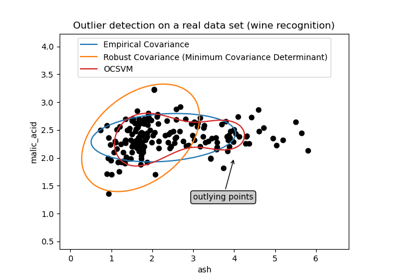
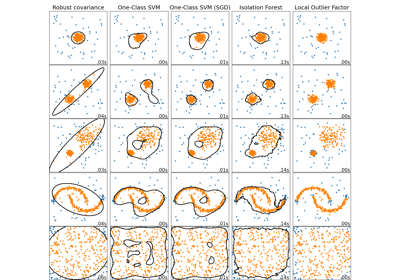
橢圓包絡#
- class sklearn.covariance.EllipticEnvelope(*, store_precision=True, assume_centered=False, support_fraction=None, contamination=0.1, random_state=None)[來源]#
用於檢測高斯分佈資料集中離群值的物件。
在使用者指南中閱讀更多內容。
- 參數:
- store_precision布林值,預設值為 True
指定是否儲存估計精度。
- assume_centered布林值,預設值為 False
如果為 True,則計算穩健位置和共變異數估計的支持度,並從中重新計算共變異數估計,而無需將資料居中。適用於平均值顯著等於零但並不完全為零的資料。如果為 False,則直接使用 FastMCD 演算法計算穩健位置和共變異數,無需額外處理。
- support_fraction浮點數,預設值為 None
原始 MCD 估計中要包含的點的比例。如果為 None,則演算法中將使用 support_fraction 的最小值:
(n_samples + n_features + 1) / 2 * n_samples。範圍為 (0, 1)。- contaminationfloat,預設值=0.1
資料集中污染的量,即資料集中離群值的比例。範圍為 (0, 0.5]。
- random_stateint,RandomState 實例或 None,預設值=None
決定用於隨機排列資料的虛擬隨機數產生器。傳遞 int 以便在多次函數呼叫中獲得可重現的結果。請參閱詞彙表。
- 屬性:
- location_形狀為 (n_features,) 的 ndarray
估計的穩健位置。
- covariance_形狀為 (n_features, n_features) 的 ndarray
估計的穩健共變異數矩陣。
- precision_形狀為 (n_features, n_features) 的 ndarray
估計的偽反矩陣。(僅在 store_precision 為 True 時儲存)
- support_形狀為 (n_samples,) 的 ndarray
已用於計算位置和形狀穩健估計的觀察值的遮罩。
- offset_float
用於從原始分數定義決策函數的偏移量。我們有以下關係:
decision_function = score_samples - offset_。偏移量取決於污染參數,並以在訓練中獲得預期的離群值數量 (決策函數 < 0 的樣本) 的方式定義。於 0.20 版本新增。
- raw_location_形狀為 (n_features,) 的 ndarray
校正和重新加權之前的原始穩健估計位置。
- raw_covariance_形狀為 (n_features, n_features) 的 ndarray
校正和重新加權之前的原始穩健估計共變異數。
- raw_support_形狀為 (n_samples,) 的 ndarray
在校正和重新加權之前,已用於計算位置和形狀的原始穩健估計的觀察值的遮罩。
- dist_形狀為 (n_samples,) 的 ndarray
訓練集(呼叫
fit的)觀察值的馬氏距離。- n_features_in_int
在fit期間看到的特徵數量。
於 0.24 版本新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在fit期間看到的特徵名稱。僅當
X具有全部為字串的特徵名稱時才定義。於 1.0 版本新增。
另請參閱
EmpiricalCovariance最大似然共變異數估計器。
GraphicalLasso具有 l1 懲罰估計器的稀疏逆共變異數估計。
LedoitWolfLedoitWolf 估計器。
MinCovDet最小共變異數行列式(穩健共變異數估計器)。
OASOracle 近似收縮估計器。
ShrunkCovariance具有收縮的共變異數估計器。
注意
從共變異數估計的離群值檢測在高維設定中可能會中斷或表現不佳。特別是,應始終注意使用
n_samples > n_features ** 2。參考文獻
[1]Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999)
範例
>>> import numpy as np >>> from sklearn.covariance import EllipticEnvelope >>> true_cov = np.array([[.8, .3], ... [.3, .4]]) >>> X = np.random.RandomState(0).multivariate_normal(mean=[0, 0], ... cov=true_cov, ... size=500) >>> cov = EllipticEnvelope(random_state=0).fit(X) >>> # predict returns 1 for an inlier and -1 for an outlier >>> cov.predict([[0, 0], ... [3, 3]]) array([ 1, -1]) >>> cov.covariance_ array([[0.7411..., 0.2535...], [0.2535..., 0.3053...]]) >>> cov.location_ array([0.0813... , 0.0427...])
