2.5. 將訊號分解為成分 (矩陣分解問題)#
2.5.1. 主成分分析 (PCA)#
2.5.1.1. 精確 PCA 和機率解釋#
PCA 用於將多變量資料集分解為一組連續的正交成分,這些成分解釋了最大量的變異數。在 scikit-learn 中,PCA 作為一個轉換器物件實現,該物件在其 fit 方法中學習 \(n\) 個成分,並且可以用於新資料以將其投影到這些成分上。
PCA 在應用 SVD 之前,會針對每個特徵對輸入資料進行居中處理,但不縮放。可選參數 whiten=True 可以將資料投影到奇異空間,同時將每個成分縮放為單位變異數。如果下游模型對訊號的各向同性做出強烈假設,這通常很有用:例如,對於具有 RBF 核函數的支持向量機和 K-均值分群演算法來說就是如此。
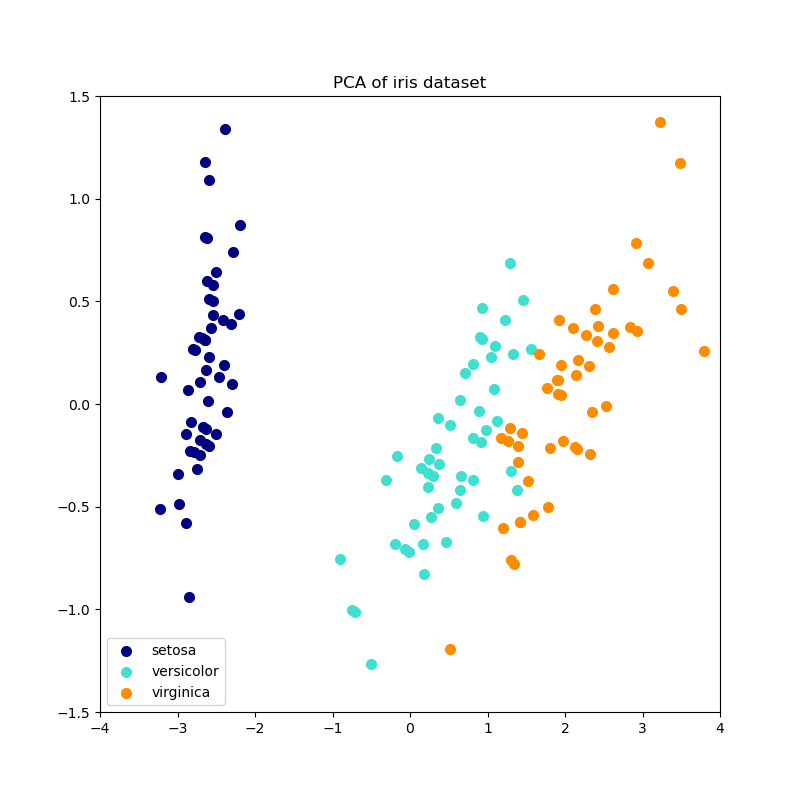
以下是 iris 資料集的範例,該資料集包含 4 個特徵,投影到解釋大部分變異數的 2 個維度上
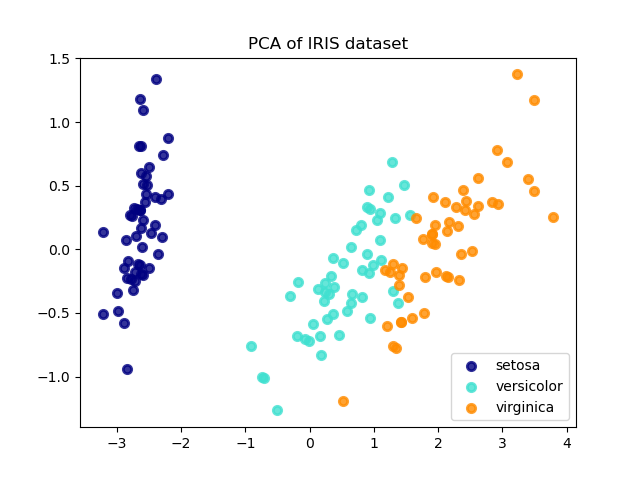
PCA 物件還提供了 PCA 的機率解釋,可以根據其解釋的變異量來提供資料的可能性。因此,它實現了一個 score 方法,該方法可以在交叉驗證中使用
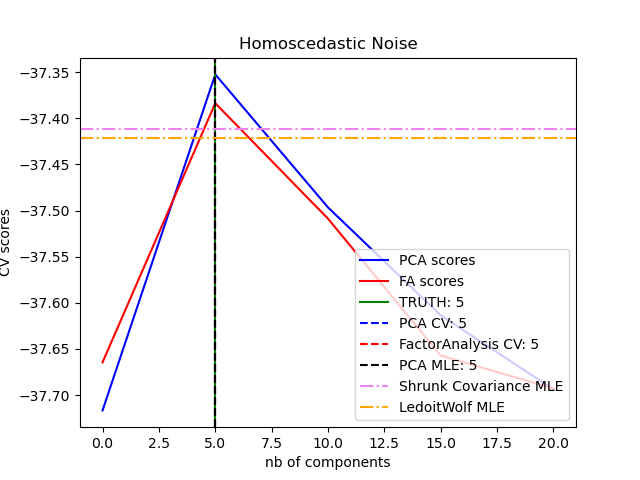
範例
2.5.1.2. 遞增 PCA#
PCA 物件非常有用,但對於大型資料集有一定的限制。最大的限制是 PCA 僅支援批次處理,這表示要處理的所有資料都必須適合主記憶體。IncrementalPCA 物件使用不同的處理方式,並允許部分計算,這幾乎與 PCA 的結果完全匹配,同時以小批次方式處理資料。IncrementalPCA 可以透過以下方式實作核心外的「主成分分析」:
對從本機硬碟或網路資料庫依序提取的資料區塊使用其
partial_fit方法。使用
numpy.memmap在記憶體對應檔案上呼叫其 fit 方法。
IncrementalPCA 僅儲存成分和雜訊變異數的估計值,以便遞增地更新 explained_variance_ratio_。這就是為什麼記憶體使用量取決於每個批次的樣本數,而不是資料集中要處理的樣本數。
與 PCA 中一樣,IncrementalPCA 會針對每個特徵對輸入資料進行居中處理,但不縮放,然後再應用 SVD。
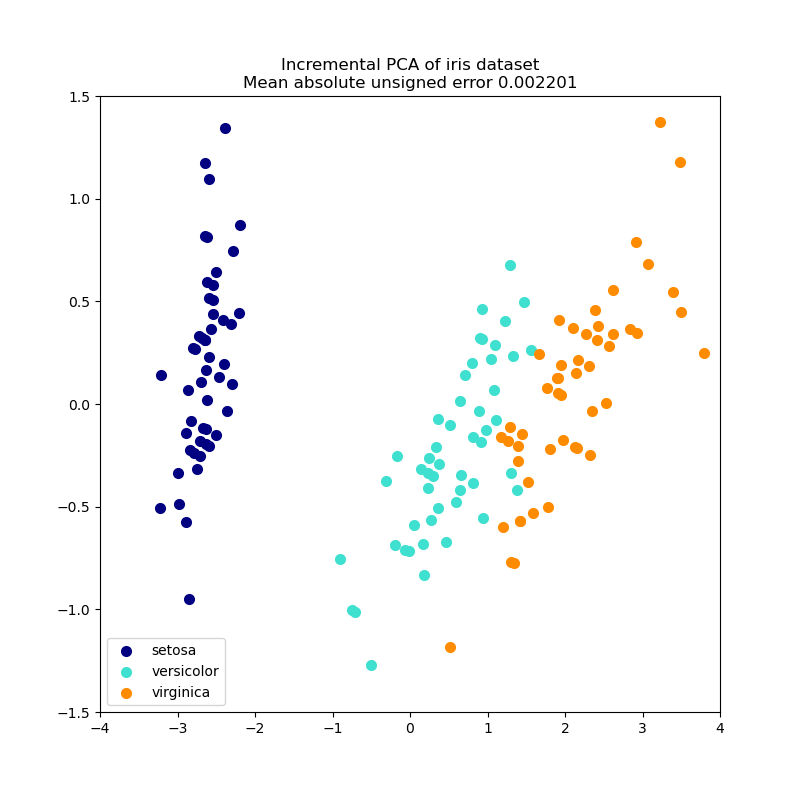
範例
2.5.1.3. 使用隨機 SVD 的 PCA#
通常,將資料投影到較低維度的空間以保留大部分變異數,方法是刪除與較低奇異值相關的成分的奇異向量,這會很有趣。
例如,如果我們使用 64x64 像素灰階圖片進行人臉辨識,則資料的維度為 4096,並且在如此寬的資料上訓練 RBF 支持向量機會很慢。此外,我們知道資料的內在維度遠低於 4096,因為所有人類面孔的圖片看起來都有些相似。樣本位於維度低得多的流形上 (例如,約為 200)。PCA 演算法可以用於線性轉換資料,同時降低維度並同時保留大部分解釋的變異數。
