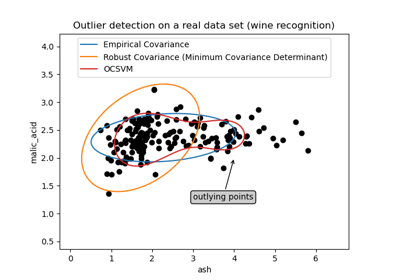
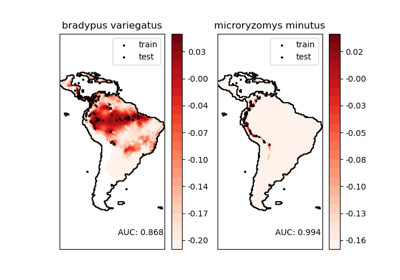
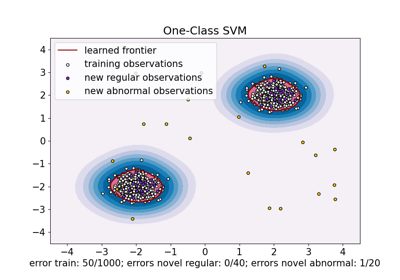
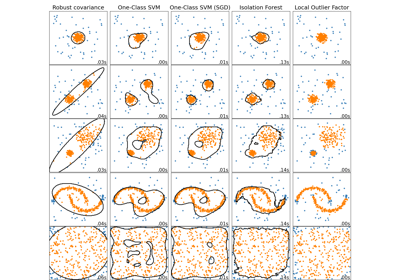
OneClassSVM#
- class sklearn.svm.OneClassSVM(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1)[原始碼]#
非監督式離群值偵測。
估計高維度分佈的支撐。
此實作基於 libsvm。
詳情請參閱使用者指南。
- 參數:
- kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} 或可調用物件, default=’rbf’
指定演算法中使用的核函數類型。如果未指定,將使用 ‘rbf’。如果給定可調用物件,則用於預先計算核矩陣。
- degreeint, default=3
多項式核函數(‘poly’)的次數。必須是非負數。所有其他核函數都會忽略此參數。
- gamma{‘scale’, ‘auto’} 或 float, default=’scale’
用於 ‘rbf’、‘poly’ 和 ‘sigmoid’ 的核函數係數。
如果傳遞
gamma='scale'(預設值),則它會使用 1 / (n_features * X.var()) 作為 gamma 的值,如果為 ‘auto’,則使用 1 / n_features
如果為 float,則必須是非負數。
在 0.22 版變更:
gamma的預設值從 ‘auto’ 變更為 ‘scale’。- coef0float, default=0.0
核函數中的獨立項。它僅在 ‘poly’ 和 ‘sigmoid’ 中有意義。
- tolfloat, default=1e-3
停止條件的容差。
- nufloat, default=0.5
訓練誤差的分數上限和支持向量的分數下限。應該在區間 (0, 1] 中。預設情況下將採用 0.5。
- shrinkingbool, default=True
是否使用縮減啟發式演算法。請參閱使用者指南。
- cache_sizefloat, default=200
指定核心快取的記憶體大小 (以 MB 為單位)。
- verbosebool, default=False
啟用詳細輸出。請注意,此設定會利用 libsvm 中每個處理序的執行階段設定,如果啟用此設定,則可能無法在多執行緒環境中正常運作。
- max_iterint, default=-1
求解器內迭代的硬性限制,如果為 -1,則表示沒有限制。
- 屬性:
coef_形狀為 (1, n_features) 的 ndarray當
kernel="linear"時,分配給特徵的權重。- dual_coef_形狀為 (1, n_SV) 的 ndarray
決策函數中支持向量的係數。
- fit_status_int
如果正確擬合,則為 0,否則為 1(將引發警告)
- intercept_形狀為 (1,) 的 ndarray
決策函數中的常數。
- n_features_in_int
在fit期間看到的特徵數量。
在 0.24 版中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在fit期間看到的特徵名稱。僅當
X具有全部都是字串的特徵名稱時,才會定義。在 1.0 版中新增。
- n_iter_int
執行最佳化常式以擬合模型的迭代次數。
在 1.1 版中新增。
n_support_形狀為 (n_classes,)、dtype=int32 的 ndarray每個類別的支持向量數量。
- offset_float
用於從原始分數定義決策函數的偏移量。我們有以下關係:decision_function = score_samples -
offset_。偏移量與intercept_相反,並為了與其他離群值偵測演算法保持一致而提供。在 0.20 版中新增。
- shape_fit_形狀為 (n_dimensions_of_X,) 的 int 元組
訓練向量
X的陣列維度。- support_形狀為 (n_SV,) 的 ndarray
支持向量的索引。
- support_vectors_形狀為 (n_SV, n_features) 的 ndarray
支持向量。
另請參閱
sklearn.linear_model.SGDOneClassSVM使用隨機梯度下降法求解線性單類別 SVM。
sklearn.neighbors.LocalOutlierFactor使用局部離群因子 (LOF) 進行非監督式離群值偵測。
sklearn.ensemble.IsolationForest隔離森林演算法。
範例
>>> from sklearn.svm import OneClassSVM >>> X = [[0], [0.44], [0.45], [0.46], [1]] >>> clf = OneClassSVM(gamma='auto').fit(X) >>> clf.predict(X) array([-1, 1, 1, 1, -1]) >>> clf.score_samples(X) array([1.7798..., 2.0547..., 2.0556..., 2.0561..., 1.7332...])
