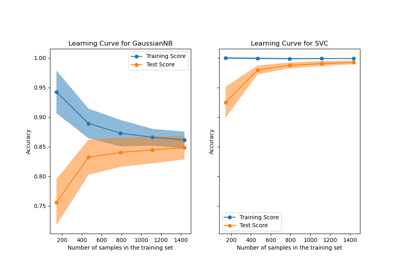
LearningCurveDisplay#
- class sklearn.model_selection.LearningCurveDisplay(*, train_sizes, train_scores, test_scores, score_name=None)[原始碼]#
學習曲線視覺化。
建議使用
from_estimator來建立LearningCurveDisplay的實例。所有參數都儲存為屬性。在 使用者指南 中閱讀更多關於視覺化 API 的一般資訊,以及關於學習曲線視覺化的 詳細文件。
在版本 1.2 中新增。
- 參數:
- train_sizesndarray,形狀為 (n_unique_ticks,)
用於產生學習曲線的訓練樣本數量。
- train_scoresndarray,形狀為 (n_ticks, n_cv_folds)
在訓練集上的分數。
- test_scoresndarray,形狀為 (n_ticks, n_cv_folds)
在測試集上的分數。
- score_namestr,預設值為 None
在
learning_curve中使用的分數名稱。它將覆蓋從scoring參數推斷的名稱。如果score為None,如果negate_score為False,則使用"Score",否則使用"Negative score"。如果scoring是一個字串或可呼叫物件,我們會推斷名稱。我們會將_替換為空格,並將第一個字母大寫。如果negate_score為False,則移除neg_並替換為"Negative",否則直接移除。
- 屬性:
- ax_matplotlib Axes
帶有學習曲線的軸。
- figure_matplotlib Figure
包含學習曲線的圖表。
- errorbar_matplotlib Artist 或 None 的列表
當
std_display_style為"errorbar"時,這是一個matplotlib.container.ErrorbarContainer物件的列表。如果使用其他樣式,則errorbar_為None。- lines_matplotlib Artist 或 None 的列表
當
std_display_style為"fill_between"時,這是對應於平均訓練和測試分數的matplotlib.lines.Line2D物件的列表。如果使用其他樣式,則line_為None。- fill_between_matplotlib Artist 或 None 的列表
當
std_display_style為"fill_between"時,這是一個matplotlib.collections.PolyCollection物件的列表。如果使用其他樣式,則fill_between_為None。
參見
範例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import LearningCurveDisplay, learning_curve >>> from sklearn.tree import DecisionTreeClassifier >>> X, y = load_iris(return_X_y=True) >>> tree = DecisionTreeClassifier(random_state=0) >>> train_sizes, train_scores, test_scores = learning_curve( ... tree, X, y) >>> display = LearningCurveDisplay(train_sizes=train_sizes, ... train_scores=train_scores, test_scores=test_scores, score_name="Score") >>> display.plot() <...> >>> plt.show()
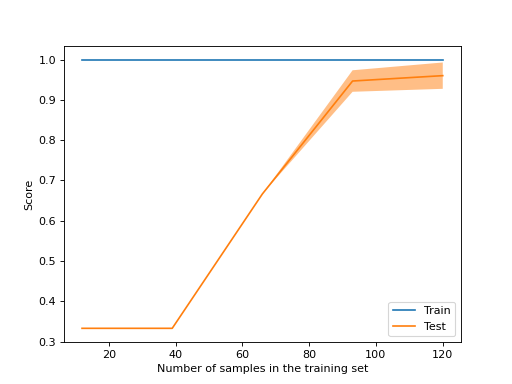
- classmethod from_estimator(estimator, X, y, *, groups=None, train_sizes=array([0.1, 0.33, 0.55, 0.78, 1.]), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=None, pre_dispatch='all', verbose=0, shuffle=False, random_state=None, error_score=nan, fit_params=None, ax=None, negate_score=False, score_name=None, score_type='both', std_display_style='fill_between', line_kw=None, fill_between_kw=None, errorbar_kw=None)[原始碼]#
從估計器建立學習曲線顯示。
在 使用者指南 中閱讀更多關於視覺化 API 的一般資訊,以及關於學習曲線視覺化的 詳細文件。
- 參數:
- estimator實作「fit」和「predict」方法的物件類型
此類型的物件會針對每個驗證進行複製。
- X形狀為 (n_samples, n_features) 的類陣列
訓練資料,其中
n_samples是樣本數,而n_features是特徵數。- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列,或 None
分類或迴歸時相對於 X 的目標;無監督學習則為 None。
- groups形狀為 (n_samples,) 的類陣列,預設值為 None
將資料集分割為訓練/測試集時使用的樣本組別標籤。僅與「Group」cv 實例(例如,
GroupKFold)搭配使用。- train_sizes形狀為 (n_ticks,) 的類陣列,預設值為 np.linspace(0.1, 1.0, 5)
將用於產生學習曲線的訓練範例的相對或絕對數量。如果 dtype 是 float,則會將其視為訓練集最大大小(由選定的驗證方法決定)的分數,即必須在 (0, 1] 範圍內。否則,會將其解釋為訓練集的絕對大小。請注意,對於分類,樣本數量通常必須足夠大,才能包含每個類別的至少一個樣本。
- cvint、交叉驗證產生器或可迭代物件,預設值為 None
決定交叉驗證分割策略。cv 的可能輸入為
None,使用預設的 5 折交叉驗證,
int,指定
(Stratified)KFold中的折數,一個可迭代物件,產生 (train, test) 分割作為索引陣列。
對於 int/None 輸入,如果估計器是分類器且
y是二元或多類,則使用StratifiedKFold。在所有其他情況下,則使用KFold。這些分割器會以shuffle=False實例化,因此分割在呼叫之間將會相同。請參閱使用者指南,以了解此處可以使用的各種交叉驗證策略。