在這種情況下,使用可選參數 svd_solver='randomized' 的類別 PCA 非常有用:由於我們將刪除大部分奇異向量,因此將計算限制為對我們將保留以實際執行轉換的奇異向量進行近似估計會更有效率。
例如,以下顯示了 Olivetti 資料集中 16 個樣本肖像 (以 0.0 為中心)。右手邊是重新塑造成肖像的前 16 個奇異向量。由於我們只需要大小為 \(n_{samples} = 400\) 和 \(n_{features} = 64 \times 64 = 4096\) 的資料集的前 16 個奇異向量,因此計算時間少於 1 秒


如果我們注意到 \(n_{\max} = \max(n_{\mathrm{samples}}, n_{\mathrm{features}})\) 且 \(n_{\min} = \min(n_{\mathrm{samples}}, n_{\mathrm{features}})\),則隨機化 PCA 的時間複雜度為 \(O(n_{\max}^2 \cdot n_{\mathrm{components}})\),而不是 PCA 中實作的精確方法的 \(O(n_{\max}^2 \cdot n_{\min})\)。
隨機化 PCA 的記憶體使用量也與 \(2 \cdot n_{\max} \cdot n_{\mathrm{components}}\) 成正比,而不是精確方法的 \(n_{\max} \cdot n_{\min}\)。
注意:即使 whiten=False (預設),svd_solver='randomized' 的 PCA 中的 inverse_transform 實作也不是 transform 的精確反轉換。
範例
參考文獻
「使用隨機性尋找結構:用於建構近似矩陣分解的隨機演算法」 Halko 等人,2009 年中的演算法 4.3
「主成分分析的隨機演算法實作」 A. Szlam 等人,2014 年
2.5.1.4. 稀疏主成分分析 (SparsePCA 和 MiniBatchSparsePCA)#
SparsePCA 是 PCA 的變體,其目標是提取最能重建資料的一組稀疏成分。
迷你批次稀疏主成分分析(MiniBatchSparsePCA)是SparsePCA的一種變體,它速度更快但準確性較低。速度的提升是透過在給定的迭代次數下,迭代處理一小部分特徵集來實現的。
主成分分析(PCA)的缺點是,此方法提取的成分都具有密集的表達形式,也就是說,當表示為原始變數的線性組合時,它們具有非零係數。這可能會使解釋變得困難。在許多情況下,真實的底層成分可以更自然地被想像成稀疏向量;例如,在人臉辨識中,成分可能會自然地映射到臉部的各個部分。
稀疏主成分產生更簡潔、更易於解釋的表示,清楚地強調哪些原始特徵對樣本之間的差異做出貢獻。
