注意
前往結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
繪製學習曲線並檢查模型的可擴展性#
在此範例中,我們展示如何使用 LearningCurveDisplay 類別輕鬆繪製學習曲線。此外,我們針對朴素貝氏和 SVM 分類器取得的學習曲線進行解釋。
然後,我們透過查看它們的計算成本,而不僅僅是它們的統計準確性,來探索並得出關於這些預測模型可擴展性的一些結論。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
學習曲線#
學習曲線顯示在訓練過程中新增更多樣本的效果。此效果是透過檢查模型在訓練分數和測試分數方面的統計效能來描述的。
在此,我們使用數字資料集計算具有 RBF 核的朴素貝氏分類器和 SVM 分類器的學習曲線。
from sklearn.datasets import load_digits
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
X, y = load_digits(return_X_y=True)
naive_bayes = GaussianNB()
svc = SVC(kernel="rbf", gamma=0.001)
from_estimator 會顯示給定資料集和要分析的預測模型的學習曲線。為了獲得分數不確定性的估計值,此方法使用交叉驗證程序。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import LearningCurveDisplay, ShuffleSplit
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 6), sharey=True)
common_params = {
"X": X,
"y": y,
"train_sizes": np.linspace(0.1, 1.0, 5),
"cv": ShuffleSplit(n_splits=50, test_size=0.2, random_state=0),
"score_type": "both",
"n_jobs": 4,
"line_kw": {"marker": "o"},
"std_display_style": "fill_between",
"score_name": "Accuracy",
}
for ax_idx, estimator in enumerate([naive_bayes, svc]):
LearningCurveDisplay.from_estimator(estimator, **common_params, ax=ax[ax_idx])
handles, label = ax[ax_idx].get_legend_handles_labels()
ax[ax_idx].legend(handles[:2], ["Training Score", "Test Score"])
ax[ax_idx].set_title(f"Learning Curve for {estimator.__class__.__name__}")
