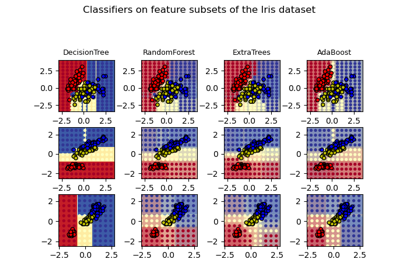
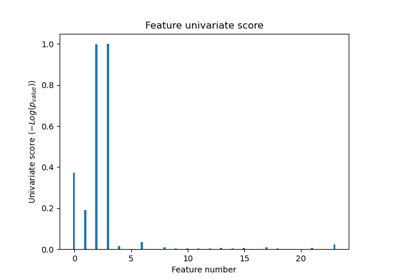
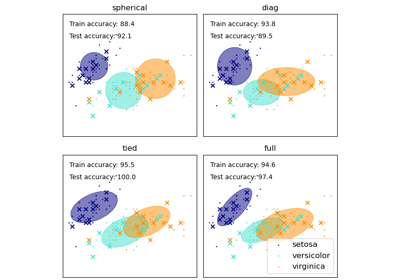
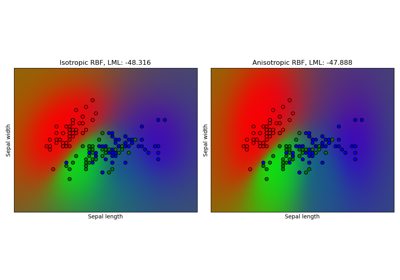
load_iris#
- sklearn.datasets.load_iris(*, return_X_y=False, as_frame=False)[原始碼]#
載入並回傳鳶尾花資料集(分類)。
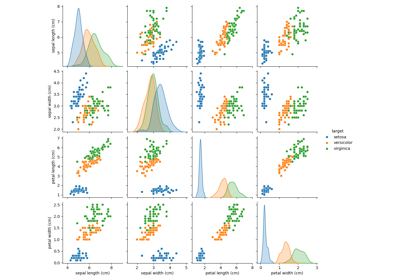
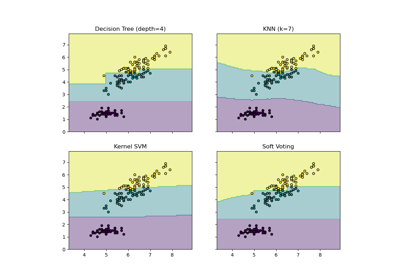
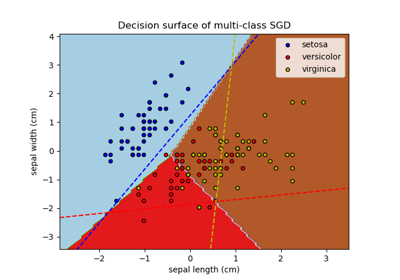
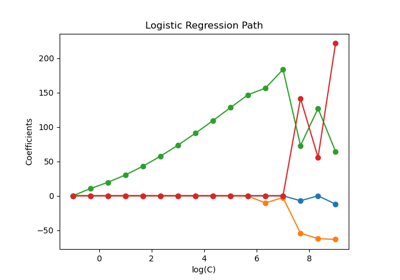
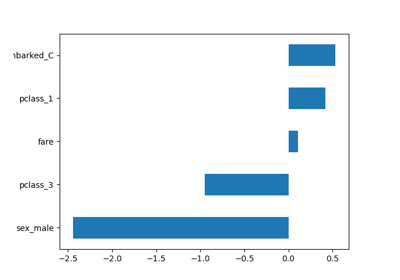
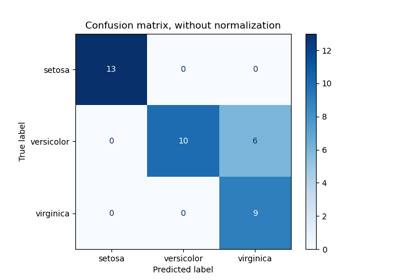
鳶尾花資料集是一個經典且非常容易的多類別分類資料集。
類別
3
每個類別的樣本數
50
總樣本數
150
維度
4
特徵
實數,正數
在使用者指南中閱讀更多內容。
在 0.20 版本中變更:根據 Fisher 的論文修正了兩個錯誤的資料點。新版本與 R 中的版本相同,但與 UCI 機器學習儲存庫中的版本不同。
- 參數:
- return_X_ybool,預設值 = False
如果為 True,則回傳
(data, target)而非 Bunch 物件。請參閱下方關於data和target物件的更多資訊。在 0.18 版本中新增。
- as_framebool,預設值 = False
如果為 True,則資料為 pandas DataFrame,包含具有適當 dtype (數值) 的欄位。目標是 pandas DataFrame 或 Series,取決於目標欄位的數量。如果
return_X_y為 True,則 (data,target) 將會是 pandas DataFrames 或 Series,如下所述。在 0.23 版本中新增。
- 回傳:
- data
Bunch 類似字典的物件,具有以下屬性。