以下範例說明從 Olivetti 人臉資料集中使用稀疏主成分分析提取的 16 個成分。可以看出,正則化項如何產生許多零值。此外,資料的自然結構使得非零係數在垂直方向上相鄰。該模型在數學上不強制執行此點:每個成分都是一個向量 \(h \in \mathbf{R}^{4096}\),並且除了以 64x64 像素圖像進行人為友善的可視化之外,沒有垂直相鄰的概念。下面顯示的成分看起來是局部的,這是資料固有結構的效果,該結構使得這種局部模式最小化重建誤差。存在考慮相鄰性和不同類型結構的稀疏誘導範數;有關這些方法的評論,請參閱[Jen09]。有關如何使用稀疏主成分分析的更多詳細資訊,請參閱下方的範例部分。

請注意,稀疏主成分分析問題有很多不同的公式。此處實作的公式基於 [Mrl09] 。解決的優化問題是一個主成分分析問題(字典學習),成分上帶有 \(\ell_1\) 懲罰
\(||.||_{\text{Fro}}\) 代表 Frobenius 範數,而 \(||.||_{1,1}\) 代表逐元素矩陣範數,它是矩陣中所有項的絕對值之和。當訓練樣本很少時,稀疏誘導的 \(||.||_{1,1}\) 矩陣範數也可以防止從雜訊中學習成分。懲罰程度(因此稀疏程度)可以透過超參數 alpha 進行調整。較小的值會導致溫和的正則化因式分解,而較大的值會將許多係數縮小為零。
注意
雖然 MiniBatchSparsePCA 類別在精神上類似於線上演算法,但它不實作 partial_fit,因為該演算法是沿著特徵方向而非樣本方向進行線上處理。
範例
參考文獻
“用於稀疏編碼的線上字典學習” J. Mairal, F. Bach, J. Ponce, G. Sapiro, 2009
“結構化稀疏主成分分析” R. Jenatton, G. Obozinski, F. Bach, 2009
2.5.2. 核主成分分析(kPCA)#
2.5.2.1. 精確核主成分分析#
KernelPCA 是主成分分析的擴展,它透過使用核函數(請參閱成對度量、親和力和核函數)實現非線性降維 [Scholkopf1997]。它有許多應用,包括去雜訊、壓縮和結構化預測(核函數依賴性估計)。KernelPCA 支援 transform 和 inverse_transform。
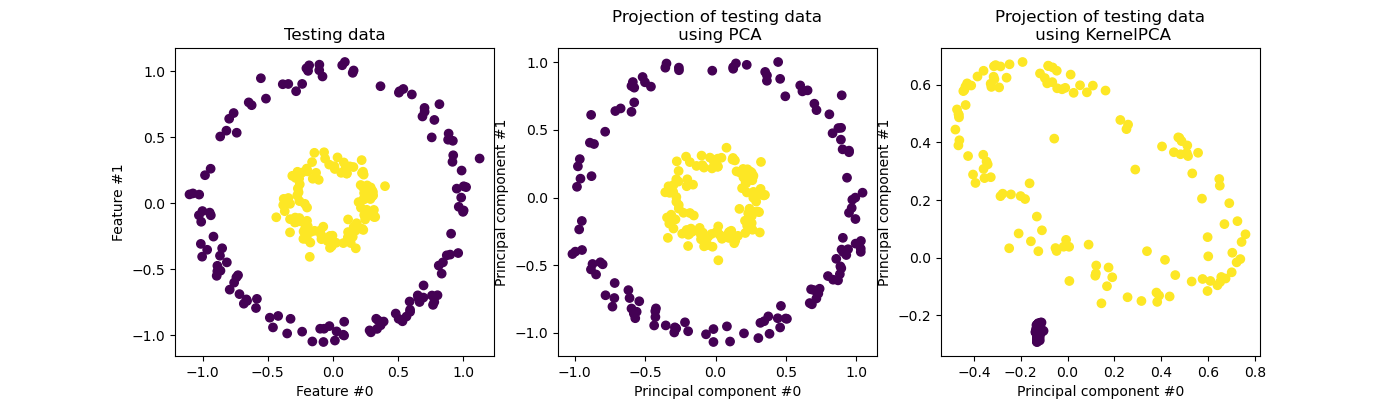
注意
KernelPCA.inverse_transform 依賴核嶺迴歸來學習將樣本從主成分分析基底映射到原始特徵空間的函數 [Bakir2003]。因此,使用 KernelPCA.inverse_transform 獲得的重建是一種近似值。有關更多詳細資訊,請參閱下面連結的範例。
範例
參考文獻
Schölkopf, Bernhard, Alexander Smola, 和 Klaus-Robert Müller. “核主成分分析。” 國際人工神經網路會議。Springer, Berlin, Heidelberg, 1997.
