1.5. 隨機梯度下降法#
隨機梯度下降法 (SGD) 是一種簡單但非常有效的方法,適用於在凸損失函數(例如(線性)支持向量機和邏輯迴歸)下擬合線性分類器和迴歸器。 儘管 SGD 在機器學習社群中存在已久,但在大規模學習的背景下,最近才受到相當大的關注。
SGD 已成功應用於文字分類和自然語言處理中常見的大規模且稀疏的機器學習問題。 鑒於資料是稀疏的,此模組中的分類器可以輕鬆擴展到具有超過 10^5 個訓練範例和超過 10^5 個特徵的問題。
嚴格來說,SGD 僅是一種優化技術,並不對應於特定的機器學習模型系列。它只是一種訓練模型的方式。通常,SGDClassifier 或 SGDRegressor 的實例在 scikit-learn API 中會有一個等效的估計器,可能會使用不同的優化技術。例如,使用 SGDClassifier(loss='log_loss') 會產生邏輯迴歸,即與 LogisticRegression 等效的模型,該模型透過 SGD 而非 LogisticRegression 中的其他求解器之一來擬合。同樣,SGDRegressor(loss='squared_error', penalty='l2') 和 Ridge 通過不同的方式解決相同的優化問題。
隨機梯度下降法的優點是
效率。
易於實作(有許多程式碼調整的機會)。
隨機梯度下降法的缺點包括
SGD 需要許多超參數,例如正規化參數和迭代次數。
SGD 對於特徵縮放很敏感。
警告
在擬合模型之前,請確保您排列(隨機洗牌)訓練資料,或使用 shuffle=True 在每次迭代後洗牌(預設使用)。此外,理想情況下,應使用例如 make_pipeline(StandardScaler(), SGDClassifier()) 來標準化特徵(請參閱管線)。
1.5.1. 分類#
SGDClassifier 類別實現了純隨機梯度下降學習常式,該常式支援不同的損失函數和分類的懲罰。以下是使用 hinge 損失訓練的 SGDClassifier 的決策邊界,等效於線性 SVM。
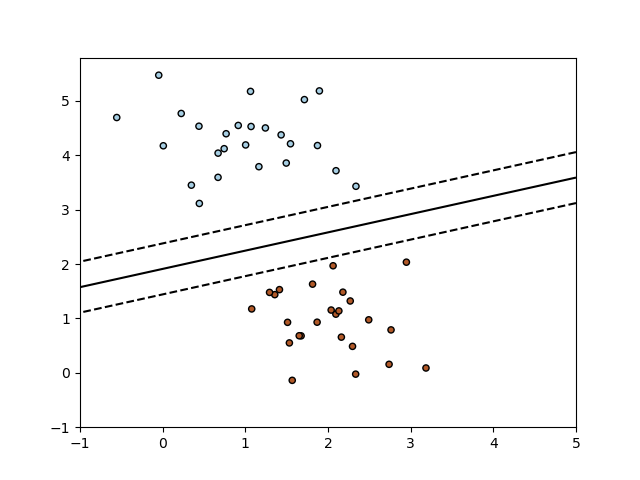
與其他分類器一樣,SGD 必須使用兩個陣列擬合:形狀為 (n_samples, n_features) 的陣列 X,其中包含訓練樣本,以及形狀為 (n_samples,) 的陣列 y,其中包含訓練樣本的目標值(類別標籤)
>>> from sklearn.linear_model import SGDClassifier
>>> X = [[0., 0.], [1., 1.]]
>>> y = [0, 1]
>>> clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=5)
>>> clf.fit(X, y)
SGDClassifier(max_iter=5)
在擬合後,模型就可以用來預測新值
>>> clf.predict([[2., 2.]])
array([1])
SGD 將線性模型擬合到訓練資料。coef_ 屬性包含模型參數
>>> clf.coef_
array([[9.9..., 9.9...]])
intercept_ 屬性包含截距(也稱為偏移量或偏差)
>>> clf.intercept_
array([-9.9...])
模型是否應使用截距,即偏置超平面,由參數 fit_intercept 控制。
到超平面的帶符號距離(計算為係數和輸入樣本之間的點積,加上截距)由 SGDClassifier.decision_function 給出
>>> clf.decision_function([[2., 2.]])
array([29.6...])