如需更詳盡的範例,請參閱物種分佈建模
- property coef_#
當
kernel="linear"時,分配給特徵的權重。- 傳回:
- 形狀為 (n_features, n_classes) 的 ndarray
- decision_function(X)[原始碼]#
到分離超平面的帶符號距離。
帶符號距離對於內部點為正,對於離群值為負。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
資料矩陣。
- 傳回:
- dec形狀為 (n_samples,) 的 ndarray
傳回樣本的決策函數。
- fit(X, y=None, sample_weight=None)[原始碼]#
偵測樣本集 X 的軟邊界。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like) 或稀疏矩陣 (sparse matrix)
樣本集,其中
n_samples是樣本數,n_features是特徵數。- y已忽略
未使用,為了 API 的一致性而存在。
- sample_weight形狀為 (n_samples,) 的類陣列,預設值為 None
每個樣本的權重。調整每個樣本的 C 值。較高的權重會迫使分類器更重視這些點。
- 傳回:
- self物件
已擬合的估計器。
注意事項
如果 X 不是 C 順序的連續陣列,則會被複製。
- fit_predict(X, y=None, **kwargs)[原始碼]#
對 X 執行擬合,並返回 X 的標籤。
離群值返回 -1,內群值返回 1。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like) 或稀疏矩陣 (sparse matrix)
輸入的樣本。
- y已忽略
未使用,為了 API 的一致性而存在。
- **kwargs字典
要傳遞給
fit的引數。在 1.4 版本中新增。
- 傳回:
- y形狀為 (n_samples,) 的 ndarray
內群值為 1,離群值為 -1。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查閱 使用者指南 以了解路由機制如何運作。
- 傳回:
- routingMetadataRequest
一個封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deep布林值,預設值為 True
如果為 True,將返回此估計器和包含的子物件(為估計器)的參數。
- 傳回:
- params字典
參數名稱對應到它們的值。
- property n_support_#
每個類別的支持向量數量。
- predict(X)[原始碼]#
對 X 中的樣本執行分類。
對於單類模型,返回 +1 或 -1。
- 參數:
- X形狀為 (n_samples, n_features) 或 (n_samples_test, n_samples_train) 的類陣列或稀疏矩陣
對於 kernel=”precomputed”,X 的預期形狀為 (n_samples_test, n_samples_train)。
- 傳回:
- y_pred形狀為 (n_samples,) 的 ndarray
X 中樣本的類別標籤。
- score_samples(X)[原始碼]#
樣本的原始評分函數。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
資料矩陣。
- 傳回:
- score_samples形狀為 (n_samples,) 的 ndarray
返回樣本的(未偏移)評分函數。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') OneClassSVM[原始碼]#
請求傳遞給
fit方法的中繼資料。請注意,只有在
enable_metadata_routing=True時,此方法才相關(請參閱sklearn.set_config)。請參閱 使用者指南 以了解路由機制如何運作。每個參數的選項為:
True:請求中繼資料,如果提供,則會傳遞給fit。如果未提供中繼資料,則忽略該請求。False:不請求中繼資料,並且元估計器不會將其傳遞給fit。None:不請求中繼資料,如果使用者提供,元估計器將引發錯誤。str:應該使用給定的別名而不是原始名稱,將中繼資料傳遞給元估計器。
預設值(
sklearn.utils.metadata_routing.UNCHANGED)保留現有的請求。這使您可以變更某些參數的請求,而無需變更其他參數。在 1.3 版本中新增。
注意事項
只有在此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則它沒有任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight參數的中繼資料路由。
- 傳回:
- self物件
更新後的物件。