注意
前往末尾下載完整範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
稀疏逆共變異數估計#
使用 GraphicalLasso 估計器從少量樣本中學習共變異數和稀疏精確度。
為了估計機率模型(例如,高斯模型),估計精確度矩陣(即逆共變異數矩陣)與估計共變異數矩陣一樣重要。實際上,高斯模型由精確度矩陣參數化。
為了處於有利的恢復條件下,我們從具有稀疏逆共變異數矩陣的模型中採樣資料。此外,我們確保資料不會過度相關(限制精確度矩陣的最大係數),並且精確度矩陣中沒有無法恢復的小係數。此外,由於觀測值數量較少,因此更容易恢復相關矩陣而不是共變異數,因此我們縮放時間序列。
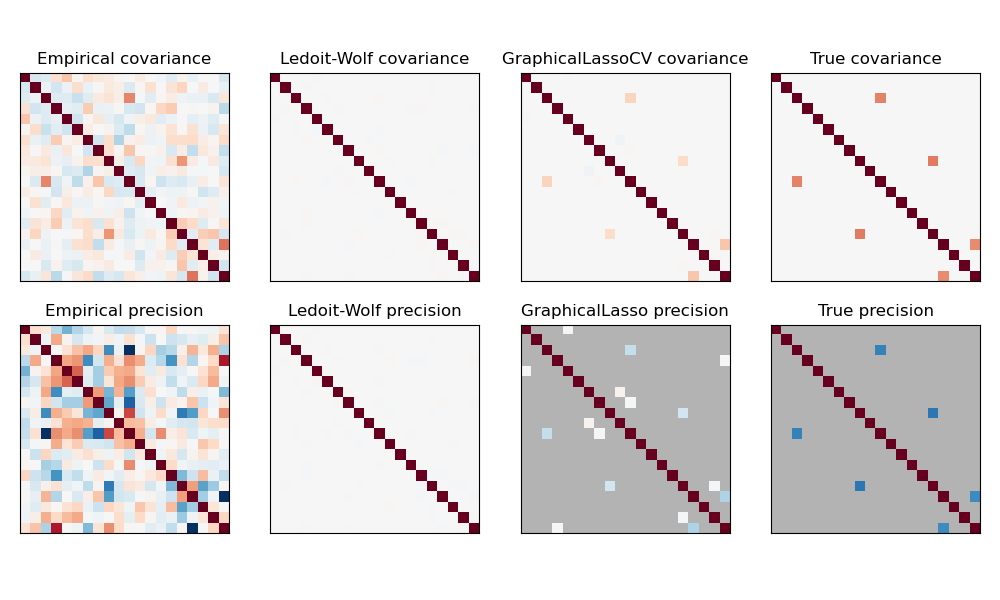
在這裡,樣本數略大於維度數,因此經驗共變異數仍然可逆。然而,由於觀測值高度相關,經驗共變異數矩陣是病態的,因此它的逆矩陣——經驗精確度矩陣——與真實值相差甚遠。
如果我們像 Ledoit-Wolf 估計器一樣使用 l2 收縮,由於樣本數量很少,我們需要大量收縮。因此,Ledoit-Wolf 精確度相當接近真實精確度,即離對角線不遠,但失去了非對角線結構。
l1 懲罰估計器可以恢復部分非對角線結構。它學習稀疏精確度。它無法恢復確切的稀疏模式:它檢測到過多的非零係數。然而,l1 估計的最高非零係數對應於真實值中的非零係數。最後,l1 精確度估計的係數偏向於零:由於懲罰,它們都小於相應的真實值,如圖所示。
請注意,為了提高圖的可讀性,調整了精確度矩陣的顏色範圍。未顯示經驗精確度的完整值範圍。
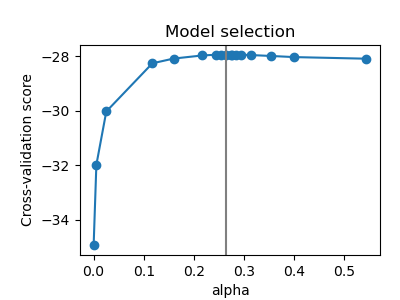
GraphicalLasso 中設定模型稀疏性的 alpha 參數由 GraphicalLassoCV 中的內部交叉驗證設定。如圖 2 所示,計算交叉驗證分數的網格會在最大值的鄰域中迭代改進。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
產生資料#
import numpy as np
from scipy import linalg
from sklearn.datasets import make_sparse_spd_matrix
n_samples = 60
n_features = 20
prng = np.random.RandomState(1)
prec = make_sparse_spd_matrix(
n_features, alpha=0.98, smallest_coef=0.4, largest_coef=0.7, random_state=prng
)
cov = linalg.inv(prec)
d = np.sqrt(np.diag(cov))
cov /= d
cov /= d[:, np.newaxis]
prec *= d
prec *= d[:, np.newaxis]
X = prng.multivariate_normal(np.zeros(n_features), cov, size=n_samples)
X -= X.mean(axis=0)
X /= X.std(axis=0)
估計共變異數#
from sklearn.covariance import GraphicalLassoCV, ledoit_wolf
emp_cov = np.dot(X.T, X) / n_samples
model = GraphicalLassoCV()
model.fit(X)
cov_ = model.covariance_
prec_ = model.precision_
lw_cov_, _ = ledoit_wolf(X)
lw_prec_ = linalg.inv(lw_cov_)
繪製結果#
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.subplots_adjust(left=0.02, right=0.98)
# plot the covariances
covs = [
("Empirical", emp_cov),
("Ledoit-Wolf", lw_cov_),
("GraphicalLassoCV", cov_),
("True", cov),
]
vmax = cov_.max()
for i, (name, this_cov) in enumerate(covs):
plt.subplot(2, 4, i + 1)
plt.imshow(
this_cov, interpolation="nearest", vmin=-vmax, vmax=vmax, cmap=plt.cm.RdBu_r
)
plt.xticks(())
plt.yticks(())
plt.title("%s covariance" % name)
# plot the precisions
precs = [
("Empirical", linalg.inv(emp_cov)),
("Ledoit-Wolf", lw_prec_),
("GraphicalLasso", prec_),
("True", prec),
]
vmax = 0.9 * prec_.max()
for i, (name, this_prec) in enumerate(precs):
ax = plt.subplot(2, 4, i + 5)
plt.imshow(
np.ma.masked_equal(this_prec, 0),
interpolation="nearest",
vmin=-vmax,
vmax=vmax,
cmap=plt.cm.RdBu_r,
)
plt.xticks(())
plt.yticks(())
plt.title("%s precision" % name)
if hasattr(ax, "set_facecolor"):
ax.set_facecolor(".7")
else:
ax.set_axis_bgcolor(".7")
# plot the model selection metric
plt.figure(figsize=(4, 3))
plt.axes([0.2, 0.15, 0.75, 0.7])
plt.plot(model.cv_results_["alphas"], model.cv_results_["mean_test_score"], "o-")
plt.axvline(model.alpha_, color=".5")
plt.title("Model selection")
plt.ylabel("Cross-validation score")
plt.xlabel("alpha")
plt.show()
腳本總執行時間:(0 分鐘 0.476 秒)
相關範例