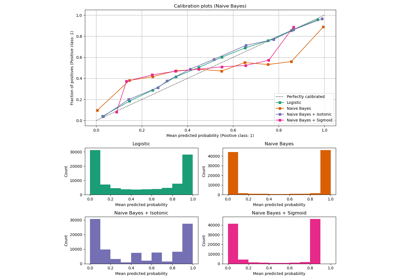
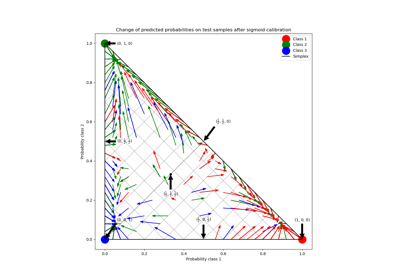
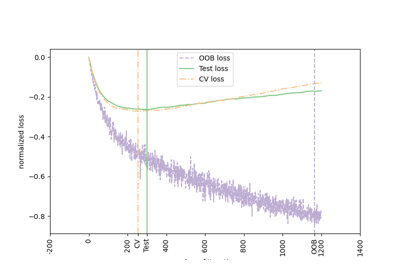
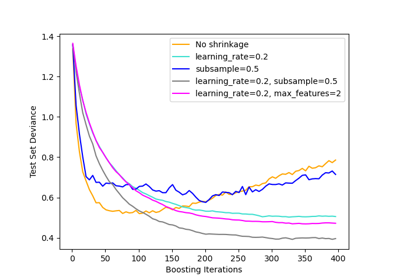
對數損失 (log_loss)#
- sklearn.metrics.log_loss(y_true, y_pred, *, normalize=True, sample_weight=None, labels=None)[原始碼]#
對數損失,又稱邏輯損失或交叉熵損失。
這是(多項式)邏輯迴歸及其延伸(如神經網路)中使用的損失函數,定義為邏輯模型的負對數似然值,該模型為其訓練資料
y_true返回y_pred機率。對數損失僅針對兩個或多個標籤定義。對於具有真實標籤 \(y \in \{0,1\}\) 和機率估計 \(p = \operatorname{Pr}(y = 1)\) 的單個樣本,對數損失為\[L_{\log}(y, p) = -(y \log (p) + (1 - y) \log (1 - p))\]在 使用者指南 中閱讀更多資訊。
- 參數:
- y_true類似陣列或標籤指示矩陣
n_samples 個樣本的真實(正確)標籤。
- y_pred浮點數的類似陣列,形狀 = (n_samples, n_classes) 或 (n_samples,)
預測機率,由分類器的 predict_proba 方法返回。如果
y_pred.shape = (n_samples,),則假設提供的機率為正類的機率。y_pred中的標籤假設以字母順序排序,如同LabelBinarizer所做的一樣。y_pred值被裁剪到[eps, 1-eps],其中eps是y_pred的 dtype 的機器精度。- normalize布林值,預設值=True
如果為 true,則返回每個樣本的平均損失。否則,返回每個樣本損失的總和。
- sample_weight形狀為 (n_samples,) 的類似陣列,預設值=None
樣本權重。
- labels類似陣列,預設值=None
如果未提供,則標籤將從 y_true 推斷。如果
labels為None且y_pred的形狀為 (n_samples,),則假設標籤為二進制,並從y_true推斷。在版本 0.18 中新增。
- 返回:
- loss浮點數
對數損失,又稱邏輯損失或交叉熵損失。
註解
使用的對數為自然對數(以 e 為底)。
參考文獻
C.M. Bishop (2006)。 Pattern Recognition and Machine Learning。 Springer, p. 209.
範例
>>> from sklearn.metrics import log_loss >>> log_loss(["spam", "ham", "ham", "spam"], ... [[.1, .9], [.9, .1], [.8, .2], [.35, .65]]) 0.21616...