具體的損失函數可以透過 loss 參數設定。 SGDClassifier 支援下列損失函數
loss="hinge":(軟邊界)線性支持向量機,loss="modified_huber":平滑的 hinge 損失,loss="log_loss":邏輯迴歸,以及以下所有迴歸損失。在這種情況下,目標被編碼為 -1 或 1,並且該問題被視為迴歸問題。然後,預測的類別對應於預測目標的符號。
請參閱下面的數學部分了解公式。前兩個損失函數是惰性的,僅在範例違反邊界約束時才更新模型參數,這使得訓練非常有效,並且即使使用 L2 懲罰,也可能會產生更稀疏的模型(即具有更多零係數)。
使用 loss="log_loss" 或 loss="modified_huber" 可以啟用 predict_proba 方法,該方法會為每個樣本 \(x\) 提供一個概率估計向量 \(P(y|x)\)
>>> clf = SGDClassifier(loss="log_loss", max_iter=5).fit(X, y)
>>> clf.predict_proba([[1., 1.]])
array([[0.00..., 0.99...]])
具體的懲罰可以透過 penalty 參數設定。 SGD 支援下列懲罰
penalty="l2":對coef_的 L2 範數懲罰。penalty="l1":對coef_的 L1 範數懲罰。penalty="elasticnet":L2 和 L1 的凸組合;(1 - l1_ratio) * L2 + l1_ratio * L1。
預設設定為 penalty="l2"。 L1 懲罰會產生稀疏解,將大多數係數驅動為零。 在高度相關屬性的存在下,Elastic Net [11] 解決了 L1 懲罰的一些缺陷。 參數 l1_ratio 控制 L1 和 L2 懲罰的凸組合。
SGDClassifier 支援多類別分類,方法是將多個二元分類器以「一對多」(OVA) 的方式組合起來。對於 \(K\) 個類別中的每一個,都會學習一個二元分類器,用於區分該類別與所有其他 \(K-1\) 個類別。在測試時,我們會計算每個分類器的信賴分數(即與超平面的有符號距離),並選擇具有最高信賴度的類別。下圖說明了在鳶尾花資料集上使用 OVA 方法的過程。虛線代表三個 OVA 分類器;背景顏色顯示了三個分類器產生的決策表面。
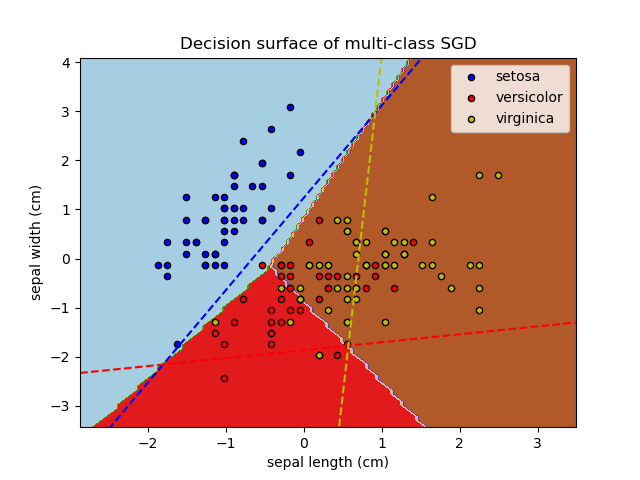
在多類別分類的情況下,coef_ 是一個形狀為 (n_classes, n_features) 的二維陣列,而 intercept_ 是一個形狀為 (n_classes,) 的一維陣列。coef_ 的第 i 列保存第 i 個類別的 OVA 分類器的權重向量;類別會按照升序索引(請參閱屬性 classes_)。請注意,原則上,由於它們允許建立機率模型,因此 loss="log_loss" 和 loss="modified_huber" 更適合用於一對多分類。
SGDClassifier 透過擬合參數 class_weight 和 sample_weight 支援加權類別和加權實例。請參閱以下範例和 SGDClassifier.fit 的 docstring 以取得更多資訊。
