注意
跳至結尾以下載完整的範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
繪製交叉驗證預測#
此範例展示如何使用 cross_val_predict 以及 PredictionErrorDisplay 來視覺化預測錯誤。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
我們將載入糖尿病資料集並建立線性迴歸模型的實例。
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
X, y = load_diabetes(return_X_y=True)
lr = LinearRegression()
cross_val_predict 會傳回一個與 y 大小相同的陣列,其中每個條目都是透過交叉驗證獲得的預測。
from sklearn.model_selection import cross_val_predict
y_pred = cross_val_predict(lr, X, y, cv=10)
由於 cv=10,這表示我們訓練了 10 個模型,並且每個模型都用於預測 10 個折疊之一。我們現在可以使用 PredictionErrorDisplay 來視覺化預測錯誤。
在左軸上,我們繪製觀察值 \(y\) 與模型給出的預測值 \(\hat{y}\)。在右軸上,我們繪製殘差(即觀察值與預測值之間的差異)與預測值。
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(ncols=2, figsize=(8, 4))
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="actual_vs_predicted",
subsample=100,
ax=axs[0],
random_state=0,
)
axs[0].set_title("Actual vs. Predicted values")
PredictionErrorDisplay.from_predictions(
y,
y_pred=y_pred,
kind="residual_vs_predicted",
subsample=100,
ax=axs[1],
random_state=0,
)
axs[1].set_title("Residuals vs. Predicted Values")
fig.suptitle("Plotting cross-validated predictions")
plt.tight_layout()
plt.show()
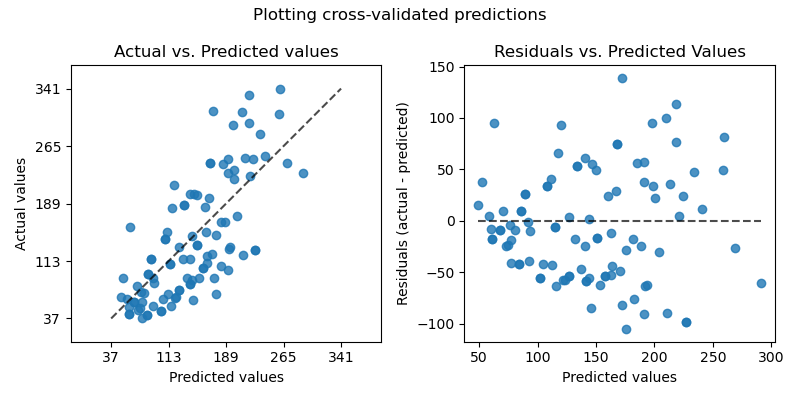
請務必注意,在此範例中,我們僅為了視覺化目的使用 cross_val_predict。
當不同的 CV 折疊在大小和分佈上有所不同時,從 cross_val_predict 傳回的串聯預測中計算單一效能指標來定量評估模型效能是有問題的。
建議使用以下項目計算每個折疊的效能指標:cross_val_score 或 cross_validate。
腳本的總執行時間:(0 分鐘 0.194 秒)
相關範例