- correct_covariance(data)[來源]#
將校正應用於原始最小共變異數行列式估計。
使用 Rousseeuw 和 Van Driessen 在 [RVD] 中提出的經驗校正因子進行校正。
- 參數:
- data形狀為 (n_samples, n_features) 的類陣列
資料矩陣,具有 p 個特徵和 n 個樣本。資料集必須是已用於計算原始估計的資料集。
- 傳回:
- covariance_corrected形狀為 (n_features, n_features) 的 ndarray
校正後的穩健共變異數估計。
參考文獻
[RVD]A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
- decision_function(X)[來源]#
計算給定觀察值的決策函數。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
資料矩陣。
- 傳回:
- decision形狀為 (n_samples,) 的 ndarray
樣本的決策函數。它等於移位的馬氏距離。成為離群值的閾值為 0,這確保了與其他離群值檢測演算法的相容性。
- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[來源]#
計算兩個共變異數估計器之間的均方誤差。
- 參數:
- comp_cov形狀為 (n_features, n_features) 的類陣列
要與之比較的共變異數。
- norm{“frobenius”, “spectral”},預設值=“frobenius”
用於計算誤差的範數類型。可用的錯誤類型:- 'frobenius'(預設):sqrt(tr(A^t.A)) - 'spectral':sqrt(max(eigenvalues(A^t.A)),其中 A 是誤差
(comp_cov - self.covariance_)。- scalingbool,預設值=True
如果為 True(預設),則平方誤差範數除以 n_features。如果為 False,則不重新調整平方誤差範數。
- squaredbool,預設值=True
是否計算平方誤差範數或誤差範數。若為 True (預設值),則傳回平方誤差範數。若為 False,則傳回誤差範數。
- 傳回:
- resultfloat
self和comp_cov共變異數估計器之間的均方誤差(以 Frobenius 範數而言)。
- fit(X, y=None)[原始碼]#
擬合 EllipticEnvelope 模型。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
訓練資料。
- y忽略
不使用,為了 API 一致性而存在。
- 傳回:
- self物件
傳回實例本身。
- fit_predict(X, y=None, **kwargs)[原始碼]#
對 X 執行擬合並傳回 X 的標籤。
異常值傳回 -1,內群值傳回 1。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列或稀疏矩陣
輸入樣本。
- y忽略
不使用,為了 API 一致性而存在。
- **kwargsdict
要傳遞給
fit的引數。於 1.4 版本新增。
- 傳回:
- y形狀為 (n_samples,) 的 ndarray
內群值為 1,異常值為 -1。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南以了解路由機制如何運作。
- 傳回:
- routingMetadataRequest
封裝路由資訊的
MetadataRequest。
- get_params(deep=True)[原始碼]#
取得此估計器的參數。
- 參數:
- deepbool,預設值為 True
若為 True,則會傳回此估計器和包含的子物件(為估計器)的參數。
- 傳回:
- paramsdict
參數名稱對應至其值的字典。
- get_precision()[原始碼]#
精確矩陣的 Getter。
- 傳回:
- precision_形狀為 (n_features, n_features) 的類陣列
與目前共變異數物件相關聯的精確矩陣。
- mahalanobis(X)[原始碼]#
計算給定觀測值的平方馬氏距離。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
我們要計算馬氏距離的觀測值。假設觀測值與 fit 中使用的資料來自相同的分佈。
- 傳回:
- dist形狀為 (n_samples,) 的 ndarray
觀測值的平方馬氏距離。
- predict(X)[原始碼]#
根據擬合模型預測 X 的標籤 (1 代表內群值,-1 代表異常值)。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
資料矩陣。
- 傳回:
- is_inlier形狀為 (n_samples,) 的 ndarray
異常值/離群值傳回 -1,內群值傳回 +1。
- reweight_covariance(data)[原始碼]#
重新權衡原始最小共變異數行列式估計值。
使用 Rousseeuw 的方法重新權衡觀測值(相當於在計算位置和共變異數估計值之前從資料集中刪除離群觀測值),如 [RVDriessen] 中所述。
- 參數:
- data形狀為 (n_samples, n_features) 的類陣列
資料矩陣,具有 p 個特徵和 n 個樣本。資料集必須是已用於計算原始估計的資料集。
- 傳回:
- location_reweighted形狀為 (n_features,) 的 ndarray
重新權衡的穩健位置估計值。
- covariance_reweighted形狀為 (n_features, n_features) 的 ndarray
重新權衡的穩健共變異數估計值。
- support_reweighted形狀為 (n_samples,)、dtype=bool 的 ndarray
用於計算重新權衡的穩健位置和共變異數估計值的觀測值遮罩。
參考文獻
[RVDriessen]A Fast Algorithm for the Minimum Covariance Determinant Estimator, 1999, American Statistical Association and the American Society for Quality, TECHNOMETRICS
- score(X, y, sample_weight=None)[原始碼]#
傳回給定測試資料和標籤的平均準確度。
在多標籤分類中,這是子集準確度,這是一個嚴苛的指標,因為您需要每個樣本的每個標籤集都被正確預測。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
測試樣本。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的類陣列
X 的真實標籤。
- sample_weight形狀為 (n_samples,),預設值為 None 的類陣列
樣本權重。
- 傳回:
- scorefloat
self.predict(X) 相對於 y 的平均準確度。