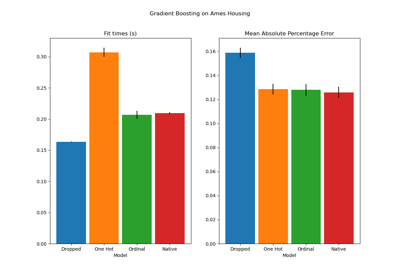
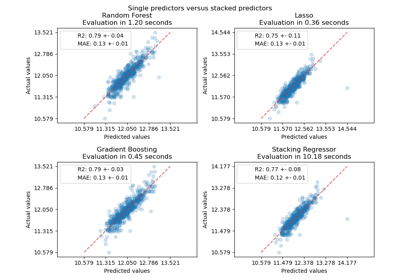
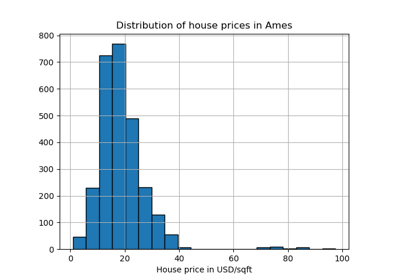
make_column_selector#
- class sklearn.compose.make_column_selector(pattern=None, *, dtype_include=None, dtype_exclude=None)[原始碼]#
建立一個可呼叫物件,用於選取要與
ColumnTransformer搭配使用的欄位。make_column_selector可以根據資料類型或欄位名稱(使用正規表示式)來選取欄位。當使用多個選取條件時,必須符合所有條件,才能選取該欄位。如需了解如何在
ColumnTransformer中使用make_column_selector根據資料類型(即dtype)選取欄位的範例,請參閱 具有混合類型的欄轉換器。- 參數:
- patternstr,預設值為 None
將會包含名稱中包含此正規表示式的欄位。如果為 None,則不會根據模式選取欄位。
- dtype_include欄位資料類型或欄位資料類型列表,預設值為 None
要包含的資料類型選取。有關詳細資訊,請參閱
pandas.DataFrame.select_dtypes。- dtype_exclude欄位資料類型或欄位資料類型列表,預設值為 None
要排除的資料類型選取。有關詳細資訊,請參閱
pandas.DataFrame.select_dtypes。
- 傳回值:
- selector可呼叫物件
欄位選取的可呼叫物件,供
ColumnTransformer使用。
另請參閱
ColumnTransformer允許將多個轉換器物件在資料欄位子集上的輸出組合到單一特徵空間的類別。
範例
>>> from sklearn.preprocessing import StandardScaler, OneHotEncoder >>> from sklearn.compose import make_column_transformer >>> from sklearn.compose import make_column_selector >>> import numpy as np >>> import pandas as pd >>> X = pd.DataFrame({'city': ['London', 'London', 'Paris', 'Sallisaw'], ... 'rating': [5, 3, 4, 5]}) >>> ct = make_column_transformer( ... (StandardScaler(), ... make_column_selector(dtype_include=np.number)), # rating ... (OneHotEncoder(), ... make_column_selector(dtype_include=object))) # city >>> ct.fit_transform(X) array([[ 0.90453403, 1. , 0. , 0. ], [-1.50755672, 1. , 0. , 0. ], [-0.30151134, 0. , 1. , 0. ], [ 0.90453403, 0. , 0. , 1. ]])
- __call__(df)[原始碼]#
欄位選取的可呼叫物件,供
ColumnTransformer使用。- 參數:
- df形狀為 (n_features, n_samples) 的資料框
要从中选择栏位的 DataFrame。