- data形狀為 (150, 4) 的 {ndarray, dataframe}
資料矩陣。如果
as_frame=True,則data將會是 pandas DataFrame。- target:形狀為 (150,) 的 {ndarray, Series}
分類目標。如果
as_frame=True,則target將會是 pandas Series。- feature_names:列表
資料集欄位的名稱。
- target_names:列表
目標類別的名稱。
- frame:形狀為 (150, 5) 的 DataFrame
只有在
as_frame=True時才會出現。包含data和target的 DataFrame。在 0.23 版本中新增。
- DESCR:字串
資料集的完整描述。
- filename:字串
資料位置的路徑。
在 0.20 版本中新增。
- (data, target)如果
return_X_y為 True 則為元組 兩個 ndarray 的元組。第一個包含一個形狀為 (n_samples, n_features) 的 2D 陣列,每一列代表一個樣本,每一欄代表特徵。第二個 ndarray 的形狀為 (n_samples,),包含目標樣本。
在 0.18 版本中新增。
- data
範例
假設您對樣本 10、25 和 50 感興趣,並且想知道它們的類別名稱。
>>> from sklearn.datasets import load_iris >>> data = load_iris() >>> data.target[[10, 25, 50]] array([0, 0, 1]) >>> list(data.target_names) [np.str_('setosa'), np.str_('versicolor'), np.str_('virginica')]
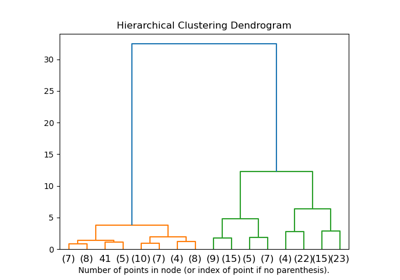
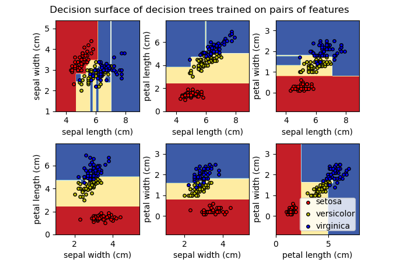
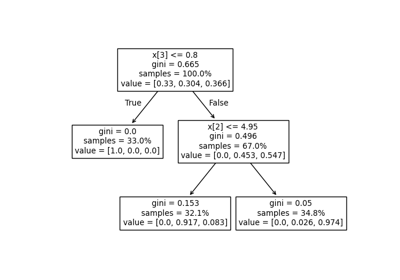
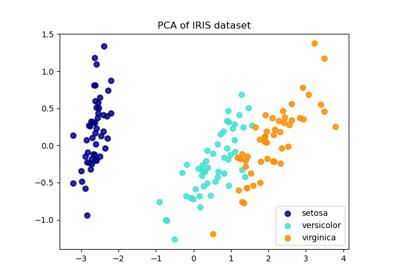
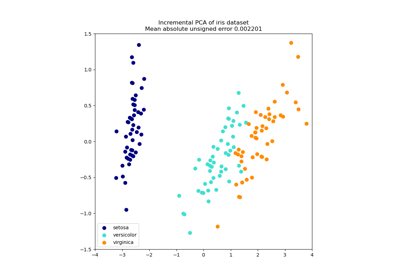
請參閱鳶尾花資料集的主成分分析 (PCA),以取得如何使用鳶尾花資料集的更詳細範例。