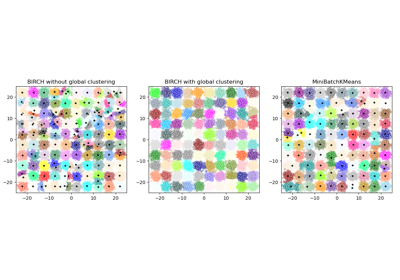
Birch#
- class sklearn.cluster.Birch(*, threshold=0.5, branching_factor=50, n_clusters=3, compute_labels=True, copy='deprecated')[原始碼]#
實作 BIRCH 分群演算法。
它是一種記憶體效率高、線上學習演算法,作為
MiniBatchKMeans的替代方案。它構建一個樹狀資料結構,叢集質心從葉節點讀取。這些可以是最終叢集質心,也可以作為其他分群演算法(例如AgglomerativeClustering)的輸入。在 使用者指南 中閱讀更多內容。
在 0.16 版本中新增。
- 參數:
- thresholdfloat,預設值為 0.5
透過合併一個新的樣本和最近的子叢集而獲得的子叢集半徑應小於閾值。否則會啟動一個新的子叢集。將此值設定為非常低會促進分裂,反之亦然。
- branching_factorint,預設值為 50
每個節點中 CF 子叢集的最大數量。如果新的樣本進入,使得子叢集的數量超過 branching_factor,則該節點會分裂成兩個節點,並在每個節點中重新分配子叢集。該節點的父子叢集會被刪除,並新增兩個新的子叢集作為 2 個分裂節點的父節點。
- n_clustersint,sklearn.cluster 模型或 None 的實例,預設值為 3
最終分群步驟後的叢集數量,將葉節點的子叢集視為新的樣本。
None:不執行最終分群步驟,並按原樣傳回子叢集。sklearn.clusterEstimator:如果提供模型,則該模型會擬合,將子叢集視為新樣本,並將初始資料對應到最近的子叢集的標籤。int:模型擬合是AgglomerativeClustering,且n_clusters設定為等於整數。
- compute_labelsbool,預設值為 True
是否為每個擬合計算標籤。
- copybool,預設值為 True
是否複製給定的資料。如果設定為 False,則會覆寫初始資料。
自 1.6 版起棄用:
copy在 1.6 版中已棄用,並將在 1.8 版中移除。由於估計器不會對輸入資料執行就地操作,因此沒有任何作用。
- 屬性:
- root__CFNode
CFTree 的根目錄。
- dummy_leaf__CFNode
指向所有葉節點的起始指標。
- subcluster_centers_ndarray
直接從葉節點讀取的所有子叢集的質心。
- subcluster_labels_ndarray
在全域叢集化後指派給子叢集質心的標籤。
- labels_形狀為 (n_samples,) 的 ndarray
指派給輸入資料的標籤陣列。如果使用 partial_fit 而非 fit,則會指派給最後一批資料。
- n_features_in_int
在 fit 期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時才定義。在 1.0 版本中新增。
另請參閱
MiniBatchKMeans替代實作,使用小批量資料增量更新質心的位置。
注意事項
樹狀資料結構由節點組成,每個節點由多個子叢集組成。節點中子叢集的最大數量由分支因素決定。每個子叢集維護線性總和、平方和以及該子叢集中樣本的數量。此外,如果子叢集不是葉節點的成員,則每個子叢集也可以將節點作為其子節點。
對於進入根目錄的新點,它會與最接近它的子叢集合併,並更新該子叢集的線性總和、平方和和樣本數量。重複執行此操作,直到更新葉節點的屬性。
請參閱 比較 BIRCH 和 MiniBatchKMeans,以比較與
MiniBatchKMeans的差異。參考文獻
Tian Zhang、Raghu Ramakrishnan、Maron Livny BIRCH:一種用於大型資料庫的高效資料叢集方法。https://www.cs.sfu.ca/CourseCentral/459/han/papers/zhang96.pdf
Roberto Perdisci JBirch - BIRCH 分群演算法的 Java 實作 https://code.google.com/archive/p/jbirch
範例
>>> from sklearn.cluster import Birch >>> X = [[0, 1], [0.3, 1], [-0.3, 1], [0, -1], [0.3, -1], [-0.3, -1]] >>> brc = Birch(n_clusters=None) >>> brc.fit(X) Birch(n_clusters=None) >>> brc.predict(X) array([0, 0, 0, 1, 1, 1])
- fit(X, y=None)[原始碼]#
為輸入資料建置 CF 樹。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features)
輸入資料。
- y忽略
不使用,此處為了 API 一致性而存在。
- 回傳值:
- self
已擬合的估計器。
- fit_predict(X, y=None, **kwargs)[原始碼]#
對
X執行分群並回傳群集標籤。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入資料。
- y忽略
不使用,此處為了 API 一致性而存在。
- **kwargsdict
要傳遞給
fit的引數。在 1.4 版本中加入。
- 回傳值:
- labels形狀為 (n_samples,) 的 ndarray,dtype=np.int64
群集標籤。
- fit_transform(X, y=None, **fit_params)[原始碼]#
擬合資料,然後轉換資料。
使用可選參數
fit_params將轉換器擬合到X和y,並回傳轉換後的X版本。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
輸入樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列,預設為 None
目標值(對於無監督轉換為 None)。
- **fit_paramsdict
額外的擬合參數。
- 回傳值:
- X_new形狀為 (n_samples, n_features_new) 的 ndarray 陣列
轉換後的陣列。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換的輸出特徵名稱。
輸出特徵名稱會以小寫的類別名稱作為前綴。例如,如果轉換器輸出 3 個特徵,則輸出特徵名稱為:
["class_name0", "class_name1", "class_name2"]。- 參數:
- input_features字串類陣列或 None,預設為 None
僅用於驗證特徵名稱是否與
fit中看到的名稱一致。
- 回傳值:
- feature_names_out字串物件的 ndarray
轉換後的特徵名稱。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用者指南 了解路由機制的運作方式。
- 回傳值:
- routingMetadataRequest
一個封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設為 True
如果為 True,將回傳此估計器的參數以及所包含的子物件(也是估計器)的參數。
- 回傳值:
- paramsdict
參數名稱對應到其值的字典。
- partial_fit(X=None, y=None)[原始碼]#
線上學習。防止從頭開始重建 CFTree。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features),預設為 None
輸入資料。如果未提供 X,則只會執行全域分群步驟。
- y忽略
不使用,此處為了 API 一致性而存在。
- 回傳值:
- self
已擬合的估計器。
- predict(X)[原始碼]#
使用子群集的
centroids_預測資料。避免計算 X 的列範數。
- 參數:
- X{類陣列, 稀疏矩陣},形狀為 (n_samples, n_features)
輸入資料。
- 回傳值:
- labels形狀為 (n_samples,) 的 ndarray
已標記的資料。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
請參閱 Introducing the set_output API 以取得如何使用 API 的範例。
- 參數:
- transform{“default”, “pandas”, “polars”},預設為 None
設定
transform和fit_transform的輸出。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換設定保持不變
在 1.4 版本中加入:已加入
"polars"選項。
- 回傳值:
- self估計器實例
估計器實例。