Bakır, Gökhan H., Jason Weston, 和 Bernhard Schölkopf. “學習尋找預影像。” 神經資訊處理系統的進展 16 (2003): 449-456.
2.5.2.2. 核主成分分析的求解器選擇#
雖然在 PCA 中,成分的數量受特徵數量的限制,但在 KernelPCA 中,成分的數量受樣本數量的限制。許多現實世界的資料集都有大量的樣本!在這些情況下,使用完整的 kPCA 找到所有成分會浪費計算時間,因為資料主要由前幾個成分描述(例如,n_components<=100)。換句話說,在核主成分分析擬合過程中進行特徵分解的中心化 Gram 矩陣的有效秩遠小於其大小。在這種情況下,近似特徵值求解器可以提供加速,並且精度損失非常低。
特徵值求解器#
當請求的 n_components 數量與樣本數量相比很小時,可以使用選用參數 eigen_solver='randomized' 來顯著減少計算時間。它依賴於隨機分解方法,以便在更短的時間內找到近似解。
隨機化 KernelPCA 的時間複雜度為 \(O(n_{\mathrm{samples}}^2 \cdot n_{\mathrm{components}})\),而不是使用 eigen_solver='dense' 實作的精確方法的 \(O(n_{\mathrm{samples}}^3)\)。
隨機化 KernelPCA 的記憶體佔用也與 \(2 \cdot n_{\mathrm{samples}} \cdot n_{\mathrm{components}}\) 成正比,而不是精確方法的 \(n_{\mathrm{samples}}^2\)。
注意:此技術與使用隨機 SVD 的 PCA 中的技術相同。
除了上述兩個求解器外,eigen_solver='arpack' 還可以用作獲得近似分解的另一種方法。在實務中,僅當要找到的成分數量極少時,此方法才會提供合理的執行時間。當所需的成分數量少於 10 個(嚴格)且樣本數量大於 200 個(嚴格)時,預設會啟用此方法。有關詳細資訊,請參閱KernelPCA。
參考文獻
dense 求解器:scipy.linalg.eigh 文件
randomized 求解器
“使用隨機性尋找結構:用於構建近似矩陣分解的隨機演算法” Halko 等人 (2009) 中的演算法 4.3
“用於主成分分析的隨機演算法的實作” A. Szlam 等人 (2014)
arpack 求解器:scipy.sparse.linalg.eigsh 文件 R. B. Lehoucq、D. C. Sorensen 和 C. Yang (1998)
2.5.3. 截斷奇異值分解和潛在語義分析#
TruncatedSVD 實作奇異值分解 (SVD) 的變體,該變體僅計算 \(k\) 個最大奇異值,其中 \(k\) 是使用者指定的參數。
TruncatedSVD 與 PCA 非常相似,但不同之處在於矩陣 \(X\) 不需要居中。當從特徵值中減去 \(X\) 的按列(每個特徵)平均值時,對結果矩陣進行截斷 SVD 等於 PCA。
關於截斷式奇異值分解 (Truncated SVD) 和潛在語義分析 (LSA)#
當將截斷式奇異值分解 (truncated SVD) 應用於詞彙-文件矩陣(由 CountVectorizer 或 TfidfVectorizer 返回)時,這種轉換被稱為潛在語義分析 (latent semantic analysis,LSA),因為它將這些矩陣轉換為低維度的「語義」空間。特別是,已知 LSA 可以對抗同義詞和多義詞(兩者大致都意味著每個詞有多種含義)的影響,這會導致詞彙-文件矩陣過於稀疏,並且在餘弦相似度等度量下表現出較差的相似性。
注意
LSA 也被稱為潛在語義索引 (latent semantic indexing, LSI),儘管嚴格來說,它指的是在資訊檢索目的的持久索引中的使用。
在數學上,應用於訓練樣本 \(X\) 的截斷式 SVD 會產生低秩近似值 \(X\)
在此操作之後,\(U_k \Sigma_k\) 是具有 \(k\) 個特徵(在 API 中稱為 n_components)的轉換後的訓練集。
為了也轉換測試集 \(X\),我們將其乘以 \(V_k\)
注意
在自然語言處理 (NLP) 和資訊檢索 (IR) 文獻中,大多數對 LSA 的處理方式都會交換矩陣 \(X\) 的軸,使其具有 (n_features, n_samples) 的形狀。我們以一種更符合 scikit-learn API 的不同方式呈現 LSA,但找到的奇異值是相同的。
