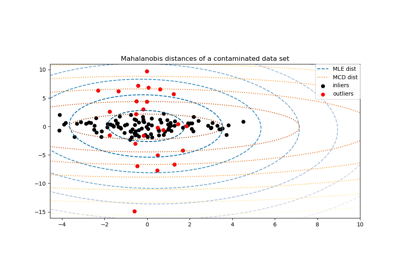
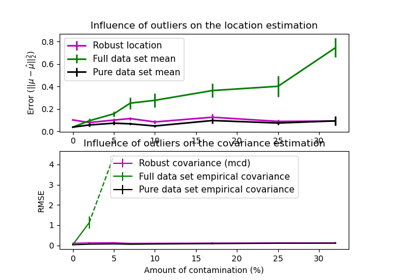
MinCovDet#
- class sklearn.covariance.MinCovDet(*, store_precision=True, assume_centered=False, support_fraction=None, random_state=None)[原始碼]#
最小共變異數行列式 (MCD):共變異數的穩健估計器。
最小共變異數行列式共變異數估計器適用於高斯分佈的數據,但也可能適用於從單峰、對稱分佈中提取的數據。它不適用於多峰數據(用於擬合 MinCovDet 物件的演算法很可能在這種情況下失敗)。應該考慮使用投影追蹤方法來處理多峰數據集。
在使用者指南中閱讀更多內容。
- 參數:
- store_precisionbool,預設值為 True
指定是否儲存估計的精確度。
- assume_centeredbool,預設值為 False
如果為 True,則計算穩健位置和共變異數估計的支持,並從中重新計算共變異數估計,而不對資料進行居中處理。適用於處理平均值顯著等於零但不完全為零的數據。如果為 False,則直接使用 FastMCD 演算法計算穩健位置和共變異數,而不進行額外處理。
- support_fractionfloat,預設值為 None
要包含在原始 MCD 估計的支持中的點的比例。預設值為 None,這表示將在演算法中使用 support_fraction 的最小值:
(n_samples + n_features + 1) / 2 * n_samples。參數必須在 (0, 1] 範圍內。- random_stateint、RandomState 實例或 None,預設值為 None
決定用於打亂數據的虛擬隨機數產生器。傳遞一個 int 以便在多個函數調用中獲得可重複的結果。請參閱詞彙表。
- 屬性:
- raw_location_形狀為 (n_features,) 的 ndarray
校正和重新加權之前的原始穩健估計位置。
- raw_covariance_形狀為 (n_features, n_features) 的 ndarray
校正和重新加權之前的原始穩健估計共變異數。
- raw_support_形狀為 (n_samples,) 的 ndarray
在校正和重新加權之前,用於計算位置和形狀的原始穩健估計的觀測值遮罩。
- location_形狀為 (n_features,) 的 ndarray
估計的穩健位置。
- covariance_形狀為 (n_features, n_features) 的 ndarray
估計的穩健共變異數矩陣。
- precision_形狀為 (n_features, n_features) 的 ndarray
估計的偽反矩陣。(僅當 store_precision 為 True 時才儲存)
- support_形狀為 (n_samples,) 的 ndarray
用於計算位置和形狀的穩健估計的觀測值遮罩。
- dist_形狀為 (n_samples,) 的 ndarray
訓練集(呼叫
fit的訓練集)觀測值的馬氏距離。- n_features_in_int
在 fit 期間看到的特徵數。
在 0.24 版本中新增。
- feature_names_in_形狀為 (
n_features_in_,) 的 ndarray 在 fit 期間看到的特徵名稱。僅當
X的特徵名稱均為字串時才定義。在 1.0 版本中新增。
另請參閱
EllipticEnvelopeEllipticEnvelope:用於偵測高斯分佈數據集中離群值的物件。EmpiricalCovarianceEmpiricalCovariance:最大概似共變異數估計器。GraphicalLassoGraphicalLasso:使用 l1 懲罰估計器的稀疏反共變異數估計。GraphicalLassoCVGraphicalLassoCV:使用交叉驗證選擇 l1 懲罰的稀疏反共變異數。LedoitWolfLedoitWolf:LedoitWolf 估計器。OASOAS:Oracle 近似收縮估計器。ShrunkCovarianceShrunkCovariance:具有收縮的共變異數估計器。
參考文獻
[Rouseeuw1984]P. J. Rousseeuw. 最小平方中位數迴歸。J. Am Stat Ass, 79:871, 1984。
[Rousseeuw]最小共變異數行列式估計器的快速演算法,1999 年,美國統計協會和美國質量協會,TECHNOMETRICS
[ButlerDavies]R. W. Butler、P. L. Davies 和 M. Jhun,最小共變異數行列式估計器的漸近性,統計年鑑,1993 年,第 21 卷,第 3 期,1385-1400
範例
>>> import numpy as np >>> from sklearn.covariance import MinCovDet >>> from sklearn.datasets import make_gaussian_quantiles >>> real_cov = np.array([[.8, .3], ... [.3, .4]]) >>> rng = np.random.RandomState(0) >>> X = rng.multivariate_normal(mean=[0, 0], ... cov=real_cov, ... size=500) >>> cov = MinCovDet(random_state=0).fit(X) >>> cov.covariance_ array([[0.7411..., 0.2535...], [0.2535..., 0.3053...]]) >>> cov.location_ array([0.0813... , 0.0427...])