SGDClassifier 支援平均 SGD (ASGD) [10]。可以透過設定 average=True 來啟用平均。ASGD 執行與常規 SGD 相同的更新(請參閱 數學公式),但不是使用係數的最後一個值作為 coef_ 屬性(即最後一次更新的值),而是將 coef_ 設定為所有更新中係數的**平均**值。intercept_ 屬性也執行相同的操作。使用 ASGD 時,學習率可以更大甚至恆定,在某些資料集中可以加快訓練時間。
對於具有邏輯損失的分類,另一種具有平均策略的 SGD 變體是隨機平均梯度 (SAG) 演算法,可在 LogisticRegression 中作為求解器使用。
範例
1.5.2. 迴歸#
類別 SGDRegressor 實作一個普通的隨機梯度下降學習常式,該常式支援不同的損失函數和懲罰來擬合線性迴歸模型。SGDRegressor 非常適合具有大量訓練樣本(> 10,000)的迴歸問題,對於其他問題,我們建議使用 Ridge、Lasso 或 ElasticNet。
具體的損失函數可以透過 loss 參數設定。SGDRegressor 支援以下損失函數
loss="squared_error":普通最小平方loss="huber":用於穩健迴歸的 Huber 損失loss="epsilon_insensitive":線性支援向量迴歸
有關公式,請參閱 下面的數學部分。Huber 和 epsilon-insensitive 損失函數可以用於穩健迴歸。不敏感區域的寬度必須透過參數 epsilon 指定。此參數取決於目標變數的尺度。
penalty 參數決定要使用的正規化(請參閱上面分類部分中的說明)。
SGDRegressor 也支援平均 SGD [10](此處再次參閱上面分類部分中的說明)。
對於具有平方損失和 l2 懲罰的迴歸,另一種具有平均策略的 SGD 變體是隨機平均梯度 (SAG) 演算法,可在 Ridge 中作為求解器使用。
1.5.3. 線上單類別 SVM#
類別 sklearn.linear_model.SGDOneClassSVM 實作使用隨機梯度下降的線上線性版本的單類別 SVM。結合核函數近似技術,sklearn.linear_model.SGDOneClassSVM 可用於近似於 sklearn.svm.OneClassSVM 中實作的核化單類別 SVM 的解,其複雜度與樣本數呈線性關係。請注意,核化單類別 SVM 的複雜度在樣本數中至少為二次方。sklearn.linear_model.SGDOneClassSVM 因此非常適合具有大量訓練樣本(> 10,000)的資料集,對於這些資料集,SGD 變體的速度可以快幾個數量級。
數學細節#
其實作基於隨機梯度下降的實作。事實上,單類別 SVM 的原始最佳化問題由下式給出
其中 \(\nu \in (0, 1]\) 是使用者指定的參數,用於控制離群值的比例和支援向量的比例。擺脫鬆弛變數 \(\xi_i\),此問題等效於
乘以常數 \(\nu\) 並引入截距 \(b = 1 - \rho\),我們得到以下等效的最佳化問題
這與 數學公式 一節中研究的最佳化問題類似,其中 \(y_i = 1, 1 \leq i \leq n\) 且 \(\alpha = \nu/2\),\(L\) 是 hinge 損失函數,\(R\) 是 L2 範數。我們只需要在最佳化迴圈中加入項 \(b\nu\)。
如同 SGDClassifier 和 SGDRegressor,SGDOneClassSVM 支援平均 SGD。可以透過設定 average=True 來啟用平均。
範例
1.5.4. 稀疏資料的隨機梯度下降#
