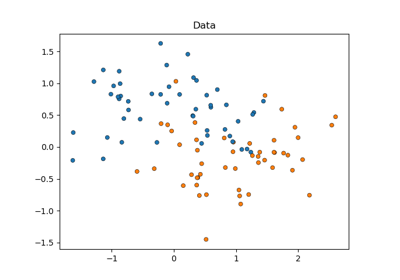
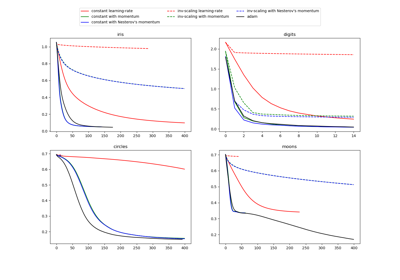
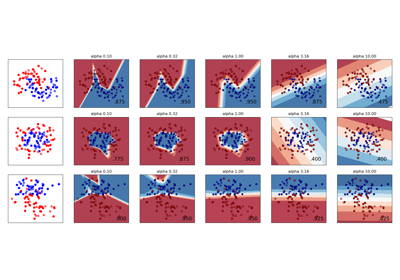
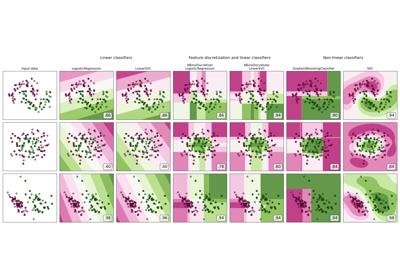
make_moons#
- sklearn.datasets.make_moons(n_samples=100, *, shuffle=True, noise=None, random_state=None)[原始碼]#
產生兩個交錯的半圓形。
一個簡單的玩具資料集,用於視覺化分群和分類演算法。更多資訊請參閱使用者指南。
- 參數:
- n_samplesint 或 shape 為 (2,) 的 tuple,dtype=int,預設值為 100
如果為 int,則表示產生的總點數。如果為雙元素 tuple,則表示兩個半圓形中各自的點數。
在 0.23 版本中變更: 新增雙元素 tuple。
- shufflebool,預設值為 True
是否打亂樣本。
- noisefloat,預設值為 None
新增至資料的高斯雜訊的標準差。
- random_stateint、RandomState 實例或 None,預設值為 None
決定資料集打亂和雜訊的隨機數產生。傳遞一個 int 以便在多次函式呼叫中產生可重現的輸出。請參閱詞彙表。
- 回傳值:
- Xshape 為 (n_samples, 2) 的 ndarray
產生的樣本。
- yshape 為 (n_samples,) 的 ndarray
每個樣本的類別成員的整數標籤 (0 或 1)。
範例
>>> from sklearn.datasets import make_moons >>> X, y = make_moons(n_samples=200, noise=0.2, random_state=42) >>> X.shape (200, 2) >>> y.shape (200,)