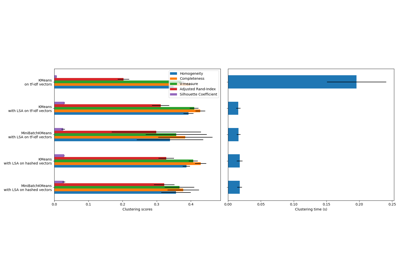
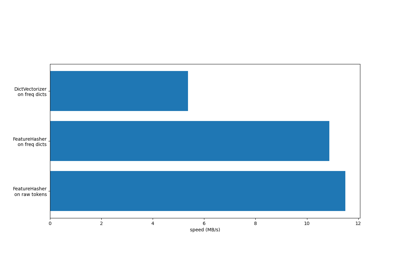
TfidfTransformer#
- class sklearn.feature_extraction.text.TfidfTransformer(*, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)[原始碼]#
將計數矩陣轉換為標準化的 tf 或 tf-idf 表示。
Tf 代表詞頻 (term-frequency),而 tf-idf 代表詞頻乘以逆向文件頻率 (inverse document-frequency)。這是一種常見的資訊檢索詞權重方案,在文件分類中也發現有很好的應用。
在給定文件中使用 tf-idf 而不是原始詞語出現頻率的目標,是縮減在給定語料庫中非常頻繁出現的詞語的影響,這些詞語在經驗上比在訓練語料庫中小部分出現的特徵資訊量更少。
用於計算文件集中文件 d 的詞語 t 的 tf-idf 公式為 tf-idf(t, d) = tf(t, d) * idf(t),並且 idf 的計算方式為 idf(t) = log [ n / df(t) ] + 1 (如果
smooth_idf=False),其中 n 是文件集中文件的總數,而 df(t) 是 t 的文件頻率;文件頻率是指文件集中包含詞語 t 的文件數。在上述方程式中將 “1” 加入 idf 的效果是,idf 為零的詞語,即在訓練集中所有文件中出現的詞語,不會被完全忽略。(請注意,上面的 idf 公式與標準教科書符號不同,標準教科書將 idf 定義為 idf(t) = log [ n / (df(t) + 1) ])。如果
smooth_idf=True(預設),則將常數 “1” 加到 idf 的分子和分母中,如同看到一個額外文件,其中每個詞語在集合中恰好出現一次,這樣可以防止除以零的情況:idf(t) = log [ (1 + n) / (1 + df(t)) ] + 1。此外,用於計算 tf 和 idf 的公式取決於參數設定,這些參數設定對應於 IR 中使用的 SMART 符號,如下所示:
預設情況下,Tf 為 “n” (自然),當
sublinear_tf=True時為 “l” (對數)。當使用 use_idf 時,Idf 為 “t”,否則為 “n” (無)。當norm='l2'時,標準化為 “c” (餘弦),當norm=None時,標準化為 “n” (無)。在使用者指南中閱讀更多內容。
- 參數:
- norm{‘l1’, ‘l2’} 或 None,預設為 ‘l2’
每個輸出列都將具有單位範數,即
‘l2’:向量元素的平方和為 1。當應用 l2 範數時,兩個向量之間的餘弦相似度是它們的點積。
‘l1’:向量元素的絕對值之和為 1。請參閱
normalize。None:不進行標準化。
- use_idf布林值,預設為 True
啟用逆向文件頻率重新加權。如果為 False,則 idf(t) = 1。
- smooth_idf布林值,預設為 True
透過將 1 加到文件頻率來平滑 idf 權重,如同看到一個額外文件,其中每個詞語在集合中恰好出現一次。防止除以零的情況。
- sublinear_tf布林值,預設為 False
應用次線性 tf 縮放,即將 tf 替換為 1 + log(tf)。
- 屬性:
另請參閱
CountVectorizerTfidfVectorizer將文字轉換為 n-gram 計數的稀疏矩陣。
HashingVectorizer
將原始文件集合轉換為 TF-IDF 特徵矩陣。
CountVectorizer將文字文件集合轉換為詞語出現次數矩陣。
參考文獻[Yates2011]
範例
>>> from sklearn.feature_extraction.text import TfidfTransformer >>> from sklearn.feature_extraction.text import CountVectorizer >>> from sklearn.pipeline import Pipeline >>> corpus = ['this is the first document', ... 'this document is the second document', ... 'and this is the third one', ... 'is this the first document'] >>> vocabulary = ['this', 'document', 'first', 'is', 'second', 'the', ... 'and', 'one'] >>> pipe = Pipeline([('count', CountVectorizer(vocabulary=vocabulary)), ... ('tfid', TfidfTransformer())]).fit(corpus) >>> pipe['count'].transform(corpus).toarray() array([[1, 1, 1, 1, 0, 1, 0, 0], [1, 2, 0, 1, 1, 1, 0, 0], [1, 0, 0, 1, 0, 1, 1, 1], [1, 1, 1, 1, 0, 1, 0, 0]]) >>> pipe['tfid'].idf_ array([1. , 1.22314355, 1.51082562, 1. , 1.91629073, 1. , 1.91629073, 1.91629073]) >>> pipe.transform(corpus).shape (4, 8)
