PowerTransformer#
- class sklearn.preprocessing.PowerTransformer(method='yeo-johnson', *, standardize=True, copy=True)[原始碼]#
對每個特徵個別套用冪轉換,使數據更趨近高斯分佈。
冪轉換是一組參數化的單調轉換,用於使數據更趨近高斯分佈。這對於處理異方差性(非恆定變異數)相關的建模問題,或其他需要常態性的情況很有用。
目前,PowerTransformer 支援 Box-Cox 轉換和 Yeo-Johnson 轉換。透過最大概似估計,可獲得穩定變異數並最小化偏度的最佳參數。
Box-Cox 要求輸入數據必須嚴格為正數,而 Yeo-Johnson 則支援正數或負數數據。
預設情況下,轉換後的數據會套用零均值、單位變異數的正規化。
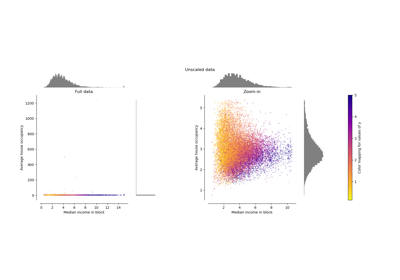
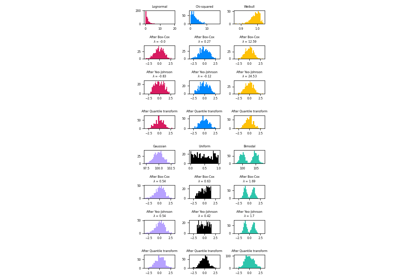
有關視覺化範例,請參閱 比較 PowerTransformer 與其他縮放器。若要查看 Box-Cox 和 Yeo-Johnson 轉換對不同分佈的影響,請參閱:將數據對應到常態分佈。
請參閱使用者指南以取得更多資訊。
在 0.20 版本中新增。
- 參數:
- 屬性:
另請參閱
power_transform沒有估算器 API 的對等函式。
QuantileTransformer使用參數
output_distribution='normal'將數據對應到標準常態分佈。
注意事項
NaN 會被視為遺失值:在
fit中忽略,並在transform中保留。參考文獻
[1]範例
>>> import numpy as np >>> from sklearn.preprocessing import PowerTransformer >>> pt = PowerTransformer() >>> data = [[1, 2], [3, 2], [4, 5]] >>> print(pt.fit(data)) PowerTransformer() >>> print(pt.lambdas_) [ 1.386... -3.100...] >>> print(pt.transform(data)) [[-1.316... -0.707...] [ 0.209... -0.707...] [ 1.106... 1.414...]]
- fit(X, y=None)[原始碼]#
估計每個特徵的最佳參數 lambda。
使用最大概似,在每個特徵上獨立估計最小化偏度的最佳 lambda 參數。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
用於估計最佳轉換參數的數據。
- yNone
已忽略。
- 回傳:
- self物件
已擬合的轉換器。
- fit_transform(X, y=None)[原始碼]#
將
PowerTransformer擬合到X,然後轉換X。- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
用於估計最佳轉換參數並使用冪轉換進行轉換的數據。
- y已忽略
未使用,為了 API 一致性而存在。
- 回傳:
- X_new形狀為 (n_samples, n_features) 的 ndarray
轉換後的數據。
- get_feature_names_out(input_features=None)[原始碼]#
取得轉換的輸出特徵名稱。
- 參數:
- input_features字串或 None 的類陣列,預設值 = None
輸入特徵。
如果
input_features為None,則會使用feature_names_in_作為輸入特徵名稱。如果未定義feature_names_in_,則會產生下列輸入特徵名稱:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features為類陣列,則如果已定義feature_names_in_,則input_features必須與feature_names_in_相符。
- 回傳:
- feature_names_out字串物件的 ndarray
與輸入特徵相同。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看使用者指南,瞭解路由機制如何運作。
- 回傳:
- routingMetadataRequest
一個
MetadataRequest,封裝了路由資訊。
- get_params(deep=True)[原始碼]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,將會回傳此估算器及其包含的子物件(也是估算器)的參數。
- 回傳:
- paramsdict
參數名稱對應到它們的值。
- inverse_transform(X)[原始碼]#
使用已擬合的 lambda 值,套用逆冪轉換。
Box-Cox 轉換的逆轉換由下式給出
if lambda_ == 0: X = exp(X_trans) else: X = (X_trans * lambda_ + 1) ** (1 / lambda_)
Yeo-Johnson 轉換的逆轉換由下式給出
if X >= 0 and lambda_ == 0: X = exp(X_trans) - 1 elif X >= 0 and lambda_ != 0: X = (X_trans * lambda_ + 1) ** (1 / lambda_) - 1 elif X < 0 and lambda_ != 2: X = 1 - (-(2 - lambda_) * X_trans + 1) ** (1 / (2 - lambda_)) elif X < 0 and lambda_ == 2: X = 1 - exp(-X_trans)
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列
轉換後的資料。
- 回傳:
- X形狀為 (n_samples, n_features) 的 ndarray
原始資料。
- set_output(*, transform=None)[原始碼]#
設定輸出容器。
請參閱 介紹 set_output API 以了解如何使用此 API 的範例。
- 參數:
- transform{“default”, “pandas”, “polars”},預設值為 None
設定
transform和fit_transform的輸出格式。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換設定不變
在 1.4 版本中新增: 新增了
"polars"選項。
- 回傳:
- self估算器實例
估算器實例。