注意
由於截距的學習率縮小,稀疏實作產生的結果與密集實作略有不同。請參閱 實作細節。
內建支援 scipy.sparse 支援的任何格式的矩陣中的稀疏資料。但是,為了獲得最大效率,請使用 scipy.sparse.csr_matrix 中定義的 CSR 矩陣格式。
範例
1.5.5. 複雜度#
隨機梯度下降法 (SGD) 的主要優勢在於其效率,基本上與訓練範例的數量呈線性關係。如果 X 是一個大小為 (n, p) 的矩陣,則訓練的成本為 \(O(k n \bar p)\),其中 k 是迭代次數(週期),而 \(\bar p\) 是每個樣本的非零屬性平均數量。
然而,最近的理論結果顯示,要達到某個期望的優化準確度,運行時間並不會隨著訓練集大小的增加而增加。
1.5.6. 停止準則#
SGDClassifier 和 SGDRegressor 類別提供了兩種準則,可在達到給定的收斂程度時停止演算法。
當
early_stopping=True時,輸入資料會被分割成訓練集和驗證集。然後,模型會在訓練集上進行擬合,並且停止準則基於在驗證集上計算的預測分數(使用score方法)。可以使用參數validation_fraction來變更驗證集的大小。當
early_stopping=False時,模型會在整個輸入資料上進行擬合,並且停止準則基於在訓練資料上計算的目標函數。
在這兩種情況下,準則都會每個週期評估一次,並且當準則連續 n_iter_no_change 次沒有改善時,演算法就會停止。改善程度會使用絕對容差 tol 進行評估,並且演算法在最大迭代次數 max_iter 之後也會在任何情況下停止。
請參閱 隨機梯度下降的提前停止,以了解提前停止的效果範例。
1.5.7. 實務應用提示#
隨機梯度下降法對特徵縮放很敏感,因此強烈建議縮放您的資料。例如,將輸入向量 X 上的每個屬性縮放到 [0,1] 或 [-1,+1],或者將其標準化,使其具有平均值 0 和變異數 1。請注意,必須將*相同*的縮放應用於測試向量,才能獲得有意義的結果。這可以使用
StandardScaler輕鬆完成。from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) # Don't cheat - fit only on training data X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) # apply same transformation to test data # Or better yet: use a pipeline! from sklearn.pipeline import make_pipeline est = make_pipeline(StandardScaler(), SGDClassifier()) est.fit(X_train) est.predict(X_test)
如果您的屬性具有固有的尺度(例如,字詞頻率或指標特徵),則不需要縮放。
尋找合理的正規化項 \(\alpha\) 的最佳方法是使用自動超參數搜尋,例如
GridSearchCV或RandomizedSearchCV,通常在10.0**-np.arange(1,7)的範圍內。根據經驗,我們發現 SGD 在觀察到大約 10^6 個訓練樣本後會收斂。因此,迭代次數的合理第一個猜測是
