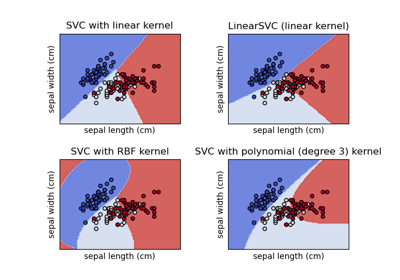
LinearSVC#
- class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', *, dual='auto', tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)[原始碼]#
線性支援向量分類器。
與參數 kernel=’linear’ 的 SVC 類似,但以 liblinear 而非 libsvm 實作,因此在懲罰和損失函數的選擇上更具彈性,且應能更好地擴展到大量的樣本。
LinearSVC和SVC之間的主要差異在於預設使用的損失函數,以及這兩個實作之間對截距正規化的處理方式。此類別支援密集和稀疏輸入,並且根據一對多的方案處理多類別支援。
請在 使用者指南 中閱讀更多內容。
- 參數:
- penalty{‘l1’, ‘l2’}, default=’l2’
指定在懲罰中使用的範數。 ‘l2’ 懲罰是 SVC 中使用的標準。 ‘l1’ 會產生稀疏的
coef_向量。- loss{‘hinge’, ‘squared_hinge’}, default=’squared_hinge’
指定損失函數。 ‘hinge’ 是標準的 SVM 損失 (例如,由 SVC 類別使用),而 ‘squared_hinge’ 是 hinge 損失的平方。 不支援
penalty='l1'和loss='hinge'的組合。- dual“auto” 或 bool,default=”auto”
選擇演算法以解決對偶或原始最佳化問題。 當 n_samples > n_features 時,優先使用 dual=False。
dual="auto"會根據n_samples、n_features、loss、multi_class和penalty的值自動選擇參數值。 如果n_samples<n_features且最佳化器支援所選的loss、multi_class和penalty,則 dual 將設為 True,否則將設為 False。在 1.3 版中變更:
"auto"選項在 1.3 版中新增,將在 1.5 版中成為預設值。- tolfloat, default=1e-4
停止條件的容差。
- Cfloat, default=1.0
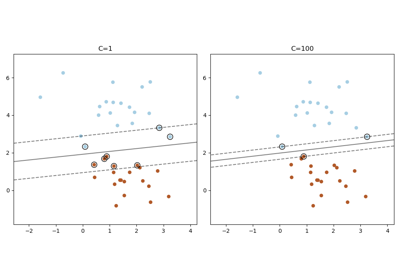
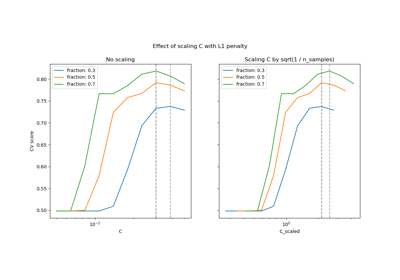
正規化參數。 正規化的強度與 C 成反比。 必須為嚴格正數。 有關縮放正規化參數 C 的影響的直觀視覺化,請參閱 縮放 SVC 的正規化參數。
- multi_class{‘ovr’, ‘crammer_singer’}, default=’ovr’
如果
y包含兩個以上的類別,則決定多類別策略。"ovr"訓練 n_classes 個一對多分類器,而"crammer_singer"則最佳化所有類別的聯合目標。 雖然crammer_singer從理論角度來看很有趣,因為它是一致的,但在實務中很少使用,因為它很少帶來更好的準確性,而且計算成本更高。 如果選擇"crammer_singer",則會忽略 loss、penalty 和 dual 選項。- fit_interceptbool, default=True
是否要擬合截距。 如果設為 True,則會擴充特徵向量以包含截距項:
[x_1, ..., x_n, 1],其中 1 對應於截距。 如果設為 False,則計算中不會使用截距 (即,預期資料已置中)。- intercept_scalingfloat, default=1.0
當
fit_intercept為 True 時,實例向量 x 會變成[x_1, ..., x_n, intercept_scaling],即附加一個常數值等於intercept_scaling的「合成」特徵到實例向量。 截距會變成 intercept_scaling * 合成特徵權重。 請注意,liblinear 在內部懲罰截距,將其視為特徵向量中的任何其他項。 為了減少正規化對截距的影響,intercept_scaling參數可以設定為大於 1 的值;intercept_scaling的值越高,正規化對截距的影響就越小。 然後,權重會變成[w_x_1, ..., w_x_n, w_intercept*intercept_scaling],其中w_x_1, ..., w_x_n代表特徵權重,而截距權重會依intercept_scaling縮放。 此縮放允許截距項與其他特徵相比具有不同的正規化行為。- class_weightdict 或 ‘balanced’, default=None