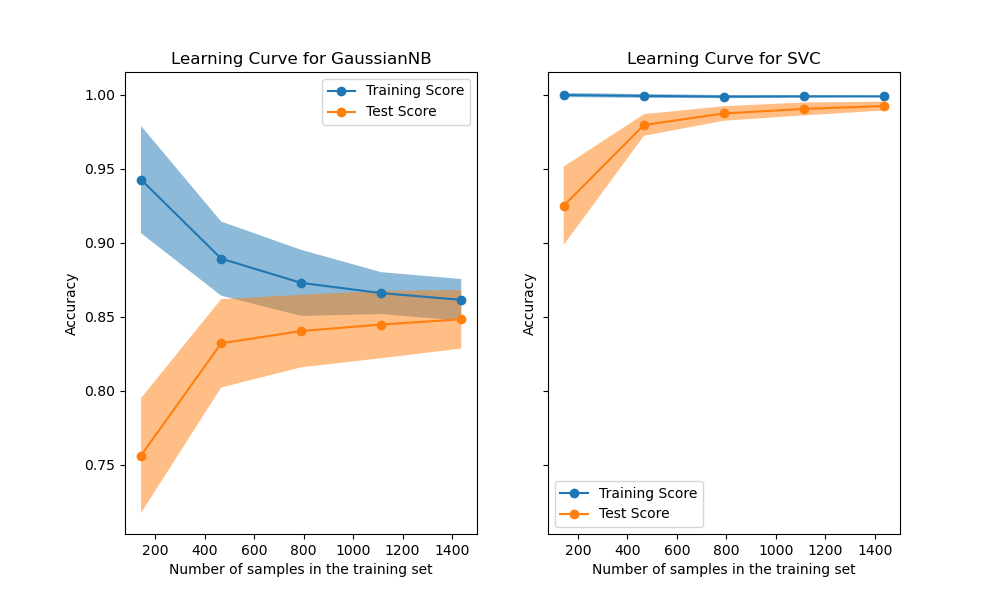
我們首先分析朴素貝氏分類器的學習曲線。其形狀可以在更複雜的資料集中經常發現:當使用少量樣本進行訓練時,訓練分數非常高,並且在增加樣本數量時會降低,而測試分數在一開始非常低,然後在新增樣本時會增加。當所有樣本都用於訓練時,訓練和測試分數會變得更實際。
我們看到具有 RBF 核的 SVM 分類器的另一個典型學習曲線。無論訓練集的大小如何,訓練分數都保持較高。另一方面,測試分數隨著訓練資料集的大小而增加。實際上,它增加到達到平穩期。觀察到這種平穩期表示可能不需要獲取新資料來訓練模型,因為模型的泛化效能不會再增加。
複雜度分析#
除了這些學習曲線外,還可以查看預測模型在訓練和評分時間方面的可擴展性。
LearningCurveDisplay 類別不提供此類資訊。我們需要改用 learning_curve 函數並手動繪製圖表。
from sklearn.model_selection import learning_curve
common_params = {
"X": X,
"y": y,
"train_sizes": np.linspace(0.1, 1.0, 5),
"cv": ShuffleSplit(n_splits=50, test_size=0.2, random_state=0),
"n_jobs": 4,
"return_times": True,
}
train_sizes, _, test_scores_nb, fit_times_nb, score_times_nb = learning_curve(
naive_bayes, **common_params
)
train_sizes, _, test_scores_svm, fit_times_svm, score_times_svm = learning_curve(
svc, **common_params
)
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(16, 12), sharex=True)
for ax_idx, (fit_times, score_times, estimator) in enumerate(
zip(
[fit_times_nb, fit_times_svm],
[score_times_nb, score_times_svm],
[naive_bayes, svc],
)
):
# scalability regarding the fit time
ax[0, ax_idx].plot(train_sizes, fit_times.mean(axis=1), "o-")
ax[0, ax_idx].fill_between(
train_sizes,
fit_times.mean(axis=1) - fit_times.std(axis=1),
fit_times.mean(axis=1) + fit_times.std(axis=1),
alpha=0.3,
)
ax[0, ax_idx].set_ylabel("Fit time (s)")
ax[0, ax_idx].set_title(
