注意
前往末尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
核嶺迴歸與 SVR 的比較#
核嶺迴歸 (KRR) 和 SVR 都透過使用核技巧來學習非線性函數,也就是說,它們在各自核所誘導的空間中學習線性函數,這對應於原始空間中的非線性函數。它們在損失函數(嶺與 epsilon 不敏感損失)方面有所不同。與 SVR 相比,KRR 的擬合可以閉合形式完成,對於中型資料集來說通常速度更快。另一方面,學習到的模型是非稀疏的,因此在預測時比 SVR 慢。
此範例說明了在人工資料集上的兩種方法,該資料集由正弦目標函數和添加到每第五個資料點的強雜訊組成。
作者:scikit-learn 開發人員 SPDX-License-Identifier: BSD-3-Clause
產生樣本資料#
import numpy as np
rng = np.random.RandomState(42)
X = 5 * rng.rand(10000, 1)
y = np.sin(X).ravel()
# Add noise to targets
y[::5] += 3 * (0.5 - rng.rand(X.shape[0] // 5))
X_plot = np.linspace(0, 5, 100000)[:, None]
建構基於核的迴歸模型#
from sklearn.kernel_ridge import KernelRidge
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVR
train_size = 100
svr = GridSearchCV(
SVR(kernel="rbf", gamma=0.1),
param_grid={"C": [1e0, 1e1, 1e2, 1e3], "gamma": np.logspace(-2, 2, 5)},
)
kr = GridSearchCV(
KernelRidge(kernel="rbf", gamma=0.1),
param_grid={"alpha": [1e0, 0.1, 1e-2, 1e-3], "gamma": np.logspace(-2, 2, 5)},
)
比較 SVR 和核嶺迴歸的時間#
import time
t0 = time.time()
svr.fit(X[:train_size], y[:train_size])
svr_fit = time.time() - t0
print(f"Best SVR with params: {svr.best_params_} and R2 score: {svr.best_score_:.3f}")
print("SVR complexity and bandwidth selected and model fitted in %.3f s" % svr_fit)
t0 = time.time()
kr.fit(X[:train_size], y[:train_size])
kr_fit = time.time() - t0
print(f"Best KRR with params: {kr.best_params_} and R2 score: {kr.best_score_:.3f}")
print("KRR complexity and bandwidth selected and model fitted in %.3f s" % kr_fit)
sv_ratio = svr.best_estimator_.support_.shape[0] / train_size
print("Support vector ratio: %.3f" % sv_ratio)
t0 = time.time()
y_svr = svr.predict(X_plot)
svr_predict = time.time() - t0
print("SVR prediction for %d inputs in %.3f s" % (X_plot.shape[0], svr_predict))
t0 = time.time()
y_kr = kr.predict(X_plot)
kr_predict = time.time() - t0
print("KRR prediction for %d inputs in %.3f s" % (X_plot.shape[0], kr_predict))
Best SVR with params: {'C': 1.0, 'gamma': np.float64(0.1)} and R2 score: 0.737
SVR complexity and bandwidth selected and model fitted in 0.535 s
Best KRR with params: {'alpha': 0.1, 'gamma': np.float64(0.1)} and R2 score: 0.723
KRR complexity and bandwidth selected and model fitted in 0.217 s
Support vector ratio: 0.340
SVR prediction for 100000 inputs in 0.112 s
KRR prediction for 100000 inputs in 0.102 s
查看結果#
import matplotlib.pyplot as plt
sv_ind = svr.best_estimator_.support_
plt.scatter(
X[sv_ind],
y[sv_ind],
c="r",
s=50,
