交叉驗證#
- sklearn.model_selection.cross_validate(estimator, X, y=None, *, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, params=None, pre_dispatch='2*n_jobs', return_train_score=False, return_estimator=False, return_indices=False, error_score=nan)[來源]#
透過交叉驗證評估度量,並記錄擬合/評分時間。
請參閱使用者指南,以了解更多資訊。
- 參數:
- estimator實作 ‘fit’ 的估算器物件
用於擬合資料的物件。
- X形狀為 (n_samples, n_features) 的 {array-like, sparse matrix}
要擬合的資料。例如,可以是列表或陣列。
- y形狀為 (n_samples,) 或 (n_samples, n_outputs) 的 array-like,預設值為None
在監督式學習中,要嘗試預測的目標變數。
- groups形狀為 (n_samples,) 的 array-like,預設值為None
將資料集分割成訓練/測試集時使用的樣本群組標籤。僅與「群組」cv 實例(例如,
GroupKFold)一起使用。1.4 版變更:只有當未透過
sklearn.set_config(enable_metadata_routing=True)啟用元數據路由時,才能傳遞groups。當啟用路由時,請透過params參數傳遞groups以及其他元數據。例如:cross_validate(..., params={'groups': groups})。- scoringstr、可呼叫物件、列表、元組或字典,預設值為None
評估交叉驗證模型在測試集上效能的策略。如果為
None,則使用估算器的預設評估標準。如果
scoring代表單一分數,則可以使用單一字串(請參閱評分參數:定義模型評估規則);
返回單一值的可呼叫物件(請參閱可呼叫的評分器)。
如果
scoring代表多個分數,則可以使用唯一字串的列表或元組;
返回字典的可呼叫物件,其中鍵是度量名稱,值是度量分數;
字典,其中度量名稱作為鍵,可呼叫物件作為值。
請參閱指定多個評估度量以取得範例。
- cvint、交叉驗證產生器或可迭代物件,預設值為None
決定交叉驗證分割策略。cv 的可能輸入為
None,以使用預設的 5 折交叉驗證,
int,以指定
(Stratified)KFold中的折數,產生 (train, test) 分割(作為索引陣列)的可迭代物件。
對於 int/None 輸入,如果估算器是分類器且
y是二元或多類別,則使用StratifiedKFold。在所有其他情況下,使用KFold。這些分割器會以shuffle=False實例化,因此分割在各個呼叫中會相同。請參閱使用者指南,以了解這裡可使用的各種交叉驗證策略。
0.22 版變更:如果 cv 為 None,則
cv的預設值從 3 折變更為 5 折。- n_jobsint,預設值為None
要並行執行的作業數。訓練估算器和計算分數會在交叉驗證分割上並行執行。
None表示 1,除非在joblib.parallel_backend上下文中。-1表示使用所有處理器。請參閱詞彙表以取得更多詳細資料。- verboseint,預設值為0
詳細程度。
- paramsdict,預設值=None
要傳遞給底層估計器的
fit方法、評分器以及 CV 分割器的參數。於版本 1.4 新增。
- pre_dispatchint 或 str,預設值='2*n_jobs'
控制平行執行期間派遣的工作數量。當派遣的工作數量超過 CPU 可以處理的數量時,減少此數值有助於避免記憶體消耗激增。此參數可以是
一個 int,指定產生的總工作數量
一個 str,給出一個以 n_jobs 為函數的表達式,例如 '2*n_jobs'
- return_train_scorebool,預設值=False
是否包含訓練分數。計算訓練分數用於深入了解不同參數設定如何影響過擬合/欠擬合的權衡。然而,計算訓練集上的分數可能在計算上很昂貴,並且並非嚴格要求用於選擇產生最佳泛化效能的參數。
於版本 0.19 新增。
於版本 0.21 變更:預設值從
True變更為False- return_estimatorbool,預設值=False
是否返回在每個分割上擬合的估計器。
於版本 0.20 新增。
- return_indicesbool,預設值=False
是否返回每個分割所選的訓練-測試索引。
於版本 1.3 新增。
- error_score'raise' 或 numeric,預設值=np.nan
如果在估計器擬合時發生錯誤,則指定給分數的值。如果設定為 'raise',則會引發錯誤。如果給定數值,則會引發 FitFailedWarning。
於版本 0.20 新增。
- 回傳值:
- scores形狀為 (n_splits,) 的 float 陣列的字典
交叉驗證每次執行時估計器的分數陣列。
回傳一個包含每個評分器的分數/時間陣列的字典。此
dict的可能鍵值為test_score每個 cv 分割上的測試分數的陣列。如果評分參數中有多個評分指標,則
test_score中的後綴_score會變更為特定的指標,例如test_r2或test_auc。train_score每個 cv 分割上的訓練分數的陣列。如果評分參數中有多個評分指標,則
train_score中的後綴_score會變更為特定的指標,例如train_r2或train_auc。僅當return_train_score參數為True時才可用。fit_time在每個 cv 分割中,在訓練集上擬合估計器的時間。
score_time在每個 cv 分割中,在測試集上評估估計器的時間。(請注意,即使
return_train_score設定為True,也不包含在訓練集上評估的時間)estimator每個 cv 分割的估計器物件。僅當
return_estimator參數設定為True時才可用。indices每個 cv 分割的訓練/測試位置索引。回傳一個字典,其中的鍵為
"train"或"test",且相關聯的值為包含索引的整數 dtype NumPy 陣列的列表。僅當return_indices=True時才可用。
另請參閱
cross_val_score執行單一度量評估的交叉驗證。
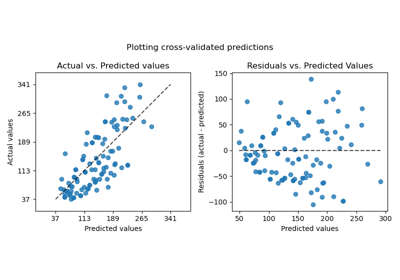
cross_val_predict從交叉驗證的每個分割取得預測結果,用於診斷目的。
sklearn.metrics.make_scorer從效能指標或損失函數建立評分器。
範例
>>> from sklearn import datasets, linear_model >>> from sklearn.model_selection import cross_validate >>> from sklearn.metrics import make_scorer >>> from sklearn.metrics import confusion_matrix >>> from sklearn.svm import LinearSVC >>> diabetes = datasets.load_diabetes() >>> X = diabetes.data[:150] >>> y = diabetes.target[:150] >>> lasso = linear_model.Lasso()
使用
cross_validate進行單一度量評估>>> cv_results = cross_validate(lasso, X, y, cv=3) >>> sorted(cv_results.keys()) ['fit_time', 'score_time', 'test_score'] >>> cv_results['test_score'] array([0.3315057 , 0.08022103, 0.03531816])
使用
cross_validate進行多度量評估(請參閱scoring參數文件以取得更多資訊)>>> scores = cross_validate(lasso, X, y, cv=3, ... scoring=('r2', 'neg_mean_squared_error'), ... return_train_score=True) >>> print(scores['test_neg_mean_squared_error']) [-3635.5... -3573.3... -6114.7...] >>> print(scores['train_r2']) [0.28009951 0.3908844 0.22784907]