將類別 i 的參數 C 設定為
class_weight[i]*C(適用於 SVC)。 如果未給定,則假設所有類別的權重均為 1。 「balanced」模式使用 y 的值自動調整權重,權重與輸入資料中的類別頻率成反比,計算方式為n_samples / (n_classes * np.bincount(y))。- verboseint, default=0
啟用詳細輸出。 請注意,此設定會利用 liblinear 中的每個處理程序執行時間設定,如果啟用,則可能無法在多執行緒環境中正常運作。
- random_stateint, RandomState 實例或 None, default=None
控制雙座標下降法(如果
dual=True)用於數據洗牌的偽隨機數生成。當dual=False時,LinearSVC的底層實作並非隨機,且random_state對結果沒有影響。傳遞一個整數可以在多次函數調用中產生可重現的輸出。請參閱 詞彙表。- max_iterint, 預設值=1000
要執行的最大迭代次數。
- 屬性:
- coef_ndarray,形狀為 (1, n_features) 如果 n_classes == 2,否則為 (n_classes, n_features)
分配給特徵的權重(原始問題中的係數)。
coef_是一個唯讀屬性,衍生自raw_coef_,其遵循 liblinear 的內部記憶體配置。- intercept_ndarray,形狀為 (1,) 如果 n_classes == 2,否則為 (n_classes,)
決策函數中的常數。
- classes_ndarray,形狀為 (n_classes,)
唯一的類別標籤。
- n_features_in_int
在 fit 期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_ndarray,形狀為 (
n_features_in_,) 在 fit 期間看到的特徵名稱。僅當
X具有全為字串的特徵名稱時才定義。在 1.0 版本中新增。
- n_iter_int
跨所有類別執行的最大迭代次數。
另請參閱
SVC使用 libsvm 實作支援向量機分類器:核心可以是非線性的,但其 SMO 演算法無法像 LinearSVC 一樣擴展到大量樣本。此外,SVC 多類模式是使用一對一方案實作,而 LinearSVC 使用一對其他方案。可以使用
OneVsRestClassifier包裝器來使用 SVC 實作一對其他方案。最後,如果輸入是 C-連續的,SVC 可以擬合密集數據而無需複製記憶體。但是,稀疏數據仍然會產生記憶體複製。sklearn.linear_model.SGDClassifierSGDClassifier 可以通過調整 penalty 和 loss 參數來優化與 LinearSVC 相同的成本函數。此外,它需要較少的記憶體,允許增量(線上)學習,並實作各種損失函數和正規化機制。
注意事項
底層 C 實作使用隨機數產生器在擬合模型時選擇特徵。因此,對於相同的輸入數據,結果略有不同並不罕見。如果發生這種情況,請嘗試使用較小的
tol參數。底層實作 liblinear 使用稀疏的內部數據表示,這會導致記憶體複製。
在某些情況下,預測輸出可能與獨立的 liblinear 不符。請參閱敘述文件中的 與 liblinear 的差異。
參考文獻
範例
>>> from sklearn.svm import LinearSVC >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.datasets import make_classification >>> X, y = make_classification(n_features=4, random_state=0) >>> clf = make_pipeline(StandardScaler(), ... LinearSVC(random_state=0, tol=1e-5)) >>> clf.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('linearsvc', LinearSVC(random_state=0, tol=1e-05))])
>>> print(clf.named_steps['linearsvc'].coef_) [[0.141... 0.526... 0.679... 0.493...]]