- R. Baeza-Yates 和 B. Ribeiro-Neto (2011)。現代資訊檢索。Addison Wesley,第 68-74 頁。
[MRS2008]
- 返回:
self物件
擬合的轉換器。
- 其他擬合參數。
X_new形狀為 (n_samples, n_features_new) 的 ndarray 陣列
- 參數:
- input_features字串或 None 的類陣列,預設值為 None
輸入特徵。
如果
input_features為None,則會使用feature_names_in_作為輸入特徵名稱。如果未定義feature_names_in_,則會產生以下輸入特徵名稱:["x0", "x1", ..., "x(n_features_in_ - 1)"]。如果
input_features為類陣列,則如果已定義feature_names_in_,則input_features必須與feature_names_in_相符。
- 詞語/符號計數的矩陣。
- feature_names_out字串物件的 ndarray
與輸入特徵相同。
- get_metadata_routing()[來源]#
取得此物件的中繼資料路由。
請查閱 使用者指南,了解路由機制的運作方式。
- 詞語/符號計數的矩陣。
- routingMetadataRequest
一個
MetadataRequest,封裝了路由資訊。
- get_params(deep=True)[來源]#
取得此估算器的參數。
- 參數:
- deepbool,預設值為 True
如果為 True,則會傳回此估算器及其包含的子物件(也是估算器)的參數。
- 詞語/符號計數的矩陣。
- paramsdict
參數名稱對應到它們的值。
- set_output(*, transform=None)[來源]#
設定輸出容器。
請參閱 介紹 set_output API,以了解如何使用此 API 的範例。
- 參數:
- transform{"default", "pandas", "polars"},預設值為 None
設定
transform和fit_transform的輸出。"default":轉換器的預設輸出格式"pandas":DataFrame 輸出"polars":Polars 輸出None:轉換組態未變更
在 1.4 版中新增:新增了
"polars"選項。
- 詞語/符號計數的矩陣。
- self估算器實例
估算器實例。
- set_params(**params)[來源]#
設定此估算器的參數。
此方法適用於簡單的估算器以及巢狀物件(例如
Pipeline)。後者具有<component>__<parameter>形式的參數,因此可以更新巢狀物件的每個元件。- 參數:
- **paramsdict
估算器參數。
- 詞語/符號計數的矩陣。
- self估算器實例
估算器實例。
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') TfidfTransformer[來源]#
要求傳遞給
transform方法的中繼資料。請注意,此方法僅在
enable_metadata_routing=True時才相關(請參閱sklearn.set_config)。請參閱 使用者指南,了解路由機制的運作方式。每個參數的選項為
True:要求中繼資料,並在提供時傳遞給transform。如果未提供中繼資料,則會忽略要求。False:不要求中繼資料,且 meta-estimator 不會將其傳遞給transform。None:不要求中繼資料,且如果使用者提供,則 meta-estimator 將會引發錯誤。str:應該以這個給定的別名傳遞中繼資料給 meta-estimator,而不是原始名稱。
預設值(
sklearn.utils.metadata_routing.UNCHANGED)保留現有的要求。這允許您變更某些參數的要求,而不是其他參數。在 1.3 版中新增。
注意事項
僅當此估算器用作 meta-estimator 的子估算器時,此方法才相關,例如在
Pipeline內部使用。否則,它沒有任何作用。- 參數:
- copy字串、True、False 或 None,預設值為 sklearn.utils.metadata_routing.UNCHANGED
針對
transform中的copy參數的中繼資料路由。
- 詞語/符號計數的矩陣。
- yNone
更新後的物件。