雖然 TruncatedSVD 轉換器適用於任何特徵矩陣,但在 LSA/文件處理設定中,建議對 tf-idf 矩陣使用它,而不是原始頻率計數。特別是,應該開啟次線性縮放和逆文件頻率 (sublinear_tf=True, use_idf=True),以使特徵值更接近高斯分佈,從而補償 LSA 對文本數據的錯誤假設。
範例
參考文獻
Christopher D. Manning, Prabhakar Raghavan 和 Hinrich Schütze (2008),Introduction to Information Retrieval, Cambridge University Press, chapter 18: Matrix decompositions & latent semantic indexing
2.5.4. 字典學習#
2.5.4.1. 使用預先計算的字典進行稀疏編碼#
SparseCoder 物件是一個估計器,可用於將訊號轉換為來自固定、預先計算的字典(例如離散小波基底)的原子稀疏線性組合。因此,此物件不會實作 fit 方法。轉換相當於一個稀疏編碼問題:找到資料的表示,使其為盡可能少的字典原子的線性組合。字典學習的所有變體都實作以下轉換方法,這些方法可透過 transform_method 初始化參數來控制
正交匹配追蹤 (正交匹配追蹤 (OMP))
最小角度迴歸 (最小角度迴歸)
由最小角度迴歸計算的 Lasso
使用座標下降的 Lasso (Lasso)
閾值處理
閾值處理非常快,但無法產生準確的重建。它們在文獻中已被證明對分類任務很有用。對於圖像重建任務,正交匹配追蹤產生最準確、無偏的重建。
字典學習物件透過 split_code 參數提供在稀疏編碼結果中分離正值和負值的可能性。當字典學習用於提取將用於監督式學習的特徵時,這很有用,因為它允許學習演算法將不同的權重分配給特定原子的負載,從而分配給相應的正載。
單個樣本的分割碼長度為 2 * n_components,並使用以下規則建構:首先,計算長度為 n_components 的正規碼。然後,將 split_code 的前 n_components 個條目填入正規碼向量的正部分。分割碼的後半部分填入碼向量的負部分,僅具有正號。因此,分割碼是非負的。
範例
2.5.4.2. 通用字典學習#
字典學習 (DictionaryLearning) 是一個矩陣分解問題,相當於找到一個(通常是過完備的)字典,該字典在稀疏編碼擬合資料方面表現良好。
將資料表示為來自過完備字典的原子的稀疏組合,被認為是哺乳動物主要視覺皮層工作的方式。因此,已顯示應用於圖像塊的字典學習在圖像處理任務(例如圖像完成、修復和去噪)以及監督式識別任務中都能產生良好的結果。
字典學習是一個最佳化問題,透過交替更新稀疏碼(作為多個 Lasso 問題的解決方案,並考慮字典固定)然後更新字典以最佳擬合稀疏碼來解決。

\(||.||_{\text{Fro}}\) 代表 Frobenius 範數,而 \(||.||_{1,1}\) 代表逐條目矩陣範數,它是矩陣中所有條目的絕對值的總和。在使用此類程序來擬合字典後,轉換只是一個稀疏編碼步驟,它與所有字典學習物件共用相同的實作(請參閱 使用預先計算的字典進行稀疏編碼)。
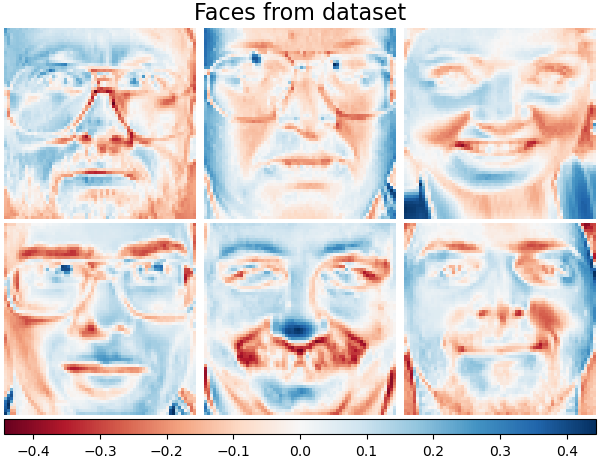
也可以約束字典和/或程式碼為正數,以符合資料中可能存在的約束。以下是套用不同正性約束的面孔。紅色表示負值,藍色表示正值,白色表示零。



下圖顯示了從浣熊臉部圖像的一部分中提取的 4x4 像素圖像塊學習的字典的外觀。

範例
參考文獻
“Online dictionary learning for sparse coding” J. Mairal, F. Bach, J. Ponce, G. Sapiro, 2009
2.5.4.3. 小批量字典學習#
MiniBatchDictionaryLearning 實作了字典學習演算法的更快但不太準確的版本,該版本更適合大型資料集。
預設情況下,MiniBatchDictionaryLearning 將資料劃分為小批量,並透過在指定數量的迭代次數內循環小批量,以線上方式進行最佳化。但是,目前它沒有實作停止條件。
估計器還實作了 partial_fit,它僅透過對小批量進行一次迭代來更新字典。當資料無法從一開始就輕鬆取得時,或者當資料不適合記憶體時,可以使用此選項進行線上學習。

2.5.5. 因素分析#
在無監督式學習中,我們只有一個資料集 \(X = \{x_1, x_2, \dots, x_n \}\)。如何以數學方式描述此資料集?\(X\) 的一個非常簡單的 連續 潛在 變數 模型是
