測單一類別標籤。對於 scikit-learn 中的二元分類,類別標籤預測是透過硬編碼的截止規則獲得的:當條件機率 \(P(y|X)\) 大於 0.5 時(使用 predict_proba 獲得)或當決策分數大於 0 時(使用 decision_function 獲得),則預測為正類別。
在這裡,我們展示一個例子,說明條件機率估計 \(P(y|X)\) 和類別標籤之間的關係
>>> from sklearn.datasets import make_classification
>>> from sklearn.tree import DecisionTreeClassifier
>>> X, y = make_classification(random_state=0)
>>> classifier = DecisionTreeClassifier(max_depth=2, random_state=0).fit(X, y)
>>> classifier.predict_proba(X[:4])
array([[0.94 , 0.06 ],
[0.94 , 0.06 ],
[0.0416..., 0.9583...],
[0.0416..., 0.9583...]])
>>> classifier.predict(X[:4])
array([0, 0, 1, 1])
雖然這些硬編碼規則起初可能看起來是合理的預設行為,但它們對於大多數用例來說絕對不是理想的。讓我們用一個例子來說明。
考慮一種情境,其中部署了一個預測模型來協助醫生檢測腫瘤。在這種情況下,醫生很可能會有興趣找出所有患有癌症的患者,並且不會遺漏任何患有癌症的患者,以便他們可以為其提供正確的治療。換句話說,醫生會優先考慮實現高召回率。這種對召回率的重視當然會伴隨著潛在更多誤報預測的權衡,從而降低模型的精確度。醫生願意承擔這種風險,因為錯過癌症的代價遠高於進一步診斷測試的代價。因此,當決定是否將患者分類為患有癌症時,當條件機率估計遠低於 0.5 時,將他們分類為癌症陽性可能更有利。
3.3.1. 後調整決策閾值#
解決引言中提出的問題的一個方法是在模型訓練完成後調整分類器的決策閾值。TunedThresholdClassifierCV 使用內部交叉驗證來調整此閾值。選擇最佳閾值以最大化給定的指標。
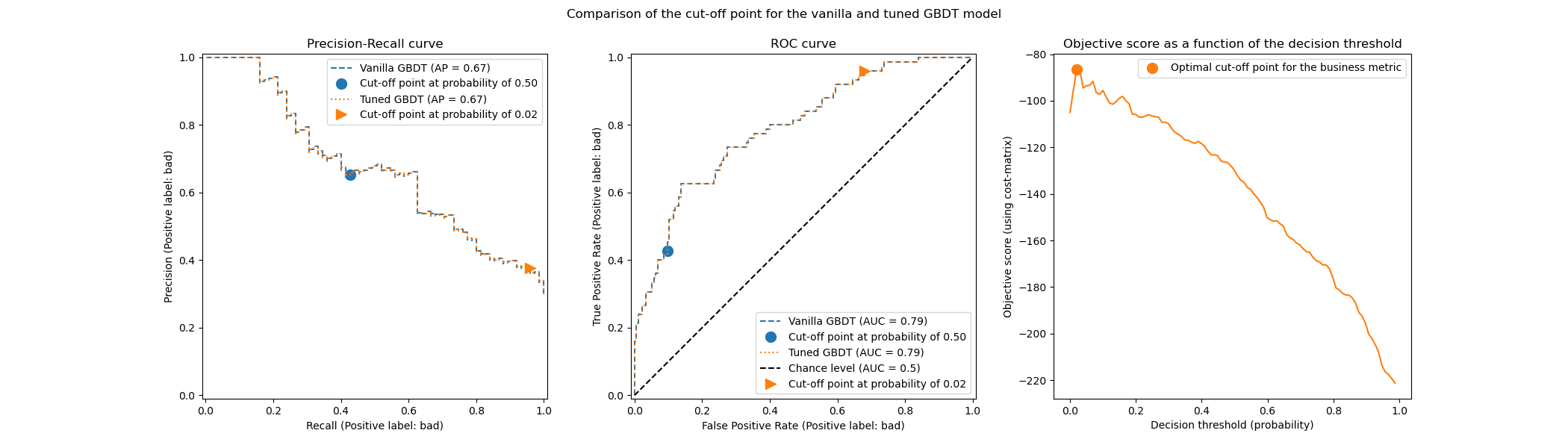
下圖說明了梯度提升分類器的決策閾值調整。雖然原始和調整後的分類器提供相同的 predict_proba 輸出,因此具有相同的接收者操作特徵 (ROC) 和精確度-召回率曲線,但由於調整後的決策閾值,類別標籤預測不同。原始分類器針對大於 0.5 的條件機率預測感興趣的類別,而調整後的分類器針對非常低的機率(約為 0.02)預測感興趣的類別。此決策閾值優化了業務定義的效用指標(在本例中為保險公司)。
3.3.1.1. 調整決策閾值的選項#
決策閾值可以透過由參數 scoring 控制的不同策略進行調整。
調整閾值的一種方法是最大化預先定義的 scikit-learn 指標。這些指標可以透過呼叫函式 get_scorer_names 來找到。預設情況下,平衡準確度是使用的指標,但請注意,應為您的用例選擇一個有意義的指標。