>>> print(clf.named_steps['linearsvc'].intercept_) [0.1693...] >>> print(clf.predict([[0, 0, 0, 0]])) [1]
- decision_function(X)[原始碼]#
預測樣本的置信度分數。
樣本的置信度分數與該樣本到超平面的帶符號距離成正比。
- 參數:
- X類陣列、稀疏矩陣,形狀為 (n_samples, n_features)
我們想要取得置信度分數的數據矩陣。
- 返回:
- scoresndarray,形狀為 (n_samples,) 或 (n_samples, n_classes)
每個
(n_samples, n_classes)組合的置信度分數。在二元情況下,self.classes_[1]的置信度分數,其中 >0 表示將預測此類別。
- densify()[原始碼]#
將係數矩陣轉換為密集陣列格式。
將
coef_成員(還原)為 numpy.ndarray。這是coef_的預設格式,並且是擬合所需的,因此僅對先前已稀疏化的模型調用此方法;否則,它是空操作。- 返回:
- self
擬合的估算器。
- fit(X, y, sample_weight=None)[原始碼]#
根據給定的訓練數據擬合模型。
- 參數:
- X類陣列、稀疏矩陣,形狀為 (n_samples, n_features)
訓練向量,其中
n_samples是樣本數,n_features是特徵數。- y類陣列,形狀為 (n_samples,)
相對於 X 的目標向量。
- sample_weight類陣列,形狀為 (n_samples,),預設值=None
分配給個別樣本的權重陣列。如果未提供,則每個樣本都給予單位權重。
在 0.18 版本中新增。
- 返回:
- selfobject
估算器的實例。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用者指南,瞭解路由機制如何運作。
- 返回:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值=True
如果為 True,將返回此估算器的參數以及包含的子物件(它們也是估算器)。
- 返回:
- paramsdict
參數名稱對應到它們的值。
- predict(X)[原始碼]#
預測 X 中樣本的類別標籤。
- 參數:
- X類陣列、稀疏矩陣,形狀為 (n_samples, n_features)
我們想要取得預測的數據矩陣。
- 返回:
- y_predndarray,形狀為 (n_samples,)
包含每個樣本的類別標籤的向量。
- score(X, y, sample_weight=None)[原始碼]#
返回給定測試數據和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為您需要正確預測每個樣本的每個標籤集。
- 參數:
- X類陣列,形狀為 (n_samples, n_features)
測試樣本。
- y類陣列,形狀為 (n_samples,) 或 (n_samples, n_outputs)
X的真實標籤。- sample_weight類陣列,形狀為 (n_samples,),預設值=None
樣本權重。
- 返回:
- scorefloat
self.predict(X)相對於y的平均準確度。
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearSVC[原始碼]#
請求傳遞至
fit方法的中繼資料。請注意,只有當
enable_metadata_routing=True時,此方法才相關 (請參閱sklearn.set_config)。請參閱關於路由機制如何運作的 使用者指南。每個參數的選項如下
True:請求中繼資料,並在提供時傳遞給fit。如果沒有提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估計器不會將其傳遞給fit。None:不請求中繼資料,且如果使用者提供中繼資料,則元估計器會引發錯誤。str:中繼資料應使用此給定的別名而不是原始名稱傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留現有的請求。這讓您可以變更某些參數的請求,而其他參數則不變。在 1.3 版本中新增。
注意
只有當此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則,它不會產生任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
fit中sample_weight參數的中繼資料路由。
- 返回:
- selfobject
更新後的物件。
- set_params(**params)[原始碼]#
設定此估計器的參數。
此方法適用於簡單的估計器以及巢狀物件 (例如
Pipeline)。後者的參數格式為<component>__<parameter>,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估計器參數。
- 返回:
- self估計器實例
估計器實例。
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearSVC[原始碼]#
請求傳遞至
score方法的中繼資料。請注意,只有當
enable_metadata_routing=True時,此方法才相關 (請參閱sklearn.set_config)。請參閱關於路由機制如何運作的 使用者指南。每個參數的選項如下
True:請求中繼資料,並在提供時傳遞給score。如果沒有提供中繼資料,則會忽略請求。False:不請求中繼資料,且元估計器不會將其傳遞給score。None:不請求中繼資料,且如果使用者提供中繼資料,則元估計器會引發錯誤。str:中繼資料應使用此給定的別名而不是原始名稱傳遞給元估計器。
預設值 (
sklearn.utils.metadata_routing.UNCHANGED) 保留現有的請求。這讓您可以變更某些參數的請求,而其他參數則不變。在 1.3 版本中新增。
注意
只有當此估計器用作元估計器的子估計器時,此方法才相關,例如在
Pipeline中使用。否則,它不會產生任何作用。- 參數:
- sample_weightstr、True、False 或 None,預設值=sklearn.utils.metadata_routing.UNCHANGED
score中sample_weight參數的中繼資料路由。
- 返回:
- selfobject
更新後的物件。
- sparsify()[原始碼]#
將係數矩陣轉換為稀疏格式。
將
coef_成員轉換為 scipy.sparse 矩陣,對於 L1 正規化的模型,這會比一般的 numpy.ndarray 表示法更節省記憶體和儲存空間。intercept_成員不會轉換。- 返回:
- self
擬合的估算器。
注意事項
對於非稀疏模型,也就是說,當
coef_中沒有很多零時,這實際上可能會增加記憶體使用量,因此請小心使用此方法。一個經驗法則是用(coef_ == 0).sum()計算的零元素數量必須超過 50%,才能提供顯著的好處。在呼叫此方法之後,進一步使用 partial_fit 方法 (如果有的話) 進行擬合將無法運作,直到您呼叫 densify 為止。