注意
前往結尾以下載完整範例程式碼。或透過 JupyterLite 或 Binder 在您的瀏覽器中執行此範例
分類器的機率校準#
在執行分類時,您通常不僅想要預測類別標籤,還想要預測相關聯的機率。此機率給予您對預測的某種程度的信心。然而,並非所有分類器都能提供良好校準的機率,有些過於自信,而另一些則過於不自信。因此,通常需要對預測機率進行單獨的校準作為後處理。此範例說明了兩種不同的校準方法,並使用 Brier 分數評估返回機率的品質(請參閱 https://en.wikipedia.org/wiki/Brier_score)。
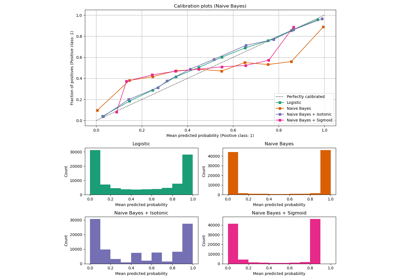
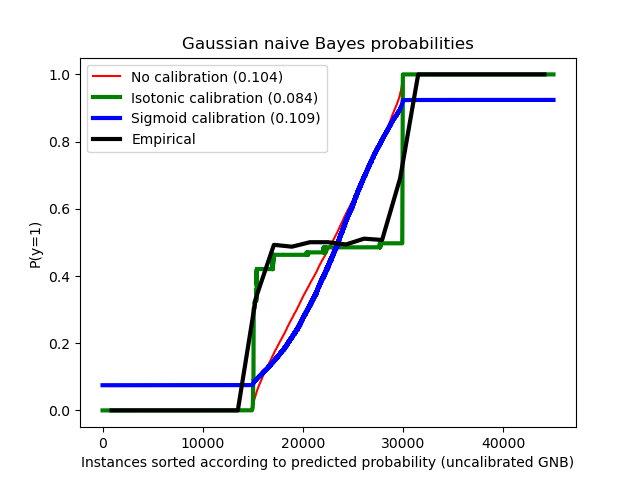
比較了使用未經校準的高斯樸素貝葉斯分類器、使用 Sigmoid 校準以及使用非參數等滲校準的估計機率。可以觀察到,只有非參數模型能夠提供機率校準,對於大多數屬於具有異質標籤的中間叢集的樣本,返回的機率接近預期的 0.5。這顯著提高了 Brier 分數。
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
產生合成資料集#
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
n_samples = 50000
n_bins = 3 # use 3 bins for calibration_curve as we have 3 clusters here
# Generate 3 blobs with 2 classes where the second blob contains
# half positive samples and half negative samples. Probability in this
# blob is therefore 0.5.
centers = [(-5, -5), (0, 0), (5, 5)]
X, y = make_blobs(n_samples=n_samples, centers=centers, shuffle=False, random_state=42)
y[: n_samples // 2] = 0
y[n_samples // 2 :] = 1
sample_weight = np.random.RandomState(42).rand(y.shape[0])
# split train, test for calibration
X_train, X_test, y_train, y_test, sw_train, sw_test = train_test_split(
X, y, sample_weight, test_size=0.9, random_state=42
)
高斯樸素貝葉斯#
from sklearn.calibration import CalibratedClassifierCV
from sklearn.metrics import brier_score_loss
from sklearn.naive_bayes import GaussianNB
# With no calibration
clf = GaussianNB()
clf.fit(X_train, y_train) # GaussianNB itself does not support sample-weights
prob_pos_clf = clf.predict_proba(X_test)[:, 1]
# With isotonic calibration
clf_isotonic = CalibratedClassifierCV(clf, cv=2, method="isotonic")
clf_isotonic.fit(X_train, y_train, sample_weight=sw_train)
prob_pos_isotonic = clf_isotonic.predict_proba(X_test)[:, 1]
# With sigmoid calibration
clf_sigmoid = CalibratedClassifierCV(clf, cv=2, method="sigmoid")
clf_sigmoid.fit(X_train, y_train, sample_weight=sw_train)
prob_pos_sigmoid = clf_sigmoid.predict_proba(X_test)[:, 1]
print("Brier score losses: (the smaller the better)")
clf_score = brier_score_loss(y_test, prob_pos_clf, sample_weight=sw_test)
print("No calibration: %1.3f" % clf_score)
clf_isotonic_score = brier_score_loss(y_test, prob_pos_isotonic, sample_weight=sw_test)
print("With isotonic calibration: %1.3f" % clf_isotonic_score)
clf_sigmoid_score = brier_score_loss(y_test, prob_pos_sigmoid, sample_weight=sw_test)
print("With sigmoid calibration: %1.3f" % clf_sigmoid_score)
Brier score losses: (the smaller the better)
No calibration: 0.104
With isotonic calibration: 0.084
With sigmoid calibration: 0.109
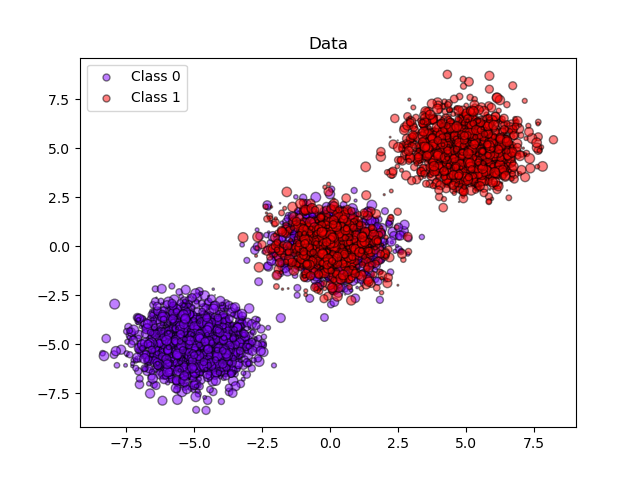
繪製資料和預測機率#
import matplotlib.pyplot as plt
from matplotlib import cm
plt.figure()
y_unique = np.unique(y)
colors = cm.rainbow(np.linspace(0.0, 1.0, y_unique.size))
for this_y, color in zip(y_unique, colors):
this_X = X_train[y_train == this_y]
this_sw = sw_train[y_train == this_y]
plt.scatter(
this_X[:, 0],
this_X[:, 1],
s=this_sw * 50,
c=color[np.newaxis, :],
alpha=0.5,
edgecolor="k",
label="Class %s" % this_y,
)
plt.legend(loc="best")
plt.title("Data")
plt.figure()
order = np.lexsort((prob_pos_clf,))
plt.plot(prob_pos_clf[order], "r", label="No calibration (%1.3f)" % clf_score)
plt.plot(
prob_pos_isotonic[order],
"g",
linewidth=3,
label="Isotonic calibration (%1.3f)" % clf_isotonic_score,
)
plt.plot(
prob_pos_sigmoid[order],
"b",
linewidth=3,
label="Sigmoid calibration (%1.3f)" % clf_sigmoid_score,
)
plt.plot(
np.linspace(0, y_test.size, 51)[1::2],
y_test[order].reshape(25, -1).mean(1),
"k",
linewidth=3,
label=r"Empirical",
)
plt.ylim([-0.05, 1.05])
plt.xlabel("Instances sorted according to predicted probability (uncalibrated GNB)")
plt.ylabel("P(y=1)")
plt.legend(loc="upper left")
plt.title("Gaussian naive Bayes probabilities")
plt.show()
腳本的總執行時間: (0 分鐘 0.334 秒)
相關範例