注意
請務必注意,這些指標帶有預設參數,特別是感興趣類別的標籤(即 pos_label)。因此,如果此標籤不適用於您的應用程式,則需要定義一個評分器,並使用 make_scorer 傳遞正確的 pos_label(以及其他參數)。請參閱 可呼叫評分器 以取得定義您自己的評分函式的資訊。例如,我們展示如何將資訊傳遞給評分器,使其在最大化 f1_score 時,感興趣的標籤為 0
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.model_selection import TunedThresholdClassifierCV
>>> from sklearn.metrics import make_scorer, f1_score
>>> X, y = make_classification(
... n_samples=1_000, weights=[0.1, 0.9], random_state=0)
>>> pos_label = 0
>>> scorer = make_scorer(f1_score, pos_label=pos_label)
>>> base_model = LogisticRegression()
>>> model = TunedThresholdClassifierCV(base_model, scoring=scorer)
>>> scorer(model.fit(X, y), X, y)
0.88...
>>> # compare it with the internal score found by cross-validation
>>> model.best_score_
0.86...
3.3.1.2. 關於內部交叉驗證的重要注意事項#
預設情況下,TunedThresholdClassifierCV 使用 5 折分層交叉驗證來調整決策閾值。參數 cv 允許控制交叉驗證策略。可以透過設定 cv="prefit" 並提供已擬合的分類器來繞過交叉驗證。在這種情況下,決策閾值會在提供給 fit 方法的資料上進行調整。
但是,使用此選項時應格外小心。由於過擬合的風險,您絕對不應使用相同的資料來訓練分類器和調整決策閾值。有關更多詳細資訊,請參閱以下範例章節(參閱 關於模型重新擬合和交叉驗證的考量)。如果您的資源有限,請考慮使用浮點數作為 cv 以限制為內部的單一訓練測試分割。
僅當提供的分類器已訓練完成,且您只想使用新的驗證集找到最佳決策閾值時,才應使用選項 cv="prefit"。
3.3.1.3. 手動設定決策閾值#
先前的章節討論了尋找最佳決策閾值的策略。也可以使用 FixedThresholdClassifier 類別手動設定決策閾值。如果您不希望在呼叫 fit 時重新擬合模型,請使用 FrozenEstimator 包裝您的子估計器,並執行 FixedThresholdClassifier(FrozenEstimator(estimator), ...)。
3.3.1.4. 範例#
請參閱名為決策函數的後調整截止點的範例,以深入了解決策閾值的後調整。
請參閱名為成本敏感學習的決策閾值後調整的範例,以了解成本敏感學習和決策閾值調整。