label="SVR support vectors",
zorder=2,
edgecolors=(0, 0, 0),
)
plt.scatter(X[:100], y[:100], c="k", label="data", zorder=1, edgecolors=(0, 0, 0))
plt.plot(
X_plot,
y_svr,
c="r",
label="SVR (fit: %.3fs, predict: %.3fs)" % (svr_fit, svr_predict),
)
plt.plot(
X_plot, y_kr, c="g", label="KRR (fit: %.3fs, predict: %.3fs)" % (kr_fit, kr_predict)
)
plt.xlabel("data")
plt.ylabel("target")
plt.title("SVR versus Kernel Ridge")
_ = plt.legend()
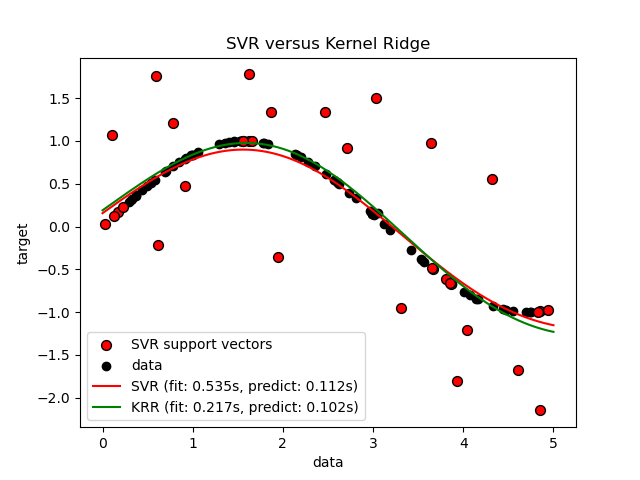
上圖比較了當使用網格搜尋最佳化 RBF 核心的複雜度/正規化和頻寬時,KRR 和 SVR 的學習模型。學習到的函數非常相似;但是,擬合 KRR 的速度比擬合 SVR 快約 3-4 倍(兩者都使用網格搜尋)。
理論上,使用 SVR 預測 100000 個目標值可能會快約三倍,因為它使用僅約 1/3 的訓練資料點作為支持向量學習了一個稀疏模型。然而,實際上,情況不一定是這樣,因為每個模型計算核函數的方式的實作細節可能會使 KRR 模型速度與執行更多算術運算的 KRR 模型一樣快甚至更快。
視覺化訓練和預測時間#
plt.figure()
sizes = np.logspace(1, 3.8, 7).astype(int)
for name, estimator in {
"KRR": KernelRidge(kernel="rbf", alpha=0.01, gamma=10),
"SVR": SVR(kernel="rbf", C=1e2, gamma=10),
}.items():
train_time = []
test_time = []
for train_test_size in sizes:
t0 = time.time()
estimator.fit(X[:train_test_size], y[:train_test_size])
train_time.append(time.time() - t0)
t0 = time.time()
estimator.predict(X_plot[:1000])
test_time.append(time.time() - t0)
plt.plot(
sizes,
train_time,
"o-",
color="r" if name == "SVR" else "g",
label="%s (train)" % name,
)
plt.plot(
sizes,
test_time,
"o--",
color="r" if name == "SVR" else "g",
label="%s (test)" % name,
)
plt.xscale("log")
plt.yscale("log")
plt.xlabel("Train size")
plt.ylabel("Time (seconds)")
plt.title("Execution Time")
_ = plt.legend(loc="best")
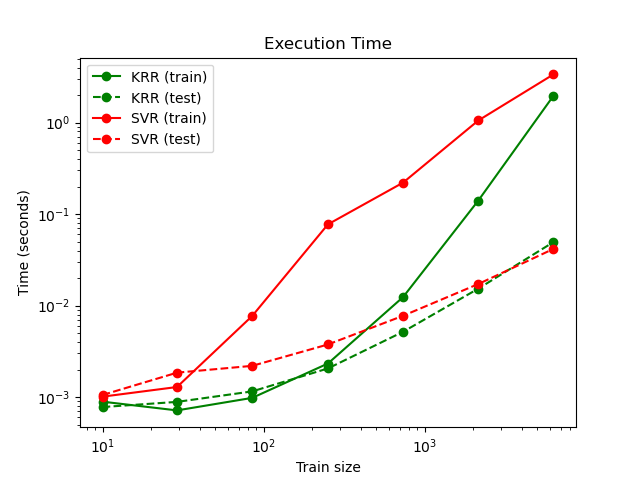
此圖比較了 KRR 和 SVR 在不同大小的訓練集下的擬合和預測時間。對於中型訓練集(少於幾千個樣本),擬合 KRR 比 SVR 快;但是,對於較大的訓練集,SVR 的擴展性更好。關於預測時間,由於學習到的稀疏解決方案,SVR 在所有訓練集大小下都應該比 KRR 快,但是由於實作細節,在實踐中情況不一定是這樣。請注意,稀疏程度以及預測時間取決於 SVR 的參數 epsilon 和 C。
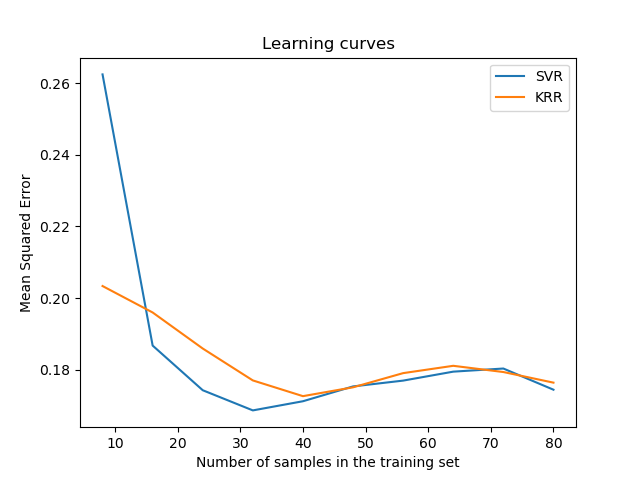
視覺化學習曲線#
from sklearn.model_selection import LearningCurveDisplay
_, ax = plt.subplots()
svr = SVR(kernel="rbf", C=1e1, gamma=0.1)
kr = KernelRidge(kernel="rbf", alpha=0.1, gamma=0.1)
common_params = {
"X": X[:100],
"y": y[:100],
"train_sizes": np.linspace(0.1, 1, 10),
"scoring": "neg_mean_squared_error",
"negate_score": True,
"score_name": "Mean Squared Error",
"score_type": "test",
"std_display_style": None,
"ax": ax,
}
LearningCurveDisplay.from_estimator(svr, **common_params)
LearningCurveDisplay.from_estimator(kr, **common_params)
ax.set_title("Learning curves")
ax.legend(handles=ax.get_legend_handles_labels()[0], labels=["SVR", "KRR"])
plt.show()
腳本的總執行時間: (0 分鐘 8.701 秒)
相關範例