f"Scalability of the {estimator.__class__.__name__} classifier"
)
# scalability regarding the score time
ax[1, ax_idx].plot(train_sizes, score_times.mean(axis=1), "o-")
ax[1, ax_idx].fill_between(
train_sizes,
score_times.mean(axis=1) - score_times.std(axis=1),
score_times.mean(axis=1) + score_times.std(axis=1),
alpha=0.3,
)
ax[1, ax_idx].set_ylabel("Score time (s)")
ax[1, ax_idx].set_xlabel("Number of training samples")
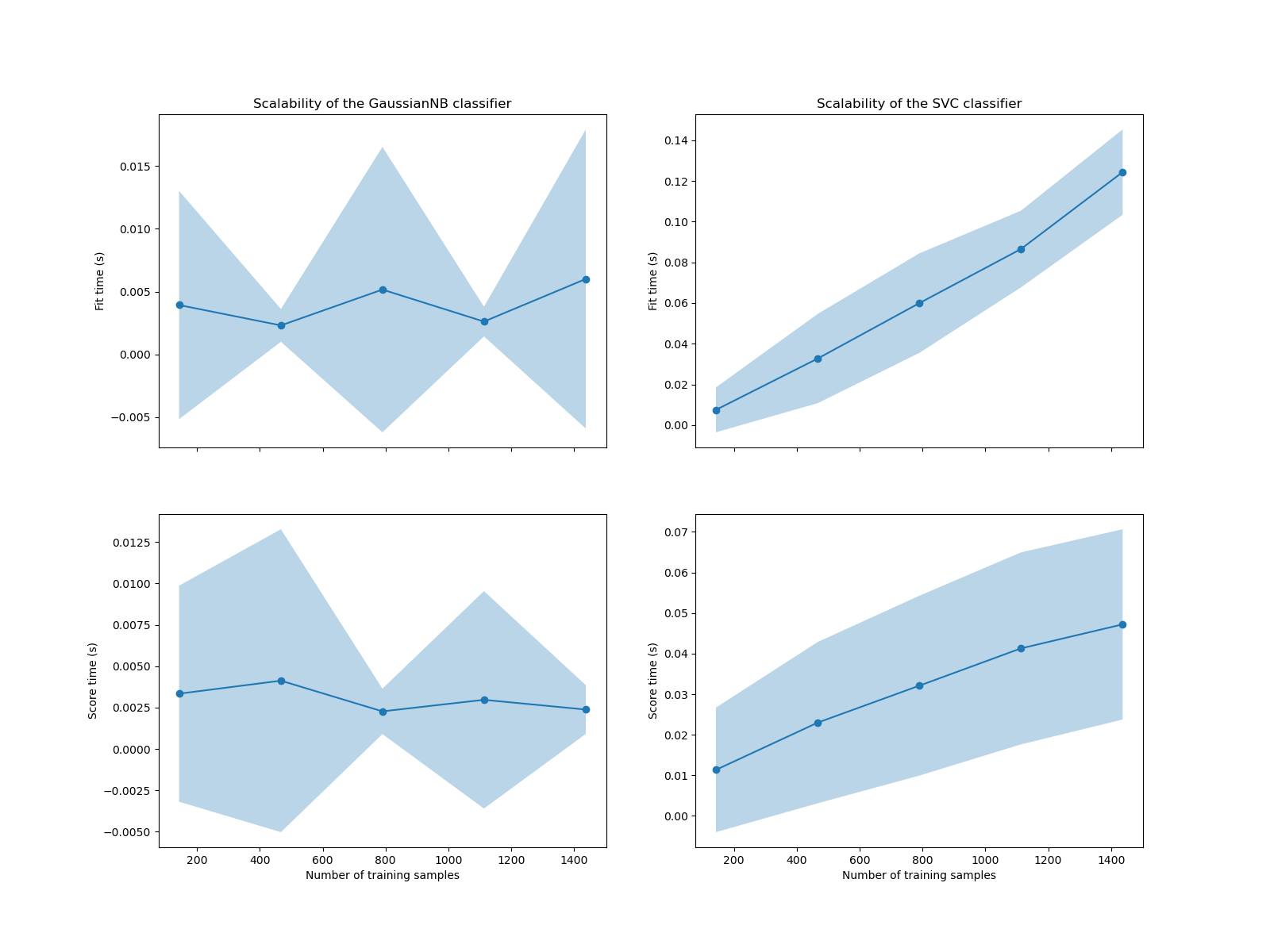
我們看到 SVM 和朴素貝氏分類器的可擴展性非常不同。SVM 分類器在擬合和評分時間的複雜度隨著樣本數量的增加而快速增加。實際上,已知此分類器的擬合時間複雜度與樣本數量呈二次以上關係,這使得它難以擴展到超過幾萬個樣本的資料集。相反地,朴素貝氏分類器在擬合和評分時間的複雜度較低,因此擴展性更好。
隨後,我們可以檢查增加訓練時間和交叉驗證分數之間的權衡。
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(16, 6))
for ax_idx, (fit_times, test_scores, estimator) in enumerate(
zip(
[fit_times_nb, fit_times_svm],
[test_scores_nb, test_scores_svm],
[naive_bayes, svc],
)
):
ax[ax_idx].plot(fit_times.mean(axis=1), test_scores.mean(axis=1), "o-")
ax[ax_idx].fill_between(
fit_times.mean(axis=1),
test_scores.mean(axis=1) - test_scores.std(axis=1),
test_scores.mean(axis=1) + test_scores.std(axis=1),
alpha=0.3,
)
ax[ax_idx].set_ylabel("Accuracy")
ax[ax_idx].set_xlabel("Fit time (s)")
ax[ax_idx].set_title(
f"Performance of the {estimator.__class__.__name__} classifier"
)
plt.show()
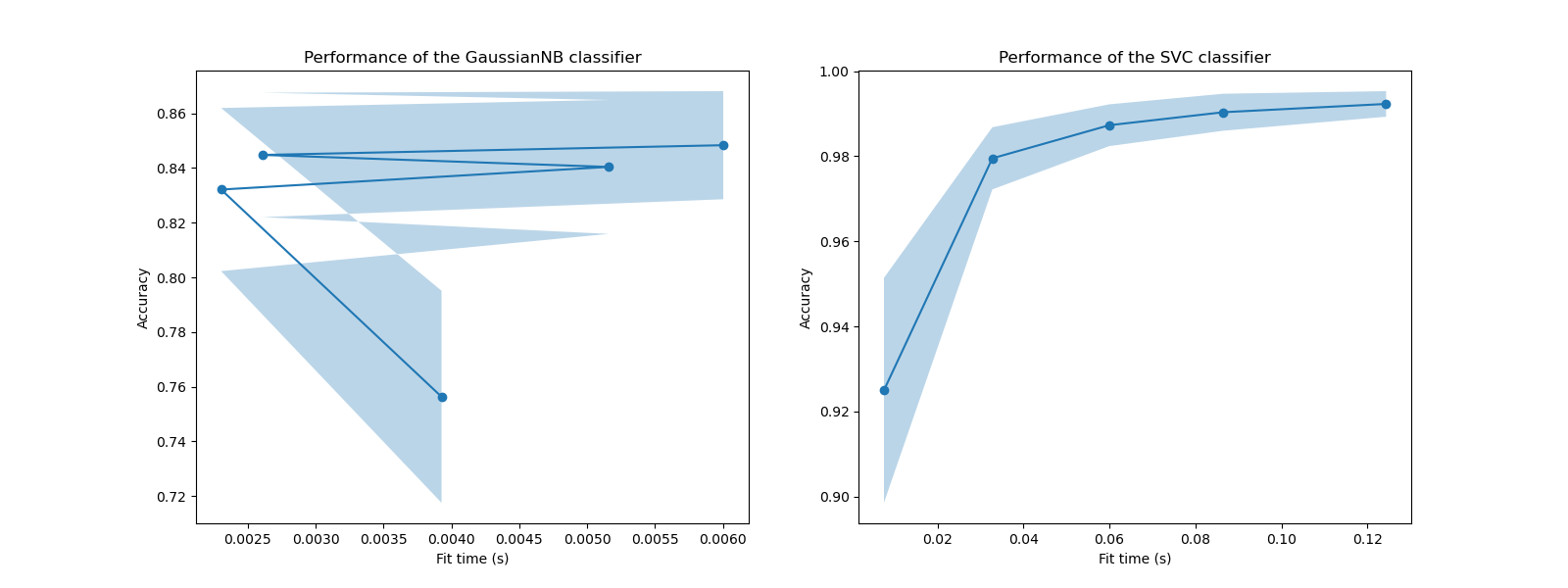
在這些圖表中,我們可以尋找交叉驗證分數不再增加且僅訓練時間增加的轉折點。
腳本總執行時間: (0 分鐘 26.655 秒)
相關範例