- scoringstr 或可呼叫物件,預設值為 None
字串(請參閱評分參數:定義模型評估規則)或具有簽名
scorer(estimator, X, y)的評分器可呼叫物件/函式(請參閱可呼叫的評分器)。- exploit_incremental_learningbool,預設值為 False
如果估計器支援增量學習,則會使用此方法來加速不同訓練集大小的擬合。
- n_jobsint,預設值為 None
要並行執行的工作數。估計器的訓練和分數計算會在不同的訓練集和測試集上並行化。
None表示 1,除非在joblib.parallel_backend環境中。-1表示使用所有處理器。請參閱詞彙表以了解更多詳細資訊。- pre_dispatchint 或 str,預設值為 'all'
並行執行的預先調度工作數(預設值為 all)。此選項可以減少配置的記憶體。str 可以是像「2*n_jobs」的運算式。
- verboseint,預設值為 0
控制詳細程度:數值越高,訊息越多。
- shufflebool,預設值為 False
是否在根據 `train_sizes` 取得訓練資料的前綴之前,先將其隨機排序。
- random_stateint、RandomState 實例或 None,預設值為 None
當
shuffle為 True 時使用。傳遞 int 以在多個函式呼叫中產生可重現的輸出。請參閱詞彙表。- error_score「raise」或數值,預設值為 np.nan
如果估計器擬合時發生錯誤,則要指派給分數的值。如果設定為「raise」,則會引發錯誤。如果提供數值,則會引發 FitFailedWarning。
- fit_paramsdict,預設值為 None
要傳遞給估計器 fit 方法的參數。
- axmatplotlib Axes,預設值為 None
要繪製的軸物件。如果
None,則會建立新的圖形和軸。- negate_scorebool,預設值為 False
是否要否定透過
learning_curve取得的分數。當在scikit-learn中使用以neg_*表示的錯誤時,這特別有用。- score_namestr,預設值為 None
用於裝飾繪圖的 y 軸的分數名稱。它會覆寫從
scoring參數推斷的名稱。如果score為None,如果negate_score為False,則我們會使用"Score",否則使用"Negative score"。如果scoring是字串或可呼叫物件,則我們會推斷名稱。我們會將_替換為空格,並將第一個字母大寫。如果negate_score為False,則我們會移除neg_並將其替換為"Negative",否則只會將其移除。- score_type{"test", "train", "both"},預設值為 "both"
要繪製的分數類型。可以是
"test"、"train"或"both"其中之一。- std_display_style{"errorbar", "fill_between"} 或 None,預設值為 "fill_between"
用於顯示平均分數周圍的分數標準差的樣式。如果
None,則不會顯示標準差的表示。- line_kwdict,預設值為 None
傳遞給用於繪製平均分數的
plt.plot的其他關鍵字引數。- fill_between_kwdict,預設值為 None
傳遞給用於繪製分數標準差的
plt.fill_between的其他關鍵字引數。- errorbar_kwdict,預設值為 None
傳遞給用於繪製平均分數和標準差分數的
plt.errorbar的其他關鍵字引數。
- 傳回值:
- display
LearningCurveDisplay 儲存計算值的物件。
- display
範例
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_iris >>> from sklearn.model_selection import LearningCurveDisplay >>> from sklearn.tree import DecisionTreeClassifier >>> X, y = load_iris(return_X_y=True) >>> tree = DecisionTreeClassifier(random_state=0) >>> LearningCurveDisplay.from_estimator(tree, X, y) <...> >>> plt.show()
- plot(ax=None, *, negate_score=False, score_name=None, score_type='both', std_display_style='fill_between', line_kw=None, fill_between_kw=None, errorbar_kw=None)[原始碼]#
繪製視覺化圖表。
- 參數:
- axmatplotlib Axes,預設值為 None
要繪製的軸物件。如果
None,則會建立新的圖形和軸。- negate_scorebool,預設值為 False
是否要否定透過
learning_curve取得的分數。當在scikit-learn中使用以neg_*表示的錯誤時,這特別有用。- score_namestr,預設值為 None
用於裝飾繪圖的 y 軸的分數名稱。它會覆寫從
scoring參數推斷的名稱。如果score為None,如果negate_score為False,則我們會使用"Score",否則使用"Negative score"。如果scoring是字串或可呼叫物件,則我們會推斷名稱。我們會將_替換為空格,並將第一個字母大寫。如果negate_score為False,則我們會移除neg_並將其替換為"Negative",否則只會將其移除。- score_type{"test", "train", "both"},預設值為 "both"
要繪製的分數類型。可以是
"test"、"train"或"both"其中之一。- std_display_style{"errorbar", "fill_between"} 或 None,預設值為 "fill_between"
用於顯示平均分數周圍的分數標準差的樣式。如果為 None,則不會顯示標準差表示。
- line_kwdict,預設值為 None
傳遞給用於繪製平均分數的
plt.plot的其他關鍵字引數。- fill_between_kwdict,預設值為 None
傳遞給用於繪製分數標準差的
plt.fill_between的其他關鍵字引數。- errorbar_kwdict,預設值為 None
傳遞給用於繪製平均分數和標準差分數的
plt.errorbar的其他關鍵字引數。
- 傳回值:
- display
LearningCurveDisplay 儲存計算值的物件。
- display