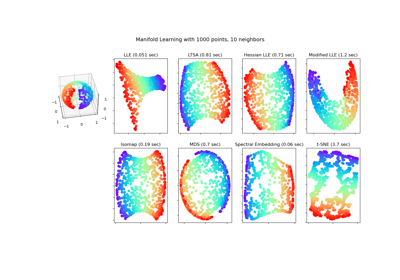
SpectralEmbedding#
- class sklearn.manifold.SpectralEmbedding(n_components=2, *, affinity='nearest_neighbors', gamma=None, random_state=None, eigen_solver=None, eigen_tol='auto', n_neighbors=None, n_jobs=None)[原始碼]#
用於非線性降維的譜嵌入 (Spectral embedding)。
根據指定的函數形成一個親和力矩陣,並對相應的圖拉普拉斯矩陣應用譜分解。 最終的轉換由每個數據點的特徵向量值給出。
注意:此處實作的實際演算法是拉普拉斯特徵映射 (Laplacian Eigenmaps)。
請在使用者指南中閱讀更多資訊。
- 參數:
- n_componentsint, default=2
投影子空間的維度。
- affinity{‘nearest_neighbors’, ‘rbf’, ‘precomputed’, ‘precomputed_nearest_neighbors’} 或可呼叫物件, default=’nearest_neighbors’
- 如何構建親和力矩陣。
‘nearest_neighbors’:透過計算最近鄰圖來構建親和力矩陣。
‘rbf’:透過計算徑向基函數(RBF)核來構建親和力矩陣。
‘precomputed’:將
X解釋為預先計算的親和力矩陣。‘precomputed_nearest_neighbors’:將
X解釋為預先計算的最近鄰稀疏圖,並透過選擇n_neighbors個最近鄰來構建親和力矩陣。可呼叫物件:使用傳入的函數作為親和力函數,該函數接受資料矩陣 (n_samples, n_features) 並回傳親和力矩陣 (n_samples, n_samples)。
- gammafloat, default=None
rbf 核的核係數。如果為 None,則 gamma 將設定為 1/n_features。
- random_stateint、RandomState 實例或 None,default=None
當
eigen_solver == 'amg'時,用於 lobpcg 特徵向量分解初始化的偽隨機數生成器,以及用於 K-Means 初始化。 使用 int 使結果在不同呼叫中具有確定性(請參閱詞彙表)。注意
當使用
eigen_solver == 'amg'時,還必須使用np.random.seed(int)來修正全域 numpy 種子,以取得確定性的結果。 有關更多資訊,請參閱 pyamg/pyamg#139。- eigen_solver{‘arpack’, ‘lobpcg’, ‘amg’}, default=None
要使用的特徵值分解策略。AMG 需要安裝 pyamg。在非常大、稀疏的問題上,它可能更快。如果為 None,則使用
'arpack'。- eigen_tolfloat, default="auto"
拉普拉斯矩陣特徵分解的停止準則。如果
eigen_tol="auto",則傳遞的容差將取決於eigen_solver如果
eigen_solver="arpack",則eigen_tol=0.0;如果
eigen_solver="lobpcg"或eigen_solver="amg",則eigen_tol=None,這會配置底層的lobpcg求解器根據其啟發式方法自動解析該值。請參閱scipy.sparse.linalg.lobpcg以取得詳細資訊。
請注意,當使用
eigen_solver="lobpcg"或eigen_solver="amg"時,tol<1e-5的值可能會導致收斂問題,應避免使用。在 1.2 版本中新增。
- n_neighborsint, default=None
用於最近鄰圖構建的最近鄰數量。如果為 None,則 n_neighbors 將設定為 max(n_samples/10, 1)。
- n_jobsint, default=None
要執行的平行工作的數量。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有處理器。 有關更多詳細資訊,請參閱詞彙表。
- 屬性:
- embedding_形狀為 (n_samples, n_components) 的 ndarray
訓練矩陣的譜嵌入。
- affinity_matrix_形狀為 (n_samples, n_samples) 的 ndarray
從樣本或預先計算構建的親和力矩陣。
- n_features_in_int
在fit期間看到的特徵數量。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。 僅當
X具有全部為字串的特徵名稱時才定義。在 1.0 版本中新增。
- n_neighbors_int
有效使用的最近鄰數量。
另請參閱
Isomap透過等距映射進行非線性降維。
參考文獻
範例
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import SpectralEmbedding >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = SpectralEmbedding(n_components=2) >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
- fit(X, y=None)[原始碼]#
從 X 中的資料擬合模型。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列或稀疏矩陣
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。如果親和性 (affinity) 為「預先計算」,則 X : {類陣列或稀疏矩陣},形狀為 (n_samples, n_samples),將 X 解釋為從樣本計算的預先計算鄰接圖。
- y忽略
不使用,為了 API 一致性而存在。
- 回傳值:
- self物件
回傳實例本身。
- fit_transform(X, y=None)[原始碼]#
從 X 中的資料擬合模型並轉換 X。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列或稀疏矩陣
訓練向量,其中
n_samples是樣本數,而n_features是特徵數。如果親和性 (affinity) 為「預先計算」,則 X : {類陣列或稀疏矩陣},形狀為 (n_samples, n_samples),將 X 解釋為從樣本計算的預先計算鄰接圖。
- y忽略
不使用,為了 API 一致性而存在。
- 回傳值:
- X_new形狀為 (n_samples, n_components) 的類陣列
訓練矩陣的譜嵌入。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由。
請查看 使用者指南 了解路由機制如何運作。
- 回傳值:
- routingMetadataRequest
一個封裝路由資訊的
MetadataRequest。