- correct_covariance(data)[原始碼]#
對原始最小共變異數行列式估計應用校正。
使用 Rousseeuw 和 Van Driessen 在 [RVD] 中建議的經驗校正係數進行校正。
- 參數:
- data形狀為 (n_samples, n_features) 的類陣列
資料矩陣,具有 p 個特徵和 n 個樣本。資料集必須是曾經用於計算原始估計值的資料集。
- 返回:
- covariance_corrected形狀為 (n_features, n_features) 的 ndarray
已校正的穩健共變異數估計值。
參考文獻
[RVD]最小共變異數行列式估計器的快速演算法,1999 年,美國統計協會和美國質量協會,TECHNOMETRICS
- error_norm(comp_cov, norm='frobenius', scaling=True, squared=True)[原始碼]#
計算兩個共變異數估計器之間的均方誤差。
- 參數:
- comp_cov形狀為 (n_features, n_features) 的類陣列
要與之比較的共變異數。
- norm{"frobenius", "spectral"},預設值為 "frobenius"
用於計算誤差的範數類型。可用的誤差類型:- 'frobenius'(預設值):sqrt(tr(A^t.A)) - 'spectral':sqrt(max(eigenvalues(A^t.A)),其中 A 是誤差
(comp_cov - self.covariance_)。- scalingbool,預設值為 True
如果為 True(預設值),則均方誤差範數除以 n_features。如果為 False,則不重新縮放均方誤差範數。
- squaredbool,預設值為 True
是否計算均方誤差範數或誤差範數。如果為 True(預設值),則返回均方誤差範數。如果為 False,則返回誤差範數。
- 返回:
- resultfloat
self和comp_cov共變異數估計器之間的均方誤差(在弗羅貝尼烏斯範數的意義上)。
- fit(X, y=None)[原始碼]#
使用 FastMCD 演算法擬合最小共變異數行列式。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
訓練資料,其中
n_samples是樣本數,而n_features是特徵數。- y忽略
未使用,為了 API 的一致性而依慣例存在。
- 返回:
- self物件
回傳實例本身。
- get_metadata_routing()[原始碼]#
取得此物件的中繼資料路由 (metadata routing)。
請查看 使用者指南 以了解路由機制如何運作。
- 返回:
- routingMetadataRequest
一個
MetadataRequest,封裝了路由資訊。
- get_params(deep=True)[原始碼]#
取得此估算器 (estimator) 的參數。
- 參數:
- deep布林值 (bool), 預設為 True
如果為 True,將回傳此估算器和所包含的子物件(也是估算器)的參數。
- 返回:
- params字典 (dict)
參數名稱對應到它們的值。
- get_precision()[原始碼]#
精確度矩陣的 getter。
- 返回:
- precision_形狀為 (n_features, n_features) 的類陣列 (array-like)
與目前共變異數物件相關聯的精確度矩陣。
- mahalanobis(X)[原始碼]#
計算給定觀測值的平方馬氏距離 (Mahalanobis distance)。
- 參數:
- X形狀為 (n_samples, n_features) 的類陣列 (array-like)
我們計算其馬氏距離的觀測值。假設觀測值是從與 fit 中所用資料相同的分配中抽取出來的。
- 返回:
- dist形狀為 (n_samples,) 的 ndarray
觀測值的平方馬氏距離。
- reweight_covariance(data)[原始碼]#
重新加權原始的最小共變異數決定因子 (Minimum Covariance Determinant) 估計值。
使用 Rousseeuw 的方法重新加權觀測值 (等同於在計算位置和共變異數估計值之前,從資料集中刪除離群觀測值),此方法描述於 [RVDriessen]。
- 參數:
- data形狀為 (n_samples, n_features) 的類陣列
資料矩陣,具有 p 個特徵和 n 個樣本。資料集必須是曾經用於計算原始估計值的資料集。
- 返回:
- location_reweighted形狀為 (n_features,) 的 ndarray
重新加權的強健位置估計值。
- covariance_reweighted形狀為 (n_features, n_features) 的 ndarray
重新加權的強健共變異數估計值。
- support_reweighted形狀為 (n_samples,) 的 ndarray, dtype=bool
一個遮罩,表示哪些觀測值被用於計算重新加權的強健位置和共變異數估計值。
參考文獻
[RVDriessen]最小共變異數行列式估計器的快速演算法,1999 年,美國統計協會和美國質量協會,TECHNOMETRICS
- score(X_test, y=None)[原始碼]#
計算在估計的高斯模型下,
X_test的對數似然率。高斯模型由其平均值和共變異數矩陣定義,分別由
self.location_和self.covariance_表示。- 參數:
- X_test形狀為 (n_samples, n_features) 的類陣列 (array-like)
我們計算其似然率的測試資料,其中
n_samples是樣本數,而n_features是特徵數。假設X_test是從與 fit 中所用資料相同的分配中抽取出來的 (包括中心化)。- y忽略
未使用,為了 API 的一致性而依慣例存在。
- 返回:
- res浮點數 (float)
以
self.location_和self.covariance_作為高斯模型平均值和共變異數矩陣的估計值時,X_test的對數似然率。