max_iter = np.ceil(10**6 / n),其中n是訓練集的大小。如果您將 SGD 應用於使用 PCA 提取的特徵,我們發現通常明智的做法是將特徵值縮放某個常數
c,使訓練資料的平均 L2 範數等於 1。我們發現,平均 SGD 在具有較多特徵和較高 eta0 時效果最佳。
參考文獻
「Efficient BackProp」 Y. LeCun, L. Bottou, G. Orr, K. Müller - 在神經網路:交易技巧 1998 中。
1.5.8. 數學公式#
我們在此描述 SGD 程序的數學細節。關於收斂速度的良好概述可以在 [12] 中找到。
給定一組訓練範例 \((x_1, y_1), \ldots, (x_n, y_n)\),其中 \(x_i \in \mathbf{R}^m\) 且 \(y_i \in \mathcal{R}\) (分類時 \(y_i \in {-1, 1}\)),我們的目標是學習一個線性評分函數 \(f(x) = w^T x + b\),其中模型參數為 \(w \in \mathbf{R}^m\),截距為 \(b \in \mathbf{R}\)。為了進行二元分類的預測,我們只需查看 \(f(x)\) 的符號。為了找到模型參數,我們最小化由下式給出的正規化訓練誤差:
其中 \(L\) 是一個衡量模型(不)擬合的損失函數,而 \(R\) 是一個懲罰模型複雜性的正規化項(也稱為懲罰);\(\alpha > 0\) 是一個非負超參數,用於控制正規化強度。
損失函數詳細資訊#
對 \(L\) 的不同選擇會導致不同的分類器或迴歸器。
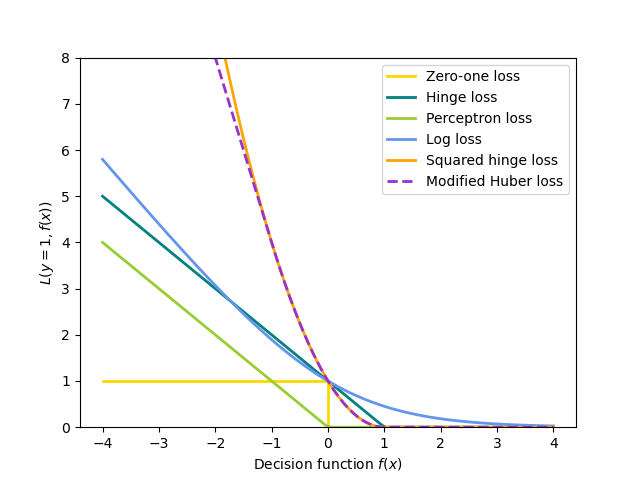
鉸鏈 (軟邊界):等同於支援向量分類。\(L(y_i, f(x_i)) = \max(0, 1 - y_i f(x_i))\)。
感知器:\(L(y_i, f(x_i)) = \max(0, - y_i f(x_i))\)。
修改後的 Huber:如果 \(y_i f(x_i) > -1\),則 \(L(y_i, f(x_i)) = \max(0, 1 - y_i f(x_i))^2\),否則 \(L(y_i, f(x_i)) = -4 y_i f(x_i)\)。
對數損失:等同於邏輯迴歸。\(L(y_i, f(x_i)) = \log(1 + \exp (-y_i f(x_i)))\)。
平方誤差:線性迴歸(根據 \(R\) 而定,為嶺迴歸或套索迴歸)。\(L(y_i, f(x_i)) = \frac{1}{2}(y_i - f(x_i))^2\)。
Huber:對離群值的敏感度低於最小平方。當 \(|y_i - f(x_i)| \leq \varepsilon\) 時,它等同於最小平方,否則 \(L(y_i, f(x_i)) = \varepsilon |y_i - f(x_i)| - \frac{1}{2} \varepsilon^2\)。
Epsilon-不敏感:(軟邊界)等同於支援向量迴歸。\(L(y_i, f(x_i)) = \max(0, |y_i - f(x_i)| - \varepsilon)\)。
所有上述損失函數都可以視為錯誤分類誤差(零一損失)的上界,如下圖所示。
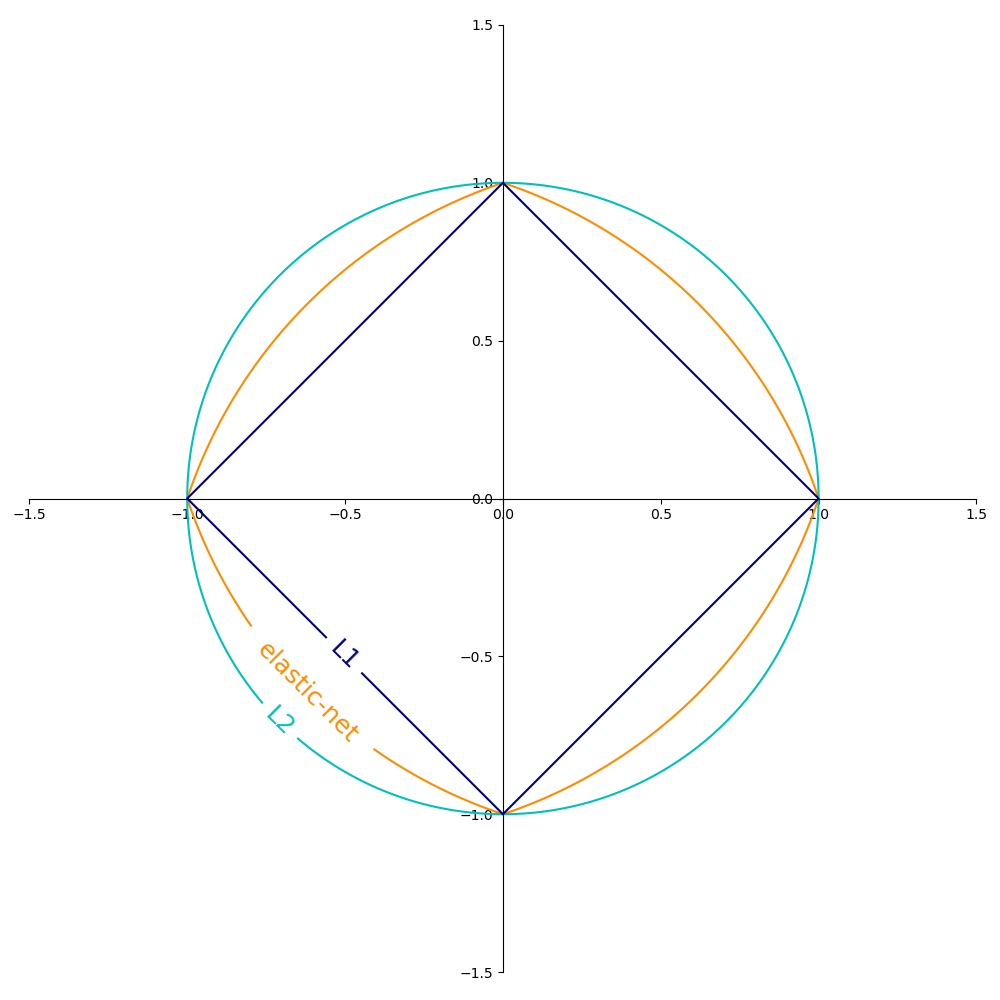
正規化項 \(R\)(penalty 參數)的常用選項包括:
L2 範數:\(R(w) := \frac{1}{2} \sum_{j=1}^{m} w_j^2 = ||w||_2^2\),