向量 \(h_i\) 被稱為「潛在」向量,因為它是未被觀察到的。\(\epsilon\) 被視為一個雜訊項,其分佈遵循平均值為 0 且共變異數為 \(\Psi\) 的高斯分佈(即 \(\epsilon \sim \mathcal{N}(0, \Psi)\)),\(\mu\) 是一些任意的偏移向量。這種模型被稱為「生成式」模型,因為它描述了 \(x_i\) 如何從 \(h_i\) 生成。如果我們將所有的 \(x_i\) 作為列來形成一個矩陣 \(\mathbf{X}\),並將所有的 \(h_i\) 作為一個矩陣 \(\mathbf{H}\) 的列,那麼我們可以寫成(使用適當定義的 \(\mathbf{M}\) 和 \(\mathbf{E}\)):
換句話說,我們分解了矩陣 \(\mathbf{X}\)。
如果給定 \(h_i\),則上述方程式自動暗示了以下機率解釋:
對於一個完整的機率模型,我們還需要對潛在變數 \(h\) 設定先驗分佈。最直接的假設(基於高斯分佈的良好性質)是 \(h \sim \mathcal{N}(0, \mathbf{I})\)。這會產生一個高斯分佈作為 \(x\) 的邊際分佈:
現在,如果沒有任何進一步的假設,擁有潛在變數 \(h\) 的想法將是多餘的 – \(x\) 可以完全用平均值和共變異數建模。我們需要在這兩個參數中的一個上施加更具體的結構。一個簡單的附加假設是關於誤差共變異數 \(\Psi\) 的結構:
\(\Psi = \sigma^2 \mathbf{I}\):這個假設導致了
PCA的機率模型。\(\Psi = \mathrm{diag}(\psi_1, \psi_2, \dots, \psi_n)\):這個模型稱為
FactorAnalysis,一個經典的統計模型。矩陣 W 有時被稱為「因子負載矩陣」。
這兩個模型本質上都是估計一個具有低秩共變異數矩陣的高斯分佈。由於這兩個模型都是機率性的,它們可以被整合到更複雜的模型中,例如因子分析混合模型。如果假設潛在變數具有非高斯先驗,則會得到非常不同的模型(例如 FastICA)。
因子分析可以產生與 PCA 相似的成分(其負載矩陣的列)。但是,我們不能對這些成分做任何一般的陳述(例如,它們是否正交)。

因子分析相較於 PCA 的主要優勢在於,它可以獨立地對輸入空間每個方向的變異數進行建模(異方差雜訊)。

這在存在異方差雜訊的情況下,比機率 PCA 可以提供更好的模型選擇。
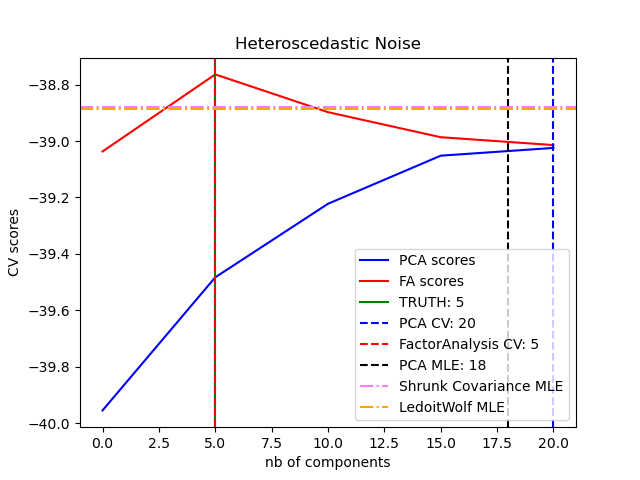
因子分析通常會接著對因子進行旋轉(使用參數 rotation),通常是為了提高可解釋性。例如,Varimax 旋轉會最大化平方負載變異數的總和,也就是說,它傾向於產生更稀疏的因子,每個因子僅受少數特徵的影響(「簡單結構」)。請參閱下面的第一個範例。
範例
2.5.6. 獨立成分分析 (ICA)#
獨立成分分析將多變數訊號分離為最大程度獨立的加性子成分。它在 scikit-learn 中使用 Fast ICA 演算法實作。通常,ICA 不用於降低維度,而是用於分離疊加的訊號。由於 ICA 模型不包含雜訊項,為了使模型正確,必須應用白化處理。這可以使用 `whiten` 參數在內部完成,也可以使用 PCA 的變體之一手動完成。
它經典地用於分離混合訊號(一個被稱為盲源分離的問題),如下面的例子所示:
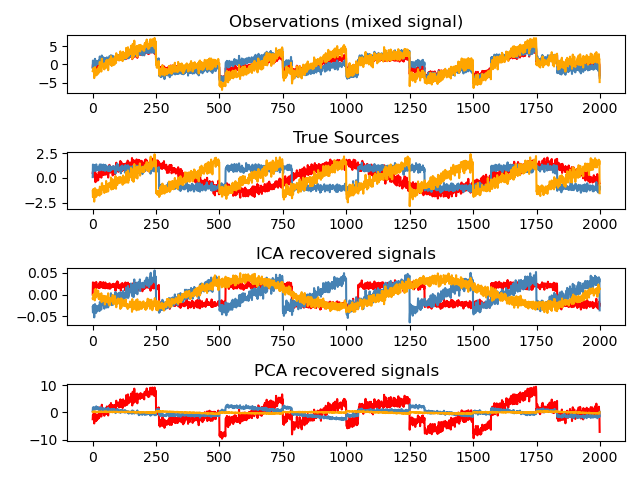
ICA 還可以用作另一種非線性分解方法,它可以找到具有某些稀疏性的成分。

範例
2.5.7. 非負矩陣分解 (NMF 或 NNMF)#
2.5.7.1. 使用弗羅貝尼烏斯範數的 NMF#
NMF [1] 是一種替代的分解方法,它假設資料和成分都是非負的。在資料矩陣不包含負值的情況下,可以將 NMF 取代 PCA 或其變體。它透過優化 \(X\) 和矩陣乘積 \(WH\) 之間的距離 \(d\),來找到樣本 \(X\) 分解成兩個非負元素矩陣 \(W\) 和 \(H\) 的方法。最廣泛使用的距離函數是平方弗羅貝尼烏斯範數,它是歐幾里得範數對矩陣的顯然延伸:
與 PCA 不同,向量的表示是通過疊加成分以相加的方式獲得,而不是相減。這種加性模型對於表示影像和文字非常有效。
在 [Hoyer, 2004] [2] 中觀察到,當仔細約束時,NMF 可以產生資料集的基於部分的表示,從而產生可解釋的模型。以下範例顯示了透過 NMF 從 Olivetti 臉部資料集中的影像中找到的 16 個稀疏成分,並與 PCA 的特徵臉進行比較。