L1 範數:\(R(w) := \sum_{j=1}^{m} |w_j|\),這會產生稀疏解。
彈性網路:\(R(w) := \frac{\rho}{2} \sum_{j=1}^{n} w_j^2 + (1-\rho) \sum_{j=1}^{m} |w_j|\),L2 和 L1 的凸組合,其中 \(\rho\) 由
1 - l1_ratio給定。
下圖顯示當 \(R(w) = 1\) 時,不同正規化項在二維參數空間 (\(m=2\)) 中的等高線。
1.5.8.1. SGD#
隨機梯度下降是一種用於無約束最佳化問題的最佳化方法。與(批次)梯度下降相反,SGD 透過一次考慮一個訓練範例來近似 \(E(w,b)\) 的真實梯度。
SGDClassifier 類別實作一階 SGD 學習常式。演算法會迭代訓練範例,並且對於每個範例,會根據由下式給定的更新規則來更新模型參數:
其中 \(\eta\) 是學習率,它控制參數空間中的步長。截距 \(b\) 的更新方式類似,但不進行正規化(對於稀疏矩陣,則會額外衰減,如實作細節中所詳述)。
學習率 \(\eta\) 可以是常數,也可以是逐漸衰減的。對於分類,預設的學習率排程(learning_rate='optimal')由下式給定:
其中 \(t\) 是時間步長(總共有 n_samples * n_iter 個時間步長),\(t_0\) 是根據 Léon Bottou 提出的啟發式方法決定的,使得預期的初始更新與權重的預期大小相當(假設訓練樣本的範數約為 1)。確切的定義可以在 BaseSGD 中的 _init_t 中找到。
對於迴歸,預設的學習率排程是反向縮放(learning_rate='invscaling'),由下式給出:
其中 \(eta_0\) 和 \(power\_t\) 是使用者通過 eta0 和 power_t 分別選擇的超參數。
對於恆定學習率,請使用 learning_rate='constant',並使用 eta0 來指定學習率。
對於自適應遞減的學習率,請使用 learning_rate='adaptive',並使用 eta0 來指定起始學習率。當達到停止條件時,學習率會除以 5,且演算法不會停止。當學習率低於 1e-6 時,演算法才會停止。
模型參數可以通過 coef_ 和 intercept_ 屬性存取:coef_ 保存權重 \(w\),而 intercept_ 保存 \(b\)。
當使用平均隨機梯度下降法(使用 average 參數)時,coef_ 設定為所有更新的平均權重:coef_ \(= \frac{1}{T} \sum_{t=0}^{T-1} w^{(t)}\),其中 \(T\) 是更新的總次數,可以在 t_ 屬性中找到。
1.5.9. 實作細節#
隨機梯度下降法的實作受到 Stochastic Gradient SVM 的影響,如 [7] 所示。與 SvmSGD 類似,權重向量表示為純量和向量的乘積,這允許在 L2 正則化的情況下有效更新權重。在稀疏輸入 X 的情況下,截距會以較小的學習率(乘以 0.01)更新,以考慮到它更新的頻率更高。訓練範例是依序選取的,並且在每個觀察到的範例之後會降低學習率。我們採用了 [8] 中的學習率排程。對於多類別分類,使用「一對所有」的方法。我們使用 [9] 中提出的截斷梯度演算法進行 L1 正則化(以及彈性網路)。程式碼以 Cython 編寫。
參考文獻