init 屬性決定了所應用的初始化方法,這對該方法的效能有很大的影響。NMF 實作了非負雙奇異值分解的方法。NNDSVD [4] 基於兩個 SVD 過程,一個逼近資料矩陣,另一個利用單位秩矩陣的代數性質來逼近所得部分 SVD 因子的正值部分。基本的 NNDSVD 演算法更適合稀疏分解。其變體 NNDSVDa(其中所有零都設定為資料中所有元素的平均值)和 NNDSVDar(其中零設定為小於資料平均值除以 100 的隨機擾動)在密集情況下是建議的。
請注意,乘法更新 ( 'mu') 求解器無法更新初始化中存在的零,因此當與引入大量零的基本 NNDSVD 演算法一起使用時,會導致較差的結果;在這種情況下,應優先選擇 NNDSVDa 或 NNDSVDar。
也可以透過設定 init="random",使用正確縮放的隨機非負矩陣來初始化 NMF。整數種子或 RandomState 也可以傳遞給 random_state 以控制可重複性。
在 NMF 中,可以將 L1 和 L2 先驗加到損失函數中,以便對模型進行正規化。L2 先驗使用弗羅貝尼烏斯範數,而 L1 先驗使用逐元素的 L1 範數。如同 ElasticNet 一樣,我們使用 l1_ratio (\(\rho\)) 參數來控制 L1 和 L2 的組合,並使用 alpha_W 和 alpha_H (\(\alpha_W\) 和 \(\alpha_H\)) 參數來控制正規化的強度。先驗值按樣本數 (\(n\_samples\)) 針對 H 和特徵數 (\(n\_features\)) 針對 W 進行縮放,以便盡可能地保持它們彼此之間以及與資料擬合項的影響平衡,使其獨立於訓練集的大小。那麼,先驗項為:
且正規化的目標函數為:
2.5.7.2. 使用 beta 散度的 NMF#
如前所述,最廣泛使用的距離函數是平方 Frobenius 範數,它是歐幾里得範數對矩陣的明顯擴展。
其他距離函數也可以在 NMF 中使用,例如,(廣義)Kullback-Leibler (KL) 散度,也稱為 I 散度
或者,Itakura-Saito (IS) 散度
這三個距離是 beta 散度系列的特例,分別對應 \(\beta = 2, 1, 0\) [6]。 beta 散度的定義為:
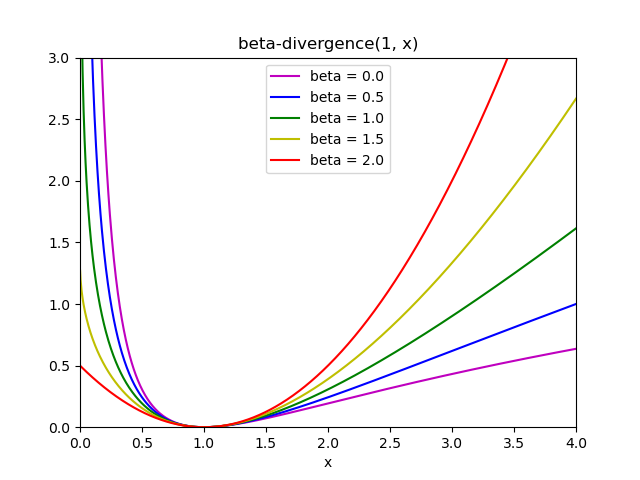
請注意,如果 \(\beta \in (0; 1)\),此定義無效,但它可以連續擴展到 \(d_{KL}\) 和 \(d_{IS}\) 的定義。
NMF 已實作的求解器#
NMF 實作了兩個求解器,分別使用座標下降法 ('cd') [5] 和乘法更新法 ('mu') [6]。 'mu' 求解器可以優化每個 beta 散度,當然包括 Frobenius 範數 (\(\beta=2\))、(廣義)Kullback-Leibler 散度 (\(\beta=1\)) 和 Itakura-Saito 散度 (\(\beta=0\))。 請注意,對於 \(\beta \in (1; 2)\),'mu' 求解器的速度明顯快於其他 \(\beta\) 值。 還請注意,對於負值(或 0,即 'itakura-saito')\(\beta\),輸入矩陣不能包含零值。
'cd' 求解器只能優化 Frobenius 範數。由於 NMF 的底層非凸性,即使在優化相同的距離函數時,不同的求解器也可能會收斂到不同的最小值。
NMF 最好與 fit_transform 方法一起使用,該方法會回傳矩陣 W。矩陣 H 儲存在已擬合模型中的 components_ 屬性中;方法 transform 將根據這些儲存的成分分解新的矩陣 X_new。
>>> import numpy as np
>>> X = np.array([[1, 1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
>>> from sklearn.decomposition import NMF
>>> model = NMF(n_components=2, init='random', random_state=0)
>>> W = model.fit_transform(X)
>>> H = model.components_
>>> X_new = np.array([[1, 0], [1, 6.1], [1, 0], [1, 4], [3.2, 1], [0, 4]])
>>> W_new = model.transform(X_new)
範例
2.5.7.3. 小批次非負矩陣分解#
MiniBatchNMF [7] 實作了非負矩陣分解(即 NMF)的更快但準確性較低的版本,更適合大型資料集。
預設情況下,MiniBatchNMF 將資料分成小批次,並透過在指定迭代次數內循環處理小批次,以線上方式優化 NMF 模型。 batch_size 參數控制批次的大小。
為了加速小批次演算法,也可以縮放過去的批次,使其重要性低於新的批次。 這可以透過引入由 forget_factor 參數控制的所謂遺忘因子來實現。
估計器還實作了 partial_fit,它只迭代一個小批次來更新 H。 當資料無法從頭開始立即取得,或當資料不適合放入記憶體時,這可以用於線上學習。
參考文獻
2.5.8. 潛在狄利克雷分配 (LDA)#
潛在狄利克雷分配是一種用於離散資料集(如文字語料庫)集合的生成機率模型。 它也是一種主題模型,用於從文檔集合中發現抽象主題。
LDA 的圖形模型是三層生成模型

關於上述圖形模型中顯示的符號,可以在 Hoffman 等人 (2013) 中找到。
語料庫是 \(D\) 個文檔的集合。
一個文檔是一連串 \(N\) 個詞。
語料庫中有 \(K\) 個主題。
方框表示重複取樣。
在圖形模型中,每個節點都是一個隨機變數,並在生成過程中扮演角色。 陰影節點表示可觀察的變數,而未陰影節點表示隱藏(潛在)的變數。 在此情況下,語料庫中的詞是我們觀察到的唯一資料。 潛在變數決定了語料庫中主題的隨機混合以及文檔中詞的分布。 LDA 的目標是使用觀察到的詞來推斷隱藏的主題結構。
關於文字語料庫建模的詳細資訊#
在對文字語料庫建模時,該模型假設具有 \(D\) 個文檔和 \(K\) 個主題的語料庫的下列生成過程,其中 \(K\) 對應於 API 中的 n_components。
對於每個主題 \(k \in K\),繪製 \(\beta_k \sim \mathrm{Dirichlet}(\eta)\)。 這提供了詞的分布,即詞出現在主題 \(k\) 中的機率。 \(\eta\) 對應於
topic_word_prior。對於每個文檔 \(d \in D\),繪製主題比例 \(\theta_d \sim \mathrm{Dirichlet}(\alpha)\)。 \(\alpha\) 對應於
doc_topic_prior。對於文檔 \(d\) 中的每個詞 \(i\)
繪製主題指派 \(z_{di} \sim \mathrm{Multinomial} (\theta_d)\)
繪製觀察到的詞 \(w_{ij} \sim \mathrm{Multinomial} (\beta_{z_{di}})\)
對於參數估計,後驗分布為
由於後驗分佈難以處理,變分貝氏方法使用較簡單的分布 \(q(z,\theta,\beta | \lambda, \phi, \gamma)\) 來近似它,並且這些變分參數 \(\lambda\)、\(\phi\)、\(\gamma\) 會被最佳化以最大化證據下界 (ELBO)
最大化 ELBO 等於最小化 \(q(z,\theta,\beta)\) 與真實後驗 \(p(z, \theta, \beta |w, \alpha, \eta)\) 之間的 Kullback-Leibler(KL) 散度。
LatentDirichletAllocation 實作了線上變分貝氏演算法,並支援線上和批次更新方法。 雖然批次方法會在每次完整傳遞資料後更新變分變數,但線上方法會從小批次資料點更新變分變數。
注意
雖然線上方法保證收斂到局部最佳點,但最佳點的品質和收斂速度可能取決於小批次大小和與學習率設定相關的屬性。
當 LatentDirichletAllocation 應用於「文件-詞彙」矩陣時,該矩陣將被分解為「主題-詞彙」矩陣和「文件-主題」矩陣。「主題-詞彙」矩陣會以 components_ 的形式儲存在模型中,而「文件-主題」矩陣則可以從 transform 方法計算得出。
LatentDirichletAllocation 也實作了 partial_fit 方法。當資料可以依序取得時,會使用這個方法。
範例
參考文獻
“潛在狄利克雷分配” D. Blei, A. Ng, M. Jordan, 2003
“潛在狄利克雷分配的線上學習” M. Hoffman, D. Blei, F. Bach, 2010
“隨機變分推論” M. Hoffman, D. Blei, C. Wang, J. Paisley, 2013
“因子分析中用於解析旋轉的 varimax 準則” H. F. Kaiser, 1958
另請參閱降維,了解如何使用鄰域成分分析進行降維。